
软工实践寒假作业(2/2)
 疫情统计程序
疫情统计程序
| 这个作业属于哪个课程 | 2020春|S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | GitHub使用、Java编程、项目管理、单元测试 |
| 作业正文 | 疫情统计程序 |
| 其他参考文献 | GitHub、CSDN、博客园 |
1. GitHub仓库
2.《构建之法》学习
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 180 |
| Estimate | 估计这个任务需要多少时间 | 3500 | 3500 |
| Development | 开发 | 1440 | 1080 |
| Analysis | 需求分析(包括学习新技术) | 540 | 225 |
| Design Spec | 生成设计文档 | 120 | 120 |
| Design Review | 设计复审 | 90 | 60 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 90 |
| Design | 具体设计 | 240 | 300 |
| Coding | 具体编码 | 360 | 720 |
| Code Review | 代码复审 | 120 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 240 |
| Reporting | 报告 | 600 | 720 |
| Test Repor | 测试报告 | 120 | 120 |
| Size Measurement | 计算工作量 | 60 | 60 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 40 |
| All | 合计 | 4110 | 4075 |
3. 解题思路
日志文本整理
- 四种患者类型:感染患者、疑似患者、治愈、死亡;可能出现的省、自治区、直辖市(没有包含特别行政区和台湾省)共31个。因此我建立一个类来囊括这些属性:
public class Lib {
public static final String str1 = "感染患者";
public static final String str2 = "疑似患者";
public static final String str3 = "治愈";
public static final String str4 = "死亡";
public static List<String> citiesList = new ArrayList<String>();
...
}
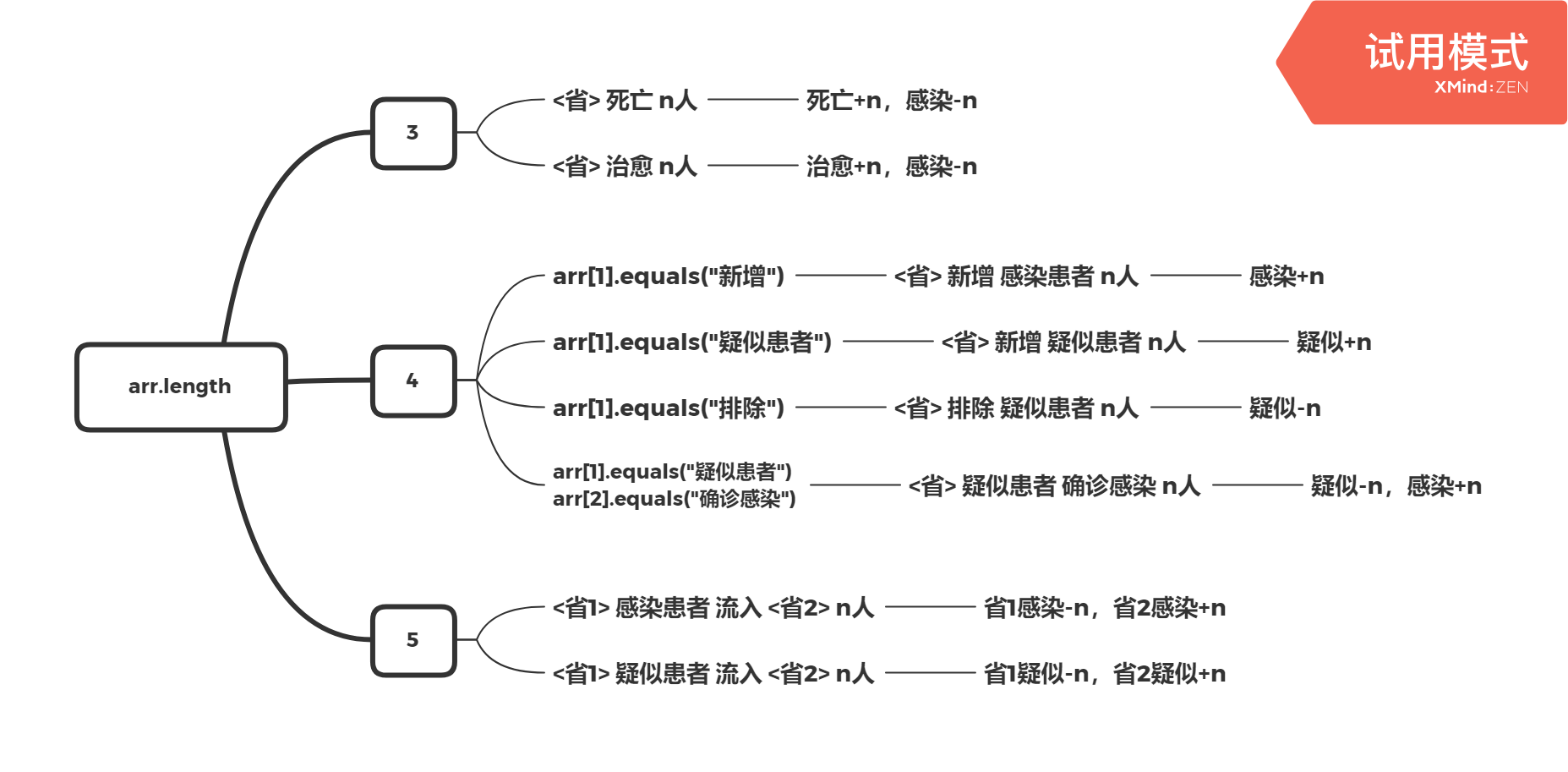
- 八种感染情况,可用split方法对文档的每一行根据空格进行分割为数组,经过查看,数组长度只有三种类型。因此,对八种感染情况的判断就可以简化为三种,然后再增加判断条件对每一种进行细分:
