DP系列-最长公共子序列
原题意:
给定两个字符串s1和s2,返回这两个字符串的最长公共子序列的长度,如果不存在则返回0。子序列是不连续的顺序列,如ace是abcde的子序列,aec就不是
示例1:
s1 = "abced", s2 = "acef"
s1和s2的最长的公共子序列是ace,所以最长公共子序列的长度为3。
示例2:
s1 = "abc", s2 = "def"
s1和s2没有公共子序列,所以长度为0。
常规尝试
首先使用递归进行尝试,定义s1的长度为m,s2的长度为n,定义函数f(i, j)为s1前i个字符和s2前j个字符中最长的公共子序列的长度。在s1的i位置和s2的j位置上的字符,有两种选择:

即:
1、当s1的i位置上的字符等于s2的j位置上的字符时,长度加1,然后再递归比较s1的i+1位置和s2的j+1位置的字符。
2、当不相等时,分两种情况,第一种s1的i+1位置和s2的j位置比较,第二种s1的i位置和s2的j+1位置比较,因为要取最长的,所以使用max求两种情况的最大值。
当i=0,j=0时,s1[0]==s2[0],然后递归去i+1和j+1的位置,最长长度为1。
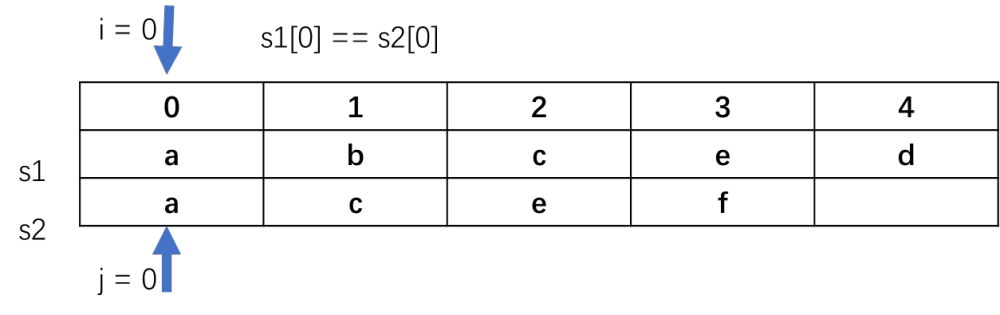
当i=1,j=1时,s1[1] != s2[1],递归去i和j+1,或者i+1和j的位置,然后取两者的最大值,最长长度为1。
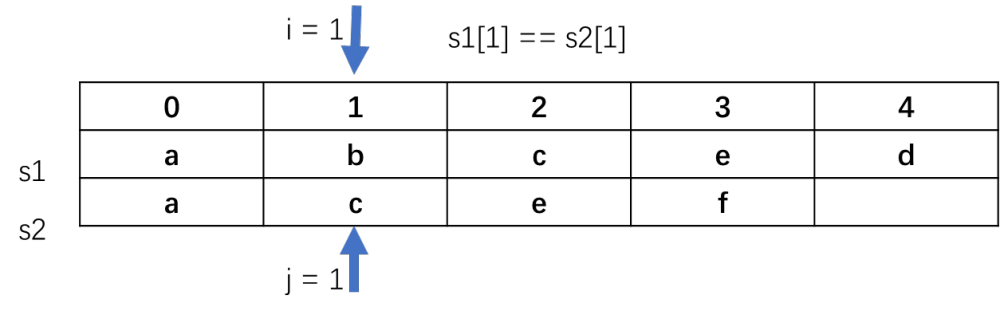
可以看出i=2并且j=1时,s1[2]==s2[1],当i=1并且j=2时,s1[1]!=s2[2],所以继续递归i=2和j=1,并且长度加1,变为2。

i=1并且j=2时,s1[1]!=s2[2]
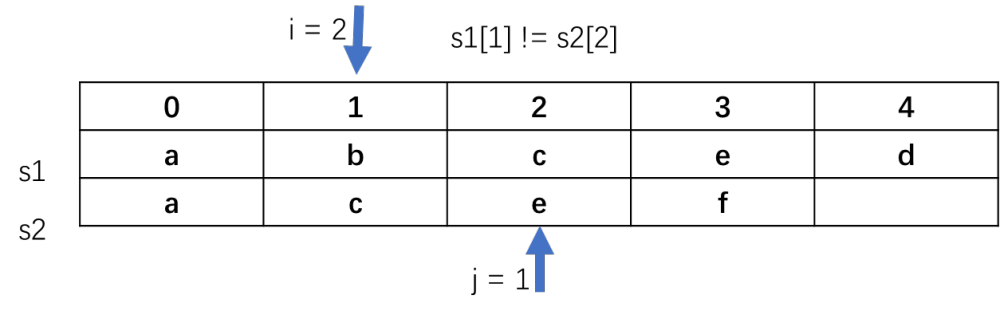
当i=3并且j=2时,s1[3]==s2[2],长度加1,变为3,再递归i+1和j+1位置。
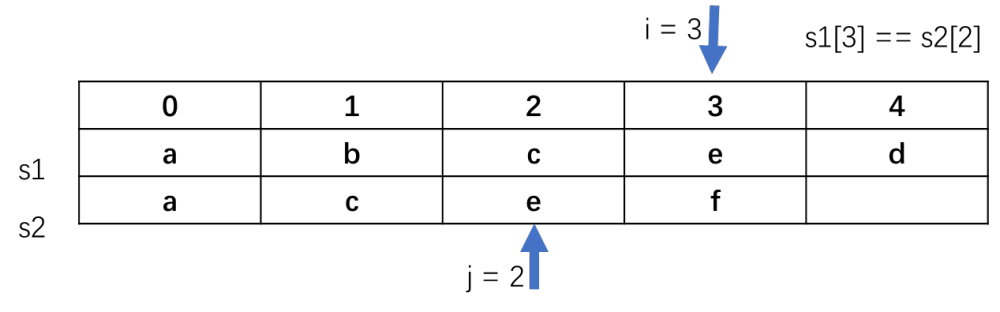
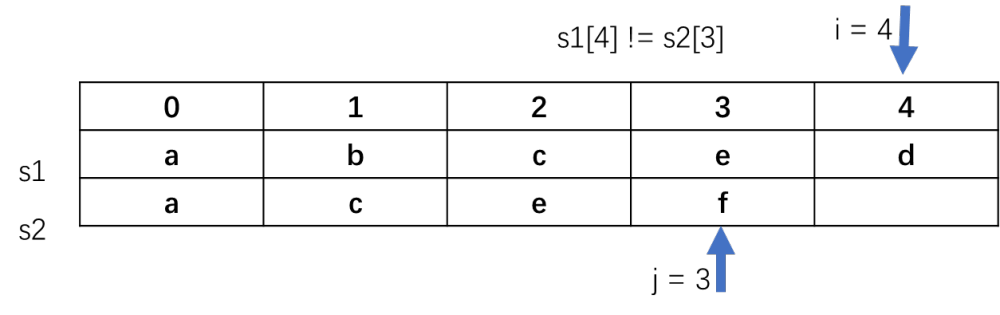
当i=4时j=3时, s1[4]!=s2[3]此时i已经来到了s1的末尾,最终最长长度为3。
根据推导过程写出代码:
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
return self.process(text1, text2, 0, 0)
def process(self, s1, s2, i, j):
"""
s1前i个字符和s2前j个字符中最长的公共子序列的长度
"""
# 当达到其中一个字符串的末尾时,递归结束
if len(s1) == i or len(s2) == j:
return 0
# 当s1[i]和s2[j]字符相同时,长度加1,然后去各自去下一位进行比较
if s1[i] == s2[j]:
return 1 + self.process(s1, s2, i + 1, j + 1)
# s1[i]不等于s2[j]时,分两种并列的可能,s1的下一位和s2的当前位置
# 与s1的当前位置和s2的下一位,比较后取较大的一个
p1 = self.process(s1, s2, i + 1, j)
