论文笔记 Android恶意软件检测即家族分类
介绍
本文主要针对Android,提出了一种新方法,可以高效地检测恶意软件并将其高精度地归类于相应的恶意软件家族。本文采用在线分类器,使本文的方法即使在大量应用程序中也可以很好地扩展,并且可以轻松适应新应用程序中的不同特征。本文使用n-gram分析和特征哈希从应用程序中提取多级指纹。 然后将其每个子指纹输入到专用的在线分类器。 根据分类器的置信度得分和设计的组合函数,将最终确定应用程序是良性还是恶意软件,或者在应用程序归因于家族归属的情况下(它属于哪个恶意软件家族)
安卓最重要的恶意软件防护措施之一是基于权限的安全模型,即用户授予应用程序权限。但很大一部分用户倾向于盲目的授予请求的权限。削弱了理论上合理的保护。
另外有一些方法建议使用与应用程序不同的功能,例如请求的权限,API调用,动态行为或多种功能的组合,并利用相似性比较指标或机器学习算法来区分恶意软件和良性应用。 这些方法通常依靠专家分析来确定要处理的特定功能,这些功能可能会排除应用程序中的其他重要功能。 此外,通过明确定义区分功能,恶意软件编写者可以更轻松地相应地更新其恶意软件,从而逃避检测。
另外,也可以基于n-gram分析进行恶意软件检测。除此之外还有一些研究在考虑从APK文件中获取信息。
恶意软件检测和家族归因均属于分类问题,其中前者是两类问题,后者是多类问题。 为了对AUT进行分类,每个分类器的决策得分将由我们设计的组合函数融合,然后将输出特定类别中应用程序的最终决策。 在恶意软件检测的情况下,特定类别将是恶意软件或良性应用程序,而在恶意软件家族归属的情况下,它将是特定的恶意软件家族。
Android基础知识
n-gram分析从给定文件中提取一系列n项目特征。于DEX和APK文件,以每字节的粒度级别提取n-gram,而对于汇编文件,粒度级别为每条指令。 对于XML文件(在APK中为二进制XML形式),我们将其转换为人类可读的格式,然后提取n元语法XML字符串。n-gram中n是一个参数,用于表示应用程序的基础要素空间的尺寸。 在几篇著作中已经研究了其对Andorid应用分类准确性的影响。 选择的ngram大小应在应用程序的多维表示与合理数量的独特功能之间取得良好的平衡。
在线分类器
由多个子指纹(以位向量的形式)组成的应用程序指纹是应用程序的抽象表示。 位向量中的每个位都可以视为一个特征。 相似的应用程序共享相似的位向量模式,而不同的应用程序将具有非常不同的位向量。 本文使用机器学习算法自动提取重要特征,这些特征有助于区分恶意软件和良性应用程序或不同恶意软件家族。
位向量表示为BV ∈ {0, 1}l,其中l是位向量的长度。本文的方法不储存向量本身而是其状态,所以用一位存储。如下图所示的分类器示意图。本文为每个子指纹使用专用的分类器,可放大区分特征,提高分类准确性。
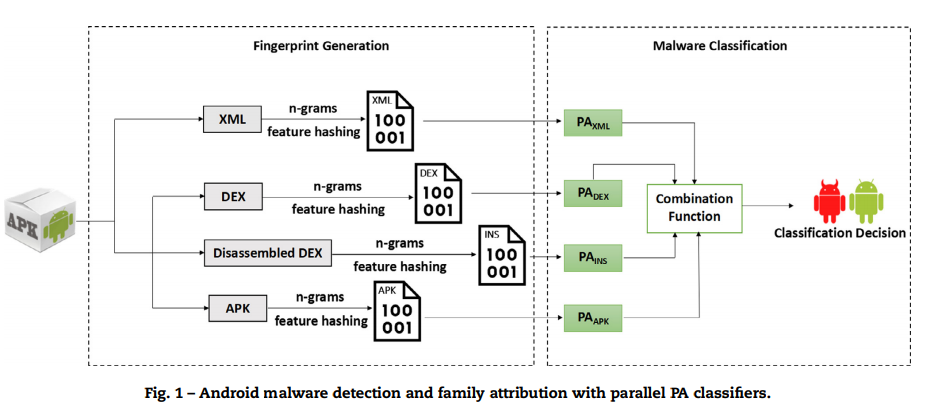
关于本文的机器学习算法,本文选择使用在线被动攻击(PA)分类器。在线分类器轮流操作,在每个循环中,它都会接收样本作为预测的输入,然后接收样本的真实标签以更新模型。 由于训练后的模型可以从传入样本流中逐步学习,因此这种学习称为增量学习。
对于多类别恶意软件家族归因问题,可以使用“一对多”(OvA)策略,其中针对每个类别训练上述单个二进制分类器,特定类别的成员标记为+1,所有其他类别采样为-1。 然后,基于具有最高置信度得分的分类器来预测样本的标签。
下面简单介绍本文采用的多类决策:
如下图所示,Sk表示第k个PA分类器的置信度得分,假设有M个恶意软件家族,并且子指纹分别基于XML文件,DEX文件,程序集文件和整个APK文件。则Sk(Cm)|PAxml表示通过XML分类器该恶意软件属于第m个软件家族的概率。
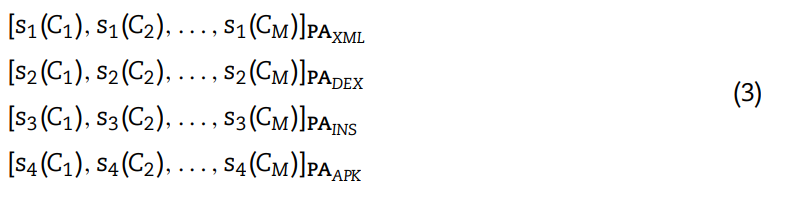
根据上述,最终决策方案可以自由指定。最直观的方式是多数投票。即在决定该恶意软件是属于C1....CM中哪一家族时,先在每一行中选出置信度最大的那一个Sk。拿上图举例,每行会产生一个Sk(max),总共四个,然后比较所在列,拥有Sk列数最多的那一列则为最终的决策。当票数相等时,则将所在列的置信度相加,取最大的那一列。
除了多数投票外,还可以使用替代组合函数,例如得分的平均值和得分的最大值,由于置信度带有符号,本文不采用此方法。
在恶意软件检测的情况下,每个得分列表Sk仅包含一个得分而不是M个得分。 稍作更改后,上述三个组合功能仍然适用。 现在,多数投票方法将对得分进行正面(表示恶意)或负面(表示良性)投票; 如果票数相等,则将正和负置信度得分相加,并根据具有较大绝对值的总和的符号做出最终决策。 分数平均值方法现在仅对分数取平均值,然后根据平均值的符号做出最终决定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号