python反爬之网页局部刷新1
# ajax动态加载网页
# 怎样判断一个网页是不是动态加载的呢?
# 查看网页源代码,如果源码中没有你要的数据,尝试访问下一页,当你点击下一页的时候,整个页面没有刷新, 只是局部刷新了,很大的可能是ajax加载
# 遇到ajax加载,一般的解决步骤就,通过浏览器或者软件抓包分析响应的请求,查看response里面哪个有你需要的数据,
# 然后再分析headers请求的网址,直接向哪个网址请求即可,当然还会有一些接口需要构建post请求
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
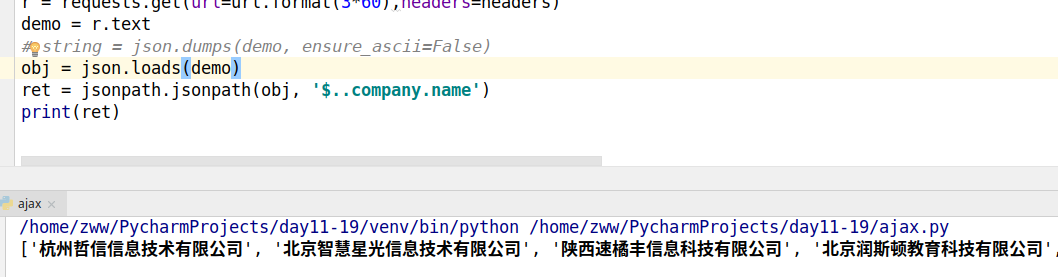
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)# ajax动态加载网页
# 怎样判断一个网页是不是动态加载的呢?
# 查看网页源代码,如果源码中没有你要的数据,尝试访问下一页,当你点击下一页的时候,整个页面没有刷新,
# 只是局部刷新了,很大的可能是ajax加载
# 遇到ajax加载,一般的解决步骤就,通过浏览器或者软件抓包分析响应的请求,查看response里面哪个是需要的数据,
# 然后再分析headers请求的网址,直接向哪个网址请求即可,当然还会有一些接口需要构建post请求
#导入的包如果下面出现红色波浪线,pip install 名字 即可
import json
import jsonpath
import requests
headers = {
'User-Agent':"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
}
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&_v=0.11045029&x-zp-page-request-id=7d6ccc963ff14b1d995b6f21942f2295-1542632726829-135321'
r = requests.get(url=url.format(3*60),headers=headers)
demo = r.text
# string = json.dumps(demo, ensure_ascii=False)
obj = json.loads(demo)
ret = jsonpath.jsonpath(obj, '$..company.name')
print(ret)
-----网页抓包----
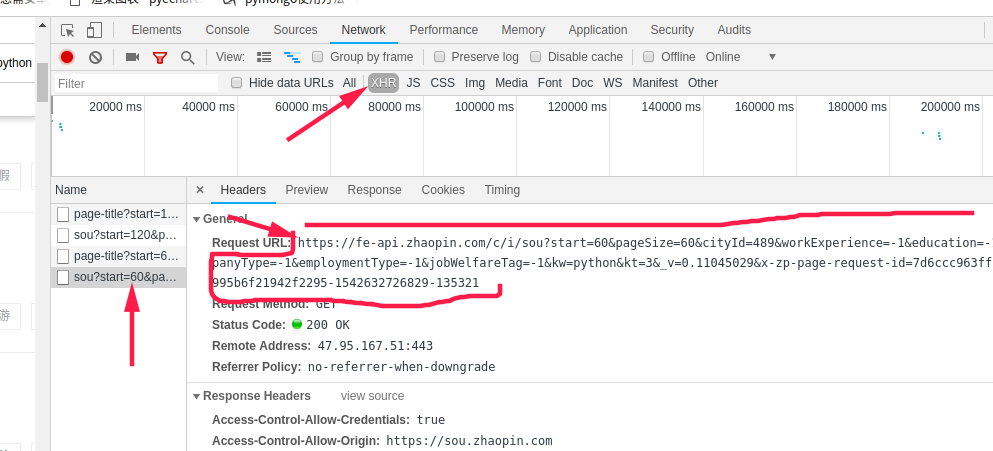
通过观察,改变start后面数字,会出现不同的数据,第一页是0,第二页是60,依次递增,pagesize则是每一页出现多少条,最好不要改变
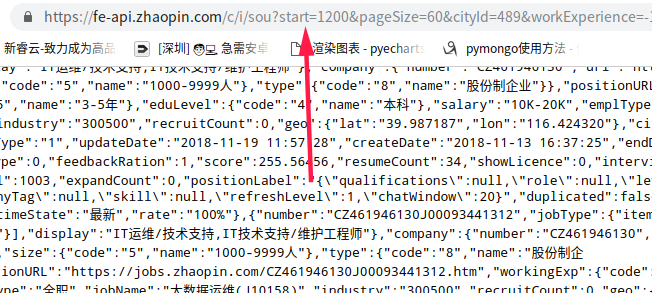
将网页中的内容粘贴到在线json解析中,可以看到,这是一个标准的json数据,通过在线解析可以看到清晰的结构

获取到的数据是一个json格式的字符串,需要使用jsonpath进行解析,获取里面的内容,图中选取了当前请求的公司名