
Python函数开发的四条原则
众所周知,熟悉Python的小伙们接触最多的就是函数,函数是组织好的、可重复使用的、用来实现单一或相关联功能的代码段。
函数能提高应用的模块性和代码的重复利用率。除了Python提供了许多内建函数,比如print()。而我们接触最频繁的就是用户自定义函数。
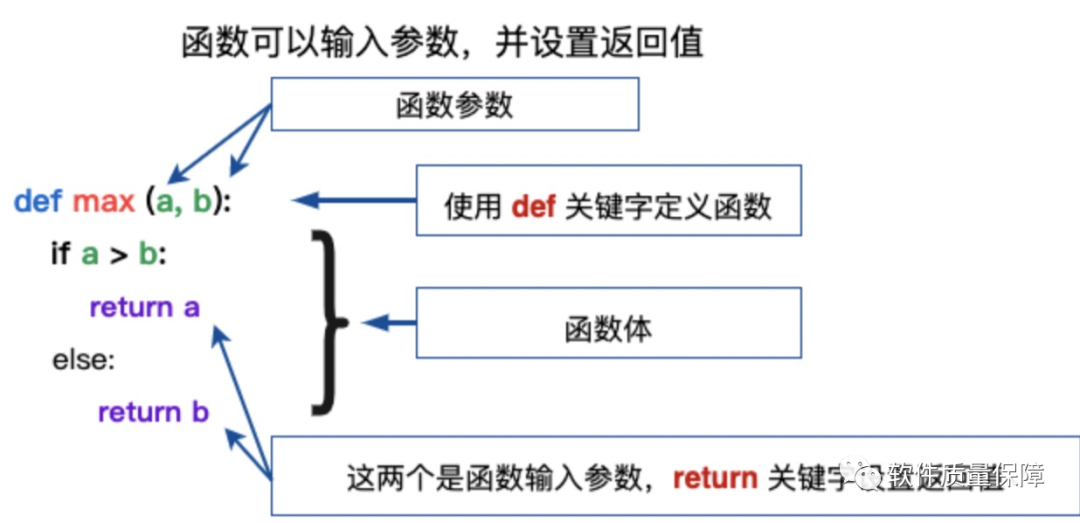
函数定义
函数定义要素:
-
def关键词,后接函数标识符名称和圆括号 ()。
-
参数,任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
-
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
-
函数内容以冒号: 起始,并且缩进。
-
return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
不定长参数
函数更多地使用场景是根据动态的输入返回动态的结果,这样入参必须是变量。而入参的类型也是有多种的,例如定长和不定长参数,定长参数大家接触的最多,不做赘述,简单介绍下不定长参数:
有时,你可能需要一个函数能处理比当初声明时更多的参数,这些参数叫做不定长参数,和定长参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ):"函数_文档字符串"function_suitereturn [expression]
注意:加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。如果在函数调用时没有指定参数,它就是一个空元组。
# 函数说明def printinfo(arg1, *vartuple):"打印任何传入的参数"print("输出: ")print(arg1)print(vartuple)# 调用printinfo 函数printinfo(70, 60, 50)printinfo(70)

还有一种就是参数带两个星号 **基本语法如下:
def functionname([formal_args,] **var_args_dict ):"函数_文档字符串"function_suitereturn [expression]
函数开发四条原则
为了使代码更好的复用和最小程度的代码冗余,掌握函数开发的四个原则尤为重要。
案例嘛,就翻翻github,捞一下我几年前刚学python那会写的代码,看看会不会有什么意外收获。

这个函数实现了自动根据播单id,下载MP3音频的功能。可以分为三个步骤:
-
请求播单,得到播单响应
-
提取播单中MP3地址
-
下载MP3音频并保存到本地
原则一:函数设计要尽量小,嵌套层次不宜过深。
所谓小,就是尽量避免过长函数,因为这样不需要上下拉动滚动条就能获得整体感观,而不是来回翻动屏幕去寻找某个变量或者某条逻辑判断等。函数中需要用到if、elif、while、for等循环语句的地方,尽量不要嵌套过深,最好能控制在3层以内。相信很多人有过这样的经历:为了弄清楚哪段代码属于内部嵌套,哪段属于中间层次的嵌套,哪段属于更外一层”
原则二:函数声明应该做到合理、简单且参数不易太多。
试想,当你看到一个函数名和其实现逻辑不一致的时候作何感想。函数命名应“反映其大体功能外,参数的设计也应该简洁明了,参数个数不宜太多。参数太多带来的弊端是:调用者需要花费更多的时间去理解每个参数的意思,测试人员需要花费更多的精力来设计测试用例,以确保参数的组合能够有合理的输出,这使覆盖测试的难度大大增加。
最近在看《像火箭科学家一样思考》一书【强推此书】,里面就有讲到对复杂与简单的看法,就函数而言,每增加一个参数,就增加函数自身可能出错的风险。
原则三:函数参数设计应该考虑向下兼容。
这个对于经常做项目的同学应该更有体感,敏捷开发模式下,项目迭代更快,对于比较大的项目,可能存在多项目并行的情况,一套代码由多条线并行开发。那么,这种模式下,你设计的函数 就必须 要预见到未来可能会扩展到的功能。例如一个大项目拆分成多个小项目迭代完成,这样你在设计函数初期就必须考虑到未来函数升级需要兼顾到地方,为未来升级留下“口子”,不致于每次迭代都要打改动。
例如本案例,后面要求将下载的音频按类目保存到不同的文件夹下面,那么这样就必须根据MP3的地址动态选择要存放的文件夹,所以函数入参就必须增加一个目录的参数,试想,如果在本代码上改动,影响范围有多大呢?
当然解法也有,就是在函数设计之初就预留不定长参数或默认参数,以备不时之需。
def DownLoadMp3(id, dir=social):原则四:函数职责尽可能单一。
要保证一个函数只做一件事,就要尽量保证抽象层级的一致性,所有的语句尽量在一个粒度上。同时在一个函数中处理多件事情也不利于代码的重用。本案例的改进版,可以将代码拆分成三部分:信息提取、下载、流程编排。具体实现如下:
# 1.获取音频Mp3信息def getMp3Response(id):url = "http://fm.xinli001.com/broadcast"querystring = {"pk": id}headers = {'accept': "application/json, text/javascript, */*; q=0.01",'x-requested-with': "XMLHttpRequest",'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36",'cache-control': "no-cache",'postman-token': "3a95a7d6-5834-f6ae-5678-82b496bf9c71"}response = requests.request("GET", url, headers=headers, params=querystring)print(response.text)try:res = json.loads(response.text)except:res = ''return res# 2.保存为MP3, 保存到特定文件夹下面:文件夹以专辑名字命名def saveAudio(url, album, filename):filepath = os.getcwd()+'/mp3/'+albumif os.path.exists(filepath):mp3 = os.path.join(filepath + '/', '' + filename + '.mp3')if url == '':print('the url is NUll, pass')else:urllib.request.urlretrieve(url, mp3, cbk)print(filename+'下载完毕')else:os.makedirs(filepath)mp3 = os.path.join(filepath + '/', '' + filename + '.mp3')if url == '':print('the url is NUll, pass')else:urllib.request.urlretrieve(url, mp3, cbk)print(filename+' 下载完毕')# 3.main函数实现流程编排def main():album = '壹心理'for id in range(38, 99395999):res = getMp3Response(id)if res:try:title = str(id) + '-' + res.get('data').get('title')url = res.get('data').get('url')saveAudio(url, album, title)except:print(str(res) + '为空')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号