String[] arr = line.split("\\s{1,}");
| 情况 | 数组长度 |
|---|---|
| <省> 死亡 n人 | 3 |
| <省> 治愈 n人 | 3 |
| <省> 新增 感染患者 n人 | 4 |
| <省> 新增 疑似患者 n人 | 4 |
| <省> 疑似患者 确诊感染 n人 | 4 |
| <省> 排除 疑似患者 n人 | 4 |
| <省1> 感染患者 流入 <省2> n人 | 5 |
| <省1> 疑似患者 流入 <省2> n人 | 5 |
在arr.length已知情况下判断具体的感染情况:
需求部分分析
- 命令行的处理
$ java InfectStatistic list -date xxxx-xx-xx -type [ip,sp,dead,cure] -province [省1 省2 ...] -log xx/log/ -out xx/output.txt
//命令行格式:-log/-out为必选项,其余为可选项
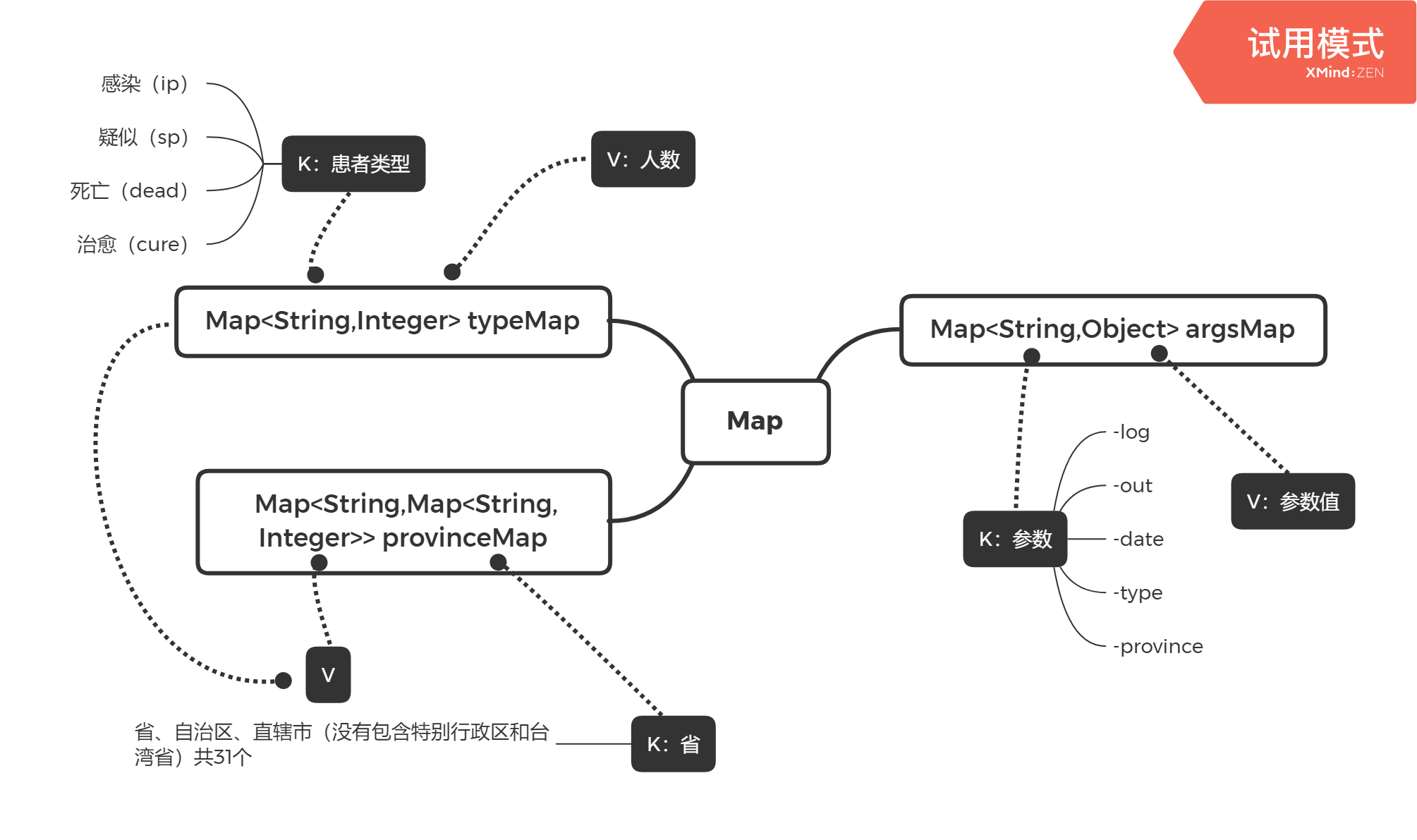
依照需求,有的参数是必选的,有的是可选,且参数-type和-province后可指定多个参数值。因此我使用了HashMap的数据结构对参数进行拼接。
Map<String,Object> argsMap = Lib.getArgsMap(args);
//getArgsMap是拼接命令行参数的方法
argsMap拼接完成后,分别取出每个键值对中的参数值,根据参数值就能对日志文档进行数据处理了:
//取出参数值
String log = argsMap.get("log").toString();
String out = argsMap.get("out").toString();
String date = argsMap.get("date").toString();
List<String> type = (List<String>)argsMap.get("type");
List<String> province = (List<String>)argsMap.get("province");
另用两个Map来存放遍历日志文件时返回的数据,三张Map的结构与联系如下:
- 参数的处理
-date: 所有日志的命名规范为 xxxx-xx-xx.log.txt,存放在/log/目录下。在接收date参数后,可以用substring方法获取文件名中的日期部分与之匹配
String fileNameDate = fileName.substring(0,fileName.indexOf(".log.txt"));
因为要处理指定日期前的所有log文件,因此需要设计一个获取最大日期的函数getMaxDate(),遍历log/目录下所有的文件并返回最新日期,以提取并出处理符合时间节点的文件数据。
public static String getMaxDate(File[] files) {
...
