解读selenium webdriver
概要
WebDriver可以像用户一样驱动原生浏览器,无论是在本地服务器还是在使用Selenium服务器的远程机器上,都标志着浏览器自动化的一个飞跃。
Selenium WebDriver也是控制浏览器代码运行的一种实现方式,通常被简称为WebDriver。
它有以下特点:
-
WebDriver框架设计简单、编程接口设计简明。
-
WebDriver是一个紧凑的面向对象的API。
-
它能有效地驱动浏览器。

原理
组件
使用WebDriver构建一个测试套件,需要你事先了解并能熟练地使用一些不同的组件。就像软件一样,不同的人可以使用不同的术语来表达同一个想法。下面是本说明中术语使用的分类。
术语
-
API:应用程序编程接口,用来操作WebDriver的一组 "命令"。
-
库:一个代码模块,它包含API和实现特定功能的代码。
-
驱动程序:负责控制实际的浏览器。大多数驱动程序是由浏览器厂商自己创建的。驱动程序通常是可执行模块,与浏览器本身一起在系统上运行,而不是在执行测试套件的系统上。PS:有些人把驱动程序也称为代理。
-
框架:用于支持WebDriver套件的附加库。这些框架可能是测试框架,如JUnit或NUnit。它们也可以是支持自然语言功能的框架,如Cucumber或Robotium。框架也可能被编写和使用,如操作或配置被测系统、数据创建、测试等。
框架的作用
WebDriver通过驱动程序与浏览器对话,属于双向通信。WebDriver通过驱动程序向浏览器传递命令,并通过同样的途径接收信息。
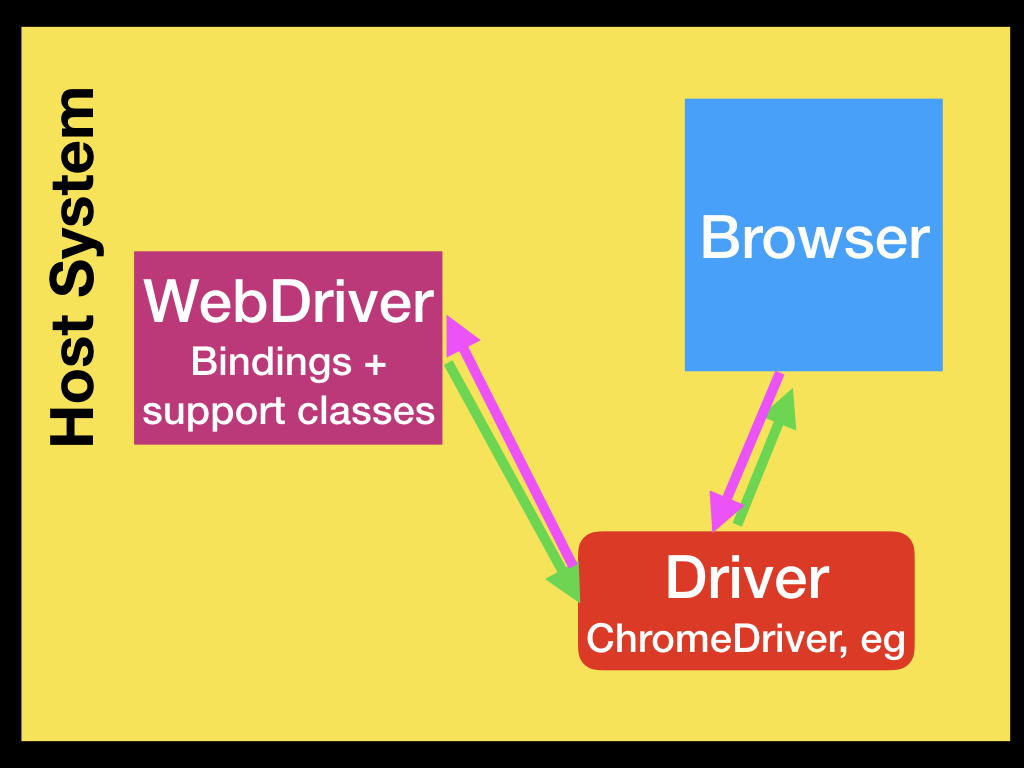
驱动程序是针对浏览器的,如Chrome/Chromium的ChromeDriver,Mozilla Firefox的GeckoDriver等。该驱动程序与浏览器运行在同一系统上。
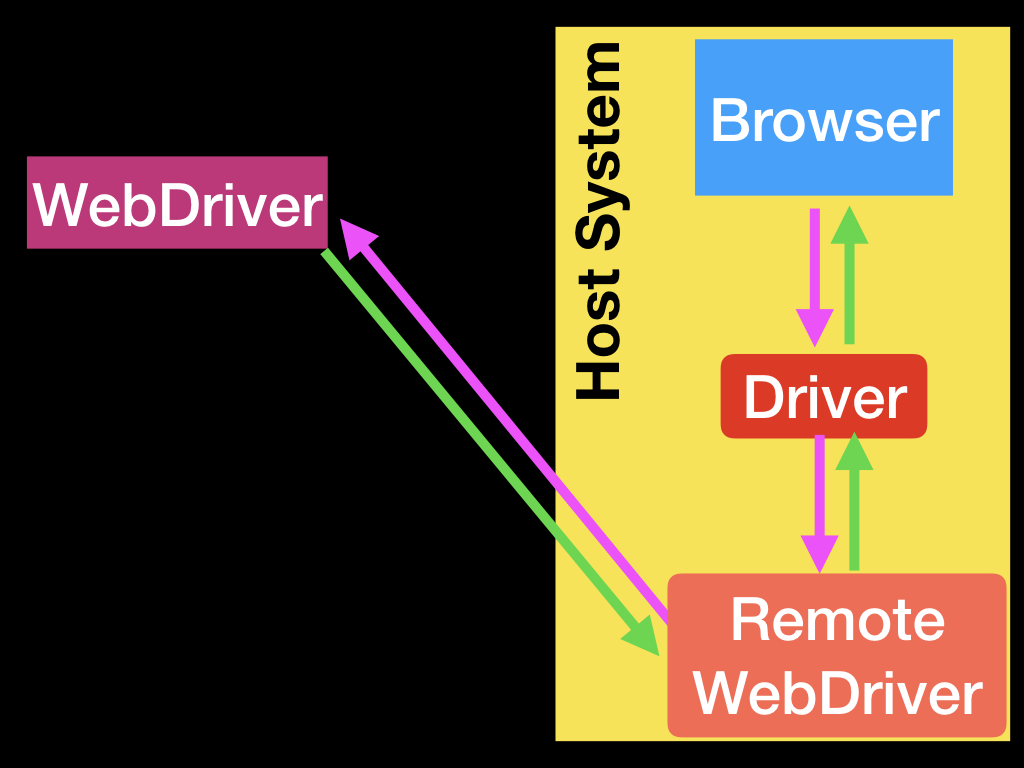
上面这个简单的例子就是直接通信。当然,与浏览器通信也可以通过Selenium Server或RemoteWebDriver进行远程通信。RemoteWebDriver与驱动程序和浏览器运行在相同的系统上。
远程通信也可以使用Selenium Server或Selenium Grid来进行,这两种方式都会与主机系统上的驱动程序进行对话。
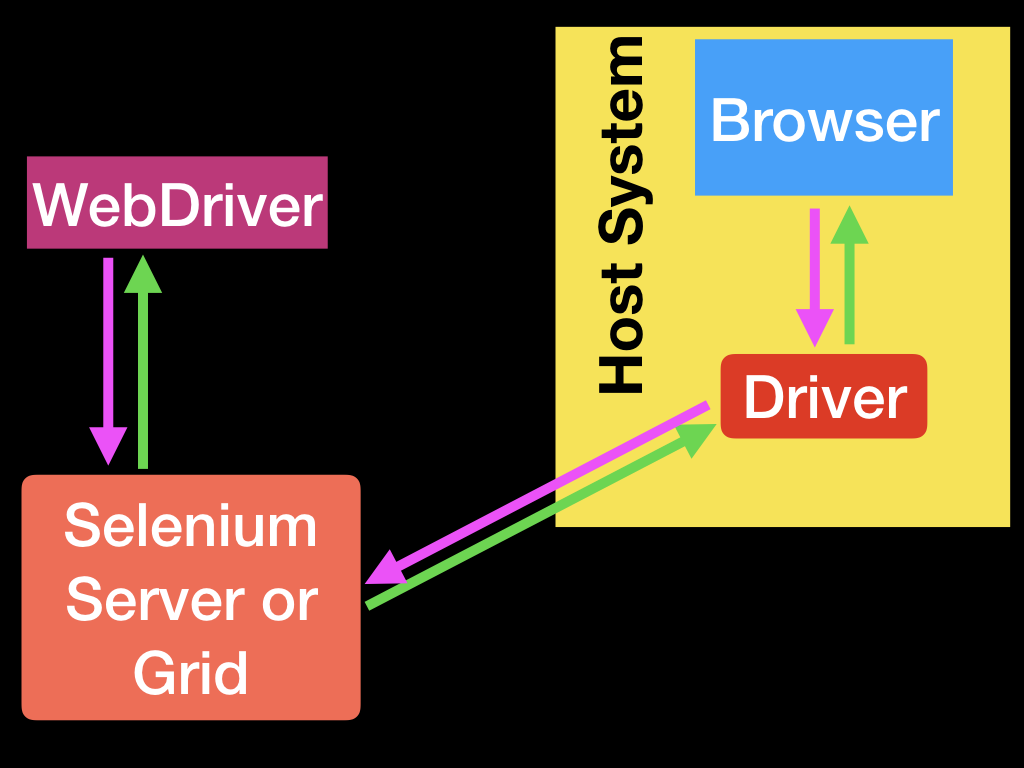
WebDriver有且仅有的职责:通过上述任何一种方式与浏览器进行通信。WebDriver对测试本身一窍不通:它不知道如何比较事物、断言通过或失败,当然也不知道测试报告或Given/When/Then语法。
但这也是各种测试框架发挥作用的关键点,至少你需要一个与语言绑定相匹配的测试框架,比如.NET的NUnit,Java的JUnit,Ruby的RSpec等。
测试框架负责运行和执行WebDriver以及测试中的相关步骤。因此,你可以认为它看起来类似于下面的图片。
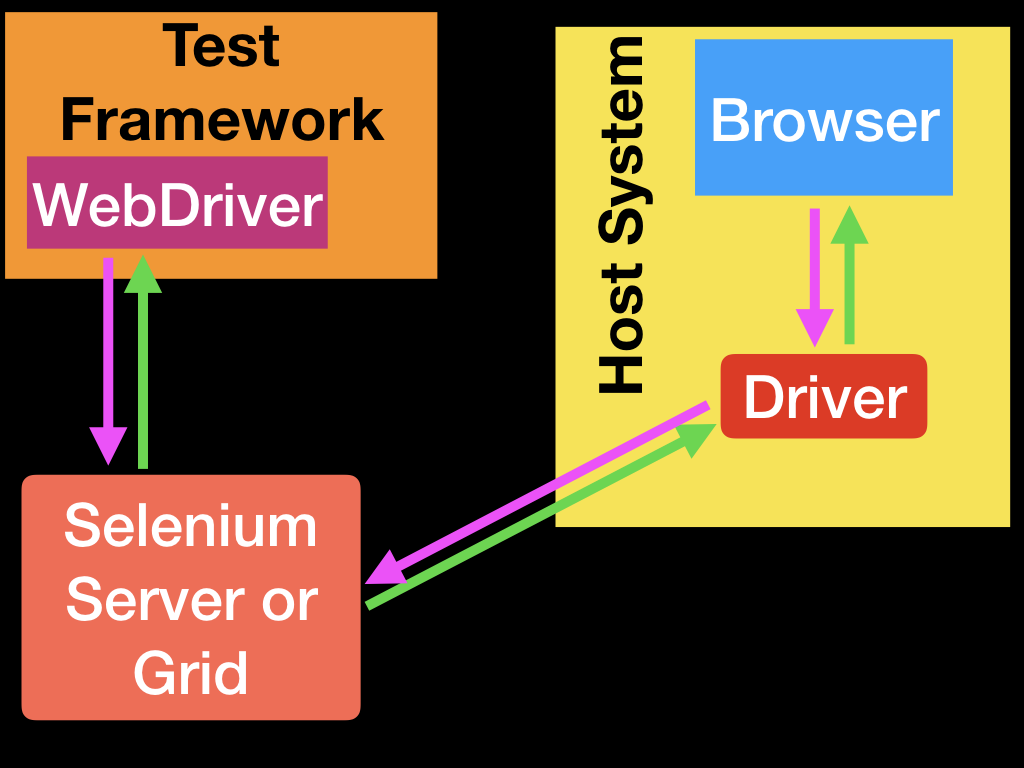
自然语言框架/工具(如Cucumber)可能作为上图中那个测试框架框的一部分而存在,也可能将测试框架完全包裹在自己的实现中。
驱动依赖
通过WebDriver,Selenium可以支持市面上所有主流的浏览器,如Chrom(ium)、Firefox、Internet Explorer、Opera和Safari。在可能的情况下,WebDriver会使用浏览器内置功能支持来驱动浏览器以实现自动化,尽管不是所有的浏览器都能支持远程控制。
WebDriver的目标是尽可能地模拟真实用户与浏览器的交互。
尽管所有的驱动程序都共享一个用于控制浏览器的面向用户的界面,但它们在设置浏览器会话的方式略有不同。由于许多驱动程序的实现是由第三方提供的,所以它们并不包含在标准的Selenium发行版中。
驱动程序实例化、配置文件管理和各种浏览器特定的设置等,使用不同浏览器有不同的要求。本节了让你了解使用不同浏览器的基本要求。
将可执行文件添加PATH路径
大多数驱动程序需要一个额外的可执行文件,以便Selenium与浏览器通信。你可以在启动WebDriver之前手动指定可执行文件的位置,但是这可能会降低你的测试的可移植性,因为可执行文件需要在每台机器上的同一个地方,或者在你的测试代码库中包含可执行文件。
