
【建议收藏】技术面必考题:多线程、多进程

软件质量保障
专注测试圈,自动化测试、测试平台开发、测试新技术、大厂测试岗面经分享, 可以帮忙内推BATJ等大厂!欢迎加VX沟通交流: ISTE1024
多进程篇
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换。multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
守护进程
-
主进程创建守护进程
-
守护进程会在主进程代码执行结束后就终止
-
守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止。
进程同步
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理。
进程间通信
虽然可以用文件共享数据实现进程间通信,但问题是:
-
效率低(共享数据基于文件,而文件是硬盘上的数据)
-
需要自己加锁处理
因此我们最好找寻一种解决方案能够兼顾:
1)效率高(多个进程共享一块内存的数据)
2)帮我们处理好锁问题
mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。
队列和管道都是将数据存放于内存中。
队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可扩展性。
队列
Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。maxsize是队列中允许最大项数,省略则无大小限制。
什么是生产者消费者模式?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
管道
创建管道的类
Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
参数介绍
dumplex:默认管道是全双工的,如果将duplex设置成False,conn1只能用于接收,conn2只能用于发送。
共享数据
基于消息传递的并发编程是大势所趋。即便是使用线程,推荐做法也是将程序设计为大量独立的线程集合;通过消息队列交换数据。这样极大地减少了对使用锁定和其他同步手段的需求,还可以扩展到分布式系统中。
-
进程间通信应该尽量避免使用本节所讲的共享数据的方式
-
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的
-
虽然进程间数据独立,但可以通过Manager实现数据共享
信号量
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去,如果指定信号量为3,那么来一个人获得一把锁,计数加1,当计数等于3时,后面的人均需要等待。一旦释放,就有人可以获得一把锁;信号量与进程池的概念很像,但是要区分开,信号量涉及到加锁的概念。
进程池
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。多进程是实现并发的手段之一,需要注意的问题是:
-
很明显需要并发执行的任务通常要远大于核数。
-
一个操作系统不可能无限开启进程,通常有几个核就开几个进程,进程开启过多,效率反而会下降(开启进程是需要占用系统资源的,而且开启多余核数目的进程也无法做到并行)。例如当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态生成多个进程,十几个还好,但如果是上百个,上千个。。手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
