 暑假集训虽然很快乐,偶尔也会比较枯燥,,这个时候就需要自娱自乐...
暑假集训虽然很快乐,偶尔也会比较枯燥,,这个时候就需要自娱自乐...
然后看hdu的排行榜发现,除了一些是虚拟测评机的账号以外,有几个都是AC自动机器人
然后发现有一位作者是用网页填表然后按钮模拟,,,默默噗噗的笑了。。。
先来晒一下排行榜

要模拟网页,,当然POST大法好啊,直接模拟发送POST数据不就好了咩,,搞填表啥的多麻烦,完全可以写一个程序后台自动跑。
然后他说了一句AC率能达到50%以上的爬虫也是挺吊的,,于是激起了我试一试的决心(我是不是很wuliao)...
先解释一下POST大法是啥。。。。
貌似研究POST的话,,弄易语言的可能研究的会比较多,很多人会利用POST来实现注册机,采集机,发贴机等等,,这里面的利益关系也是很深的
但是易语言弄POST也会遇到一些局限,,毕竟是语言的局限,再怎样也无法跟C#大法来比较,虽说C#用来弄单纯的POST略有浪费。。。
网页与网页服务器是利用http协议传输数据,包括两种,一种是GET一种是POST
模拟浏览器的点击啥的,,其实最终的目的是让浏览器解析网页,然后发送对应的数据包反馈给服务器
然而我们为什么不直接发送对应的数据包给服务器呢?这样就不关浏览器的事情了,也增加了程序的鲁棒性
对于整个程序总体的思路是这样的:
1.首先在百度上搜索对应的题号,然后采集百度上来自csdn的链接
2.对之前采集的链接利用类直接获取网页源码,从中解析code部分
3.最重要的一个剪枝,获取这个网页中<title>和</title>中的内容,从里面查找是否含有题号!!通过这个剪枝,整个AC率可以上升N倍~
4.认证code部分中是否含有"#include"这个内容,,这样可以防止code边框中可能是其他内容而不是代码
5.去杭电提交代码,如果通过了就下一题,不通过继续在之前解析的csdn中找代码
然后我们来一条一条的分析。。
首先放一个我自己写好的类,里面封装了最基础的http类和一些常用的函数(其实http类和Regex类只是把C#中的WebRequest类和Regex类简化了一下,,这样写起来更方便,然后稍微增加了几个常用到的文本处理的静态函数,以方便调用 )
-
-
using System;
-
using System.Collections.Generic;
-
using System.Linq;
-
using System.Text;
-
using System.Net;
-
using System.IO;
-
using System.Diagnostics;
-
using System.Text.RegularExpressions;
-
-
namespace Exyao {
-
class Exyao_http {
-
public CookieContainer cookie = new CookieContainer();
-
public string encode;
-
public HttpWebResponse response;
-
-
public Exyao_http(string _Encoding) {
-
encode = _Encoding;
-
}
-
-
public string GET(string url) {
-
HttpWebRequest http = (HttpWebRequest)WebRequest.Create(url);
-
http.Method = "GET";
-
http.CookieContainer = cookie;
-
HttpWebResponse res = (HttpWebResponse)http.GetResponse();
-
-
response = res;
-
Stream s = res.GetResponseStream();
-
StreamReader rs = new StreamReader(s, Encoding.GetEncoding(encode));
-
string ret = rs.ReadToEnd();
-
rs.Close();
-
s.Close();
-
return ret;
-
}
-
-
public string POST(string url, string data = "") {
-
HttpWebRequest http = (HttpWebRequest)WebRequest.Create(url);
