

yolo v1记录
这里主要从输入数据增量和检测层的处理两个方面来说下v1版本,文中使用的参数和数值为代码中默认值并以voc数据集为例来说明的。
一.输入数据处理
网络的配置使用batch和subdivisions两个参数来控制网络输入图片的批量处理,以batch作为一次读取图片个数,以batch/subdivisions作为一次传播使用的图片个数,以subdivisions为一次读取的数据用来传播的循环次数。
输入的数据也分图片数据和标注数据,先说对图片的操作。
读取图片后,程序会做增量处理,根据detection层的jitter参数对图片做抖动。假设一张图片原始的宽高为w和h,则jitter后的宽高为
dw = w*jitter
dh = h*jitter
对于宽度来说,在-dw和dw两值之间随机产生两个整数pleft和pright作为新的图片的参考,以
w - pleft - pright
作为新的图片的宽度,对高度来说,处理方式相同,所以新的图片是在jitter的比例下放大或者缩小。以jitter为默认的0.2为例,它向上下左右随机的伸展或者缩小1/5的原图的比例来生成一张新的图片。新图片的填充方式:重叠的部分,原值拷贝;缩小的部分丢弃;扩展的部分以原图的边缘值填充。下图给出了一个可能的图片增量的输出图片(分别为原图和生成的新图)
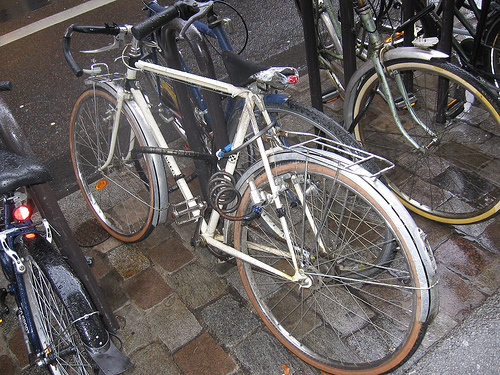

然后将生成的新图片缩放至统一大小,再随机选择是否将图片左右180°翻转,将最终的图片作为传播的输入数据。
是否需要抖动及抖动的幅度控制以及是否翻转图像等增量操作在实际使用中需要仔细考虑,如果目标有很多靠边的情况,就不能抖动或者jitter的值要控制的很小,如果是字符识别等目的,显然就不能翻转图像。
图片处理完后,开始处理对应图片的标注信息。因为输入的目标位置是相对于原图的坐标,在新生成的图片中,对应的目标位置就发生了变化,所以原坐标信息需要转换成相对于新图的目标位置,本文后续所说的标注信息指的就是新图对应的转换后的信息,程序使用的也是这个信息。
算法将输入图片划分成7*7的方格,根据标注的目标坐标信息找到其中心所在的方格的位置,其计算方法为
int col = (int)(x*num_boxes);
int row = (int)(y*num_boxes);
以x坐标为例,目标中心真实坐标的为x*w,图片分成7份每份宽度w/7,则在横向7个格的第几个格为x*w/(w/7)=x*num_boxes,取整即为所在方格的位置,余数就是相对该方格的偏移,从上面计算方法可以看出,余数意义就是目标中心位于这个方格宽高的比例(x方向相相对值是w/7)。
每一个方格包含 1+4+20=25个标注信息,一张图片给定了7*7*25=1225个缓冲用来存储标注信息,如果图片中标注了n个目标,根据上面转换方式,可以找到每一个目标所在的方格,其中一个目标在缓冲区的位置为
(col + row * 7) * 25
例如一个标注目标类别为5,其内部信息分别为1(默认为0,表示没有目标)、[00000100000000000000]、x、y(xy为为上述相对方格位置偏移量)、w、h,如下所示
[1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 x y w h]
从上面thruth的使用方式可以看出,如果一张图片有两个目标很近,近到两者标注坐标的中心落在了7*7的同一个方格,就只有一个目标被接受,从代码实现上看,接受的是先读取的目标信息,后续的在同一个格子的目标被忽略。
二.检测层处理
数据输入完成后,就开始网络的传播了,v1版本的中间网络使用的也是传统的方式,没什么可说的,这里主要学习下最后一层detection layer的处理方式。
网络将输入图片转换成7*7*((1 + 4)*2+20) = 7 * 7 * 30的维度,每个1*1*30的维度对应图片中7*7的单元格中的一个,中间含有类别预测和bbox的坐标预测,如果目标的中心落在某个网格,则这个网格就负责预测这个目标.总的来说就是让网络来负责预测类别和位置信息。
具体入下:
网络的输出大小是按上面所说的,但是输出的意义并不像thruth的方式来的,它的布局如下
|
|
|
|
|
|
…… |
|
|
|
…… |
|
|
|
|
|<-----------------7*7*20----------------à|<---------7*7*2--à----------------->|<----------------------7*7*4*2-----------------------à|
|<--------------类别置信度-------------à|<-有目标置信度à----------------->|<---------------------目标位置---------------------à|
每一个网格要预测两个bbox、两个confidence和一个类别置信度,这个confidence表示该网络预测的bbox有目标的置信度和该目标的位置有多准确两重意思,类别置信度表示该物体属于某一类的概率,则confidence*类别置信度表示了网格中是某个物体的概率。
是否有目标,只可能为0或1,所以他的loss为(I{0|1} - output)^2
类别置信度采用softmax回归,这个比较好理解,只是他的loss没有采用传统的交叉熵方式,也是直接采用加权值的平方差的方式。命中的网格处计算loss=∑(thrush-output)^2 。
位置的loss采用(1-iou)^2
这里还要提一下loss的设计,代码实现中的loss没有严格按照论文里的定义来实现,但其本质是没有变的。
网上有人说一个方格只能预测出两个物体,而且是同一类别的,个人觉得是不对的。一个网格确实只能预测两个物体,所以它对集中的小目标效果不好,但是两个物体只能是同一类别,没有理论依据,从test中可以看出,只要两个物体中类别的置信度大于阈值,是都可以输出的。之后在进行非极大值抑制:对于同一类别的98个结果,不管是否是同一个方格预测的目标,只要两者IOU不大于阈值,则较小的目标丢弃;而不同类别之间时不进行nms操作的,所以同一个网格输出两个不同的目标是没有问题的。

