简单易用的任务队列-beanstalkd
概述
beanstalkd 是一个简单快速的分布式工作队列系统,协议基于 ASCII 编码运行在 TCP 上。其最初设计的目的是通过后台异步执行耗时任务的方式降低高容量 Web 应用的页面延时。其具有简单、轻量、易用等特点,也支持对任务优先级、延时/超时重发等控制,同时还有众多语言版本的客户端支持,这些优点使得它成为各种需要队列系统场景的一种常见选择。
beanstalkd 优点
- 如他官网的介绍,simple&fast,使用非常简单,适合需要引入消息队列又不想引入 kafka 这类重型的 mq,维护成本低;同时,它的性能非常高,大部分场景下都可以 cover 住。
- 支持持久化
- 支持消息优先级,topic,延时消息,消息重试等
- 主流语言客户端都支持,还可以根据 beanstalkd 协议自行实现。
beanstalkd 不足
- 无最大内存控制,当业务消息极多时,服务可能会不稳定。
- 官方没有提供集群故障切换方案(主从或哨兵等),需要自己解决。
beanstalkd 重点概念
- job
任务,队列中的基本单元,每个 job 都会有 id 和优先级。有点类似其他消息队列中的 message 的概念。但 job 有各种状态,下文介绍生命周期部分会重点介绍。job 存放在 tube 中。
- tube
管道,用来存储同一类型的 job。有点类似其他消息队列中的 topic 的概念。beanstalkd 通过 tube 来实现多任务队列,beanstalkd 中可以有多个管道,每个管道有自己的 producer 和 consumer,管道之间互相不影响。
- producer
job 生产者。通过 put 命令将一个 job 放入到一个 tube 中。
- consumer
job 消费者。通过 reserve 来获取 job,通过 delete、release、bury 来改变 job 的状态。
beanstalkd 生命周期
上文介绍到,beanstalkd 中 job 有状态区分,在整个生命周期中,job 可能有四种状态:READY, RESERVED, DELAYED, BURIED。只有处于READY状态的 job 才能被消费。下图介绍了各状态之间的流转情况。
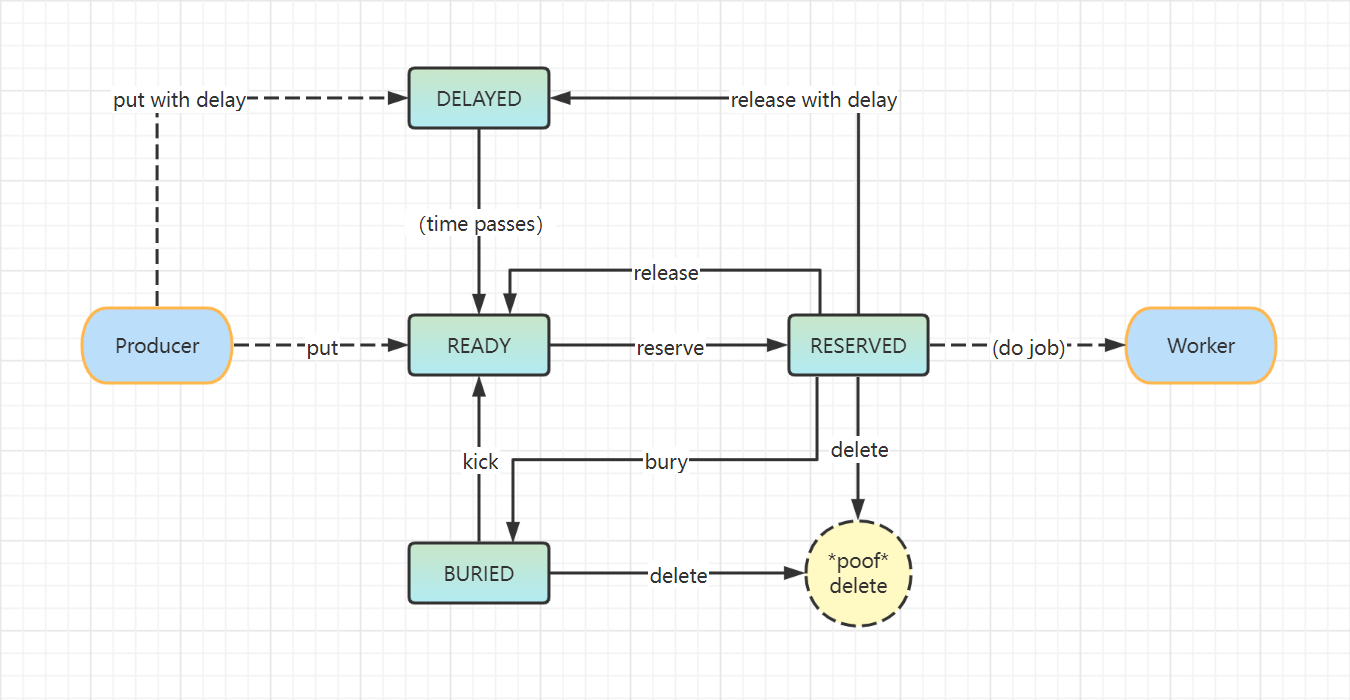
producer 在创建 job 的时候有两种方式,put 和 put with delay(延时任务)。
如果 producer 使用 put 直接创建一个 job 时,该 job 就处于 READY 状态,等待 consumer 处理。
如果 producer 使用 put with delay 方式创建 job,该 job 的初始状态为 DELAYED 状态,等待延迟时间过后才变更为 READY 状态。
以上两种方式创建的 job 都会传入一个 TTR(超时机制),当 job 处于 RESERVED 状态时,TTR 开始倒计时,当 TTR 倒计时完,job 状态还没有改变,则会认为该 job 处理失败,会被重新放回到队列中。
consumer 获取到(reserve)一个 READY 状态的 job 之后,该 job 的状态就会变更为 RESERVED。此时,其他的 consumer 就不能再操作该 job 了。当 consumer 完成该 job 之后,可以选择 delete,release,或 bury 操作。
- delete ,job 被删除,从 beanstalkd 中清除,以后也无法再获取到,生命周期结束。
- release ,可以把该 job 重新变更为 READY 状态,使得其他的 consumer 可以继续获取和执行该 job,也可以使用 release with delay 延时操作,这样会先进入 DELAYED 状态,延迟时间到达后再变为 READY。