通过在你的系统路径中添加一个包含WebDriver二进制文件的文件夹,Selenium将能够找到额外的二进制文件,而不需要你的测试代码找到驱动的确切位置。
创建一个目录来放置可执行文件,比如/opt/WebDriver/bin,将该目录添加到您的PATH中。
export PATH=$PATH:/opt/WebDriver/bin >> ~/.profile
现在你已经准备环境了。打开的命令提示输入一个新的命令,输入上一步创建的文件夹中的一个二进制文件的名称,例如:
chromedriver
如果您的PATH配置正确,您将看到一些与启动驱动程序有关的输出:

Chromium/Chrome
要驱动Chrome或Chromium,你必须下载chromedriver,并将其放在系统路径上的文件夹中。
在Linux或macOS上,这意味着要修改PATH环境变量。你可以通过执行下面的命令来查看系统路径中由冒号分隔的目录。
echo $PATH要将chromedriver包含在路径上,如果还没有的话,请确保包含chromedriver二进制的父目录。下面这行将设置PATH环境变量的当前内容,加上冒号后添加的额外路径。
$ export PATH="$PATH:/path/to/chromedriver"
配置好chromedriver后,你可以从任何目录下执行chromedriver。
实例化一个Chrome/Chromium会话,您可以执行以下操作:
#Simple assignment from selenium.webdriver import Chrome driver = Chrome()#Or use the context managerfrom selenium.webdriver import Chrome with Chrome() as driver:#your code inside this indent
操作浏览器
-
浏览器导航
启动浏览器后,首先要做的就是打开网站,这可以通过一行代码来实现。
driver.get("https://selenium.dev")-
获取当前 URL
可以使用以下方法从浏览器的地址栏读取当前的URL。
driver.current_url
-
后退Back
driver.back()-
前进Forward
driver.forward()-
刷新Refresh
driver.refresh()
-
获取网站title
driver.title
-
窗口和标签
WebDriver不区分窗口和标签。如果你的网站打开了一个新的标签页或窗口,Selenium会让你使用一个窗口句柄来处理它。每个窗口都有一个唯一的标识符,它在一个会话中保持不变。你可以通过使用以下方法获得当前窗口的窗口句柄。
driver.current_window_handle
-
切换窗口或标签
点击一个在新窗口中打开的链接会将新窗口或标签页集中在屏幕上,但WebDriver不会知道操作系统认为哪个窗口是活动的。要使用新窗口,您需要切换到新窗口。如果你只打开了两个标签页或窗口,并且你知道你从哪个窗口开始,通过消除过程,你可以在WebDriver能看到的两个窗口或标签页上循环,并切换到不是原来的那个窗口。
然而,Selenium 4提供了一个新的api NewWindow,它可以创建一个新的标签(或)新的窗口,并自动切换到它。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Start the driver
with webdriver.Firefox() as driver:
# Open URL
driver.get("https://seleniumhq.github.io")
# Setup wait for later
wait = WebDriverWait(driver, 10)
# Store the ID of the original window
original_window = driver.current_window_handle
# Check we don't have other windows open already
assert len(driver.window_handles) == 1
# Click the link which opens in a new window
driver.find_element(By.LINK_TEXT, "new window").click()