return maxDate;
}
-type&& -province: 在对额日志文本的分析中,发现-type和-province都为可选参数,因此我把这两个参数放在一起处理。在命令行处理的部分已经提到过他们的数据结构:
//省-患者类型:人数
Map<String,Map<String,Integer>> provinceMap = new HashMap<String, Map<String,Integer>>();
//患者类型-人数
Map<String,Integer> typemap = new LinkedHashMap<String,Integer>();
依据-type和-province在命令行中的出现情况分类处理,解决思路如下:
a. if(type.size()>0 && province.size()<1) {
先输出全国的指定的type数据;
根据provinceMap中的keys顺序输出其他省的数据(仅日志中出现过 的省,指定的type);
}
b. if(type.size()>0 && province.size()>0) {
if(province.contains("全国")) {输出全国的指定的type的数据;}
检测province的其他参数值,依次输出其指定的type数据;
}
c. if(type.size()<1 && province.size()>0) {
if(province.contains("全国")) {输出全国的每一种type数据;}
输出province中提及的省份的每一种type数据;
}
d. if(type.size()<1 && province.size()<1) {
输出全国的每一种type数据;
输出province中提及的省的每一种type数据;
}
- 文件读写处理
a. 检测log参数是否存在,不存在则提示错误;
**b. **检测文件夹中是否有文件,无文件则提示错误;
c. 获取文件夹中最大日期的文件名;
d. 处理无-date参数的情况;
e. 检测日期是否超出范围,超出则给出错误提示。
4. 设计实现过程
程序流程设计
类图
- 负责解析参数、日志文件读取和文件输出的类InfectStatistic:
- 提供命令行参数拼接、城市排序和患者类型中文转换的类Lib:
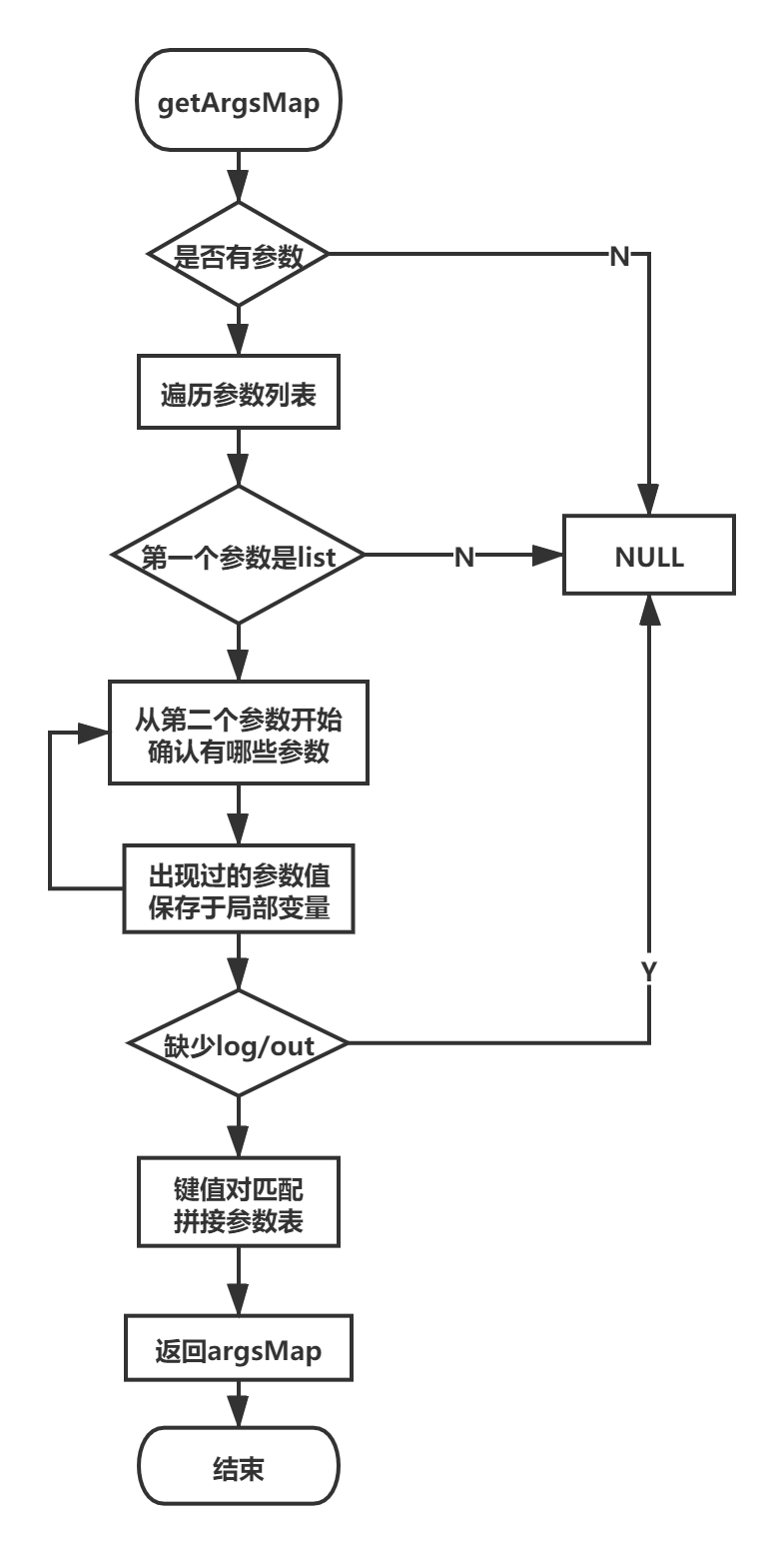
关键函数流程图
- getArgsMap函数:获取命令行参数列表并拼接于表中。
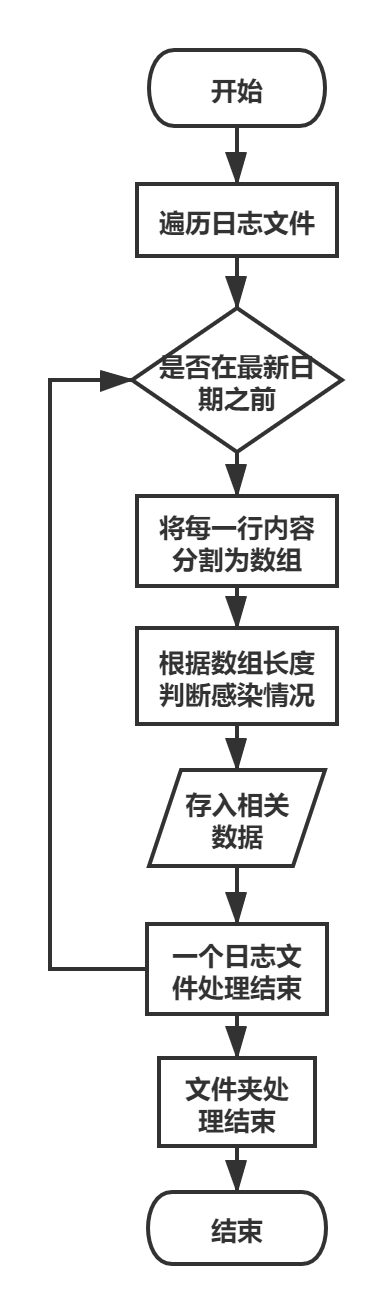
- 日志文件读取,参数解析流程:
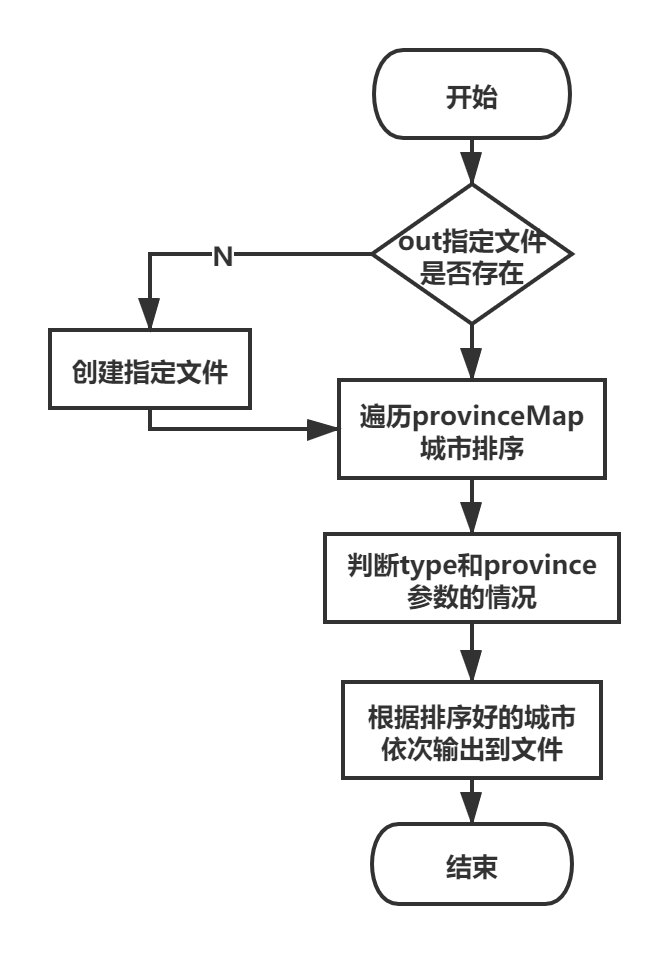
- 文件输出流程:
5. 代码说明
- 命令行参数的拼接
public static Map<String,Object> getArgsMap(String[] args) {
if(args.length<1) {
System.out.println("没有传入参数");
return null;
}
else {
//记录两个必会附带指令是否附带了
boolean hasLog = false;
boolean hasOut = false;
//定义变量保存传进来的参数
String log = "";
String out = "";
String date = "";
//一个参数后跟多个参数值的情况
List<String> type = new ArrayList<String>();