- bury,可以将 job 休眠,等需要的时候,在将休眠的 job 通过 kick 命令变更回 READY 状态,也可以通过 delete 直接删除 BURIED 状态的 job 。
处于 BURIED 状态的 job,可以通过 kick 重回 READY 状态,也可以通过 delete 删除 job。
为什么设计这个 BURIED 状态呢?
一般我们可以用这个状态来做异常捕获,例如执行超时或者异常的 job,我们可以将其置为 BURIED 状态,这样做有几个好处:
1.可以便面这些异常的 job 直接被放回队列重试,影响正常的队列消费(这些失败一次的 job,很有可能再次失败)。如果没有这个 BURIED 状态,如果我们要单独隔离,一般我们会使用一个新的 tube 单独存放这些异常的 job,使用单独的 consumer 消费。这样就不会影响正常的新消息消费。特别是失败率比较高的时候,会占用很多的正常资源。
2.便于人工排查,上面已经讲到,可以将异常的 job 置为 BURIED 状态,这样人工排查时重点关注这个状态就可以了。
beanstalkd 特性
持久化
通过 binlog 将 job 及其状态记录到本地文件,当 beanstalkd 重启时,可以通过读取 binlog 来恢复之前的 job 状态。
分布式
在 beanstalkd 的文档中,其实是支持分布式的,其设计思想和 Memcached 类似,beanstalkd 各个 server 之间并不知道彼此的存在,是通过 client 实现分布式以及根据 tube 名称去特定的 server 上获取 job。贴一篇专门讨论 beanstalkd 分布式的文章,Beanstalkd的一种分布式方案
任务延时
天然支持延时任务,可以在创建 job 时指定延时时间,也可以当 job 被处理完后才能后,消费者使用 release with delay 将 job 再次放入队列延时执行。
任务优先级
producer 生成的 job 可以给他分配优先级,支持 0 到 2^32 的优先级,值越小,优先级越高,默认优先级为 1024。优先级高的 job 会被 consumer 优先执行。
超时机制
为了防止某个 consumer 长时间占用 job 但无法处理完成的情况,beanstalkd 的 reserve 操作支持设置 timeout 时间(TTR)。如果 consumer 不能在 TTR 内发送 delete、release 或 bury 命令改变 job 状态,那么 beanstalkd 会认为任务处理失败,会将 job 重新置为 READY 状态供其他 consumer 消费。
如果消费者已经预知可能无法在 TTR 内完成该 job,则可以发送 touch 命令,使得 beanstalkd 重新计算 TTR。
任务预留
有一个 BURIED 状态可以作为缓冲,具体特点见上文生命周期中关于 BURIED 状态的介绍。
安装及配置
以下以 ubuntu 为例,安转 beanstalkd:
sudo apt-get update
sudo apt-get install beanstalkd
vi /etc/sysconfig/beanstalkd
# 添加如下内容
BEANSTALKD_BINLOG_DIR=/data/beanstalkd/binlog
可以通过 beanstalkd 命令来运行服务,并且可以添加多种参数。命令的格式如下:
beanstalkd [OPTIONS]
-b DIR wal directory
-f MS fsync at most once every MS milliseconds (use -f0 for "always fsync")
-F never fsync (default)
-l ADDR listen on address (default is 0.0.0.0)
-p PORT listen on port (default is 11300)
-u USER become user and group
