Spring Cloud 核心组件协作及原理

上面是Spring Cloud这种RPC的框架图,对于Spring Cloud这个框架大家应该比较熟悉了,但是不能只停留在使用的层面,其底层的很多原理也需要去知晓。
业务举例:

一、Eureka

如上图所示,库存服务、仓储服务、积分服务中都有一个Eureka Client组件,这个组件专门负责将这个服务的信息注册到Eureka Server中。说白了,就是告诉Eureka Server,自己在哪台机器上,监听着哪个端口。而Eureka Server是一个注册中心,里面有一个注册表,保存了各服务所在的机器和端口号。
比如订单服务里的Eureka Client组件,它会找Eureka Server问一下:库存服务在哪台机器啊?监听着哪个端口啊?仓储服务呢?积分服务呢?然后就可以把这些相关信息从Eureka Server的注册表中拉取到自己本地缓存起来。
这时如果订单服务想要调用库存服务,不就可以找自己本地的Eureka Client问一下库存服务在哪台机器?监听哪个端口吗?收到响应后,紧接着就可以发送一个请求过去,调用库存服务扣减库存的那个接口。
因此:
Eureka Client : 负责将这个服务的信息注册到Eureka Server中
Eureka Server: 注册中心里面有一个注册表,保存了各个服务所在的IP和端口号

Eureka 核心功能
- 1、
服务注册和发现:eureka 分客户端(Eureka Client)和服务端(Eureka Server),服务端即为注册中心,提供服务注册和发现的功能。所有客户端将自己注册到注册中心上,服务端使用 Map 结构基于内存保存所有客户端信息(IP、端口、续约等信息)。客户端定时从注册中心拉取注册表到本地,就可以通过负载均衡的方式进行服务间的调用。 - 2、
服务注册(Register):Eureka Client 启动时向 Eureka Server 注册,并提供自身的元数据、IP地址、端口、状态等信息。 - 3、
服务续约(Renew):Eureka Client 默认每隔30秒向 Eureka Server 发送一次心跳进行服务续约,通过续约告知 Eureka Server 自己是正常的。如果 Eureka Server180秒没有收到客户端的续约,就会认为客户端故障,并将其剔除。 - 4、
抓取注册表(Fetch Registry):Eureka Client 启动时会向 Eureka Server全量抓取一次注册表到本地,之后会每隔30秒增量抓取注册表合并到本地注册表。如果合并后的本地注册表与 Eureka Server 端的注册表不一致(hash 比对),就全量抓取注册表覆盖本地的注册表。
5、服务下线(Cancel):Eureka Client 程序正常关闭时,会向 Eureka Server 发送下线请求,之后 Eureka Server 将这个实例从注册表中剔除。
6、故障剔除(Eviction):默认情况下,Eureka Client 连续180秒没有向 Eureka Server 发送续约请求,就会被认为实例故障,然后从注册表剔除。
7、Eureka Server 集群:Eureka Server 采用对等复制模式(Peer to Peer)来进行副本之间的数据同步,集群中每个 Server 节点都可以接收写操作和读操作。Server 节点接收到写操作后(注册、续约、下线、状态更新)会通过后台任务打包成批量任务发送到集群其它 Server 节点进行数据同步。Eureka Server 集群副本之间的数据会有短暂的不一致性,它是满足 CAP 中的 AP,即 高可用性和分区容错性。
自我保护机制
如果客户端超过180秒未续约则被认为是实例故障,后台定时任务会定时清除故障的实例。但 eureka 并不是直接把所有过期实例都清除掉,它会判断最近一分钟客户端续约次数是否大于每分钟续约阈值(85%),如果低于这个阈值,就任务是自身网络抖动导致客户端无法续约,然后进入自我保护模式,不再剔除过期实例。而且,在摘除过期实例的时候,它也不是一次性摘除所有过期实例,而是一次只摘除不超过15%的实例,分批次摘除。
eureka 认为保留可用及过期的数据总比丢失掉可用的数据好。我觉得它这里的一套自我保护机制的思想是值得我们学习的。
二、Feign
现在订单服务确实知道库存服务、积分服务、仓库服务在哪里了,同时也监听着哪些端口号了。但是新问题又来了:难道订单服务要自己写一大堆代码,跟其他服务建立网络连接,然后构造一个复杂的请求,接着发送请求过去,最后对返回的响应结果再写一大堆代码来处理吗?
若真的这么去做,就像下面这样:

可以看到自己去实现请求发送和接收结果,过程很复杂,若每个请求都这样那么是一项繁琐的工作。
如果用Feign的话:

Feign Client会在底层根据注解,跟指定的服务建立连接、构造请求、发起靕求、获取响应、解析响应等。
所以,Feign到底是啥?
Feign 是啥?
上面的介绍,大家应该有个大概的理解了,下面总结概括下。
通过 接口 + 注解的方式发起 HTTP 请求调用,面向接口编程,而不是像 Java 中通过封装 HTTP 请求报文的方式直接调用。服务消费方拿到服务提供方的接⼝,然后像调⽤本地接⼝⽅法⼀样去调⽤,实际发出的是远程的请求。让我们更加便捷和优雅的去调⽤基于 HTTP 的 API,被⼴泛应⽤在 Spring Cloud 的解决⽅案中。
Feign 的首要目标就是减少 HTTP 调用的复杂性。
在微服务调用的场景中,我们调用很多时候都是基于 HTTP 协议的服务,如果服务调用只使用提供 HTTP 调用服务的 HTTP Client 框架:

相比这些 HTTP 请求框架,Feign 封装了 HTTP 请求调用的流程,而且会强制使用者去养成面向接口编程的习惯(因为 Feign 本身就是要面向接口)。不用过多考虑编解码、请求超时、重试等。
Feign 怎么执行的?
Feign的一个关键机制就是使用了动态代理。
大致流程:
- 某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理
- Feign的动态代理会根据接口上的@RequestMapping等注解,来动态构造出要请求的服务地址
- 最后针对这个地址,发起请求、解析响应
![在这里插入图片描述]()

如果用一句话来概括Feign的工作原理,就是:
在微服务启动时,Feign会进行包扫描,对加@FeignClient注解的接口,按照注解的规则,创建远程接口的本地JDK Proxy代理实例。然后,将这些本地Proxy代理实例,注入到Spring IOC容器中。当远程接口的方法被调用,由Proxy代理实例去完成真正的远程访问,并且返回结果。
Dive into Feign
只是定了接口并没有具体的实现类,但是却可以在测试类中直接调用接口的方法来完成接口的调用,我们知道在 Java 里面接口是无法直接进行使用的,因此可以大胆猜测是 Feign 在背后默默生成了接口的代理实现类:

