多模型的安卓恶意软件分类
Drebin样本的百度网盘下载链接我放在安卓恶意软件分类那篇文章了,大家自行下载。最近看到一篇论文,题为**HYDRA: A multimodal deep learning framework for malware classification**。本篇论文提到了一个多模式的恶意软件分类框架,具体实现时,就是一个多输入单输出的网络框架。框架示意图如下
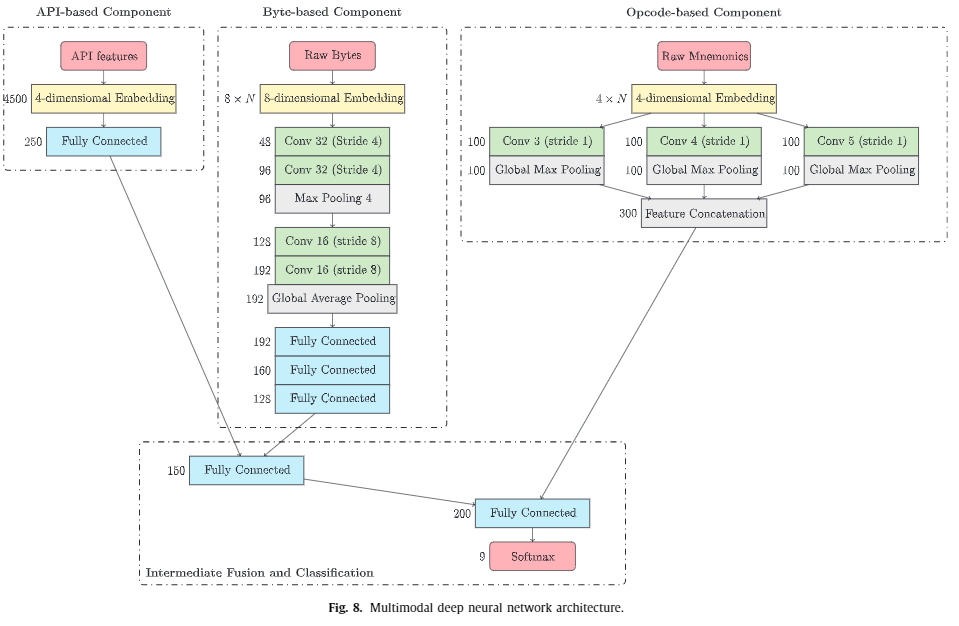
于是催生了本次实验。在前几篇博文中,在做恶意软件分类时,最后都会加上特征融合,并且效果都不错。此次实验旨在比较论文框架与特征融合。基于安卓恶意软件分类,所用特征为API,opcode的n-gram,权限。这也是论文模型的3输入。
论文框架
先基于opcodeui,以及权限特征做二输入分类,看看效果,在加入API特征,验证模型的扩展性。模型用keras的函数式api搭建,代码如下
# stacked generalization with neural net meta model on blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from sklearn.metrics import accuracy_score
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.utils import plot_model
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import concatenate
from tensorflow.keras.layers import *
from numpy import argmax
from tensorflow.keras.preprocessing.text import Tokenizer
import tensorflow.keras.preprocessing.text as T
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
import numpy as np
import pandas as pd
#数据读取以及乱序
subtrainfeature1 = pd.read_csv("D:\\android\\dataset\\3_gram.csv")
subtrainfeature2 = pd.read_csv("D:\\android\\dataset\\permissions.csv")
labels = subtrainfeature2["Class"]
train_data_1 = subtrainfeature1.iloc[:,:].values
subtrainfeature2.drop(["Class"], axis=1, inplace=True)
train_data_2 = subtrainfeature2.iloc[:,:].values
import numpy as np
index = np.random.permutation(len(labels))
labels = labels[index]
train_data_1 = train_data_1[index]
train_data_2 = train_data_2[index]
p1 = int(len(labels)*0.8)
train_labels = labels[:p1]
test_labels = labels[p1:]
data_1_train = train_data_1[:p1]
data_1_test = train_data_1[p1:]
data_2_train = train_data_2[:p1]
data_2_test = train_data_2[p1:]
#模型构造1 3-gram
input1 = Input(shape=(343))
model1_x = Dense(200,input_dim = 343, activation='relu')(input1)