-
http.CookieContainer = cookie;
-
http.Method = "POST";
-
http.ContentType = "application/x-www-form-urlencoded";
-
Stream sd = http.GetRequestStream();
-
StreamWriter sw = new StreamWriter(sd);
-
sw.Write(data);
-
sw.Close();
-
-
HttpWebResponse res = (HttpWebResponse)http.GetResponse();
-
response = res;
-
Stream s = res.GetResponseStream();
-
StreamReader rs = new StreamReader(s, Encoding.GetEncoding(encode));
-
string ret = rs.ReadToEnd();
-
rs.Close();
-
s.Close();
-
return ret;
-
}
-
-
public void deal_cookie() {
-
string[] h = response.Headers.GetValues("Set-Cookie");
-
if (h == null) return;
-
foreach (string c in h) {
-
cookie.SetCookies(response.ResponseUri, c);
-
}
-
}
-
}
-
-
class Exyao_Regex {
-
private Regex r;
-
private Match ret_;
-
private bool is_all;
-
private MatchCollection ret;
-
-
public Exyao_Regex(string s) {
-
r = new Regex(s);
-
}
-
-
public bool match(string s, bool all = false, int start = 0) {
-
is_all = all;
-
if (all) {
-
ret = r.Matches(s, start);
-
return ret.Count != 0;
-
}
-
else {
-
ret_ = r.Match(s, start);
-
return ret_.Success;
-
}
-
}
-
-
public int getn() {
-
return ret.Count;
-
}
-
-
public string get_text(int id = 0) {
-
if (is_all) {
-
return ret[id].Value;
-
}
-
else {
-
return ret_.Value;
-
}
-
}
-
-
public string get_subtext(int i = 0, int j = 0) {
-
if (is_all) {
-
GroupCollection g = ret[i].Groups;
-
return g[j + 1].Value;
-
}
-
else {
-
GroupCollection g = ret_.Groups;
-
return g[j + 1].Value;
-
}
-
}
-
}
-
-
class F {
-
public static string urlencode_utf8(string s) {
-
byte[] bs = Encoding.GetEncoding("utf-8").GetBytes(s);
-
int len = bs.Length;
-
string ret = "";
-
for (int i = 0; i < len; i++) {
-
int c = bs[i];
-
c = c < 0 ? 256 + c : c;
-
if (c < 42 || c == 43 || c > 57 && c < 64 || c > 90 && c < 95 || c == 96 || c > 122) {
-
ret += "%" + c.ToString("x2");
-
}
-
else {
-
ret += (char)c;
-
}
-
}
-
return ret;
-
}
-
-
