基于权限的安卓恶意软件检测
Drebin样本的百度网盘下载链接我放在安卓恶意软件分类那篇文章了,大家自行下载。本次实验接上一次基于操作码序列的安卓恶意软件检测实验,这一次选取的特征是权限特征。即将apk文件反编译后,在AndroidManifest.xml文件中可以看到这个软件所需要的权限,如下图,本次实验的主要利用这些权限特征做二分类实验

数据集
数据集基本与上一次基于操作码序列的实验相同,1000个来自drebin的恶意软件,以及1000个上次实验的良性软件。由于这次调取权限特征采用了androguard库中的get_permissions()方法,无需自己去正则匹配,不仅大大简化了操作,而且大大缩短了特征提取的时间。
特征提取
本次实验的特征提取方法:先遍历良性软件和恶意软件集,计算出每个权限特征出现的次数,选取出现次数大于100的特征,共51个。则特征表是以个51列的表,一个软件对应特征表中的一行,如果有这个特征,则这列置1,没有则置0。代码如下:
from androguard.core.bytecodes import apk, dvm #代码比较粗糙,为了简便,函数未作封装
from androguard.core.analysis import analysis
from androguard.core.bytecodes.dvm import DalvikVMFormat
from collections import *
import re
import os
import pandas as pd
malware_dir = "D:\\android\\dataset\\drebin-1"
kind_dir = "D:\\android\\dataset\\Benign_2016\\"
map3gram_kind = defaultdict(Counter)
map3gram_mal = defaultdict(Counter)
count = 1
for file in os.listdir(malware_dir):
print ("counting the 3-gram of the {0} file...".format(str(count)))
print(file)
count+=1
apk_dir = os.path.join(malware_dir,file)
app = apk.APK(apk_dir)
map3gram_mal[file] = app.get_permissions()
count = 1
for file in os.listdir(kind_dir):
print ("counting the 3-gram of the {0} file...".format(str(count)))
print(file)
count+=1
apk_dir = os.path.join(kind_dir,file)
app = apk.APK(apk_dir)
map3gram_kind[file] = app.get_permissions()
cc = Counter([])
for d,lists in map3gram_kind.items():
for list in lists:
cc[list]+=1;
for d,lists in map3gram_mal.items():
for list in lists:
cc[list]+=1;
selectedfeatures = {}
tc = 0
for k,v in cc.items():
if v >= 100:
selectedfeatures[k] = v
print (k,v)
tc += 1
dataframelist = []
for fid,op3gram in map3gram_kind.items():
standard = {}
standard["Class"] = 0
for feature in selectedfeatures:
if feature in op3gram:
standard[feature] = 1
else:
standard[feature] = 0
dataframelist.append(standard)
for fid,op3gram in map3gram_mal.items():
standard = {}
standard["Class"] = 1
for feature in selectedfeatures:
if feature in op3gram:
standard[feature] = 1
else:
standard[feature] = 0
dataframelist.append(standard)
df = pd.DataFrame(dataframelist)
df.to_csv("D:\\android\\dataset\\permissions.csv",index=False)
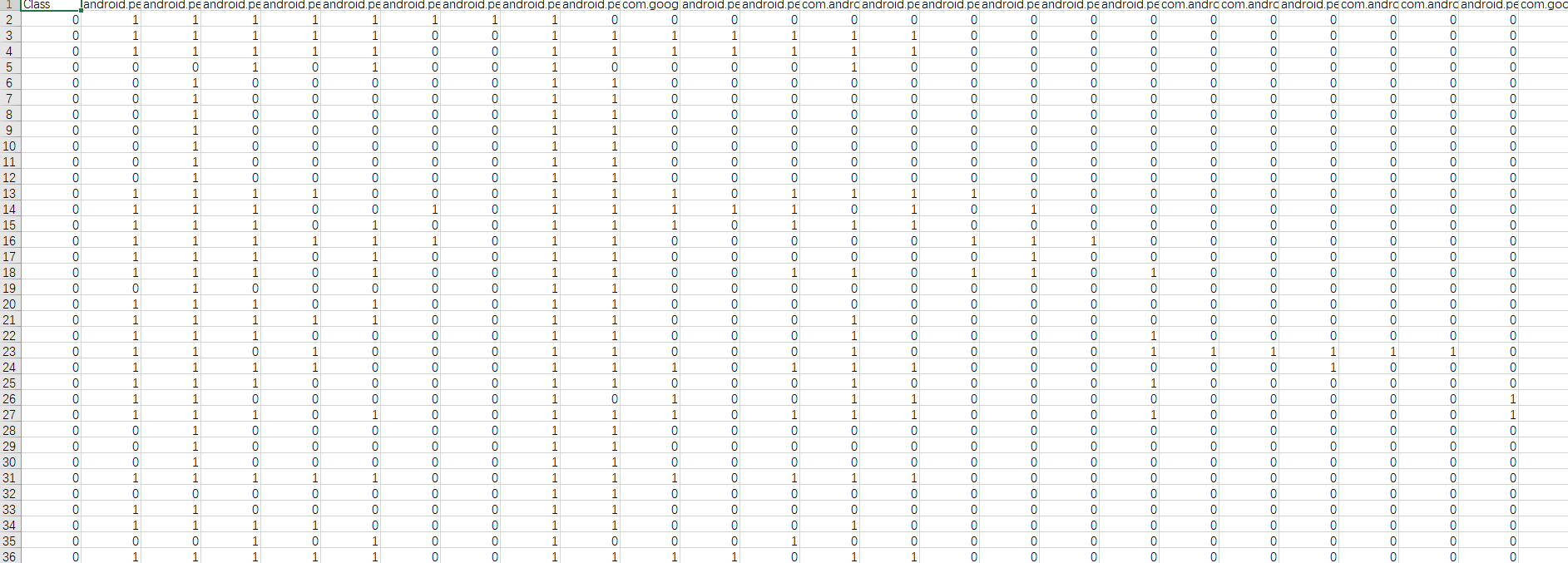
提取后特征表如下
机器学习
机器学习算法采用随机森林,同样10交叉验证,代码如下
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
import pandas as pd
train_data = pd.read_csv('D:\\android\\dataset\\permissions.csv')
labels = train_data["Class"]
data = train_data.iloc[:,1:]
data = data.iloc[:,:].values
srf = RF(n_estimators=500, n_jobs=-1)
clf_s = cross_val_score(srf, data, labels, cv=10)
