
Redis的基本数据类型及其底层实现原理
最近去面试,面试官都会先问:Redis中有哪些数据类型?接着就会问Redis各种数据类型底层结构,会问如果要统计用户活跃数、用户登录数等有没有好的方案等等,现在一块来了解下。
一、Redis支持的数据类型
Redis 主要有以下几种数据类型:
String字符串对象Hash哈希Map对象List列表对象Set集合对象ZSet有序集合
还有三种特殊数据类型:
geospatial: Redis 在 3.2 推出 Geo 类型,该功能可以推算出地理位置信息,两地之间的距离。hyperloglog:基数:数学上集合的元素个数,是不能重复的。这个数据结构常用于统计网站的 UV。bitmap: bitmap 就是通过最小的单位 bit 来进行0或者1的设置,表示某个元素对应的值或者状态。一个 bit 的值,或者是0,或者是1;也就是说一个 bit 能存储的最多信息是2。bitmap 常用于统计用户信息比如活跃粉丝和不活跃粉丝、登录和未登录、是否打卡等。
补充说明:
基数是一种算法。举个例子 一本英文著作由数百万个单词组成,你的内存却不足以存储它们,那么我们先分析下业务。英文单词本身是有限的,在这本书的几百万个单词中有许许多多重复单词,扣去重复的单词,这本书中也就 千到 万多个单词而己,那么内存就足够存储它 了。比如数字集合{ l,2,5 1,5,9 }的基数集合为{ 1,2,5 }那么 基数(不重复元素)就是基数的作用是评估大约需要准备多少个存储单元去存储数据,基数并不是存储元素,存储元素消耗内存空间比较大,而是给某个有重复元素的数据集合( 般是很大的数据集合〉评估需要的空间单元数。

几种特殊类型的使用场景会在文末详细地补充介绍,请耐心看完。
二、redisObject对象
Redis存储的所有值对象在内部都定义为redisObject结构体,内部结构如下图所示:

Redis存储的包括string,hash,list,set,zset在内的所有数据类型,都使用redisObject来封装的。
下面针对每个字段做详细说明:
1.type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string,hash,list,set,zset。可以使用type {key}命令查看对象所属类型,type命令返回的是值对象类型,键都是string类型。
2.encoding字段:表示Redis内部编码类型,encoding在Redis内部使用,代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异,具体细节见之后编码优化部分。
3.lru字段:记录对象最后一次被访问的时间,当配置了 maxmemory和maxmemory-policy=volatile-lru | allkeys-lru 时,用于辅助LRU算法删除键数据。可以使用object idletime {key}命令在不更新lru字段情况下查看当前键的空闲时间。开发提示:可以使用scan + object idletime 命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理降低内存占用。
4.refcount字段:记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间。使用object refcount {key}获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存。具体细节见之后共享对象池部分。
5.ptr字段:与对象的数据内容相关,如果是整数直接存储数据,否则表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作。开发提示:高并发写入场景中,在条件允许的情况下建议字符串长度控制在39字节以内,减少创建redisObject内存分配次数从而提高性能。
可以简单的理解成下图:

每一种类型都有自己特有的数据结构,下面我们要探讨的就是每种数据类型的具体的底层结构。
三、String
- string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
- value其实不仅是String,也可以是数字
- string 类型是二进制安全的,可以包含任何数据,比如jpg图片或者序列化的对象
- string 类型的值最大能存储
512MB - 常用命令:
get、set、incr、decr、mget等
应用场景
常规key-value缓存应用。常规计数: 微博数, 粉丝数。
String 底层实现
字符串是我们日常工作中用得最多的对象类型,它对应的编码可以是int、raw和embstr。
通过 object encoding key 命令来查看具体的编码格式:

如果一个字符串对象保存的是不超过long类型的整数值,此时编码类型即为int,其底层数据结构直接就是long类型。例如执行set number 10086,就会创建int编码的字符串对象作为number键的值。