public static string urlencode_gb2312(string url) {
-
byte[] bs = Encoding.GetEncoding("gb2312").GetBytes(url);
-
int len = bs.Length;
-
string ret = "";
-
for (int i = 0; i < len; i++) {
-
int c = bs[i];
-
c = c < 0 ? 256 + c : c;
-
if (c < 42 || c == 43 || c > 57 && c < 64 || c > 90 && c < 95 || c == 96 || c > 122) {
-
ret += "%" + c.ToString("x2");
-
}
-
else {
-
ret += (char)c;
-
}
-
}
-
return ret;
-
}
-
-
public static bool instr(string a, string b) {
-
if (a.IndexOf(b) >= 0) return true;
-
return false;
-
}
-
-
public static string substr(string s, string l, string r, int begin = 0) {
-
int lp, rp;
-
lp = s.IndexOf(l, begin);
-
if (lp < 0) return "";
-
-
rp = s.IndexOf(r, lp + l.Length);
-
if (rp < 0) return "";
-
-
return s.Substring(lp + l.Length, rp - lp - l.Length);
-
}
-
-
public static string readfile(string file, string encode = "gb2312") {
-
FileStream fs = new FileStream(file, FileMode.Open);
-
StreamReader sr = new StreamReader(fs, Encoding.GetEncoding(encode));
-
string ret = sr.ReadToEnd();
-
sr.Close();
-
fs.Close();
-
return ret;
-
}
-
-
public static void writefile(string file, string content = "", string encode = "gb2312") {
-
FileStream fs = new FileStream(file, FileMode.OpenOrCreate);
-
StreamWriter sw = new StreamWriter(fs, Encoding.GetEncoding(encode));
-
sw.Write(content);
-
sw.Close();
-
fs.Close();
-
}
-
-
public static string gb2312_to_utf8(string s) {
-
Encoding gb2312 = Encoding.GetEncoding("gb2312");
-
Encoding utf8 = Encoding.GetEncoding("utf-8");
-
-
byte[] w = gb2312.GetBytes(s);
-
w = Encoding.Convert(gb2312, utf8, w);
-
return utf8.GetString(w);
-
}
-
-
public static string utf8_to_gb2312(string s) {
-
Encoding gb2312 = Encoding.GetEncoding("gb2312");
-
Encoding utf8 = Encoding.GetEncoding("utf-8");
-
-
byte[] w = utf8.GetBytes(s);
-
w = Encoding.Convert(utf8, gb2312, w);
-
return gb2312.GetString(w);
-
}
-
}
-
}
我们先来尝试一下利用http协议直接获取百度的内容
用Google浏览器按F12点Network就可以开始录制封包
