面试官:你了解一致性Hash算法吗?
面试官问这个问题不奇怪,可以说一致性Hash算法是分布式系统中的一个基石一样的算法,没有这个算法可能很多问题不太好解决。
Hash算法在很多分布式集群产品中都有应⽤,⽐如分布式集群架构Redis、Hadoop、ElasticSearch, Mysql分库分表,Nginx负载均衡等。
一、解决什么问题?
先看看一致性Hash算法到底解决的是什么场景中的问题。
假设有三台缓存服务器,用于缓存图片,这三台缓存服务器编号为0号、1号、2号。现在,有3万张图片需要缓存,这些图片被均匀随机的缓存到这3台服务器上,每台服务器能够缓存1万张左右的图片,以便它们能够分摊缓存的压力。
但是如果这样做,当我们需要访问某个缓存项时,则需要遍历3台缓存服务器,从3万个缓存项中找到我们需要访问的缓存,遍历的过程效率太低,缓存的目的就是提高速度,改善用户体验,减轻后端服务器压力,如果每次访问一个缓存项都需要遍历所有缓存服务器的所有缓存项,时间太长。
该怎么办呢?
之前说过分布式session问题,其中有一个方式就是对客户端的IP取Hash,使得同一个客户端每次访问的是同一台服务器。 分布式session问题可以参考这里。
也就是,对缓存项的键进行哈希,将hash后的结果对缓存服务器的数量进行取模操作,通过取模后的结果,决定缓存项将会缓存在哪一台服务器上。
但是,上述HASH算法有一些缺陷,试想一下,如果3台缓存服务器已经不能满足我们的缓存需求,那么我们应该怎么做呢?没错,很简单,多增加两台缓存服务器不就行了,假设,我们增加了一台缓存服务器,那么缓存服务器的数量就由3台变成了4台,此时,如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,被除数不变的情况下,余数肯定不同,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变,换句话说,如果想要访问一张图片,这张图片的缓存位置必定会发生改变,以前缓存的图片也会失去缓存的作用与意义,由于大量缓存在同一时间失效,造成了缓存的雪崩,此时前端缓存已经无法起到承担部分压力的作用,后端服务器将会承受巨大的压力,整个系统很有可能被压垮,所以应该想办法不让这种情况发生,但是由于上述HASH算法本身的缘故,使用取模法进行缓存时,这种情况是无法避免的,为了解决这些问题,一致性哈希算法诞生了。
一致性hash算法的基本概念
一致性哈希算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性哈希算法是对2^32取模。
为啥会这样做,其实前面也说了,因为对服务器数量取模,一旦服务器的数量改变,那么之前计算得到的Hash映射就作废了,但是对2^32取模,这个是很大的一个数,除非服务器的数量超过这个数,不然不会因为服务器的数量改变而作废。
Hash环
首先,我们把2^32想象成一个圆,就像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处把这个圆想象成由2^32个点组成的圆,示意图如下:
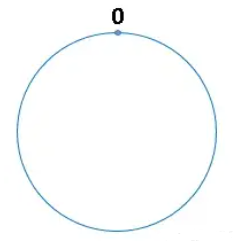
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32 - 1,也就是说0点左侧的第一个点代表2^32 - 1,我们把这个圆环称为hash环。
这个hash环有啥用?
还是以上面的3台缓存服务器为例,服务器A、服务器B、服务器C,那么在生产环境中,这三台服务器肯定有自己的IP地址,我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式:
hash(服务器A的IP地址) % 2^32
通过上述公式算出的结果一定是一个0到2^32 - 1之间的一个整数,就用算出的这个整数,代表服务器A,既然这个整数肯定处于0到2^32 - 1之间,那么,上图中的hash环上必定有一个点与这个整数对应,服务器A就可以映射到这个环上,用下图示意:
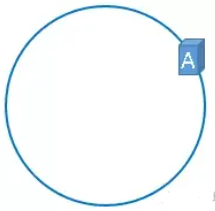
同理,服务器B与服务器C也可以通过相同的方法映射到上图中的hash环中。
hash(服务器B的IP地址) % 2^32
hash(服务器C的IP地址) % 2^32

到目前为止,我们已经把缓存服务器与hash环联系在了一起,我们通过上述方法,把缓存服务器映射到了hash环上,那么使用同样的方法,我们也可以将需要缓存的对象映射到hash环上。
假设,我们需要使用缓存服务器缓存图片,而且我们仍然使用图片的名称作为找到图片的key,那么我们使用如下公式可以将图片映射到上图中的hash环上。
hash(图片名称) % 2^32
映射后的示意图如下,下图中的橘黄色圆形表示图片。