p2 = self.process(s1, s2, i, j + 1)
return max(p1, p2)
分析下,递归的深度就是空间复杂度,时间复杂度是 ,其中T是每个递归的时间复杂度,depth是深度,则时间复杂度
,其中T是每个递归的时间复杂度,depth是深度,则时间复杂度 ,空间复杂度为O(m+n)。这样数据量大的时候,非常耗时的,因为有很多重复的运算,解决办法就是加缓存,让重复的计算只进行一次。
,空间复杂度为O(m+n)。这样数据量大的时候,非常耗时的,因为有很多重复的运算,解决办法就是加缓存,让重复的计算只进行一次。
记忆化搜索
分析下process函数中只有i和j的变化会得到不同的结果,所以定义二维数组cache,初始化为None,长宽分别为s1的长度m和s2的长度n,因为字符串索引从0开始,所以字符串的长度可以包含所有字符串。
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
m = len(text1)
n = len(text2)
cache = [[None] * n for _ in range(m)]
return self.process(text1, text2, 0, 0, cache)
def process(self, s1, s2, i, j, cache):
# 当达到其中一个字符串的末尾时,递归结束
if len(s1) == i or len(s2) == j:
return 0
# 当cache[i][j]为None的时候,说明还没有计算过,计算后再返回
if cache[i][j] is None:
if s1[i] == s2[j]:
cache[i][j] = 1 + self.process(s1, s2, i + 1, j + 1, cache)
else:
p1 = self.process(s1, s2, i + 1, j, cache)
p2 = self.process(s1, s2, i, j + 1, cache)
cache[i][j] = max(p1, p2)
# cache[i][j]已经计算过,直接返回
return cache[i][j]
动态规划
可以根据递归的尝试来画出动态规划的转移,从递归可以看出,我们设置一个二维数组dp,dp[i][j]表示s1从第i个字符开始到末尾,s2从第j个字符开始到末尾,最长的公共子序列的长度,dp[i][j]依赖i+1、j+1位置的值,所以我们填表的时候从下往上,从右往左,这样计算dp[i][j]位置时,i+1和j+1的位置已经计算出来了,可以直接使用。
转换图如下:

状态转移
if s1[i] == s2[j]:
dp[i][j] = 1 + dp[i+1][j+1]
else:
dp[i][j] = max(dp[i+1][j], dp[i][j+1])
当i来到s1的末尾时,或者j来到s2的末尾时,两者最长的公共子序列长度为0,最后dp[0][0]就是最终的结果,表示s1从第0个字符开始到末尾,s2从第0个字符开始到末尾,最长的公共子序列的长度。根据填表的顺序写出代码:
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
m = len(text1)