model1_x = Dense(150, activation = 'relu')(model1_x)
model1_x = Dense(150, activation = 'relu')(model1_x)
model1_x = Dense(150, activation = 'relu')(model1_x)
model1_x = Dense(100, activation = 'relu')(model1_x)
model1_x = Dense(100, activation = 'relu')(model1_x)
model1_x = Dense(100, activation = 'relu')(model1_x)
model1_x = Dense(50, activation = 'relu')(model1_x)
model1_x = Dense(50, activation = 'relu')(model1_x)
model1_x = Dense(50, activation = 'relu')(model1_x)
model1_x = Dense(30, activation = 'relu')(model1_x)
#模型构造2 权限特征
input1 = Input(shape=(343))
model1_x = Dense(200,input_dim = 343, activation='relu')(input1)
model1_x = Dense(150, activation = 'relu')(model1_x)
model1_x = Dense(150, activation = 'relu')(model1_x)
model1_x = Dense(150, activation = 'relu')(model1_x)
model1_x = Dense(100, activation = 'relu')(model1_x)
model1_x = Dense(100, activation = 'relu')(model1_x)
model1_x = Dense(100, activation = 'relu')(model1_x)
model1_x = Dense(50, activation = 'relu')(model1_x)
model1_x = Dense(50, activation = 'relu')(model1_x)
model1_x = Dense(50, activation = 'relu')(model1_x)
model1_x = Dense(30, activation = 'relu')(model1_x)
#全连接层
full = concatenate([model1_x,model2_x])
full = Dense(60,activation='relu')(full)
full = Dense(60,activation='relu')(full)
full = Dense(30,activation='relu')(full)
output = Dense(1,activation='sigmoid')(full)
#打印模型
model = Model(inputs=[input1,input2], outputs=output)
plot_model(model, show_shapes=True, to_file='model_andorid.jpg')
model.compile(
optimizer='adam'
,loss = 'binary_crossentropy'
,metrics=['acc']
)
#训练
from sklearn.model_selection import StratifiedKFold
history = model.fit(
[data_1_train,data_2_train],
train_labels,
epochs=50,
batch_size = 64,
validation_data=([data_1_test,data_2_test], test_labels)
)
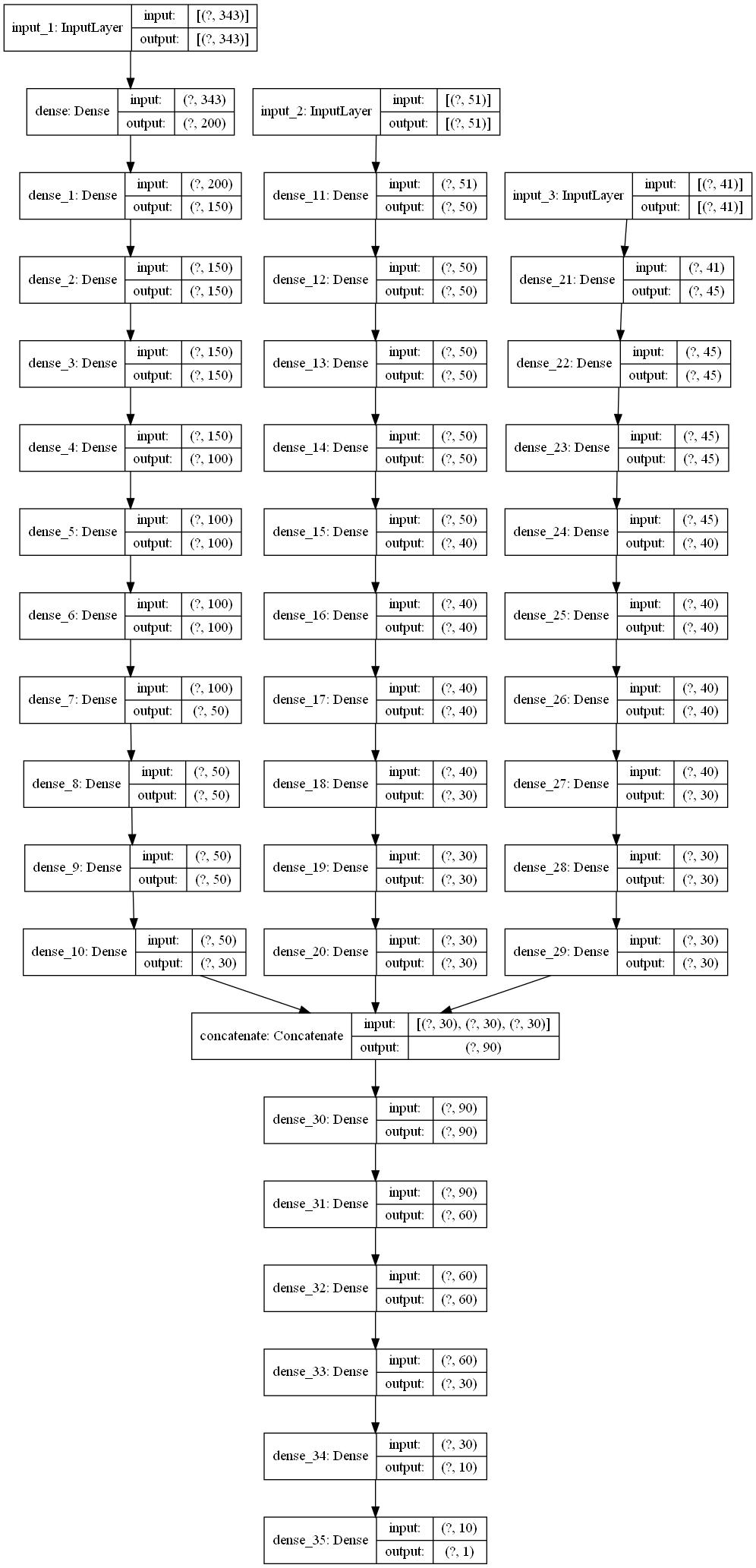
模型示意图如下:
贴上api提取的代码:
import os
from androguard.misc import AnalyzeAPK
from androguard.core.androconf import load_api_specific_resource_module
from collections import *
import re
import os
import pandas as pd
malware_dir = "D:\\android\\dataset\\drebin-1"
kind_dir = "D:\\android\\dataset\\Benign_2016\\"
permmap = load_api_specific_resource_module('api_permission_mappings')
def get_apis(file_path):
out = AnalyzeAPK(file_path)
dx = out[2]
cc = Counter([])
dd = Counter([])
for meth_analysis in dx.get_methods():
meth = meth_analysis.get_method()
cc[meth.get_name()]+=1
name = meth.get_class_name() + "-" + meth.get_name() + "-" + str(meth.get_descriptor())
for k,v in permmap.items():
if name == k:
dd[meth.get_name()]+=1
return cc,dd
def file_api_count(file_path):
a,d = get_apis(file_path)
e = Counter([])
for k,v in a.items():
if v>=100:
e[k]+=v
return d,e
count = 1
mapapi_mal_less = defaultdict(Counter)
mapapi_mal_more = defaultdict(Counter)
mapapi_kind_less = defaultdict(Counter)
for file in os.listdir(malware_dir):
print("counting the {0} file...".format(str(count)))
count+=1
apk_dir = os.path.join(malware_dir,file)
mapapi_mal_less[file], mapapi_mal_more[file]= file_api_count(apk_dir)
count = 1
for file in os.listdir(kind_dir):
print("counting the {0} file...".format(str(count)))
count+=1
apk_dir = os.path.join(kind_dir,file)
mapapi_kind_less[file], mapapi_kind_more[file] = file_api_count(apk_dir)
cc = Counter([])
for d,lists in mapapi_kind_more.items():
for item,num in lists.items():
cc[item]+=num
for d,lists in mapapi_mal_more.items():
for item,num in lists.items():
cc[item]+=num
selectedfeatures = {}
tc = 0
for k,v in cc.items():
if v >= 100:
selectedfeatures[k] = v
print (k,v)
tc += 1
#存入与权限特征无关的api,并未用到
dataframelist = []
for fid,count in mapapi_kind_more.items():
standard = {}
standard["Class"] = 0