List<String> province = new ArrayList<String>();
//循环参数,确定都有哪些参数
for(int i=0; i<args.length; i++) {
//第一个参数必须是list,否则报错
if(!"list".equals(args[0])) {
System.out.println("第一个参数必须是list");
return null;
}
if(i>0) {
//从第二个参数开始确认输入了哪些参数
//一般都是第一个参数后一个为实际参数值,但是也有情况后面
//跟着多个参数,多个参数用循环来控制
if("-log".equals(args[i])) {
hasLog = true;
log = args[i+1];
} else if("-out".equals(args[i])) {
hasOut = true;
out = args[i+1];
} else if("-date".equals(args[i])) {
date = args[i+1];
} else if("-type".equals(args[i])) {
int j=1;
while(args.length>i+j && !args[i+j].startsWith("-")) {
type.add(args[i+j]);
j++;
}
} else if("-province".equals(args[i])) {
int j=1;
while(args.length>i+j && !args[i+j].startsWith("-")) {
province.add(args[i+j]);
j++;
}
}
}
}
//缺少了out 或者 log直接提示错误
if(!hasLog || !hasOut) {
System.out.println("请注意 -log -out 为必须含有的两个参数");
return null;
}
//如果能执行到这里说明一切正常,拼接参数
Map<String,Object> argsMap = new HashMap<String,Object>();
argsMap.put("log", log);
argsMap.put("out", out);
argsMap.put("date",date);
argsMap.put("type",type);
argsMap.put("province", province);
return argsMap;
}
}
- 日志读取,参数解析
if(arr.length==3) {
//此时状况为死亡,治愈两种情况,都是在对应的数上做加法;同时,感染患者减去这些;
String tempNumStr = arr[2].substring(0,arr[2].length()-1);
int tempNum = Integer.parseInt(tempNumStr);
typeMap.put(arr[1], typeMap.get(arr[1])+tempNum);
typeMap.put(Lib.ipstr, typeMap.get(Lib.ipstr)-tempNum);
//计算上全国的数据
totalMap.put(arr[1], totalMap.get(arr[1])+tempNum);
totalMap.put(Lib.ipstr, totalMap.get(Lib.ipstr)-tempNum);
} else if(arr.length==4) {