远程接口的本地JDK Proxy代理实例,有以下特点:
(1)本地Proxy代理实例,实现了一个加 @FeignClient 注解的远程调用接口;
(2)本地Proxy代理实例,能在内部进行HTTP请求的封装,以及发送HTTP 请求;
(3)本地Proxy代理实例,能处理远程HTTP请求的响应,并且完成结果的解码,然后返回给调用者
本地JDK Proxy代理实例的创建过程
FeignInvocationHandler
通过 JDK Proxy 生成动态代理类,核心步骤就是需要定制一个调用处理器,具体来说,就是实现JDK中位于java.lang.reflect 包中的 InvocationHandler 调用处理器接口,并且实现该接口的 invoke(…) 抽象方法。
为了创建Feign的远程接口的代理实现类,Feign提供了自己的一个默认的调用处理器,叫做 FeignInvocationHandler 类。调用处理器可以进行替换,如果Feign与Hystrix结合使用,则会替换成 HystrixInvocationHandler 调用处理器类。
默认的调用处理器 FeignInvocationHandler 有一个非常重要Map类型成员 dispatch 映射,保存着远程接口方法到MethodHandler方法处理器的映射,即 dispatch 中保存了所有的方法以及这个方法对应的方法处理器。
FeignInvocationHandler 源码如下:
static class FeignInvocationHandler implements InvocationHandler {
private final Target target;
//方法实例对象和方法处理器的映射
private final Map<Method, MethodHandler> dispatch;
//构造函数
FeignInvocationHandler(Target target, Map<Method, MethodHandler> dispatch) {
this.target = checkNotNull(target, "target");
this.dispatch = checkNotNull(dispatch, "dispatch for %s", target);
}
//默认Feign调用的处理
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//...
//首先,根据方法实例,从dispatch(方法实例对象和方法处理器的映射)中,
//取得 方法处理器,然后,调用 方法处理器 的 invoke(...) 方法
return dispatch.get(method).invoke(args);
}
}
重点在于invoke(…)方法,虽然核心代码只有一行,但是其功能是复杂的:
- (1)根据Java反射的方法实例,在dispatch 映射对象中,找到对应的MethodHandler 方法处理
- (2)调用MethodHandler方法处理器的 invoke(…) 方法,完成实际的HTTP请求和结果的处理。
MethodHandler
Feign的方法处理器 MethodHandler 是一个独立的接口,定义在 InvocationHandlerFactory 接口中,仅仅拥有一个invoke(…)方法,源码如下:
//定义在InvocationHandlerFactory接口中
public interface InvocationHandlerFactory {
//方法处理器接口,仅仅拥有一个invoke(…)方法
interface MethodHandler {
//完成远程URL请求
Object invoke(Object[] argv) throws Throwable;
}
}
MethodHandler 的invoke(…)方法,主要职责是完成实际远程URL请求,然后返回解码后的远程URL的响应结果。Feign提供了默认的 SynchronousMethodHandler 实现类,提供了基本的远程URL的同步请求处理。
final class SynchronousMethodHandler implements MethodHandler {
//…
// 执行Handler 的处理
public Object invoke(Object[] argv) throws Throwable {
RequestTemplate requestTemplate = this.buildTemplateFromArgs.create(argv);
Retryer retryer = this.retryer.clone();
while(true) {
try {
return this.executeAndDecode(requestTemplate);
} catch (RetryableException var5) {
//…省略不相干代码
}
}
}
//执行请求,然后解码结果
Object executeAndDecode(RequestTemplate template) throws Throwable {
Request request = this.targetRequest(template);
long start = System.nanoTime();
Response response;
try {
response = this.client.execute(request, this.options);
response.toBuilder().request(request).build();
}
}
}
SynchronousMethodHandler的invoke(…)方法,调用了自己的executeAndDecode(…) 请求执行和结果解码方法。该方法的工作步骤:
- (1)首先通 RequestTemplate 请求模板实例,生成远程URL请求实例 request;
- (2)然后用自己的 feign 客户端client成员,excecute(…) 执行请求,并且获取 response 响应;
- (3)对response 响应进行结果解码。
整体的远程调用执行流程
第1步:通过Spring IOC 容器实例,装配代理实例,然后进行远程调用。
Feign在启动时,会为加上了@FeignClient注解的所有远程接口,创建一个本地JDK Proxy代理实例,并注册到Spring IOC容器。在这里,暂且将这个Proxy代理实例,叫做 DemoClientProxy,稍后,会详细介绍这个Proxy代理实例的具体创建过程。
第2步:执行 InvokeHandler 调用处理器的invoke(…)方法
JDK Proxy动态代理实例的真正的方法调用过程,具体是通过 InvokeHandler 调用处理器完成的。故这里的DemoClientProxy代理实例,会调用到默认的FeignInvocationHandler 调用处理器实例的invoke(…)方法。
默认的调用处理器 FeignInvocationHandler,内部保持了一个远程调用方法实例和方法处理器的一个Key-Value键值对Map映射dispatch 。FeignInvocationHandler 在其invoke(…)方法中,会根据Java反射的方法实例,在dispatch 映射对象中,找到对应的 MethodHandler 方法处理器,然后由后者完成实际的HTTP请求和结果的处理。
所以在第2步中,FeignInvocationHandler 会从自己的 dispatch映射中,找到hello()方法所对应的MethodHandler 方法处理器,然后调用其 invoke(…)方法。
第3步:执行 MethodHandler 方法处理器的invoke(…)方法
通过前面关于 MethodHandler 方法处理器的非常详细的组件介绍,feign默认的方法处理器为 SynchronousMethodHandler,其invoke(…)方法主要是通过内部成员feign客户端成员 client,完成远程 URL 请求执行和获取远程结果。feign.Client 客户端有多种类型,不同的类型,完成URL请求处理的具体方式不同。
第4步:通过 feign.Client 客户端成员,完成远程 URL 请求执行和获取远程结果
如果MethodHandler方法处理器实例中的client客户端,是默认的 feign.Client.Default 实现类性,则使用JDK自带的HttpURLConnnection类,完成远程 URL 请求执行和获取远程结果。
如果MethodHandler方法处理器实例中的client客户端,是 ApacheHttpClient 客户端实现类性,则使用 Apache httpclient 开源组件,完成远程 URL 请求执行和获取远程结果。
注意:
SynchronousMethodHandler 并不是直接完成远程URL的请求,而是通过负载均衡机制,定位到合适的远程server 服务器,然后再完成真正的远程URL请求。换句话说,SynchronousMethodHandler实例的client成员,其实际不是feign.Client.Default类型,而是 LoadBalancerFeignClient 客户端负载均衡类型。
因此,上面的第3步,如果进一步细分话,大致如下:(1)首先通过 SynchronousMethodHandler 内部的client实例,实质为负责客户端负载均衡 LoadBalancerFeignClient 实例,首先查找到远程的 server 服务端;(2) 然后再由LoadBalancerFeignClient 实例内部包装的feign.Client.Default 内部类实例,去请求server端服务器,完成URL请求处理。
三、Ribbon
说完了Feign,还没完。现在新的问题又来了,如果人家库存服务部署在了5台机器上:
192.168.169:9000
192.168.170:9000
192.168.171:9000
192.168.172:9000
192.168.173:9000
Feign该如何选择请求哪台服务器呢?
Ribbon就是专门解决这个问题的。它的作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上。Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法。
负载均衡代码实例
先搭建演示需要的服务,一个消费者服务consumer,三个服务提供者provider,一个eureka注册中心服务
consumer服务通过服务名去调用三个provider,那么consumer就是客户端。
( 代码位置,可自行下载: GitHub - ImOk520/myspringcloud ):

