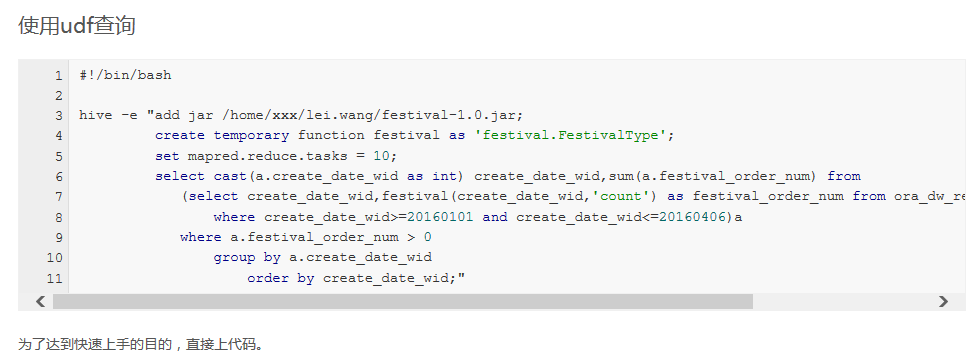
hive下UDF函数的使用
1、编写函数
[java] view plaincopyprint?
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class LowerCase extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
package com.example.hive.udf;
i
import org.apache.hadoop.hive.ql.exec.UDF;
i
import org.apache.hadoop.io.Text;
p
public final class LowerCase extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
}
2、用eclipse下的fatjar插件进行打包
先下载net.sf.fjep.fatjar_0.0.31.jar插件包,cp至eclipse/plugins目录下,重启eclipse,右击项目选Export,选择用fatjar导出(可以删掉没用的包,不然导出的jar包很大)
3、将导出的hiveudf.jar复制到hdfs上
hadoop fs -copyFromLocal hiveudf.jar hiveudf.jar
4、进入hive,添加jar,
add jar hdfs://localhost:9000/user/root/hiveudf.jar
5、创建一个临时函数
create temporary function my_lower as 'com.example.hive.udf.LowerCase';
6、调用
select LowerCase(name) from teacher;
注:这种方法只能添加临时的函数,每次重新进入hive的时候都要再执行4-6,要使得这个函数永久生效,要将其注册到hive的函数列表
添加函数文件$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFLowerCase.java
修改$HIVE_HOME/src/ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java文件
import org.apache.hadoop.hive.ql.udf.UDFLowerCase;
registerUDF(“LowerCase”, UDFLowerCase.class,false);
(上面这个方法未测试成功)
为了避免每次都有add jar 可以设置hive的'辅助jar路径'
在hive-env.sh中 export HIVE_AUX_JARS_PATH=/home/ckl/workspace/mudf/mudf_fat.jar;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号