如果字符串对象保存的是一个长度大于39字节的字符串,此时编码类型即为raw,其底层数据结构是简单动态字符串(SDS)。
如果长度小于等于39个字节,编码类型则为embstr,底层数据结构就是embstr编码SDS。下面,我们详细理解下什么是简单动态字符串。
SDS
SDS是"simple dynamic string"的缩写。 redis中所有场景中出现的字符串,由SDS来实现。

free:还剩多少空间 len:字符串长度 buf:存放的字符数组。
在源码的 src目录下,找到了 sds.h 这样一个文件,规定了 SDS 的结构:
struct sdsshr<T>{
T len;//数组长度
T alloc;//数组容量
unsigned flags;//sdshdr类型
char buf[];//数组内容
}
可以看出,SDS 的结构有点类似于 Java 中的 ArrayList。buf[]表示真正存储的字符串内容,alloc 表示所分配的数组的长度,len 表示字符串的实际长度,并且由于 len 这个属性的存在,Redis 可以在 O(1)的时间复杂度内获取数组长度。
空间预分配
为减少修改字符串带来的内存重分配次数,sds采用了“一次管够”的策略:
- 若修改之后sds长度小于1MB,则多分配现有len长度的空间
- 若修改之后sds长度大于等于1MB,则扩充除了满足修改之后的长度外,额外多1MB空间
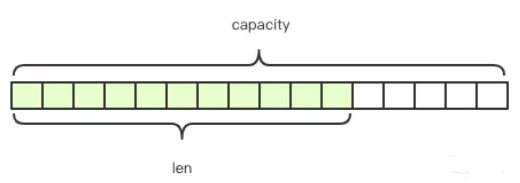
由于Redis的字符串是动态字符串,可以修改,内部结构类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。如上图所示,内部为当前字符串实际分配的空间capacity,一般高于实际字符串长度len。
假设我们要存储的结构是:
{
"name": "xiaowang",
"age": "35"
}
如果此时将此用户信息的name改为“xiaoli”,再存到redis中,redis是不需要重新分配空间的,使用已分配空间即可。
惰性空间释放
为避免缩短字符串时候的内存重分配操作,sds在数据减少时,并不立刻释放空间。
SDS与C字符串的区别
C语言使用长度为N+1的字符数组来表示长度为N的字符串,并且字符串的最后一个元素是空字符\0。Redis采用SDS相对于C字符串有如下几个优势:
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少修改字符串时带来的内存重分配次数
- 二进制安全
raw和embstr编码的SDS区别
长度大于39字节的字符串,编码类型为raw,底层数据结构是简单动态字符串(SDS)。
比如当我们执行set story "Long, long, long ago there lived a king ..."(长度大于39)之后,Redis就会创建一个raw编码的String对象。数据结构如下:

长度小于等于39个字节的字符串,编码类型为embstr,底层数据结构则是embstr编码SDS。
embstr编码是专门用来保存短字符串的,它和raw编码最大的不同在于:raw编码会调用两次内存分配分别创建redisObject结构和sdshdr结构,而embstr编码则是只调用一次内存分配,在一块连续的空间上同时包含redisObject结构和sdshdr`结构。

编码转换
int编码和embstr编码的字符串对象在条件满足的情况下会自动转换为raw编码的字符串对象。
- 对于int编码来说,当我们修改这个字符串为不再是整数值的时候,此时字符串对象的编码就会从int变为raw;
- 对于embstr编码来说,只要我们修改了字符串的值,此时字符串对象的编码就会从embstr变为raw。embstr编码的字符串对象可以认为是只读的,因为Redis为其编写任何修改程序。当我们要修改embstr编码字符串时,都是先将转换为raw编码,然后再进行修改。
Redis字符串结构特点
O(1)时间复杂度获取:字符串长度,已用长度,未用长度。- 可用于保存字节数组,支持安全的二进制数据存储。
- 内部实现空间预分配机制,降低内存再分配次数。
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
四、List
列表对象的编码可以是linkedlist或者ziplist,对应的底层数据结构是链表和压缩列表。
默认情况下,当列表对象保存的所有字符串元素的长度都小于64字节,且元素个数小于512个时,列表对象采用的是ziplist编码,否则使用linkedlist编码。可以通过配置文件修改该上限值。
链表
提供了高效的节点重排能力以及顺序性的节点访问方式。在Redis中,每个链表节点使用listNode结构表示:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点值
void *value;
} listNode
多个listNode通过prev和next指针组成双端链表,如下图所示:

为了操作起来比较方便,Redis使用了list结构持有链表。list结构为链表提供了表头指针head、表尾指针tail,以及链表长度计数器len,而dup、free和match成员则是实现多态链表所需类型的特定函数。
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表包含的节点数量
unsigned long len;
// 节点复制函数
void *(*dup)(void *ptr);
// 节点释放函数
void (*free)(void *ptr);
// 节点对比函数
int (*match)(void *ptr, void *key);
} list;