启动所有服务,查看注册中心:

消费者consumer中我们调用的接口如下:
 三个服务提供者都是以procider这个名字启动的,此时通过provider这个服务名就能映射三个服务提供者。但是这还不能实现负载均衡,还需要在RestTemplate中加上@LoadBalanced注解:
三个服务提供者都是以procider这个名字启动的,此时通过provider这个服务名就能映射三个服务提供者。但是这还不能实现负载均衡,还需要在RestTemplate中加上@LoadBalanced注解:
 此时调用consumer的接口如下:
此时调用consumer的接口如下:

这里每个服务提供者对应不同的数据库,分别对应db01,db02,db03,每次调用会负载均衡到不同的服务提供者,因此数据库的名称会不断变化:
 上面可以看到, 客户端consumer的RestTemplate 上加了 @LoadBalance 注解,通过这个注解实现了客户端的主动负载均衡。
上面可以看到, 客户端consumer的RestTemplate 上加了 @LoadBalance 注解,通过这个注解实现了客户端的主动负载均衡。
Ribbon 是怎么工作的?
Ribbon是和Feign以及Eureka紧密协作,完成工作的。
- 首先Ribbon会从 Eureka Client里获取到对应的服务注册表,也就知道了所有的服务都部署在了哪些机器上,在监听哪些端口号。
- 然后Ribbon就可以使用默认的Round Robin算法,从中选择一台机器
- Feign就会针对这台机器,构造并发起请求。
![在这里插入图片描述]()