for feature,num in count.items():
if feature in selectedfeatures:
standard[feature] = num
dataframelist.append(standard)
for fid,count in mapapi_mal_more.items():
standard = {}
standard["Class"] = 1
for feature,num in count.items():
if feature in selectedfeatures:
standard[feature] = num
dataframelist.append(standard)
df = pd.DataFrame(dataframelist)
df.to_csv("D:\\android\\dataset\\api_more.csv",index=False)
#存入与权限特征有关的api
ff = Counter([])
selectfeature2 = []
for d,lists in mapapi_kind_less.items():
for item,num in lists.items():
selectfeature2.append(item)
for d,lists in mapapi_mal_less.items():
for item,num in lists.items():
selectfeature2.append(item)
for fid,count in mapapi_kind_less.items():
standard = {}
standard["Class"] = 0
for feature,num in count.items():
if feature in selectfeature2:
standard[feature] = num
else:
standard[feature] = 0
dataframelist2.append(standard)
for fid,count in mapapi_mal_less.items():
standard = {}
standard["Class"] = 1
for feature,num in count.items():
if feature in selectfeature2:
standard[feature] = num
else:
standard[feature] = 0
dataframelist2.append(standard)
df2 = pd.DataFrame(dataframelist2)
df2.to_csv("D:\\android\\dataset\\api_less.csv",index=False)
50轮训练结果的最后十轮精确度如下
0.9850,0.9750,0.9750,0.9775,0.9800,0.9775,0.9725,0.9775,0.9750,0.9775
加入api特征,代码与上文类似,其模型示意图如下:
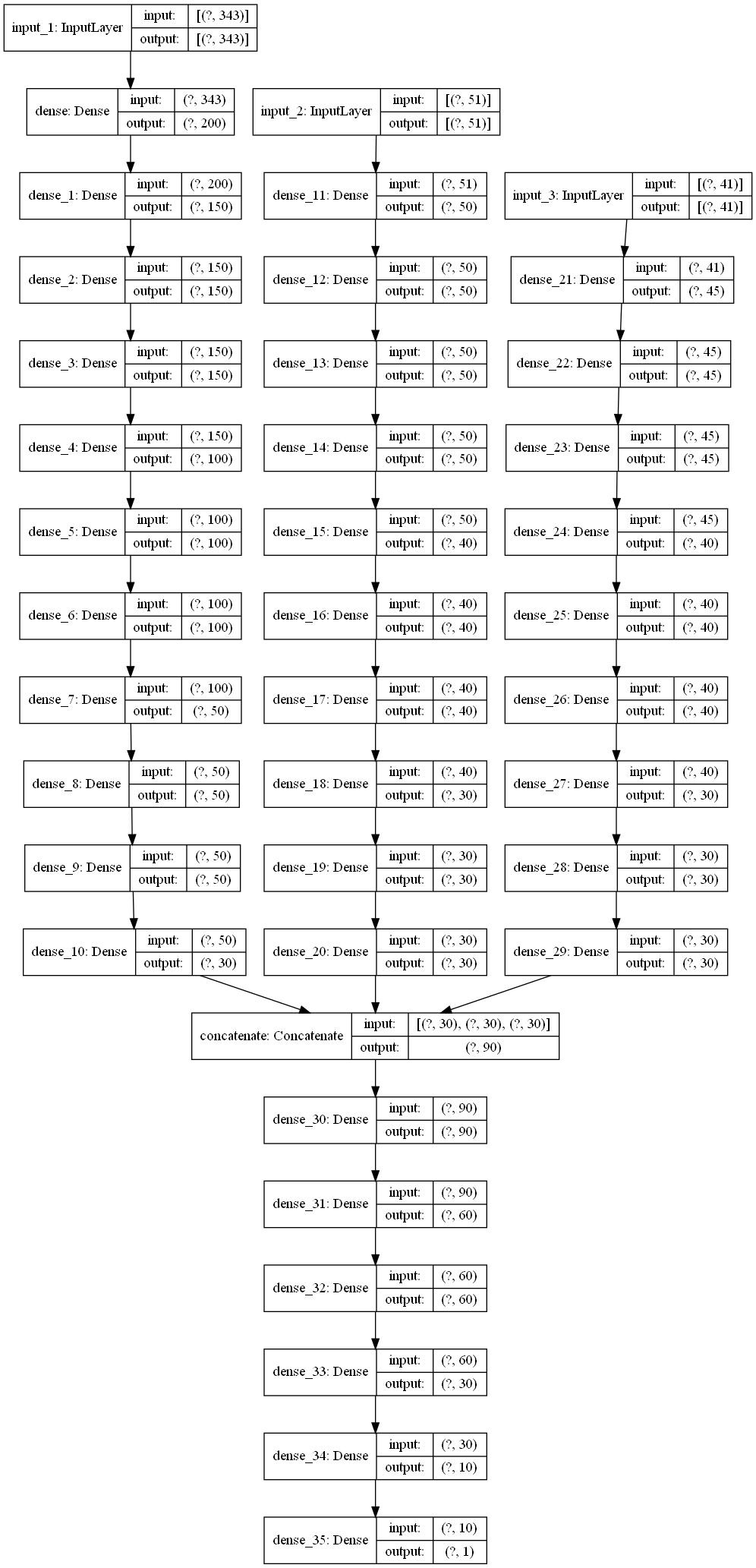
50轮训练结果的最后十轮精确度如下:
0.9875,0.9875,0.9875,0.9875,0.9875,0.9875,0.9875,0.9900,0.9900,0.9900
特征融合
尝试之前的方法,将特征融合在一起,看看精确度
先尝试两特征融合,opcode n-gram和权限特征,代码在上一篇博文中可以找到,就不贴了,最终基于深度学习的十轮交叉验证精确度如下:
[0.99, 0.98, 0.985, 1.0, 0.995, 0.97, 0.98, 0.995, 0.97, 0.9849246]
加入api特征后,精确度如下:
[0.99, 0.99, 0.985, 1.0, 1.0, 0.99, 0.985, 0.98, 0.975, 0.9798995]
总结
比较结果如下:
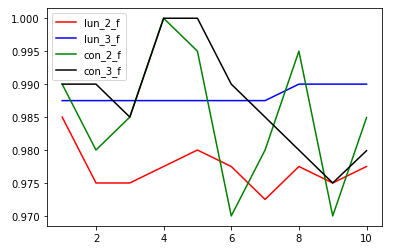
可见多模型精度不如单模型特征融合,但是稳定性胜于特征融合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号