
文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于肽段鉴定中错误发生率估计的能体现重复性的诱饵数据库)
文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于肽段鉴定中错误发生率估计的能体现重复性的诱饵数据库)
期刊名:Journal of Proteome Research
发表时间:(2020年3月)
IF:3.78
单位:
- 滑铁卢大学计算机科学学院
- 多伦多细胞生物学和SPARC生物项目中心
- 多伦多大学分子遗传学系
技术:肽段鉴定,诱饵数据库构建
一、 概述:
该研究开发了一种基于de Bruijn图形模型的诱饵数据库构建算法。这种算法构建的诱饵数据库在保证随机性的同时,在很大程度上保留了目标数据库中的序列结构的重复性。而将de Bruijn策略与其他常见诱饵库构建策略进行对比得到的结果表明,在0.01这一较高的错误发生率(FDR)水平上该方法能鉴定到更多的肽段。
二、 研究背景:
在基于质谱的蛋白质组学研究中,数据库搜索方法是最常用的肽段鉴定方法。其原理首先利用蛋白质序列,通过酶切法将其转化为肽,建立理论肽段序列数据库;接着通过将实际谱图与理论数据库中的肽段序列相匹配来实现肽段鉴定。
数据库搜索方法需要一个合理的方法来评估结果的FDR,而目标诱饵(target-decoy)方法是最常见的一种。该方法使用由目标蛋白序列和人工生成的诱饵序列组成的串联序列数据库与MS/MS谱匹配。理想情况下,谱图匹配到诱饵和目标序列的概率分布是相同的。因此,诱饵匹配数成为目标数据库中错误匹配数的估计,FDR则是通过诱饵匹配数与报告的目标匹配数之间的比率来估计的。
因此合理地构建诱饵库就是目标诱饵方法的核心问题,使用de Bruijn方法构建诱饵库可以避免常用的反库或随机库等诱饵库所产生的缺陷。
三、实验设计:
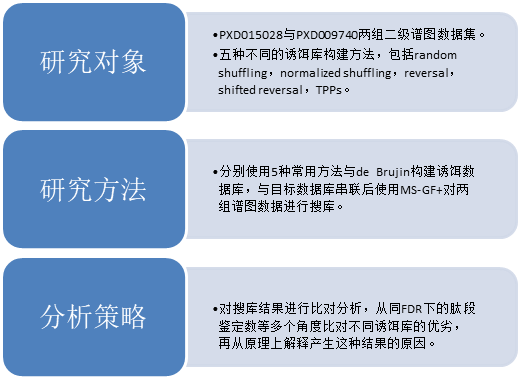
四、研究成果:
1、目标库与不同方法生成的诱饵库中肽段总数与肽段种类数目。可以看出在目标库中大约有一半的数目是重复肽段。因此random shuffling与normalized shuffling生成的诱饵库包含的肽段种类更多,这最终会导致FDR的偏高。而其他四种方法利用一定的规则生成诱饵序列,避免或减少了这一问题。

2、不同诱饵库在1%FDR下的肽段谱图匹配数。Normalized Shuffling方法的FDR是在乘以0.519的标准化因子后计算的。从图中可以看出使用de brujin诱饵库得到的肽段数量最多。这个现象可以从以下几个角度解释:
对于Random Shuffling,Normalized Shuffling与TPP方法而言,性能较差的原因是诱饵数据库中肽段的种类比目标库要多。由于诱饵肽种类的增加,质谱谱图与更多的诱饵肽进行了匹配评分,这可能导致一些分数处在阈值上的真正该被匹配到的目标肽被随机产生的诱饵肽所淘汰。这对正确识别目标肽有不利的影响。
而对于Reversal与shifted Reversal方法,性能较差的原因可能是目标肽和诱饵肽及其谱图的碎片离子之间存在高度的相关性。

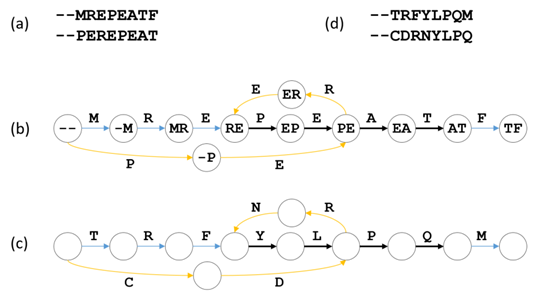
3、de brujin的原理实例图:(a) 两个目标库蛋白序列的示例。(b) 对应的k=2的de-Bruijn图。每个目标序列对应于图中的一条路径。第一个序列、第二个序列和两个序列共享的边分别为蓝色、橙色和黑色。(c) 边缘标签随机替换为其他氨基酸。(d) 诱饵蛋白序列是通过在重标记图中跟踪两个目标蛋白的路径获得的。
简而言之,氨基酸在替换时会考虑以此氨基酸为起始的k个氨基酸所组成的序列,相同的序列会将此氨基酸替换为同一个随机氨基酸,从而达到保护序列重复性的效果。
五、文章亮点(结论讨论):针对生成用于数据库搜库方法FDR估计的诱饵库,本文提出了一种数学上严格且易于实现的方法de brujin,能够在保留蛋白质重复结构的同时生成带有随机性的诱饵序列。此方法避免了简单的随机方法不保留目标数据库中的重复片段与Reversal方法使目标诱饵库之间相似性过高的问题,且从数据与原理两个角度说明了de Bruijn方法的良好性能。
阅读人:刘佳维

 浙公网安备 33010602011771号
浙公网安备 33010602011771号