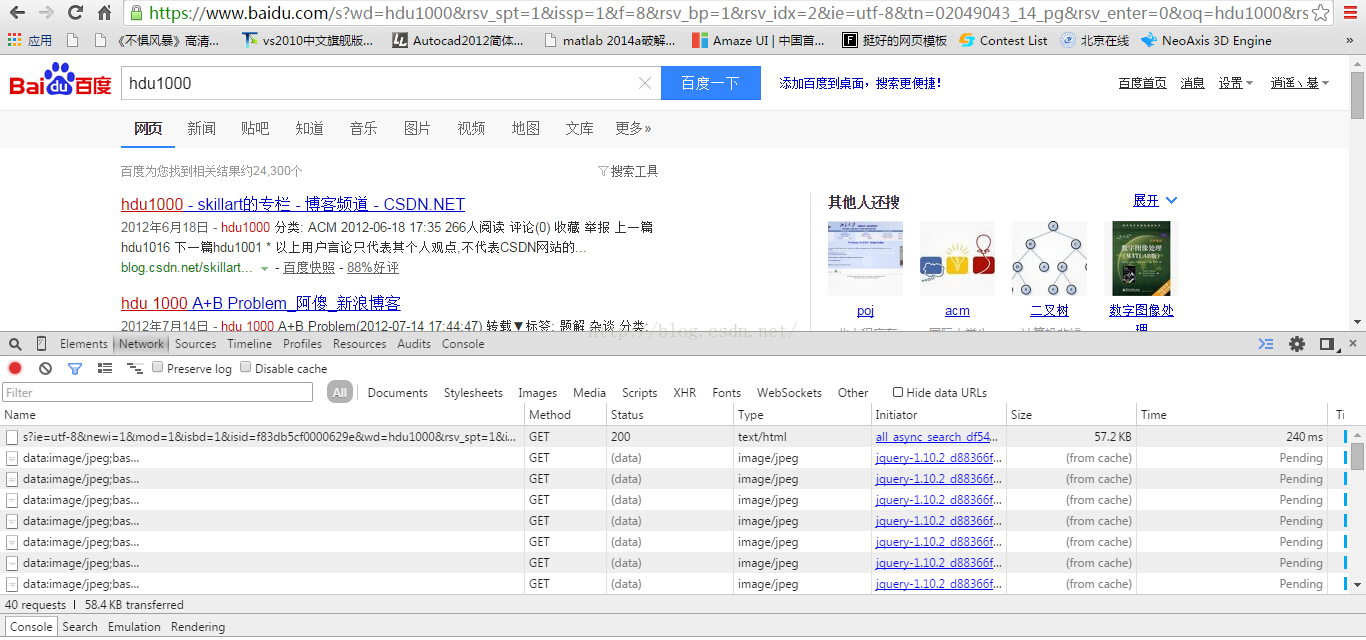
一般最重要的那一条里面都会带有很重要的参数,要么Method就是POST类型,要么就是GET中带上了很重要的参数
很明显,这里面第一条地址中带了我们搜索的内容,地址是
-
http://www.baidu.com/s?wd=hdu1000&rsv_spt=1&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=02049043_14_pg&rsv_enter=0&oq=hdu1000&rsv_t=f307M1pw6K7opc%2Fa5gyHuAJnjgYujheimT04UNMEmJrUz%2BBAo6%2B64AxFVh4WEuKUzFNKx2Q&rsv_pq=f83db5cf0000629e
我们可以稍微简化一下,其实可以就写成http://www.baidu.com/s?wd=hdu1000
这样我们就获得了地址,然后我们可以查看一下这个网页的源码

然后会得到html源码,找到大概的位置
一般html代码都是通过循环去生成的,所以每个块的代码基本都是类似的
我们只需要掌握这种代码格式就可以了
平时我们点击百度的地址就知道,,一般的链接刚开始使用的都是百度的短地址,然后会跳转,所以我们要采集那些短地址
把鼠标放到链接上,浏览器会显示出链接的地址,发现是以www.baidu.com/link开头的,于是我们在源码中搜索这一句

目标已经很明确了,就是要把他们取出来。。如果在acm里,,看似需要非常繁琐的文本处理,,
然而这是工程嘛,,用正则表达式效率已经高的惊人了。所以我们可以利用正则表达式写出匹配
因为我这下面这份函数是从以前写的,,当时就直接复制了,好像当时发现里面可能有可能引号是单引号的原因,所以写了两个正则去匹配
-
public static string[] baidu(string content) {
-
Exyao_http http = new Exyao_http("utf-8");
-
string html = http.GET("http://www.baidu.com/s?wd=" + F.urlencode_utf8(content) + "&ct=2097152&pn=0");
-
-
Exyao_Regex reg = new Exyao_Regex("data-tools=\"\\{title:'(.*?)',url:'(.*?)'\\}\"");
-
reg.match(html, true);
-
-
List<string> ret = new List<string>();
-
for (int i = 0; i < reg.getn(); i++) {
-
ret.Add(reg.get_subtext(i, 1));
-
}
-
-
reg = new Exyao_Regex("data-tools='\\{\"title\":\"(.*?)\",\"url\":\"(.*?)\"\\}");
-
reg.match(html, true);
-
-
for (int i = 0; i < reg.getn(); i++) {
-
ret.Add(reg.get_subtext(i, 1));
-
}
-
return ret.ToArray();
-
}
另外讲一下几个关于网页表单很重要的编码。。。
一个是url编码,因为如果要传送的数据中包含一些符号,可能会对原本的文本的分隔符产生冲突,比如& / =等一些用于地址的符号,所以需要把这些符号转义
网页中都是利用url编码进行转义的,在之前发的类中我已封装好了函数。。
然后一个问题就是网页的编码,分gb2312和utf-8两种
gb2312是中文编码,utf-8是一种更普遍的面向更多语言的编码,两种编码在字母的ASCII码上,是一样的
但是在中文汉字上,gb2312是占2个字节,但是utf-8是占3个字节,这也会导致两种编码下的内容url编码之后会不一样
对于网页一般在源码中都会表明清楚采用的是什么源码。是什么源码你数据包就应该使用哪种源码
我的那个http类处理了一下网页编码,只要刚开始在初始化的时候填好编码,,之后返回出来的内容都会自动转码,但是提交表单的时候还是需要按照指定的编码去url编码
现在,,我们来考虑如何从csdn的博客中采集代码
就以hdu1000的第一个地址为基础,我们来查看它的网页源码