我们可以通过维护一个进程池来控制进程数目,比如httpd的进程模式,规定最小进程数和最大进程数...
对于远程过程调用的高级应用程序而言,应该使用进程池,Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,就重用进程池中的进程。
创建进程池的类:如果指定numprocess为3,则进程池会从无到有创建三个进程,然后自始至终使用这三个进程去执行所有任务,不会开启其他进程。
Pool([numprocess [,initializer [, initargs]]]):创建进程池
参数介绍:
numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值
initializer:是每个工作进程启动时要执行的可调用对象,默认为None
initargs:是要传给initializer的参数组
方法:
p.apply(func [, args [, kwargs]])
在一个池工作进程中执行func(args,kwargs),然后返回结果。
需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()
p.apply_async(func [, args [, kwargs]]):
在一个池工作进程中执行func(args,kwargs),然后返回结果。
此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,
将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。
p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成
P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
多线程篇
什么是线程
那么线程就可以被理解成进程中可独立运行的子任务。
既然是在一个进程内独立运行的子任务,那么单进程意思就是当前进程只能同时允许一个进程在运行,而多线程可以允许多个线程程间来回切换,进而更快的完成更多的任务。
举个例子:
有一把锤子,两家人共用。小明家需要用这把锤子打造一个柜子(需要一天时间),小新家只需要用这个锤子在墙上钉一个钉子(最多五分钟)。既然是共用的锤子,而两家人都需要使用,在单线程的环境下,如果想小明家先拿到锤子,那么就需要独占一天的时间,小新家虽然只需要使用五分钟,但是却要等一天时间小明家才会把锤子空出来。而在多线程的环境下,虽然小明家先拿到锤子,但是也不是一天都在使用,中间也需要吃饭,也需要等待其他材料到齐,总有锤子空闲的时期,这个时候可以先让小新家拿去使用五分钟,然后使用完归还小明家继续使用。
在多线程的环境下,CPU 完全可以在两个任务间来回切换,使耗时短的任务不致于等待耗时长的任务完成才能得到执行,系统的运行效率将大大的得到提升。
但是需要注意的是,凡事都有一个度,虽然多线程间切换任务可以加快多个任务执行的效率,但是同时,在切换任务的时候,也是有一定的开销的,频繁的切换任务可能切换任务消耗的时间会更多。
为什么要使用多线程
1.更快的响应时间