Redis链表实现的特征总结如下:
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(n)。
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以NULL为终点。
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)。
- 带链表长度计数器:程序使用list结构的len属性来对list持有的节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
- 多态:链表节点使用void*指针来保存节点值,可以保存各种不同类型的值。
压缩列表
压缩列表。 redis的列表键和哈希键的底层实现之一。此数据结构是为了节约内存而开发的。和各种语言的数组类似,它是由连续的内存块组成的,这样一来,由于内存是连续的,就减少了很多内存碎片和指针的内存占用,进而节约了内存。
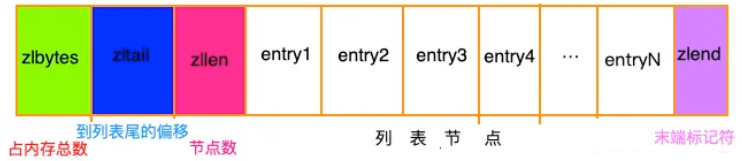
entry的结构是这样的:

压缩列表记录了各组成部分的类型、长度以及用途:

五、Hash
哈希对象的编码可以是ziplist或者hashtable。
哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节并且保存的键值对数量小于 512 个,使用ziplist 编码;否则使用hashtable;
hash-ziplist
ziplist底层使用的是压缩列表实现,前面已经详细介绍了压缩列表的实现原理。每当有新的键值对要加入哈希对象时,先把保存了键的节点推入压缩列表表尾,然后再将保存了值的节点推入压缩列表表尾。比如,我们执行如下三条HSET命令:
HSET profile name "tom"
HSET profile age 25
HSET profile career "Programmer"
如果此时使用ziplist编码,那么该Hash对象在内存中的结构如下:

hash-hashtable
hashtable 编码的哈希对象使用字典dictht作为底层实现。字典是一种保存键值对的数据结构。
typedef struct dictht{
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size-1
unsigned long sizemask;
// 该哈希表已有节点数量
unsigned long used;
} dictht
table属性是一个数组,数组中的每个元素都是一个指向dictEntry结构的指针,每个dictEntry结构保存着一个键值对。size属性记录了哈希表的大小,即table数组的大小。used属性记录了哈希表目前已有节点数量。sizemask总是等于size-1,这个值主要用于数组索引。比如下图展示了一个大小为4的空哈希表。

哈希表节点
哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
unit64_t u64;
nit64_t s64;
} v;
// 指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
key属性保存着键值对中的键,而v属性则保存了键值对中的值。值可以是一个指针,一个uint64_t整数或者是int64_t整数。next属性指向了另一个dictEntry节点,在数组桶位相同的情况下,将多个dictEntry节点串联成一个链表,以此来解决键冲突问题。(链地址法)
字典
Redis字典由dict结构表示:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
//rehash索引
// 当rehash不在进行时,值为-1
int rehashidx;
}
ht是大小为2,且每个元素都指向dictht哈希表。一般情况下,字典只会使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用。rehashidx记录了rehash的进度,如果目前没有进行rehash,值为-1。

rehash
为了使hash表的负载因子(ht[0]).used/ht[0]).size)维持在一个合理范围,当哈希表保存的元素过多或者过少时,程序需要对hash表进行相应的扩展和收缩。rehash(重新散列)操作就是用来完成hash表的扩展和收缩的。rehash的步骤如下:
- 为
ht[1]哈希表分配空间
如果是扩展操作,那么ht[1]的大小为第一个大于ht[0].used*2的2^n。比如ht[0].used=5,那么此时ht[1]的大小就为16。(大于10的第一个2^n的值是16)
如果是收缩操作,那么ht[1]的大小为第一个大于ht[0].used的2^n。比如ht[0].used=5,那么此时ht[1]的大小就为8。(大于5的第一个2^n的值是8) - 将保存在
ht[0]中的所有键值对rehash到ht[1]中。 - 迁移完成之后,释放掉
ht[0],并将现在的ht[1]设置为ht[0],在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
哈希表的扩展和收缩时机:
当服务器没有执行BGSAVE或者BGREWRITEAOF命令时,负载因子大于等于1触发哈希表的扩展操作。
当服务器在执行BGSAVE或者BGREWRITEAOF命令,负载因子大于等于5触发哈希表的扩展操作。
当哈希表负载因子小于0.1,触发哈希表的收缩操作。
渐进式rehash
前面讲过,扩展或者收缩需要将ht[0]里面的元素全部rehash到ht[1]中,如果ht[0]元素很多,显然一次性rehash成本会很大,从影响到Redis性能。为了解决上述问题,Redis使用了渐进式rehash技术,具体来说就是分多次,渐进式地将ht[0]里面的元素慢慢地rehash到ht[1]中。下面是渐进式rehash的详细步骤:
- 为
ht[1]分配空间。 - 在字典中维持一个索引计数器变量
rehashidx,并将它的值设置为0,表示rehash正式开始。 - 在
rehash进行期间,每次对字典执行添加、删除、查找或者更新时,除了会执行相应的操作之外,还会顺带将ht[0]在rehashidx索引位上的所有键值对rehash到ht[1]中,rehash完成之后,rehashidx值加1。 - 随着字典操作的不断进行,最终会在某个时刻迁移完成,此时将
rehashidx值置为-1,表示rehash结束。
渐进式rehash一次迁移一个桶上所有的数据,设计上采用分而治之的思想,将原本集中式的操作分散到每个添加、删除、查找和更新操作上,从而避免集中式rehash带来的庞大计算。
因为在渐进式rehash时,字典会同时使用ht[0]和ht[1]两张表,所以此时对字典的删除、查找和更新操作都可能会在两个哈希表进行。比如,如果要查找某个键时,先在ht[0]中查找,如果没找到,则继续到ht[1]中查找。
hash对象中的hashtable
HSET profile name "tom"
HSET profile age 25
HSET profile career "Programmer"
还是上述三条命令,保存数据到Redis的哈希对象中,如果采用hashtable编码保存的话,那么该Hash对象在内存中的结构如下:

六、Set
集合对象的编码可以是intset或者hashtable。
当集合对象保存的元素都是整数,并且个数不超过512个时,使用intset编码,否则使用hashtable编码。
set-intset
整数集合(intset)是Redis用于保存整数值的集合抽象数据结构,它可以保存类型为int16_t、int32_t或者int64_t的整数值,并且保证集合中的数据不会重复。Redis使用intset结构表示一个整数集合。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
contents数组是整数集合的底层实现:整数集合的每个元素都是contents数组的一个数组项,各个项在数组中按值大小从小到大有序排列,并且数组中不包含重复项。虽然contents属性声明为int8_t类型的数组,但实际上,contents数组不保存任何int8_t类型的值,数组中真正保存的值类型取决于encoding。如果encoding属性值为INTSET_ENC_INT16,那么contents数组就是int16_t类型的数组,以此类推。
当新插入元素的类型比整数集合现有类型元素的类型大时,整数集合必须先升级,然后才能将新元素添加进来。这个过程分以下三步进行。
- 根据新元素类型,扩展整数集合底层数组空间大小。
- 将底层数组现有所有元素都转换为与新元素相同的类型,并且维持底层数组的有序性。
- 将新元素添加到底层数组里面。
还有一点需要注意的是,整数集合不支持降级,一旦对数组进行了升级,编码就会一直保持升级后的状态。
举个栗子,当我们执行SADD numbers 1 3 5向集合对象插入数据时,该集合对象在内存的结构如下:

set-hashtable
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象对应一个集合元素,字典的值都是NULL。当我们执行SADD fruits "apple" "banana" "cherry"向集合对象插入数据时,该集合对象在内存的结构如下:

七、Zset
有序集合的编码可以是ziplist或者skiplist。
当有序集合保存的元素个数小于128个,且所有元素成员长度都小于64字节时,使用ziplist编码,否则,使用skiplist编码。
zset-ziplist
ziplist编码的有序集合使用压缩列表作为底层实现,每个集合元素使用两个紧挨着一起的两个压缩列表节点表示,第一个节点保存元素的成员(member),第二个节点保存元素的分值(score)。
压缩列表内的集合元素按照分值从小到大排列。如果我们执行ZADD price 8.5 apple 5.0 banana 6.0 cherry命令,向有序集合插入元素,该有序集合在内存中的结构如下:

zset-skiplist
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表。
typedef struct zset {
zskiplist *zs1;
dict *dict;
}
继续介绍之前,我们先了解一下什么是跳跃表。
跳跃表
跳跃表(skiplist)是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
Redis的跳跃表由zskiplistNode和zskiplist两个结构定义,zskiplistNode结构表示跳跃表节点,zskiplist保存跳跃表节点相关信息,比如节点的数量,以及指向表头和表尾节点的指针等。
跳跃表节点 zskiplistNode
跳跃表节点zskiplistNode结构定义如下:
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
下图是一个层高为5,包含4个跳跃表节点(1个表头节点和3个数据节点)组成的跳跃表:

- 每次创建一个新的跳跃表节点的时候,会根据幂次定律(越大的数出现的概率越低)随机生成一个1-32之间的值作为当前节点的"层高"。每层元素都包含2个数据,前进指针和跨度。
前进指针:每层都有一个指向表尾方向的前进指针,用于从表头向表尾方向访问节点。
跨度:层的跨度用于记录两个节点之间的距离。 - 后退指针(BW)
节点的后退指针用于从表尾向表头方向访问节点,每个节点只有一个后退指针,所以每次只能后退一个节点。 - 分值和成员
节点的分值(score)是一个double类型的浮点数,跳跃表中所有节点都按分值从小到大排列。节点的成员(obj)是一个指针,指向一个字符串对象。在跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点的分值确实可以相同。
需要注意的是,表头节点不存储真实数据,并且层高固定为32,从表头节点第一个不为NULL最高层开始,就能实现快速查找。
跳跃表 zskiplist
实际上,仅靠多个跳跃表节点就可以组成一个跳跃表,但是Redis使用了zskiplist结构来持有这些节点,这样就能够更方便地对整个跳跃表进行操作。比如快速访问表头和表尾节点,获得跳跃表节点数量等等。zskiplist结构定义如下:
typedef struct zskiplist {
// 表头节点和表尾节点
struct skiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大层数
int level;
} zskiplist;
下图是一个完整的跳跃表结构示例:

有序集合对象的skiplist实现
前面讲过,skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表。
typedef struct zset {
zskiplist *zs1;
dict *dict;
}
zset结构中的zs1跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素。通过跳跃表,可以对有序集合进行基于score的快速范围查找。zset结构中的dict字典为有序集合创建了从成员到分值的映射,字典的键保存了成员,字典的值保存了分值。通过字典,可以用O(1)复杂度查找给定成员的分值。
假如还是执行ZADD price 8.5 apple 5.0 banana 6.0 cherry命令向zset保存数据,如果采用skiplist编码方式的话,该有序集合在内存中的结构如下:

小结
Redis底层数据结构主要包括简单动态字符串(SDS)、链表、字典、跳跃表、整数集合和压缩列表六种类型,并且基于这些基础数据结构实现了字符串对象、列表对象、哈希对象、集合对象以及有序集合对象五种常见的对象类型。每一种对象类型都至少采用了2种数据编码,不同的编码使用的底层数据结构也不同。
以上数据结构也是下面进行Redis内存优化的基础。
八、Redis的内存优化
上面其实已经介绍了一些优化方法,比如:
- 高并发写入场景中,在条件允许的情况下建议字符串长度控制在39字节以内,减少创建redisObject内存分配次数从而提高性能。
- 可以使用
scan + object idletime命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理降低内存占用。
此外还可以从:
- 缩减键值对象
- 字符串优化
- 编码优化
- 控制key的数量
等方面进行redis的内存优化处理。
缩减键值对象
降低Redis内存使用最直接的方式就是缩减键(key)和值(value)的长度。
- key长度:如在设计键时,在完整描述业务情况下,键值越短越好。
- value长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二进制数组放入Redis。首先应该在业务上精简业务对象,去掉不必要的属性避免存储无效数据。其次在序列化工具选择上,应该选择更高效的序列化工具来降低字节数组大小。以JAVA为例,内置的序列化方式无论从速度还是压缩比都不尽如人意,这时可以选择更高效的序列化工具,如: protostuff,kryo等,下图是JAVA常见序列化工具空间压缩对比。
值对象除了存储二进制数据之外,通常还会使用通用格式存储数据比如:json,xml等作为字符串存储在Redis中。这种方式优点是方便调试和跨语言,但是同样的数据相比字节数组所需的空间更大,在内存紧张的情况下,可以使用通用压缩算法压缩json,xml后再存入Redis,从而降低内存占用,例如使用GZIP压缩后的json可降低约60%的空间。
共享对象池
对象共享池指Redis内部维护[0-9999]的整数对象池。创建大量的整数类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚至超过了整数自身空间消耗。所以Redis内存维护一个[0-9999]的整数对象池,用于节约内存。
除了整数值对象,其他类型如list,hash,set,zset内部元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整数对象以节省内存。整数对象池在Redis中通过变量REDIS_SHARED_INTEGERS定义,不能通过配置修改。可以通过object refcount命令查看对象引用数验证是否启用整数对象池技术,如下:
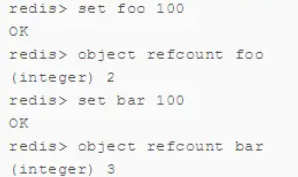
设置键foo等于100时,直接使用共享池内整数对象,因此引用数是2,再设置键bar等于100时,引用数又变为3,如下图所示。

使用整数对象池究竟能降低多少内存?让我们通过测试来对比对象池的内存优化效果,如下表所示。

使用共享对象池后,相同的数据内存使用降低30%以上。可见当数据大量使用[0-9999]的整数时,共享对象池可以节约大量内存。
需要注意的是对象池并不是只要存储[0-9999]的整数就可以工作。当设置maxmemory并启用LRU相关淘汰策略如:volatile-lru,allkeys-lru时,Redis禁止使用共享对象池,测试命令如下:

为什么开启maxmemory和LRU淘汰策略后对象池无效?
LRU算法需要获取对象最后被访问时间,以便淘汰最长未访问数据,每个对象最后访问时间存储在redisObject对象的lru字段。对象共享意味着多个引用共享同一个redisObject,这时lru字段也会被共享,导致无法获取每个对象的最后访问时间。如果没有设置maxmemory,直到内存被用尽Redis也不会触发内存回收,所以共享对象池可以正常工作。
综上所述,共享对象池与maxmemory+LRU策略冲突,使用时需要注意。 对于ziplist编码的值对象,即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高,ziplist编码细节后面内容详细说明。
为什么只有整数对象池?
首先整数对象池复用的几率最大,其次对象共享的一个关键操作就是判断相等性,Redis之所以只有整数对象池,是因为整数比较算法时间复杂度为O(1),只保留一万个整数为了防止对象池浪费。如果是字符串判断相等性,时间复杂度变为O(n),特别是长字符串更消耗性能(浮点数在Redis内部使用字符串存储)。对于更复杂的数据结构如hash,list等,相等性判断需要O(n2)。对于单线程的Redis来说,这样的开销显然不合理,因此Redis只保留整数共享对象池。
字符串优化
字符串重构:指不一定把每份数据作为字符串整体存储,像json这样的数据可以使用hash结构,使用二级结构存储也能帮我们节省内存。同时可以使用hmget,hmset命令支持字段的部分读取修改,而不用每次整体存取。
编码优化
Redis为什么需要对一种数据结构实现多种编码方式?
主要原因是Redis作者想通过不同编码实现效率和空间的平衡。比如当我们的存储只有10个元素的列表,当使用双向链表数据结构时,必然需要维护大量的内部字段如每个元素需要:前置指针,后置指针,数据指针等,造成空间浪费,如果采用连续内存结构的压缩列表(ziplist),将会节省大量内存,而由于数据长度较小,存取操作时间复杂度即使为O(n2)性能也可满足需求。
编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换。
控制key的数量
当使用Redis存储大量数据时,通常会存在大量键,过多的键同样会消耗大量内存。Redis本质是一个数据结构服务器,它为我们提供多种数据结构,如hash,list,set,zset 等结构。使用Redis时不要进入一个误区,大量使用get/set这样的API,把Redis当成Memcached使用。对于存储相同的数据内容利用Redis的数据结构降低外层键的数量,也可以节省大量内存。
如下图所示,通过在客户端预估键规模,把大量键分组映射到多个hash结构中降低键的数量。