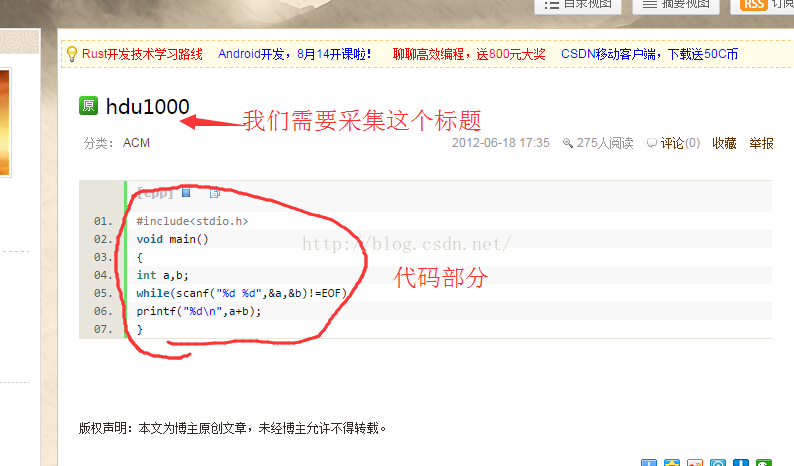


我们可以发现,,标题肯定是在<title>里面啊,,我们需要先采集一次标题,,然后看我们的题号是否在这个标题中。如果不在,那这篇文章肯定就不是正确代码啊,,
acmer写题解当然会把题号写在标题中~~
再看代码可以发现,代码框里面的内容都在<pre>这个标签里面,,所以我们就可以采集整个网页中出现的<pre>标签里面的内容
然后在这个内容里面寻找是否有"#include",如果有,说明这个里面的代码就可能是答案了咯
-
public static string getcode(string url, string id = "") {
-
Exyao_http http = new Exyao_http("utf-8");
-
-
Exyao_Regex zz = new Exyao_Regex("<pre.*?>([\\s\\S]*?)<\\/pre>");
-
string html = http.GET(url);
-
url = http.response.ResponseUri.ToString();
-
if (!F.intext(url, "/article/details/")) return "";
-
-
string title = F.substr(html, "<title>", "</title>");
-
if (!F.intext(title, id)) return "";
-
if (!F.intext(title, "hdu") && !F.intext(title, "HDU")) return "";
-
-
zz.match(html, true);
-
for (int i = 0; i < zz.getn(); i++) {
-
string code = zz.get_subtext(i, 0);
-
if (!F.intext(code, "#include")) continue;
-
-
code = code.Replace("<", "<");
-
code = code.Replace(">", ">");
-
code = code.Replace(""", "\"");
-
code = code.Replace("&", "&");
-
code = code.Replace(" ", " ");
-
Exyao_Regex reg = new Exyao_Regex("&#(.*?);");
-
reg.match(code, true);
-
for (int j = 0; j < reg.getn(); j++) {
-
string p = "";
-
p += (char)(int.Parse(reg.get_subtext(j, 0)));
-
code = code.Replace(reg.get_text(j), p);
-
}
-
-
-
return code.Substring(code.IndexOf("#include"));
-
}
-
return "";
-
}
剩下的,,我们需要封装一下关于杭电oj的操作,估计很多人都是冲着如何POST而过来看的把。。
利用我们之前教的截取封包,我们来截取一下hdu的登录封包

这条的Method是POST方法,,因为截图空间有限没截取出来,,我们很容易就能发现数据包
于是可以得到POST的地址和数据
-
地址 http://acm.hdu.edu.cn/userloginex.php?action=login
-
数据 username=账号&userpass=密码&login=Sign+In
提交数据部分,也是一样的道理,都可以利用抓包工具获得
下面是关于杭电登录和提交的代码

之所以不发文件,和上面代码不直接发代码是为了防止恶意刷,,毕竟这个只是无聊做的,并不想被当成恶意攻击杭电oj,,(毕竟我还是很喜欢hduoj的)
之前我提交也都是选在凌晨,并且每份代码中间加了10s的延时,也是为了防止影响到别人刷题..
关于http协议方面还能做出许多很好玩的东西,,基本上网页能达到的效果,都可以通过程序直接模拟封包来完成
上次听别人说我博客好像不能留言了。。(不知道是不是真的→_→),,求测试。
------------------- 这是千千的个人网站哦! https://www.dreamwings.cn -------------------