if(arr[1].equals("新增")) {
//新增,无论是感染新增,还是疑似新增,都是在原基础上做加法,同样的全国的变化也是如此
String tempNumStr = arr[3].substring(0,arr[3].length()-1);
int tempNum = Integer.parseInt(tempNumStr);
typeMap.put(arr[2], typeMap.get(arr[2])+tempNum);
//计算上全国的数据
totalMap.put(arr[2], totalMap.get(arr[2])+tempNum);
} else {
if(arr[1].equals("疑似患者")) {
if(arr[2].equals("确诊感染")) {
//在此情况下,疑似患者数量减少n , 确诊患者数量增加 n,同样的全国的变化也是如此
String tempNumStr = arr[3].substring(0,arr[3].length()-1);
int tempNum = Integer.parseInt(tempNumStr);
typeMap.put(arr[1], typeMap.get(arr[1])-tempNum);
typeMap.put(Lib.ipstr, typeMap.get(Lib.ipstr)+tempNum);
totalMap.put(arr[1], totalMap.get(arr[1])-tempNum);
totalMap.put(Lib.ipstr, totalMap.get(Lib.ipstr)+tempNum);
}
} else if(arr[1].equals("排除")) {
//此种情况下,该省排除相应人数,全国也排除相应人数
String tempNumStr = arr[3].substring(0,arr[3].length()-1);
int tempNum = Integer.parseInt(tempNumStr);
typeMap.put(arr[2], typeMap.get(arr[2])-tempNum);
totalMap.put(arr[2], totalMap.get(arr[2])-tempNum);
}
}
} else if(arr.length==5) {
//此种情况就是给省1减去对应的人给省二加上对应的人,对于全国来说没有变化
//(1)对省一的操作
String tempNumStr = arr[4].substring(0,arr[4].length()-1);
int tempNum = Integer.parseInt(tempNumStr);
typeMap.put(arr[1], typeMap.get(arr[1])-tempNum);
String city2 = arr[3];
if(provinceMap.containsKey(city2)) {
typeMap = provinceMap.get(city2);
} else {
typeMap = new LinkedHashMap<String,Integer>();
typeMap.put(Lib.ipstr, 0);
typeMap.put(Lib.spstr, 0);
typeMap.put(Lib.curestr, 0);
typeMap.put(Lib.deadstr,0);
provinceMap.put(city2, typeMap);
}
//(2)对省二的操作