根据键规模在客户端通过分组映射到一组hash对象中,如存在100万个键,可以映射到1000个hash中,每个hash保存1000个元素。hash的field可用于记录原始key字符串,方便哈希查找。hash的value保存原始值对象,确保不要超过hash-max-ziplist-value限制。下面测试这种优化技巧的内存表现,如下表所示。
Redis内存优化汇总
- 高并发写入场景中,在条件允许的情况下建议字符串长度控制在39字节以内,减少创建redisObject内存分配次数从而提高性能。
- 可以使用
scan + object idletime命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理降低内存占用。 - 可以使用通用压缩算法压缩json,xml后再存入Redis,从而降低内存占用,例如使用GZIP压缩后的json可降低约60%的空间。(当频繁压缩解压json等文本数据时,开发人员需要考虑压缩速度和计算开销成本,这里推荐使用google的Snappy压缩工具,在特定的压缩率情况下效率远远高于GZIP等传统压缩工具,且支持所有主流语言环境。)
- 开发中在满足需求的前提下,尽量使用整数对象以节省内存(共享对象池)。
- 使用Redis时不要进入一个误区,大量使用get/set这样的API,把Redis当成Memcached使用。对于存储相同的数据内容利用Redis的数据结构降低外层键的数量,也可以节省大量内存。
- 使用ziplist+hash优化keys后,如果想使用超时删除功能,开发人员可以存储每个对象写入的时间,再通过定时任务使用hscan命令扫描数据,找出hash内超时的数据项删除即可。
Redis的数据特性是ALL IN MEMORY,优化内存将变得非常重要。对于内存优化建议先要掌握Redis内存存储的特性比如字符串,压缩编码,整数集合等,再根据数据规模和所用命令需求去调整,从而达到空间和效率的最佳平衡。建议使用Redis存储大量数据时,把内存优化环节加入到前期设计阶段,否则数据大幅增长后,开发人员需要面对重新优化内存所带来开发和数据迁移的双重成本。当Redis内存不足时,首先考虑的问题不是加机器做水平扩展,应该先尝试做内存优化。当遇到瓶颈时,再去考虑水平扩展。即使对于集群化方案,垂直层面优化也同样重要,避免不必要的资源浪费和集群化后的管理成本。
九、Redis的布隆过滤器
布隆过滤器是什么?
布隆过滤器是一个神奇的数据结构,可以用来判断一个元素是否在一个集合中。很常用的一个功能是用来去重。
在爬虫中常见的一个需求:目标网站 URL 千千万,怎么判断某个 URL 爬虫是否宠幸过?简单点可以爬虫每采集过一个 URL,就把这个 URL 存入数据库中,每次一个新的 URL 过来就到数据库查询下是否访问过。
但是随着爬虫爬过的 URL 越来越多,每次请求前都要访问数据库一次,并且对于这种字符串的 SQL 查询效率并不高。除了数据库之外,使用 Redis 的 set 结构也可以满足这个需求,并且性能优于数据库。
但是 Redis 也存在一个问题:耗费过多的内存。
这个时候布隆过滤器就有用了。相比于数据库和 Redis,使用布隆过滤器可以很好的避免性能和内存占用的问题。
布隆过滤器原理
布隆过滤器本质是一个位数组,位数组就是数组的每个元素都只占用 1 bit ,每个元素只能是 0 或者 1。这样申请一个 10000 个元素的位数组只占用 10000 / 8 = 1250 B 的空间。
布隆过滤器除了一个位数组,还有 K 个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1
假设布隆过滤器有 3 个哈希函数:f1, f2, f3 和一个位数组 arr。现在要把 https://jaychen.cc 插入布隆过滤器中:
- 对值进行三次哈希计算,得到三个值
n1, n2, n3。 - 把位数组中三个元素
arr[n1], arr[n2], arr[n3]置为 1。
当要判断一个值是否在布隆过滤器中,对元素再次进行哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
上面的原理其实是有漏洞的:当插入的元素原来越多,位数组中被置为 1 的位置就越多,当一个不在布隆过滤器中的元素,经过哈希计算之后,得到的值在位数组中查询,有可能这些位置也都被置为 1。这样一个不存在布隆过滤器中的也有可能被误判成在布隆过滤器中。但是如果布隆过滤器判断说一个元素不在布隆过滤器中,那么这个值就一定不在布隆过滤器中。
也就是说:
- 布隆过滤器说某个元素在,可能会被误判。
- 布隆过滤器说某个元素不在,那么一定不在。
Redis 中的布隆过滤器
redis 在 4.0 的版本中加入了 module 功能,布隆过滤器可以通过 module 的形式添加到 redis 中,所以使用 redis 4.0 以上的版本可以通过加载 module 来使用 redis 中的布隆过滤器。但是这不是最简单的方式,使用 docker 可以直接在 redis 中体验布隆过滤器。
> docker run -d -p 6379:6379 --name bloomfilter redislabs/rebloom
> docker exec -it bloomfilter redis-cli
redis 布隆过滤器主要就两个命令:
bf.add添加元素到布隆过滤器中:bf.add urls https://jaychen.cc。bf.exists判断某个元素是否在过滤器中:bf.exists urls https://jaychen.cc。
上面说过布隆过滤器存在误判的情况,在 redis 中有两个值决定布隆过滤器的准确率:
error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve urls 0.01 100
三个参数的含义:
第一个值是过滤器的名字。 第二个值为 error_rate 的值。 第三个值为 initial_size 的值。
使用这个命令要注意一点:执行这个命令之前过滤器的名字应该不存在,如果执行之前就存在会报错:(error) ERR item exists
十、补充
补充一、Redis中bitmap的妙用
bitmap本身会极大的节省储存空间,一个bit位来表示某个元素对应的值或者状态。
redis通过setbit命令实现bitmap存储:
SETBIT key offset value
以上命令的含义是,设置或者清空key在offset处的bit值(value只能是0或者1)。
使用场景
使用场景有如下几种:
(1)用户签到
很多网站都提供了签到功能(这里不考虑数据落地事宜),并且需要展示最近一个月的签到情况:
根据日期 offset =hash % 365 ; key = 年份#用户id
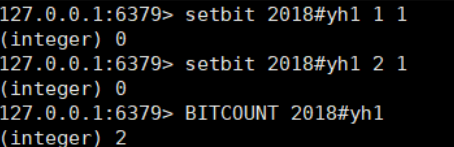
(2)统计活跃用户
使用时间作为key,然后用户ID为offset,如果当日活跃过就设置为1
如果计算某几天/月/年的活跃用户,可以使用下面的命令:
BITOP operation destkey key [key ...]
是对一个或多个 key 进行位元操作,并将结果保存到 destkey 上,BITOP 命令支持 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种参数。
例如:
统计20190216~20190217 总活跃用户数:1