print(clf_s)
最终结果如下
array([0.97 , 0.985 , 0.985 , 0.96 , 0.975 ,0.965 , 0.9 , 0.965 , 0.91 , 0.95979899])
深度学习
继续使用深度学习方法试一试。
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from tensorflow.keras.preprocessing.text import Tokenizer
import tensorflow.keras.preprocessing.text as T
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
import numpy as np
train_data = pd.read_csv('D:\\android\\dataset\\permissions.csv')
labels = train_data["Class"]
data = train_data.iloc[:,1:]
train_data = data.iloc[:,:].values
from sklearn.model_selection import StratifiedKFold
seed = 7
np.random.seed(seed)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
cvscores = []
for train, test in kfold.split(train_data, labels):
model = keras.Sequential()
model.add(layers.Dense(50,input_dim = 51, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(16, activation = 'relu'))
model.add(layers.Dense(1, activation = 'sigmoid'))
model.compile(
optimizer = 'adam',
loss='binary_crossentropy',
metrics=['acc']
)
model.fit(train_data[train],labels[train],epochs=60, batch_size=256,verbose = 0)
scores = model.evaluate(train_data[test], labels[test], verbose=0)
print(scores[1])
cvscores.append(scores[1])
print(cvscores)
最终结果:
[0.945, 0.935, 0.96, 0.97, 0.965, 0.95, 0.93, 0.945, 0.935, 0.959799]
特征结合
和上一次微软恶意软件检测一样,尝试将操作码特征和权限特征结合起来,代码如下
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
import pandas as pd
import numpy as np
subtrainfeature1 = pd.read_csv("D:\\android\\dataset\\3_gram.csv")
subtrainfeature2 = pd.read_csv("D:\\android\\dataset\\permissions.csv")
clas = range(1,2000)
subtrainfeature1.insert(0,'num',clas)
subtrainfeature2.insert(0,'num',clas)
subtrain = pd.merge(subtrainfeature1,subtrainfeature2,on="num")
labels = subtrain["Class_x"]
subtrain.drop(["Class_x","num"], axis=1, inplace=True)
subtrain = subtrain.iloc[:,:].values
srf = RF(n_estimators=500, n_jobs=-1)
clf_s = cross_val_score(srf, subtrain, labels, cv=10)
10轮交叉验证准确度如下:
array([0.985 , 0.995 , 0.99 , 0.96 , 0.9 ,0.975 , 0.96 , 0.985 , 0.985 , 0.98492462])
总结
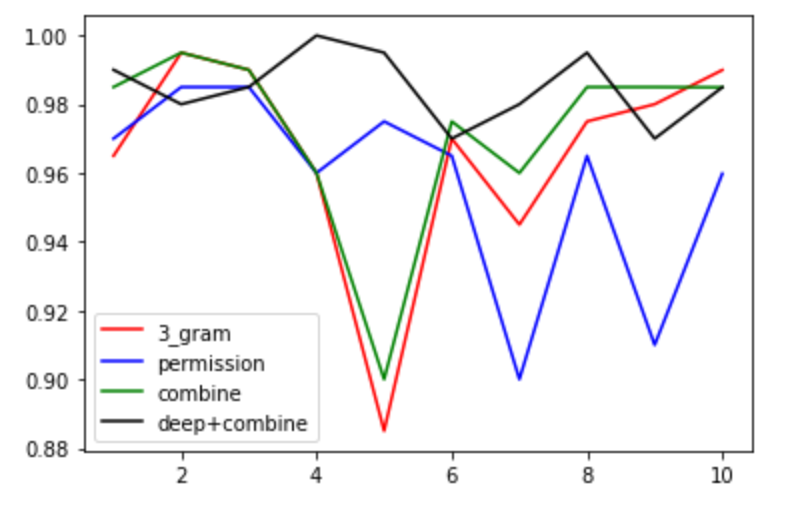
权限特征准确度:
array([0.97 , 0.985 , 0.985 , 0.96 , 0.975 ,0.965 , 0.9 , 0.965 , 0.91 , 0.95979899])
3-gram分类准确度:
array([0.965 , 0.995 , 0.99 , 0.96 , 0.885 ,0.97 , 0.945 , 0.975 , 0.98 , 0.98994975])
特征结合准确度:
array([0.985 , 0.995 , 0.99 , 0.96 , 0.9 ,0.975 , 0.96 , 0.985 , 0.985 , 0.98492462])
深度学习+特征结合:
[0.99, 0.98, 0.985, 1.0, 0.995, 0.97, 0.98, 0.995, 0.97, 0.9849246]
比较图如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号