蓝绿发布?灰度发布?滚动发布?
一、概述
应用程序升级面临最大挑战是新旧业务切换,将软件从测试的最后阶段带到生产环境,同时要保证系统不间断提供服务。
长期以来,业务升级渐渐形成了几个发布策略:蓝绿发布、灰度发布和滚动发布,目的是尽可能避免因发布导致的流量丢失或服务不可用问题。

下面先大致介绍下三种发布形式。
蓝绿发布

项目逻辑上分为A、B组,在项目系统时,首先把A组从负载均衡中摘除,进行新版本的部署。B组仍然继续提供服务。

当A组升级完毕,负载均衡重新接入A组,再把B组从负载列表中摘除,进行新版本的部署。A组重新提供服务。

最后,B组也升级完成,负载均衡重新接入B组,此时,AB组版本都已经升级完成,并且共同对外提供服务。
特点:
- 如果出问题,影响范围较大;
- 发布策略简单;
- 用户无感知,平滑过渡;
- 升级/回滚速度快
缺点:
- 需要准备正常业务使用资源的两倍以上服务器,防止升级期间单组无法承载业务突发;
- 短时间内浪费一定资源成本;
蓝绿发布在早期物理服务器时代,还是比较昂贵的,由于云计算普及,成本也大大降低。
灰度发布
也叫金丝雀发布。
灰度发布只升级部分服务,即让一部分用户继续用老版本,一部分用户开始用新版本,如果用户对新版本没什么意见,那么逐步扩大范围,把所有用户都迁移到新版本上面来。

部署过程:
- 从LB摘掉灰度服务器,升级成功后再加入LB;
- 少量用户流量到新版本;
- 如果灰度服务器测试成功,升级剩余服务器。
特点:
- 保证整体系统稳定性,在初始灰度的时候就可以发现、调整问题,影响范围可控;
- 新功能逐步评估性能,稳定性和健康状况,如果出问题影响范围很小,相对用户体验也少;
- 用户无感知,平滑过渡
缺点:
- 自动化要求高
灰度发布是通过切换线上并存版本之间的路由权重,逐步从一个版本切换为另一个版本的过程。
滚动发布
滚动发布是指每次只升级一个或多个服务,升级完成后加入生产环境,不断执行这个过程,直到集群中的全部旧版本升级新版本。
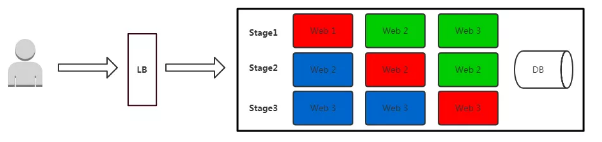
- 红色:正在更新的实例
- 蓝色:更新完成并加入集群的实例
- 绿色:正在运行的实例
部署过程:
- 先升级1个副本,主要做部署验证;
- 每次升级副本,自动从LB上摘掉,升级成功后自动加入集群;
- 事先需要有自动更新策略,分为若干次,每次数量/百分比可配置;
- 回滚是发布的逆过程,先从LB摘掉新版本,再升级老版本,这个过程一般时间比较长;
- 自动化要求高。
特点:
- 节约资源
- 用户无感知,平滑过渡
缺点:
- 部署时间慢,取决于每阶段更新时间;
- 发布策略较复杂;
- 无法确定OK的环境,不易回滚。
小结
综上所述,三种方式均可以做到平滑式升级,在升级过程中服务仍然保持服务的连续性,升级对外界是无感知的。那生产上选择哪种部署方法最合适呢?这取决于哪种方法最适合你的业务和技术需求。如果你们运维自动化能力储备不够,肯定是越简单越好,建议蓝绿发布,如果业务对用户依赖很强,建议灰度发布。如果是K8S平台,滚动更新是现成的方案,建议先直接使用。
- 蓝绿发布:两套环境交替升级,旧版本保留一定时间便于回滚。
- 灰度发布:根据比例将老版本升级,例如80%用户访问是老版本,20%用户访问是新版本。
- 滚动发布:按批次停止老版本实例,启动新版本实例。
二、灰度方案
灰度解决什么问题
一个变更如果在发布后立即全量上线,那么如果出现系统、逻辑、数据等问题,将会是灾难性的。
或者说这个新的功能,我们对客户是否满意不太有把握,那么贸然全部铺开可能引起大量客户反感甚至投诉。
安全生产规则中所谓的“无灰度,不发布”就是这个思想,通过灰度尽可能的减少问题的影响面。如果通过灰度过程发现一个线上问题,那么去掉灰度的保护,可能就会产生一个严重的故障。
灰度过程就是在规避变更过程中这个最大的风险:全局影响。通过减小影响范围,再配合灰度线上验证、监控报警等手段,将出现问题时影响面,控制在有限的范围内,如减少订正的数据量或降低资损金额等。
灰度带来什么问题
灰度过程中产生的灰度数据,可能对非灰度数据产生侵入。
灰度系统需要与上下游联动,灰度本身也需要推进,一旦遇到问题,还需要进行灰度停止、灰度回退等更复杂的操作,因此灰度整体是一个动态的过程,而在整个动态过程中,需要严格保持灰度数据&非灰度数据的隔离,否则将会导致问题影响面扩大化,危及整个系统,甚至发生严重故障。
这里尤其需要注意的是灰度停止与灰度回退的复杂性:如果灰度停止手段不能生效,那么问题影响就无法得到有效控制;灰度回退则需要涉及阻断灰度流程、修改已有灰度数据、修复错误数据等,一般来说是整套灰度方案中最复杂的部分。
灰度与非灰度数据都是真实的业务数据,一旦出现问题,并不能通过删除灰度数据或脏数据的方式解决问题,一般需要进行数据订正,或发布新的变更进行修复。数据订正的数量、订正数据的正确性、如何甄别灰度用户、如何保证新变更的正确性、如何保证新变更可以有效修复问题数据等,都是恢复过程中的难点工作与潜在风险。
虽然灰度方案会引入各种各样问题与风险,整个系统的复杂度也将成倍的增加,对灰度的质量保障方案也会同时变得更为复杂。那么如何有效的控制这些风险,同时高质量的达成项目目标呢?我们常说,好质量不是测出来的,对于复杂的灰度系统来说,这句话同样适用。一个高质量的灰度方案,不仅需要完善的测试,更要依赖于良好的设计。保障安全生产和达成项目目标二者绝不是矛盾的,只要灰度方案设计得当,鱼与熊掌可兼得之。
数据库变更对旧版本的兼容性的影响
例如:某个表有a、b两个字段,新的版本增加了c字段,在灰度部署过程中就会带来新旧版本的兼容性问题。
因此在写SQL时,必须明确字段含义,不能这样写:
insert into t values('1', '2');
而应该写成:
insert into t(a,b) values('1', '2');
这样兼容性更好的语句。
发布用户群的选择
不能采用类似Nginx的权重策略,因为会导致同一个用户在新旧版本中反复调用,出现问题。
解决方法是:Nginx + lua脚本化
基于IP或UA等用户稳定特性,通过Hash取模来决定版本:

什么时候才能提升分配比例
在灰度发布过程中,要监测用户请求失败率、用户请求处理时长、异常次数等,以保证比例分配、回滚等。
SkyWalking,国产开源监控系统较常用。

灰度设计
灰度维度的选取
生产系统中常见的灰度的规则,有用户id尾号、业务单据id尾号、白名单、黑名单、时间戳等。
黑名单则是一种兜底手段,可以对特殊用户(如数据量特别大用户、重点客户等)进行屏蔽,减少或避免其受到灰度的影响,尤其是在灰度过程出现问题时,直接阻断其进入系统中的问题逻辑。
采用用户id尾号或业务单据id尾号作为灰度key,是更常见的灰度区分方式。但如何选取这类灰度key,需要注意几个要点。
- 第一,选取的key应当是均匀分布或近似均匀分布的,如集团的havanaId等,否则全量用户无法分批分散的命中新逻辑,灰度的逐步放量的能力就失去了作用,极端地,整个灰度能力会退化为布尔化的全局开关。
- 第二,计算key的逻辑需要尽量简化。系统中使用灰度key来判别走新逻辑还是旧逻辑,这个条件判断一般会在系统中反复出现、多次执行,此时如果设计特别复杂计算方式,则会给系统带来额外的开销。除此之外,简化key的计算逻辑也会带来业务语义上的简化,便于整个业务链上的技术同学与非技术同学快速理解,也便于遇到问题时快速定位与排查,更有利于系统的长期维护。
- 第三,要结合业务实际选取。如果选取一个当次变更新增的业务字段作为灰度key,那么上下游系统是否需要做同步改造?离线数据&报表是否需要配合改造?如果选取一个对下游业务未记录的或无意义的字段呢?这些都是通过合理设计可以节省的改造成本。因此在选取灰度key时,需要选取上下游业务已有的、通用的、具有业务意义的字段。
简化灰度逻辑
灰度逻辑仅仅是将一个用户或单据非此即彼的区分开,因此灰度逻辑不仅没有必要做的太过复杂,而且还应当尽量简化,如果业务上有条件,最好能用一个字段或一个变量搞定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号