typeMap.put(arr[1], typeMap.get(arr[1])+tempNum);
}
- 输出文件
if(type.size()>0 && province.size()<1) {
//只有type
StringBuffer sbf = new StringBuffer();
for(int i=0; i<type.size(); i++) {
sbf.append(Lib.getNamebyType(type.get(i)) + totalMap.get(Lib.getNamebyType(type.get(i)))+"人 ");
}
bw.write("全国 " + sbf.toString());
//先输出全国的
bw.newLine();
//根据排好续的keys依次输出到txt中
for(int i=0; i<keys.size(); i++) {
Map<String,Integer> tempMap = provinceMap.get(keys.get(i));
StringBuffer sbf2 = new StringBuffer();
for(int j=0; j<type.size(); j++) {
sbf2.append(Lib.getNamebyType(type.get(j))+tempMap.get(Lib.getNamebyType(type.get(j)))+"人 ");
}
bw.write(keys.get(i)+" "+sbf2.toString());
bw.newLine();
}
bw.close();
} else if(type.size()>0 && province.size()>0) {
//既有type,也有province //先输出全国的
if(province.contains("全国")) {
StringBuffer sbf = new StringBuffer();
for(int i=0; i<type.size(); i++) {
sbf.append(Lib.getNamebyType(type.get(i))+totalMap.get(Lib.getNamebyType(type.get(i)))+"人 ");
}
bw.write("全国 "+sbf.toString());
bw.newLine();
}
//全国输入进去以后,再看还有没有没输入的
province = Lib.sortByAlphabet(province);
for(String str: province) {
if(str.equals("全国")) {
continue;
}
Map<String,Integer> tempMap = provinceMap.get(str);
StringBuffer sbf2 = new StringBuffer();
for(int j=0; j<type.size(); j++) {
sbf2.append(Lib.getNamebyType(type.get(j))+(tempMap==null? 0:tempMap.get(Lib.getNamebyType(type.get(j))))+"人 ");
}
bw.write(str+" "+sbf2.toString());
bw.newLine();
}
bw.close();
//不指定type,则列出所有情况
} else if(type.size()<1 && province.size()>0) {