n = len(text2)
# python中定义二维数组
dp = [[0] * (n + 1) for _ in range(m + 1)]
return self.process(text1, text2, m, n, dp)
def process(self, s1, s2, m, n, dp):
# 从下向上遍历
for i in range(m - 1, -1, -1):
# 从右向左遍历
for j in range(n - 1, -1, -1):
if s1[i] == s2[j]:
dp[i][j] = 1 + dp[i + 1][j + 1]
else:
dp[i][j] = max(dp[i + 1][j], dp[i][j + 1])
return dp[0][0]
这样时间复杂度为 ,空间复杂度为
,空间复杂度为 。
。
滚动数组
从动态规划的代码中可以看出,每次dp[i][j]其实只依赖前面一行的数据,再之前的数据已经不会再参与计算了,所以可以使用滚动数组,再次优化空间。
自下而上
以上所有的过程是常规尝试的,也称之为自上而下的,我们最长见的都是自下而上的,就是我们要解决当前问题,先解决他的子问题。想知道s1前i个字符和s2前j个字符中最长的公共子序列的长度,只需要知道s1前i-1个字符和s2前j-1个字符的最长公共子序列的长度,再加1即可。
递归代码
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
return self.process(text1, text2, len(text1), len(text2))
def process(self, s1, s2, m, n):
"""
表示s1前m个字符和s2前n个字符中最长的公共子序列的长度
"""
if m == 0 or n == 0:
return 0
if s1[m - 1] == s2[n - 1]:
return self.process(s1, s2, m - 1, n - 1) + 1
p1 = self.process(s1, s2, m - 1, n)
p2 = self.process(s1, s2, m, n - 1)
return max(p1, p2)
动态规划
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
m = len(text1)
n = len(text2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
return self.process(text1, text2, m, n, dp)
def process(self, s1, s2, m, n, dp):
# dp[i][j] 表示s1前i个字符和s2前j个字符中最长的公共子序列的长度
for i in range(1, m + 1):
for j in range(1, n + 1):
if s1[i - 1] == s2[j - 1]:
dp[i][j] = 1 + dp[i - 1][j - 1]
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]