# Wait for the new window or tab
wait.until(EC.number_of_windows_to_be(2))
# Loop through until we find a new window handle
for window_handle in driver.window_handles:
if window_handle != original_window:
driver.switch_to.window(window_handle)
break
# Wait for the new tab to finish loading content
wait.until(EC.title_is("SeleniumHQ Browser Automa创建新的窗口/新的标签页、切换
创建一个新的窗口(或)标签,并将新窗口或标签集中在屏幕上。您不需要切换就可以使用新窗口(或)标签页。如果你有两个以上的窗口(或)标签页被打开,而不是新窗口,你可以在WebDriver可以看到的两个窗口或标签页上循环,并切换到不是原来的那个窗口或标签页。
# Opens a new tab and switches to new tab driver.switch_to.new_window('tab') # Opens a new window and switches to new windowdriver.switch_to.new_window('window'
-
关闭窗口/标签页
当你完成一个窗口或标签页的操作,并且它不是浏览器中最后一个打开的窗口或标签页时,你应该关闭它,并切换回之前使用的窗口。假设你遵循了上一节的代码示例,你将会把之前的窗口句柄存储在一个变量中。
#Close the tab or window driver.close() #Switch back to the old tab or windowdriver.switch_to.window(original_window)
在关闭窗口后忘记切换到另一个窗口句柄,将使WebDriver在已经关闭的页面上执行,并将触发No Such Window异常,必须切换回一个有效的窗口句柄才能继续执行。
在会话结束时退出浏览器
当你完成浏览器会话时,你应该调用退出,而不是关闭。
driver.quit()
Quit的作用:
-
关闭所有与WebDriver会话相关联的窗口和标签。
-
关闭浏览器进程
-
关闭后台驱动进程
-
通知Selenium Grid浏览器不再使用,以便它可以被另一个会话使用(如果你使用Selenium Grid)。
如果没有调用退出,将会留下额外的后台进程和端口在你的机器上运行,这可能会导致后续问题。
一些测试框架提供了一些方法和注释,你可以在测试结束时挂到这些方法和注释上进行拆解。
def tearDown(self):
self.driver.quit()如果不是在测试上下文中运行WebDriver,你可以考虑使用大多数语言提供的try / finally,这样异常仍然会清理WebDriver会话。
try: #WebDriver code here... finally:driver.quit()
Python的WebDriver现在支持python上下文管理器,当使用with关键字时,它可以在执行结束时自动退出驱动程序。
with webdriver.Firefox() as driver:
# WebDriver code here...
# WebDriver will automatically quit after indentationFrames and Iframes
Frames是一种从同一域名上的多个文档构建网站布局的手段,现已被淘汰。除非你使用的是 HTML5 之前的 webapp,否则你不太可能使用它们。Iframes允许从一个完全不同的域中插入一个文档,并且至今仍然被普遍使用。
如果你需要使用Frames或iframe,WebDriver允许你以同样的方式使用它们。如果我们使用浏览器开发工具检查iframe中的button元素,html包含以下内容:
<div id="modal">
<iframe id="buttonframe" name="myframe" src="https://seleniumhq.github.io">
<button>Click here</button> </iframe></div>