if(province.contains("全国")) {
bw.write("全国 "+Lib.ipstr +totalMap.get(Lib.ipstr)+"人 "+Lib.spstr +totalMap.get(Lib.spstr)+"人 "+Lib.curestr +totalMap.get(Lib.curestr)+"人 "+Lib.deadstr +totalMap.get(Lib.deadstr)+"人");
bw.newLine();
} else {
province = Lib.sortByAlphabet(province);
for(String str:province){
int str1Num = 0;
int str2Num = 0;
int str3Num = 0;
int str4Num = 0;
if(provinceMap.containsKey(str)) {
Map<String,Integer> tempMap = provinceMap.get(str);
str1Num = tempMap.get(Lib.ipstr);
str2Num = tempMap.get(Lib.spstr);
str3Num = tempMap.get(Lib.curestr);
str4Num = tempMap.get(Lib.deadstr);
}
bw.write( str+" "+Lib.ipstr +str1Num+"人 "+Lib.spstr +str2Num+"人 "+Lib.curestr +str3Num+"人 "+Lib.deadstr +str4Num+"人");
bw.newLine();
}
}
bw.close();
} else {
//既没有type也没有province
//先输出全国的
bw.write("全国 "+Lib.ipstr +totalMap.get(Lib.ipstr)+"人 "+Lib.spstr +totalMap.get(Lib.spstr)+"人 "+Lib.curestr +totalMap.get(Lib.curestr)+"人 "+Lib.deadstr +totalMap.get(Lib.deadstr)+"人");
bw.newLine();
//根据排好续的keys依次输出到txt中
for(int i=0; i<keys.size(); i++) {
Map<String,Integer> tempMap = provinceMap.get(keys.get(i));
bw.write( keys.get(i)+" "+Lib.ipstr +tempMap.get(Lib.ipstr)+"人 "+Lib.spstr +tempMap.get(Lib.spstr)
+"人 "+Lib.curestr +tempMap.get(Lib.curestr)+"人 "+Lib.deadstr +tempMap.get(Lib.deadstr)+"人");
bw.newLine();
}
bw.close();
6. 单元测试
测试部分1
- getMaxDate方法


- getArgsMap测试
**a. **缺少-list参数的情况:

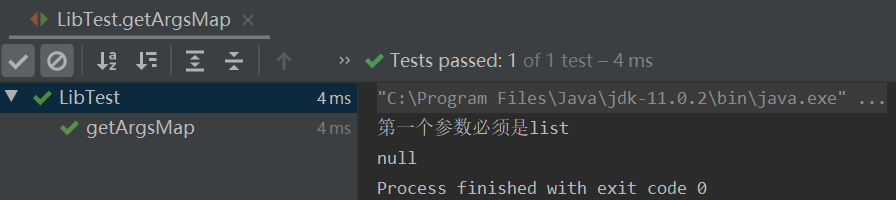
**b. **-type、-province参数不止一个参数值的情况:


- sortByAlphabet测试
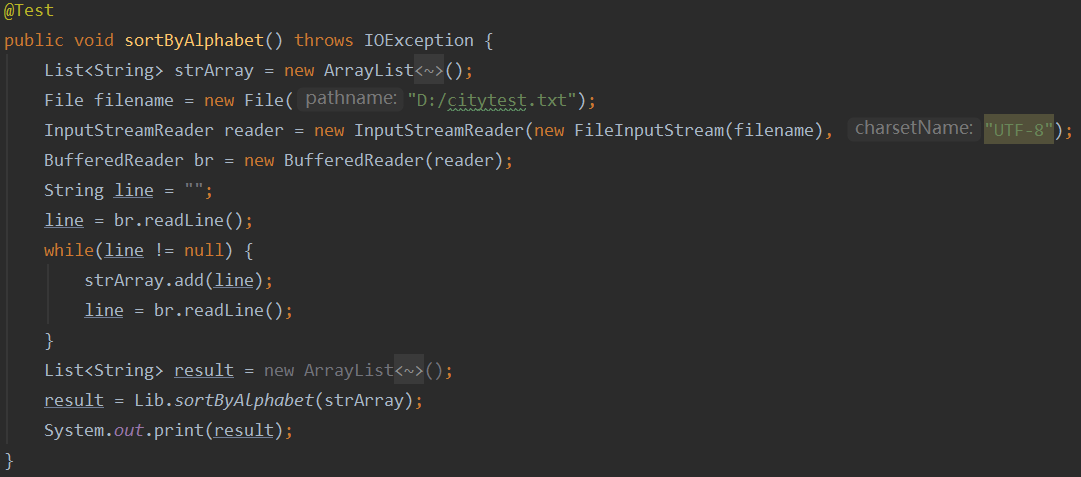