这个比较好理解上面的例子比如一个车间一条流水线1天两班倒(24小时工作)可以生产1w个手机壳。如果要生产100w个手机壳如果一个车间就只有一条生产线那是不是需要100天。100天等你生产出来这个手机壳都过时了。那如果一个车间有50条生产线并行生产,那是不是生产100w手机壳2天就完工了。
2.更多的处理器核心
线程是大多数操作系统调度的基本单元,一个程序作为一个进程来运行,程序运行过程中能够创建多个线程,而一个线程在一个时刻只能运行在一个处理器核心上。
3.更好的编程模型
java为多线程编程提供了良好。考究并且一致的编程模型,使开发人员能够更加专注于问题解决,即为所遇到的问题建立适合的模型,而不是绞尽脑汁地考虑如何将其多线程化。一旦开发人员建立好了模型,稍作修改总是能够方便地映射到Java提供的多线程编程模型上。
GIL锁
Python在设计的时候,还没有多核处理器的概念。因此,为了设计方便与线程安全(数据安全),直接设计了一个锁。
这个锁要求,任何进程中,一次只能有一个线程在执行。
因此,并不能为多个线程分配多个CPU,所以Python中的线程只能实现并发,而不能实现真正的并行。但是Python3中的GIL锁有一个很棒的设计,在遇到阻塞(不是耗时)的时候,会自动切换线程。参考:https://juejin.im/post/5b977e5c5188255c996b6fad
什么是 JMM
JMM(Java Memory Model),是一种基于计算机内存模型(定义了共享内存系统中多线程程序读写操作行为的规范),屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。保证共享内存的原子性、可见性、有序性。
能用图的地方尽量不废话,先来看一张图:
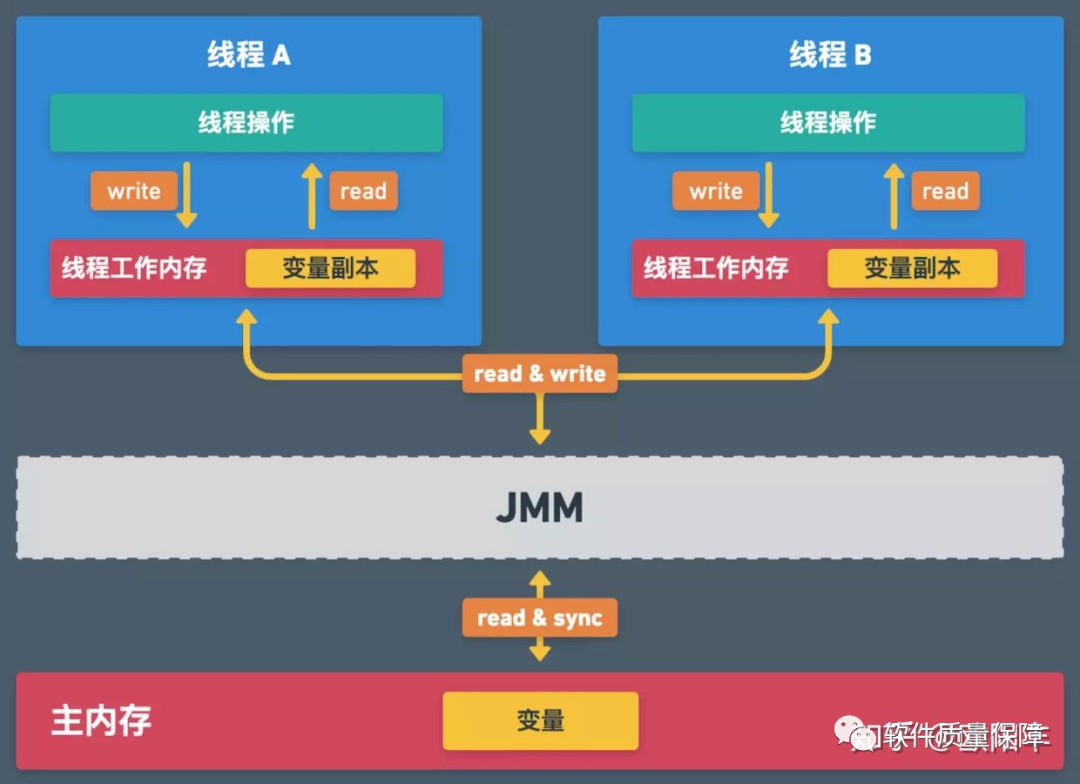
上图描述了一个多线程执行场景。线程 A 和线程 B 分别对主内存的变量进行读写操作。其中主内存中的变量为共享变量,也就是说此变量只此一份,多个线程间共享。但是线程不能直接读写主内存的共享变量,每个线程都有自己的工作内存,线程需要读写主内存的共享变量时需要先将该变量拷贝一份副本到自己的工作内存,然后在自己的工作内存中对该变量进行所有操作,线程工作内存对变量副本完成操作之后需要将结果同步至主内存。
线程的工作内存是线程私有内存,线程间无法互相访问对方的工作内存。
为了便于理解,用图来描述一下线程对变量赋值的流程。
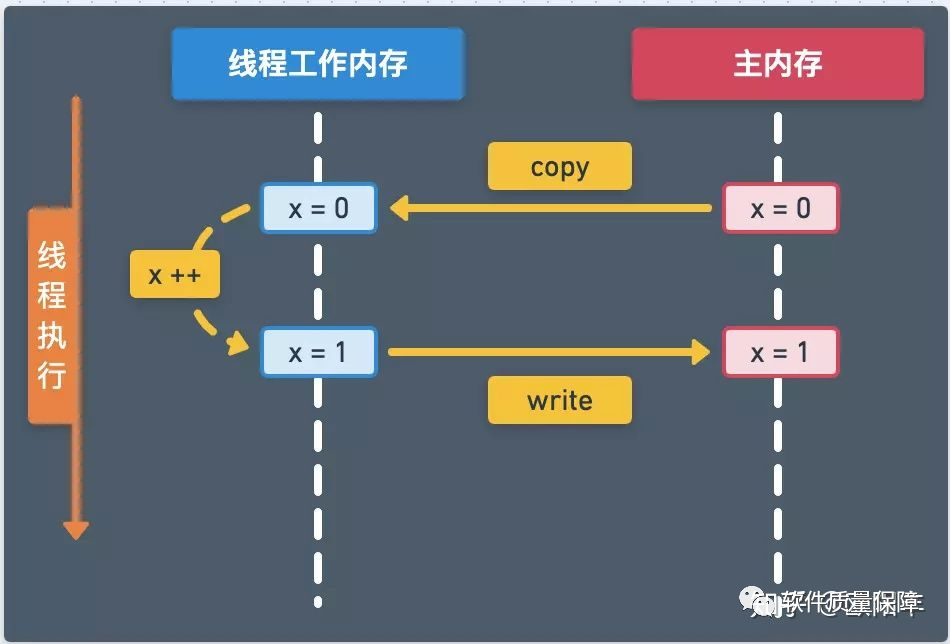
那么问题来了,线程工作内存怎么知道什么时候又是怎样将数据同步到主内存呢?这里就轮到 JMM 出场了。JMM 规定了何时以及如何做线程工作内存与主内存之间的数据同步。简单总结一下原子性、可见性、有序性
1.原子性:
对共享内存的操作必须是要么全部执行直到执行结束,且中间过程不能被任何外部因素打断,要么就不执行。
2.可见性:
多线程操作共享内存时,执行结果能够及时的同步到共享内存,确保其他线程对此结果及时可见。
3.有序性:
程序的执行顺序按照代码顺序执行,在单线程环境下,程序的执行都是有序的,但是在多线程环境下,JMM 为了性能优化,编译器和处理器会对指令进行重排,程序的执行会变成无序。
线程安全的本质
其实第一张图的例子是有问题的,主内存中的变量是共享的,所有线程都可以访问读写,而线程工作内存又是线程私有的,线程间不可互相访问。那在多线程场景下,图上的线程 A 和线程 B 同时来操做共享内存里的同一个变量,那么主内存内的此变量数据就会被破坏。也就是说主内存内的此变量不是线程安全的。
1. 出现线程安全问题的原因?