如果不是iframe,我们可能会使用以下操作来点击按钮:
driver.find_element(By.TAG_NAME, 'button').click()
然而,如果在iframe之外没有按钮,你可能会得到一个no such element错误。这是因为Selenium只知道顶层文档中的元素。为了与按钮交互,我们需要首先切换到框架,就像我们切换窗口一样,WebDriver提供了三种切换到框架的方法。
WebElement
使用WebElement进行切换是最灵活的选择。你可以使用你喜欢的选择器找到框架并切换到它。
# Store iframe web element
iframe = driver.find_element(By.CSS_SELECTOR, "#modal > iframe")
# switch to selected iframe
driver.switch_to.frame(iframe)
# Now click on button
driver.find_element(By.TAG_NAME, 'button').click()-
name or ID
如果你的frames或iframe有一个id或name属性,可以用这个属性代替。如果名字或ID在页面上不是唯一的,那么第一个找到的名字将被切换到。
# Still witch frame by id driver.switch_to.frame('buttonframe') # Now, Click on the buttondriver.find_element(By.TAG_NAME, 'button').click()
-
使用索引
也可以使用frames的索引,如可以使用JavaScript中的window.frames来查询。
driver.switch_to.frame(1)
-
窗口管理
获取窗口size
# Access each dimension individually
width = driver.get_window_size().get("width")
height = driver.get_window_size().get("height")
# Or store the dimensions and query them later
size = driver.get_window_size()
width1 = size.get("width")
height1 = size.get("height")-
设置窗口size
driver.set_window_size(1024, 768)获取窗口位置
# Access each dimension individually
x = driver.get_window_position().get('x')
y = driver.get_window_position().get('y')
# Or store the dimensions and query them later
position = driver.get_window_position()
x1 = position.get('x')
y1 = position.get('y')
-
设置窗口位置
driver.set_window_position(0, 0)
窗口最大化
driver.maximize_window()
窗口最小化
最小化当前浏览上下文的窗口。该命令的具体行为是针对各个窗口管理器的。
最小化窗口通常会将窗口隐藏在系统托盘中。
注意:该功能适用于Selenium 4及以后的版本。
driver.minimize_window()
窗口全屏
driver.fullscreen_window()
截屏
用于捕获当前浏览环境的屏幕截图,图片为Base64格式编码的屏幕截图。
from selenium import webdriver
driver = webdriver.Chrome()
# Navigate to url
driver.get("http://www.example.com")
# Returns and base64 encoded string into image
driver.save_screenshot('./image.png')
driver.quit()TakeElementScreenshot