-z BYTES set the maximum job size in bytes (default is 65535)
-s BYTES set the size of each wal file (default is 10485760)
(will be rounded up to a multiple of 512 bytes)
-c compact the binlog (default)
-n do not compact the binlog
-v show version information
-V increase verbosity
-h show this help
如下我们启动一个 beanstalkd 服务,并开启 binlog:
nohup beanstalkd -l 0.0.0.0 -p 11300 -b /data/beanstalkd/binlog/ &
beanstalkd管理工具
官方推荐的一些管理工具:Tools
笔者常用的管理工具:https://github.com/ptrofimov/beanstalk_console
如果只是简单的操作和查看 beanstalkd,可以使用 telnet 工具,然后执行 stats,use,put,watch 等:
$ telnet 127.0.0.1 11300
stats
实际应用
beansralkd 有很多语言版本的客户端实现,官方提供了一些客户端列表beanstalkd客户端列表。
如果现有的这些库不满足需求,也可以自行实现,参考 beanstalkd协议。
以下以 go 为例,简单演示下 beanstalkd 常用处理操作。
go get github.com/beanstalkd/go-beanstalk
生产者
向默认的 tube 中投入 job:
id, err := conn.Put([]byte("myjob"), 1, 0, time.Minute)
if err != nil {
panic(err)
}
fmt.Println("job", id)
向指定的 tube 中投入 job:
tube := &beanstalk.Tube{Conn: conn, Name: "mytube"}
id, err := tube.Put([]byte("myjob"), 1, 0, time.Minute)
if err != nil {
panic(err)
}
fmt.Println("job", id)
消费者
消费默认的 tube 中的 job:
id, body, err := conn.Reserve(5 * time.Second)
if err != nil {
panic(err)
}
fmt.Println("job", id)
fmt.Println(string(body))
消费指定的 tube (此处指定多个) 中的 job:
tubeSet := beanstalk.NewTubeSet(conn, "mytube1", "mytube2")
id, body, err := tubeSet.Reserve(10 * time.Hour)
if err != nil {
panic(err)
}
fmt.Println("job", id)
fmt.Println(string(body))
beanstalkd 使用小 tips
- 可以通过指定 tube ,在 put 的时候将 job 放入指定的 tube 中,否则会放入 default 的 tube 中。
- beanstalkd 支持持久化,在启动时使用
-b参数来开启binlog,通过binog可以将 job 及其状态记录到文件里。当重新使用-b参数重启 beanstalkd,将读取binlog来恢复之前的 job 及状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号