统计20190216~20190217 在线活跃用户数:2

(3)用户在线状态
设置一个key,然后用户ID为offset,如果在线就设置为1,不在线就设置为0,和上面的场景一样,5000W用户只需要6MB的空间。
====================================================================
补充二、Redis中HyperLogLog的妙用
Redis 为 HyperLogLog提供了三个命令:PFADD、PFCOUNT、PFMERGE
PFADD
将任意数量的元素添加到指定的 HyperLogLog 里面,如果 HyperLogLog 估计的近似基数在命令执行之后出现了变化, 那么命令返回 1 , 否则返回 0 。如果命令执行时给定的键不存在, 那么程序将先创建一个空的 HyperLogLog 结构, 然后再执行命令。
# 命令格式:PFADD key element [element …]
# 如果给定的键不存在,那么命令会创建一个空的 HyperLogLog,并向客户端返回 1
127.0.0.1:6379> PFADD ip_20220301 "192.168.0.1" "192.168.0.2" "192.168.0.3"
(integer) 1
# 元素估计数量没有变化,返回 0(因为 192.168.0.1 已经存在)
127.0.0.1:6379> PFADD ip_20220301 "192.168.0.1"
(integer) 0
# 添加一个不存在的元素,返回 1。注意,此时 HyperLogLog 内部存储会被更新,因为要记录新元素
127.0.0.1:6379> PFADD ip_20220301 "192.168.0.4"
(integer) 1
PFCOUNT
- 作用于单个键时,返回储存在给定键的 HyperLogLog 的近似基数,如果键不存在,那么返回 0
- 作用于多个键时,返回所有给定 HyperLogLog 的并集的近似基数,这个近似基数是通过将所有给定 HyperLogLog 合并至一个临时 HyperLogLog 来计算得出
# 返回 ip_20220301 包含的唯一元素的近似数量
127.0.0.1:6379> PFCOUNT ip_20220301
(integer) 4
127.0.0.1:6379> PFADD ip_20220301 "192.168.0.5"
(integer) 1
127.0.0.1:6379> PFCOUNT ip_20220301
(integer) 5
127.0.0.1:6379> PFADD ip_20220302 "192.168.0.1" "192.168.0.6" "192.168.0.7"
(integer) 1
# 返回 ip_20220301 和 ip_20220302 包含的唯一元素的近似数量
127.0.0.1:6379> PFCOUNT ip_20220301 ip_20220302
(integer) 7
PFMERGE
将多个 HyperLogLog 合并(merge)为一个 HyperLogLog,合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合(observed set)的并集。
合并得出的 HyperLogLog 会被储存在 destkey 键里面,如果该键并不存在,那么命令在执行之前,会先为该键创建一个空的 HyperLogLog。
# 命令格式:PFMERGE destkey sourcekey [sourcekey …]
# ip_2022030102 是 ip_20220301 与 ip_20220302 并集
127.0.0.1:6379> PFMERGE ip_2022030102 ip_20190301 ip_20220302
OK
127.0.0.1:6379> PFCOUNT ip_2022030102
(integer) 7
使用场景
HyperLogLog 不保存数据内容的特性,所以只适用于一些特定的场景:计算日活、7日活、月活数据。
例如:
如果我们通过解析日志,把 ip 信息(或用户 id)放到集合中,例如:HashSet。如果数量不多则还好,但是假如每天访问的用户有几百万。无疑会占用大量的存储空间。且计算月活时,还需要将一个整月的数据放到一个 Set 中,这随时可能导致我们的程序 OOM。
有了 HyperLogLog,这件事就变得很简单了。因为存储日活数据所需要的内存只有 12K,例如:
ip_20220301
ip_20220302
ip_20220303
...
ip_20220331
计算某一天的日活,只需要执行 PFCOUNT ip_202203XX 就可以了。每个月的第一天,执行 PFMERGE 将上一个月的所有数据合并成一个 HyperLogLog,例如:ip_202203。再去执行 PFCOUNT ip_202203,就得到了 3 月的月活。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· DeepSeek R1 简明指南:架构、训练、本地部署及硬件要求
· NetPad:一个.NET开源、跨平台的C#编辑器