用于捕捉当前浏览环境中元素的屏幕截图。WebDriver端点screenshot返回以Base64格式编码的屏幕截图。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# Navigate to url
driver.get("http://www.example.com")
ele = driver.find_element(By.CSS_SELECTOR, 'h1')
# Returns and base64 encoded string into image
ele.screenshot('./image.png')
driver.quit()-
打印页面
在浏览器中打印当前页面。
from selenium.webdriver.common.print_page_options import PrintOptions
print_options = PrintOptions()
print_options.page_ranges = ['1-2']
driver.get("printPage.html")
base64code = driver.print_page(print_options)等待
一般来说,WebDriver可以说是一个阻塞式的API。因为它是一个进程外的库,指示浏览器做什么,而且由于Web平台具有内在的异步性,所以WebDriver并不跟踪DOM的活跃、实时状态。这就带来了一些挑战,我们将在这里讨论。
根据经验,使用Selenium和WebDriver所产生的大多数间歇性问题都与浏览器和用户指令之间的竞赛条件有关。一个例子可能是,用户指示浏览器导航到一个页面,然后在试图找到一个元素时得到一个no such element错误。
<!doctype html>
<meta charset=utf-8>
<title>Race Condition Example</title>
<script>
var initialised = false;
window.addEventListener("load", function() {
var newElement = document.createElement("p");
newElement.textContent = "Hello from JavaScript!";
document.body.appendChild(newElement);
initialised = true;
});
</script>
driver.get("file:///race_condition.html");
WebElement element = driver.findElement(By.tagName("p"));
assertEquals(element.getText(), "Hello from JavaScript!");
这里的问题是,WebDriver中使用的默认页面加载策略在调用导航后返回之前,会监听document.readyState是否变为 "完成"。因为p元素是在文档完成加载后添加的,所以这个WebDriver脚本可能是间歇性的。之所以说 "可能 "是间歇性的,是因为在没有明确等待或阻止这些事件的情况下,无法保证异步触发的元素或事件。
幸运的是,WebElement接口上可用的普通指令集--如WebElement.click和WebElement.sendKeys--都保证是同步的,即函数调用不会返回(或者回调式语言中的回调不会触发),直到命令在浏览器中完成。高级用户交互API,键盘和鼠标,是个例外,因为它们明确是作为 "按我说的做 "的异步命令。
等待是让自动任务执行经过一定时间后再继续下一步。
为了克服浏览器和你的WebDriver脚本之间的竞赛条件的问题,大多数Selenium客户端都带有一个等待包。当采用等待时,你使用的是通常所说的显式等待。
Explicit wait
显式等待对Selenium客户端的命令式、过程式语言是可用的。它们允许你的代码停止程序执行,或者冻结线程,直到你传递给它的条件解决。该条件以一定的频率被调用,直到等待的超时结束。这意味着,只要条件返回一个假值,它就会一直尝试和等待。
由于显式等待允许你等待一个条件发生,所以它们很适合用于同步浏览器和它的DOM以及你的WebDriver脚本之间的状态。
为了弥补我们之前的错误指令集,我们可以采用等待的方式,让 findElement 调用等待,直到脚本中动态添加的元素被添加到 DOM 中。