Ribbon 的负载策略

- RoundRobinRule 轮询
轮询服务列表List的index,选择index对应位置的服务。 - RandomRule 随机
随机服务列表List的index,选择index对应位置的服务。 - RetryRule 重试
指定时间内,重试(请求)某个服务不成功达到指定次数,则不再请求该服务。 - 自定义负载算法
负载均衡原理
Ribbon的负载均衡,主要通过LoadBalancerClient来实现的,而LoadBalancerClient具体交给了ILoadBalancer来处理,ILoadBalancer通过配置IRule、IPing等信息,并向EurekaClient获取注册列表的信息,并默认10秒一次向EurekaClient发送“ping”,进而检查是否更新服务列表,最后,得到注册列表后,ILoadBalancer根据IRule的策略进行负载均衡。
而RestTemplate 被@LoadBalance注解后,能过用负载均衡,主要是维护了一个被@LoadBalance注解的RestTemplate列表,并给列表中的RestTemplate添加拦截器,进而交给负载均衡器去处理。
为什么在RestTemplate加一个@LoadBalance注解就可可以开启负载均衡呢?
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
全局搜索ctr+shift+f @LoadBalanced 有哪些类用到了 LoadBalanced 有哪些类用到了, 发现LoadBalancerAutoConfiguration类,即LoadBalancer自动配置类:
@Configuration
@ConditionalOnClass(RestTemplate.class)
@ConditionalOnBean(LoadBalancerClient.class)
@EnableConfigurationProperties(LoadBalancerRetryProperties.class)
public class LoadBalancerAutoConfiguration {
@LoadBalanced
@Autowired(required = false)
private List restTemplates = Collections.emptyList();
}
@Bean
public SmartInitializingSingleton loadBalancedRestTemplateInitializer(
final List customizers) {
return new SmartInitializingSingleton() {
@Override
public void afterSingletonsInstantiated() {
for (RestTemplate restTemplate : LoadBalancerAutoConfiguration.this.restTemplates) {
for (RestTemplateCustomizer customizer : customizers) {
customizer.customize(restTemplate);
}
}
}
};
}
@Configuration
@ConditionalOnMissingClass("org.springframework.retry.support.RetryTemplate")
static class LoadBalancerInterceptorConfig {
@Bean
public LoadBalancerInterceptor ribbonInterceptor(
LoadBalancerClient loadBalancerClient,
LoadBalancerRequestFactory requestFactory) {
return new LoadBalancerInterceptor(loadBalancerClient, requestFactory);
}
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(
final LoadBalancerInterceptor loadBalancerInterceptor) {
return new RestTemplateCustomizer() {
@Override
public void customize(RestTemplate restTemplate) {
List list = new ArrayList<>(
restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
restTemplate.setInterceptors(list);
}
};
}
}
}
在该类中,首先维护了一个被@LoadBalanced修饰的RestTemplate对象的List,在初始化的过程中,通过调用customizer.customize(restTemplate)方法来给RestTemplate增加拦截器LoadBalancerInterceptor。
而LoadBalancerInterceptor,用于实时拦截,在LoadBalancerInterceptor这里实现来负载均衡。LoadBalancerInterceptor的拦截方法如下:
@Override
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return this.loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution));
}
综上所述,Ribbon的负载均衡,主要通过LoadBalancerClient来实现的,而LoadBalancerClient具体交给了ILoadBalancer来处理,ILoadBalancer通过配置IRule、IPing等信息,并向EurekaClient获取注册列表的信息,并默认10 秒一次向EurekaClient发送“ping”,进而检查是否更新服务列表,最后,得到注册列表后,ILoadBalancer根据IRule的策略进行负载均衡。
而 RestTemplate 被@LoadBalance注解后,能够负载均衡,主要是维护了一个被@LoadBalance注解的RestTemplate列表,并给列表中的RestTemplate添加拦截器,进而交给负载均衡器去处理。
多个RestTemplate从哪来?主要是@LoadBalance注解是包含@Qualifier注解的:
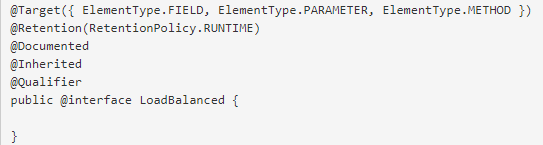
@Qualifier注解注解有两个使用场景:
- 一、当Spring上下文中含有某个Bean的多个实例,可以指定获取某个实例
- 二、获取Spring上下文中,某个Bean的创建,使用
Qualifier注解标记的对象集合
SpringCloud-ribbon组件中,@Qualifie的作用是获取所有使用LoadBalanced注解标记的 RestTemplate 的对象。

四、Hystrix
假如积分服务挂了,每次订单服务调用积分服务的时候,都会卡住几秒钟,然后抛出—个超时异常。这样会导致什么问题?
如果系统处于高并发的场景下,大量请求涌过来的时候,订单服务的100个线程都会卡在请求积分服务这块。导致订单服务没有一个线程可以处理请求。然后就会导致别人请求订单服务的时候,发现订单服务也挂了,不响应任何请求了。
这么多服务互相调用,要是不做任何保护的话,某一个服务挂了,就会引起连锁反应,导致别的服务也挂。也就是微服务雪崩问题。
怎么进行隔离保护?
这时就轮到Hystrix闪亮登场了。Hystrix是隔离、熔断以及降级的一个框架。
Hystrix会起很多个小小的线程池,比如订单服务请求库存服务是一个线程池,请求仓储服务是一个线程池,请求积分服务是一个线程池。每个线程池里的线程就仅仅用于请求那个服务。
积分服务挂了,会咋样?
当然会导致订单服务里那个用来调用积分服务的线程都卡死不能工作了啊!但由于订单服务调用库存服务、仓储服务的这两个线程池都是正常工作的,所以这两个服务不会受到任何影响。

这个时候如果别人请求订单服务,订单服务还是可以正常调用库存服务扣减库存,调用仓储服务通知发货。只不过调用积分服务的时候,每次都会报错。但是如果积分服务都挂了,每次调用都要去卡住几秒钟干啥呢?所以直接对积分服务熔断,比如在5分钟内请求积分服务直接就返回了,不要去走网络请求卡住几秒钟,这个过程,就是所谓的熔断!
积分服务挂了就熔断,好歹干点儿什么啊!别啥都不干就直接返回啊?那也可以来个降级:每次调用积分服务,就在数据库里记录一条消息,说给某某用户增加了多少积分,因为积分服务挂了,导致没增加成功!这样等积分服务恢复了,你可以根据这些记录手工加一下积分。这个过程,就是所谓的降级。
总的来说,发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号