现在服务器与图片都被映射到了hash环上。
那么上图中的这个图片到底应该被缓存到哪一台服务器上呢?
从图片的位置开始,沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的图片将会被缓存到服务器A上。
一致性哈希算法就是通过这种方法,判断一个对象应该被缓存到哪台服务器上的,将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存于的服务器,由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,一张图片必定会被缓存到固定的服务器上,那么,当下次想要访问这张图片时,只要再次使用相同的算法进行计算,即可算出这个图片被缓存在哪个服务器上,直接去对应的服务器查找对应的图片即可。

1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。
三、一致性哈希算法的优点
前面说过,如果简单的对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存的雪崩,从而很有可能导致系统崩溃。
那么使用一致性哈希算法,能够避免这个问题吗?
假设,服务器B出现了故障,我们现在需要将服务器B移除,那么,我们将上图中的服务器B从hash环上移除即可,移除服务器B以后示意图如下。

在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变。

但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别。
也就是说,某个服务器的下线只是会将原本将在该服务器上缓存的对象,沿顺时针顺延到下一个服务器,且该服务器的下线不会对其他的服务器产生影响。这就是一致性哈希算法的优点。
四、哈希环的偏斜
上面我们聊了一致性hash的优点,下面来说说它可能带来的问题 —— 哈希环的偏斜。
上面我们都是假设服务器的IP进行Hash取2^32的模后是均匀分布在环上的,但是实际中,可能会出现计算后的值很接近的情况,这会造成Hash环的偏斜问题,如下:

如果服务器被映射成上图中的模样(发生偏斜),那么被缓存的对象很有可能大部分集中缓存在某一台服务器上,如下图所示:

上图中,1号、2号、3号、4号、6号图片均被缓存在了服务器A上,只有5号图片被缓存在了服务器B上,服务器C上甚至没有缓存任何图片,如果出现上图中的情况,A、B、C三台服务器并没有被合理的平均的充分利用,缓存分布的极度不均匀,而且,如果此时服务器A出现故障,那么失效缓存的数量也将达到最大值,在极端情况下,仍然有可能引起系统的崩溃,上图中的情况则被称之为hash环的偏斜。
五、虚拟节点
怎样防止hash环的偏斜呢?一致性hash算法中使用虚拟节点解决了这个问题。
如果想要均衡的将缓存分布到3台服务器上,最好能让这3台服务器尽量多的、均匀的出现在hash环上,但是,真实的服务器资源只有3台,我们怎样凭空的让它们多起来呢,没错,就是凭空的让服务器节点多起来,既然没有多余的真正的物理服务器节点,我们就只能将现有的物理节点通过虚拟的方法复制出来,这些由实际节点虚拟复制而来的节点被称为"虚拟节点"。加入虚拟节点以后的hash环如下。

虚拟节点是实际节点(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节点。
具体做法可以在服务器ip或主机名的后⾯增加编号来实现。⽐如,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “节点1的ip#1”、“节点1的ip#2”、“节点1的ip#3”、“节点2的ip#1”、“节点2的ip#2”、“节点2的ip#3”的哈希值,于是形成六个虚拟节点。当客户端被路由到虚拟节点的时候其实是被路由到该虚拟节点所对应的真实节点。
从上图可以看出,A、B、C三台服务器分别虚拟出了一个虚拟节点,当然,如果你需要,也可以虚拟出更多的虚拟节点。
引入虚拟节点的概念后,缓存的分布就均衡多了,上图中,1号、3号图片被缓存在服务器A中,5号、4号图片被缓存在服务器B中,6号、2号图片被缓存在服务器C中,如果你还不放心,可以虚拟出更多的虚拟节点,以便减小hash环偏斜所带来的影响,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大。
六、一致性hash的特点
好的一致性算法需满足以下几个方面:
- 平衡性(Balance) 平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
- 单调性(Monotonicity) 单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
- 分散性(Spread) 在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
- 负载(Load) 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同
的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。- 平滑性(Smoothness) 平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
如果可以满足以上几个方面,则可以很低成本的增加、减少机器,这个分布式系统也就更加健壮。
七、典型应用场景
主要的应用场景归纳起来有两个:请求的负载均衡 和 分布式存储。
请求的负载均衡(⽐如nginx的ip_hash策略)
Nginx的ip_hash策略,可以在客户端IP不变的情况下,将其发出的请求路由到同一台目标服务器,实现会话粘滞,避免处理session共享问题。
分布式存储
就是上面三台服务器保存图片的例子。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号