from selenium.webdriver.support.ui import WebDriverWait
def document_initialised(driver):
return driver.execute_script("return initialised")
driver.navigate("file:///race_condition.html")
WebDriverWait(driver).until(document_initialised)
el = driver.find_element(By.TAG_NAME, "p")
assert el.text == "Hello from JavaScript!"我们以函数引用的形式传递条件,即等待将反复运行,直到其返回值为truthhy。一个 "真实 "的返回值是指在当前语言中评价为布尔值真的任何东西,比如一个字符串、数字、布尔值、一个对象(包括一个WebElement),或者一个填充的(非空)序列或列表。这意味着一个空列表评价为false。当条件是真实的,阻塞等待被中止时,条件的返回值就会变成等待的返回值。
有了这些知识,并且因为wait实用程序默认忽略没有这样的元素错误,我们可以重构我们的代码,使其更加简洁:
from selenium.webdriver.support.ui import WebDriverWait
driver.navigate("file:///race_condition.html")
el = WebDriverWait(driver).until(lambda d: d.find_element_by_tag_name("p"))
assert el.text == "Hello from JavaScript!"Implicit wait
不同于显式等待的等待类型,称为隐式等待。通过隐式等待,WebDriver在试图找到任何元素时,会在一定时间内轮询DOM。当网页上的某些元素不是立即可用,需要一些时间来加载时,这很有用。
隐式等待元素出现的功能在默认情况下是禁用的,需要在每个会话的基础上手动启用。混合使用显式等待和隐式等待会导致意想不到的后果,即即使元素可用或条件为真,等待的时间也会达到最长。
警告:不要混合隐式和显式等待。不要混合隐式和显式等待。这样做会导致不可预知的等待时间。例如,设置隐式等待为10秒,显式等待为15秒,可能会导致20秒后发生超时。
隐式等待是告诉WebDriver,当试图找到一个或多个元素时,如果它们不是立即可用,则会在一定时间内轮询DOM。默认设置为0,意味着禁用。一旦设置,隐式等待将在会话的整个过程中被设置。
driver = Firefox()
driver.implicitly_wait(10)
driver.get("http://somedomain/url_that_delays_loading")
my_dynamic_element = driver.find_element(By.ID, "myDynamicElement")FluentWait
FluentWait实例定义了等待条件的最长时间,以及检查条件的频率。
用户可以配置等待以在等待时忽略特定类型的异常,例如在页面上搜索元素时忽略NoSuchElementException。
driver = Firefox()
driver.get("http://somedomain/url_that_delays_loading")
wait = WebDriverWait(driver, 10, poll_frequency=1, ignored_exceptions=[ElementNotVisibleException, ElementNotSelectableException])
element = wait.until(EC.element_to_be_clickable((By.XPATH, "//div")))Http proxies
代理服务器作为客户端和服务器之间请求的中介。简单来说,流量通过代理服务器流向你所请求的地址并返回。
使用Selenium自动化脚本的代理服务器可以:
-
捕捉网络流量
-
模拟网站的后台调用
-
在复杂的网络拓扑结构或严格的企业限制/政策下访问所需网站。
-
如果你在企业环境中,浏览器无法连接到一个URL,很可能这个环境需要代理才能访问。