- getNameByType测试


main测试
- 缺少参数-list


- 指定日期超出范围


- 不指定-date,默认为最新日期


- 不指定-type和-province,默认输出全国和日志中提及的省的全部type


- 不指定-type,默认输出全部type


- 不指定-province,默认输出全国和日志中提及的省的数据


- -province指定的省未在日志中提及


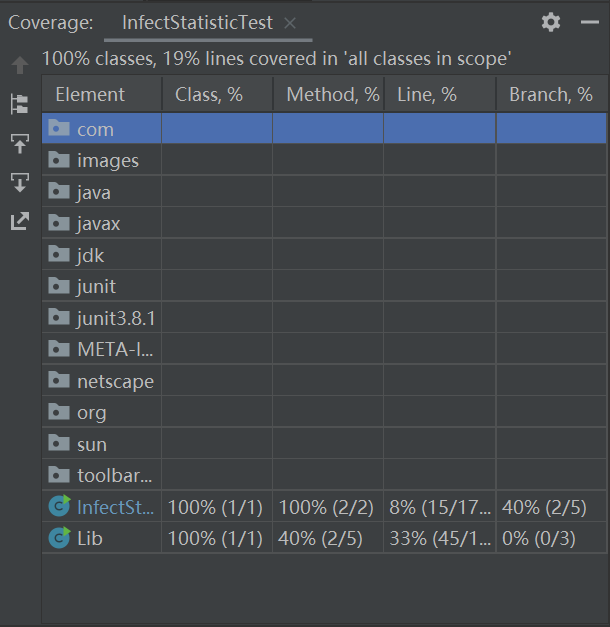
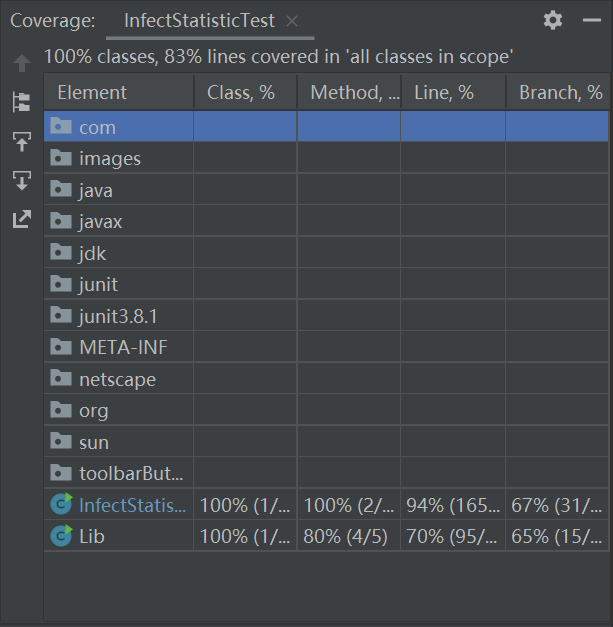
7. 单元测试覆盖率优化和性能测试
测试类InfectStatisticTest
- 优化前后
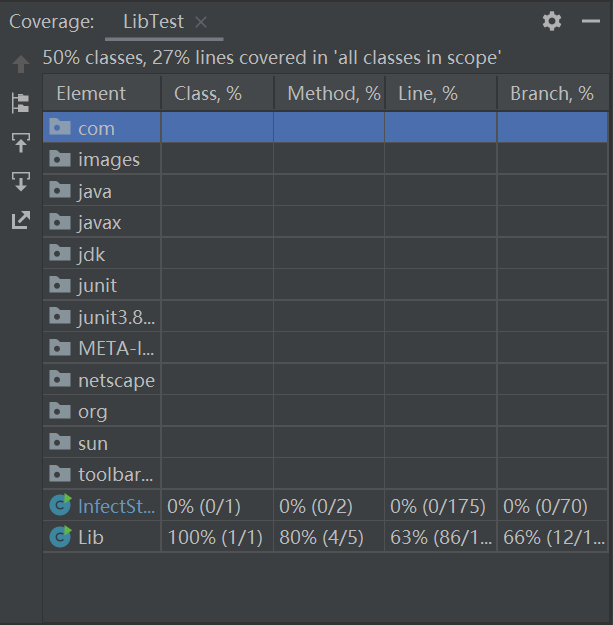
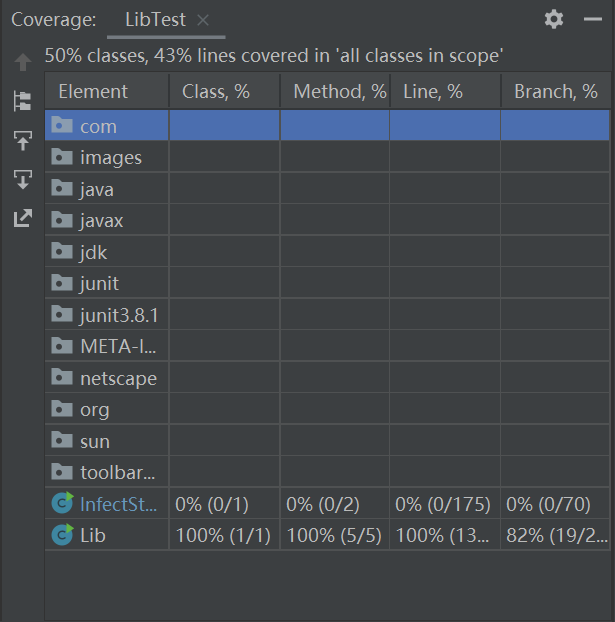
测试类LibTest
- 优化前后
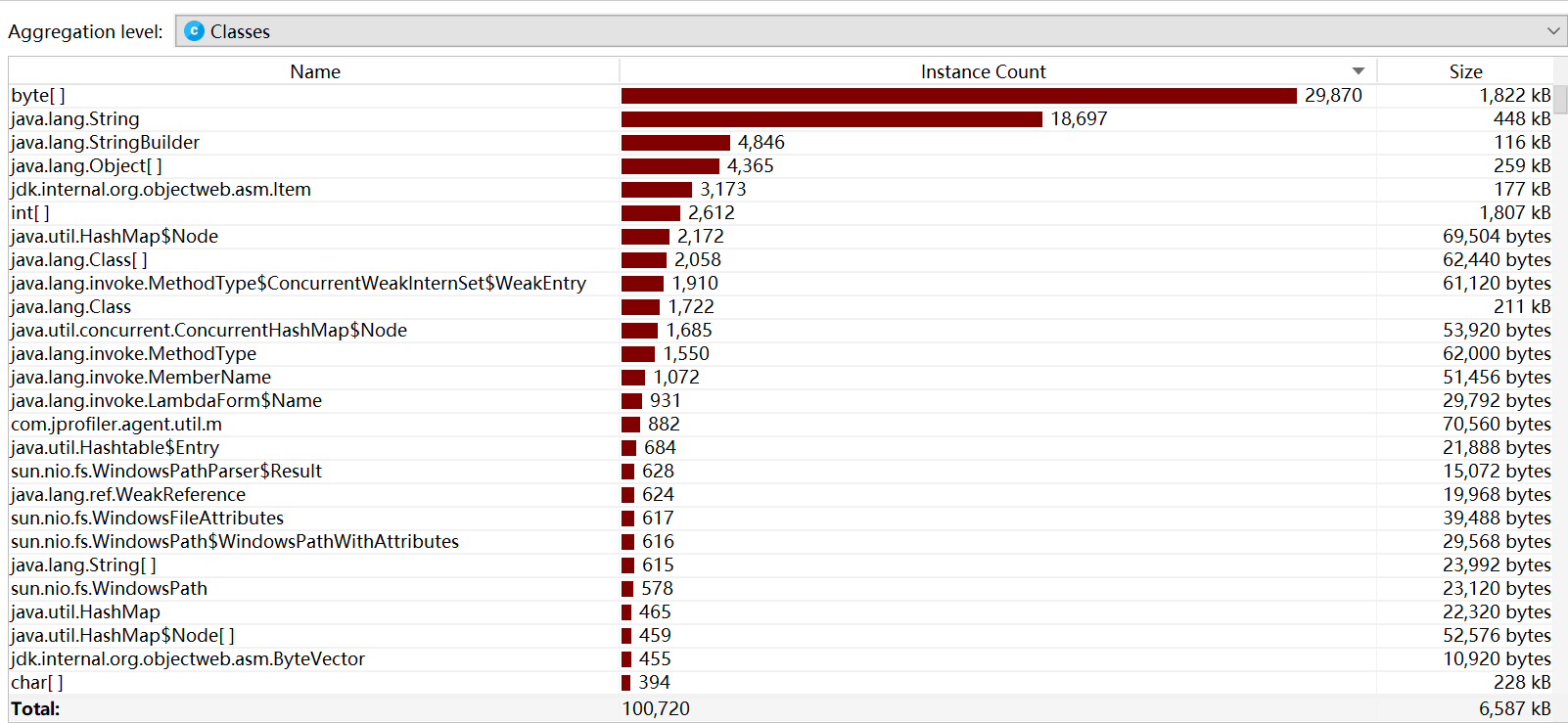
性能测试
8.GitHub仓库、代码规范
9. 心路历程与收获
在这个作业之前,编程时从不事先定制项目流程,总是想到什么模块就做什么模块,遇到什么问题就解决什么,这种方法看似简单其实工作量非常大,且项目遇到问题时思维非常容易混乱,不容易扩展与维护,也不利于后来的学习。因此本次作业的一个收获就是学习提前制定工作计划,能有效地较少盲目性,规避低级错误,整个过程会很有秩序。
之前总觉得项目管理是晦涩难懂的,但在本次作业过程中逐渐建立了项目管理的意识,最显著的进步是学习了如何使用Git,基本掌握了工作中必需的命令,并学习了Git的工作原理和流程。用Git管理项目确实很清晰和便捷,可以看到自己的程序是怎样的完善、修改的,另外,一个合格的项目开发人员应该能够编写规范的commit message,这除了有利于理解和组织自己的程序外,也能够在团队中建立良好的信息沟通(如果需要的话)。
最后一点想说的就是需求分析,虽然之前已经面向对象分析与设计的课程,但是很多人忽视了这个阶段,将重心过多的放在了解决方案上。虽然需求分析确实不是一个轻松的过程。但真正想做好项目,应该在充分理解需求后再着手于设计。例如本次作业的需求文档,内容划分非常细致,需要花时间理解,如果忽略了需求分析这个环节,就会产生需求上的疏漏或者错误。这时候需求分析的重要性就不言而喻了。一方面避免了频繁返工,另一方面也能增强项目的专业性和价值。
10. 技术路线图相关的5个仓库
brief:记录了作者每天整理的计算机视觉、深度学习、机器学习相关方向的论文,包括了CV优质论文速递、CV顶会/期刊、2019CV论文最佳综述。
brief:深度学习与计算机视觉实例入门与配套代码,定位是初学者入门。
brief:本文档的定位是 PyTorch 入门教程,主要针对想要学习PyTorch的学生群体或者深度学习爱好者。通过教程的学习,能够实现零基础了解和学习深度学习,PyTorch是当前难得的简洁优雅且高效快速的计算机视觉学习框架。
brief:提供国内各大公司人工智能方向职位的工作机会资源,包括机器学习,深度学习,计算机视觉,SLAM,自动驾驶和自然语言处理等方向。国内公司人工智能方向(含机器学习,深度学习,计算机视觉和自然语言处理)职位的招聘信息。
brief:快速开启人工智能自学计划,在学习过程中少走弯路用最快的效率入门Ai并开始实战项目, 提供了近200个Ai实战案例和项目,这些是作者线上与线下教学所开发和积累的案例,适合进行循序渐进的学习与练手。