在多个线程并发环境下,多个线程共同访问同一共享内存资源时,其中一个线程对资源进行写操作的中途(写⼊入已经开始,但还没 结束),其他线程对这个写了一半的资源进⾏了读操作,或者对这个写了一半的资源进⾏了写操作,导致此资源出现数据错误。
2. 如何避免线程安全问题?
保证共享资源在同一时间只能由一个线程进行操作(原子性,有序性)。
将线程操作的结果及时刷新,保证其他线程可以立即获取到修改后的最新数据(可见性)。
编程实践
1.两个线程交替打印奇偶数
from threading import Lock, Thread
# 打印奇数
def odd_printer(k):
for i in range(1, k + 1):
if i % 2 != 0:
lock_even.acquire()
print(t_odd.name, i),
lock_odd.release()
# 打印偶数
def even_printer(k):
for i in range(1, k + 1):
if i % 2 == 0:
lock_odd.acquire()
print(t_even.name, i),
lock_even.release()
if __name__ == "__main__":
lock_odd = Lock()
lock_even = Lock()
t_odd = Thread(target=odd_printer, args=(10,))
t_even = Thread(target=even_printer, args=(10,))
lock_odd.acquire()
t_odd.start()
t_even.start()
t_odd.join()
t_even.join()(InterruptedException e) {
e.printStackTrace();
}
}
}2.多进程测试代码
#!/usr/bin/env python
# 使用多进程测试代码必须两核以上(相当于多个CPU同时运行)
import time
import multiprocessing
import os # 系统模块
def func():
time.sleep(3)
i = 0
for j in range(1000):
i += 1
return True
def main():
start_time = time.time()
# 创建一个子进程,进程对象
p = multiprocessing.Process(target=func)
# 获取当前进程的名字
# multiprocessing.current_process()
# 判断这个进程实例,是否还在运行
# p.is_alive()
# 不管这个是否在运行,强制杀掉
# p.terminate()
# 默认值False,主进程
p.daemon = True
# join 等待这个进程结束,主进程才结束
# p.join()
# 启动进程
p.start()
func()
end_time = time.time()
print("子进程:", end_time - start_time)
def get_pid():
# linux独有的,window上没有
# linux创建进程,是操作系统把父进程的东西拷贝到子进程,复制进程
# windows创建进程,类似于模块导入的方法,一定要写main方法,要不会出现执行多次
pid = os.fork()
if pid == 0: # 子进程永远返回的是0
print('子进程{},父进程{}'.format(os.getpid(), os.getppid()))
else: # 父进程返回的是子进程的id
print('父进程{},子进程{}'.format(os.getpid(), pid))
def main1():
start_time = time.time()
func()
func()
end_time = time.time()
print(end_time - start_time)
class BolockProcess(multiprocessing.Process):
def __init__(self):
super().__init__()
def run(self):
n = 5
while n > 0:
print('the time is{}'.format(time.ctime()))
time.sleep(2)
n -= 1
def test_BolockProcess(): # 对象继承
for i in range(5):
p = BolockProcess()
p.start()
if __name__ == '__main__':
# start_time = time.time()
# main()
# end_time = time.time()
# print("主进程:", end_time - start_time)
# main1()
# get_pid()
test_BolockProcess()
参考文档
https://mp.weixin.qq.com/s/evPO-5-r9W3rWmTo4Gz_Pg
https://mp.weixin.qq.com/s/XKXUjykwY8p6x-wTu4f8Hg
https://www.cnblogs.com/kaituorensheng/p/4445418.html#_label0
https://blog.csdn.net/lianjiaokeji/article/details/83095187
https://www.cnblogs.com/jiangfan95/p/11439207.html
https://zhuanlan.zhihu.com/p/73899015
https://www.freecodecamp.org/news/how-to-think-like-a-programmer-3ae955d414cd/
https://juejin.im/post/5b977e5c5188255c996b6fad
https://docs.python.org/zh-cn/3/library/multiprocessing.html
https://juejin.im/post/5d97643c6fb9a04e1a3bb1e0
内推福利
扫我投递简历(校园招聘)

社招需要内推的可以直接联系我or私信我(VX: ISTE1024)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号