Selenium WebDriver提供了一种代理设置的方式。
from selenium import webdriver
PROXY = "<HOST:PORT>"
webdriver.DesiredCapabilities.FIREFOX['proxy'] = {
"httpProxy": PROXY,
"ftpProxy": PROXY,
"sslProxy": PROXY,
"proxyType": "MANUAL",
}
with webdriver.Firefox() as driver:
# Open URL
driver.get("https://selenium.dev")
网页加载策略
定义当前会话的页面加载策略。默认情况下,当Selenium WebDriver加载页面时,它遵循正常的网页加载策略。当页面加载耗费大量时间时,总是建议停止下载额外的资源(如图片、css、js)。
文档的document.readyState属性描述了当前文档的加载状态。默认情况下,WebDriver将暂缓响应driver.get()(或)driver.navigate().to()调用,直到文档准备状态完成。
在SPA应用中(如Angular、React、Ember),一旦动态内容已经加载完毕(即一旦pageLoadStrategy状态为COMPLETE),点击链接或在页面中执行一些操作将不会向服务器发出新的请求,因为内容是在客户端动态加载的,不需要完全刷新页面。
SPA应用程序可以动态加载许多视图,而不需要任何服务器请求,所以网页加载策略将始终显示COMPLETE状态,直到我们做一个新的driver.get()和driver.navigate().to()。
WebDriver 网页加载策略支持以下方式:
-
normal
这将使Selenium WebDriver等待整个页面被加载。当设置为正常时,Selenium WebDriver会一直等待,直到加载事件被返回,默认加载方式也是normal。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.page_load_strategy = 'normal'
driver = webdriver.Chrome(options=options)
# Navigate to url
driver.get("http://www.google.com")
driver.quit()-
eager
这种加载方式具体是,Selenium WebDriver等待到初始HTML文档被完全加载和解析,并放弃样式表、图像和子框架的加载。
当设置为eager时,Selenium WebDriver会等待DOMContentLoaded事件的返回。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.page_load_strategy = 'eager'
driver = webdriver.Chrome(options=options)
# Navigate to url
driver.get("http://www.google.com")
driver.quit()-
none
当设置为none时,Selenium WebDriver只等待下载初始页面。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.page_load_strategy = 'none'
driver = webdriver.Chrome(options=options)
# Navigate to url
driver.get("http://www.google.com")
driver.quit()Remote WebDriver
用户可以像在本地使用WebDriver一样远程使用它。主要的区别是,远程WebDriver需要被配置,以便它能在单独的机器上运行测试。
远程WebDriver由两部分组成:一个客户端和一个服务器。客户端是你的WebDriver测试,而服务器是一个简单的Java servlet,它可以托管在任何现代JEE应用程序服务器上。
Remote WebDriver server
服务器将始终运行在装有您要测试的浏览器的机器上。服务器可以从命令行或通过代码配置来使用。
-
命令行启动服务器
一旦你下载了selenium-server-standalon-{VERSION}.jar,把它放在你要测试的浏览器的电脑上。然后,在该jar的目录下,运行以下内容。
java -jar selenium-server-standalone-{VERSION}.jar
-
运行服务器的注意事项
调用者需要正确地终止每个会话,调用Selenium#stop()或WebDriver#quit。
selenium服务器为每个正在进行的会话保留内存日志,当调用Selenium#stop()或WebDriver#quit时,这些日志会被清除。如果你忘记终止这些会话,你的服务器可能会泄漏内存。如果你保持了非常长的会话,你可能需要每隔一段时间就停止/退出一次(或者用-Xmx jvm选项增加内存)。
-
Timeouts
服务器支持两种不同的超时方式,可以设置如下。
java -jar selenium-server-standalone-{VERSION}.jar -timeout=20 -browserTimeout=60
-
浏览器超时
控制浏览器被允许挂起的时间(数值以秒为单位)。
-
超时
控制客户端在恢复会话之前允许离开多长时间(值为秒)。
PS:从2.21版本开始,不再支持系统属性selenium.server.session.timeout。
browserTimeout是作为普通超时机制失效时的一种备份超时机制,应该主要用于网格/服务器环境中,以保证崩溃/丢失的进程不会停留太久,污染运行环境。
Remote WebDriver client
要运行远程WebDriver客户端,我们首先需要连接到远程WebDriver。我们通过将URL指向运行测试的服务器地址来实现。为了定制我们的配置,我们设置所需的功能。下面是一个实例化远程WebDriver对象的例子,它指向我们的远程Web服务器www.example.com,在Firefox上运行我们的测试。
from selenium import webdriver
firefox_options = webdriver.FirefoxOptions()
driver = webdriver.Remote(
command_executor='http://www.example.com',
options=firefox_options
)
driver.get("http://www.google.com")
driver.quit()为了进一步定制我们的测试配置,我们可以添加其他需要的功能。
-
浏览器选项
例如,你想在Windows XP上运行Chrome,使用Chrome 67版本。
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.set_capability("browserVersion", "67")
chrome_options.set_capability("platformName", "Windows XP")
driver = webdriver.Remote(
command_executor='http://www.example.com',
options=chrome_options
)
driver.get("http://www.google.com")
driver.quit()本地文件检测器
本地文件检测器允许将文件从客户端机器传输到远程服务器。例如,如果一个测试需要将一个文件上传到Web应用程序,远程WebDriver可以在运行时自动将文件从本地机器传输到远程Web服务器,这样就可以从运行测试的远程机器上传文件。默认情况下不会被启用,需要通过以下方式启用。
from selenium.webdriver.remote.file_detector import LocalFileDetector
driver.file_detector = LocalFileDetector()
定义好上述代码后,就可以按照以下方式测试上传文件。
driver.get("http://sso.dev.saucelabs.com/test/guinea-file-upload")
driver.find_element(By.ID, "myfile").send_keys("/Users/sso/the/local/path/to/darkbulb.jpg")声明
未经允许,不得私自转载,否则追究法律责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号