
Journal of Proteome Research | 人类牙槽骨蛋白的蛋白质组学和n端分析:改进的蛋白质提取方法和LysargiNase消化策略增加了蛋白质组的覆盖率和缺失蛋白的识别 | (解读人:卜繁宇)
文献名:Proteomic and N-Terminomic TAILS Analyses of Human Alveolar Bone Proteins: Improved Protein Extraction Methodology and LysargiNase Digestion Strategies Increase Proteome Coverage and Missing Protein Identification(人类牙槽骨蛋白的蛋白质组学和n端分析:改进的蛋白质提取方法和LysargiNase消化策略增加了蛋白质组的覆盖率和缺失蛋白的识别)
期刊名:Journal of Proteome Research
发表时间:2019年12月
IF:3.780
单位:
不列颠哥伦比亚大学
物种:人牙槽骨
技术:蛋白质组学,N末端组学
一、 概述:
本研究选取健康人群的牙槽骨,优化骨蛋白的提取方法和工作流程:一方面采用多种蛋白酶消化策略提高肽段的覆盖度,另一方面,采用TAILS N-terminomics技术来鉴定天然骨蛋白的N末端和蛋白水解产生的新N末端。本研究首次使骨基质完全溶解,共鉴定出>2600个蛋白、1368个N-termini、一个具有高可信度证据的Missing Protein-- pannexin-3,以及17个具有MS以外证据的PE1蛋白。
二、 研究背景:
在人类蛋白质组计划(HPP)中,仍有2129个蛋白缺乏令人信服的证据来证明它们的存在,这些蛋白被称之为“Missing Protein”,简称MP。尽管骨骼作为人体的一个重大组成部分,但与其他组织相比,它的蛋白质组学研究明显不足,而骨蛋白提取的技术挑战是造成这一现象的主要原因。因此,本研究优化骨蛋白的提取方法和工作流程,并应用于蛋白质组学。
三、实验设计:

四、研究成果:
1. 骨蛋白的提取过程(如图1):表面非矿化类骨质在4M GuHCl (G1)中溶解,然后在矿化类骨质(G1沉积物)中释放与0.5 M EDTA (E段)结合的蛋白;脱矿化作用后,在第二次的4M GuHCl (G2)中释放不溶性胶原蛋白。接下来是两个新的固相酶解步骤: trypsin消化(T1)和6 M尿素+LysC消化(U1)。值得注意的是,在U1部分中,由COL2A1 (isoform 2)、COL19A1、COL28A1、LACRT和SPATA31E1编码的5个蛋白被鉴定出来。 其中COL19A1基因编码XIX型胶原蛋白、COL28A1基因编码XXVIII型胶原蛋白,而XIX型和XXVIII型胶原蛋白在人类骨骼中尚未见报道,这反映出该工作流程的效用。

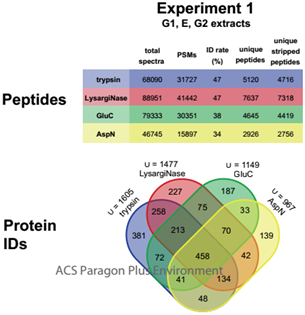
2. 在G1、E和G2部分结束后,采用多种蛋白酶消化策略。各种蛋白酶鉴定蛋白数量如下:胰蛋白酶1605、 LysargiNase1477、GluC1149和AspN 965,其中有773个蛋白没有被胰蛋白酶鉴定出来。
3. 利用TAILS来富集G1、E和G2提取物中的N-termini蛋白。Shotgun 分析中有~2%的氨基端被封锁住,相比之下,TAILS有~84%,表示出TAILS有>40倍富集N端半胰蛋白酶肽的能力。利用iProphet结合Shotgun 和TAILS分析,共得到8334个PSMs (1% FDR),其中1368个是非冗余的N端多肽。图D显示出大多数(60%)的N端PSMs是二甲基化的,表明它们是蛋白水解产生的新N端;乙酰化约占总PSMs的25%。

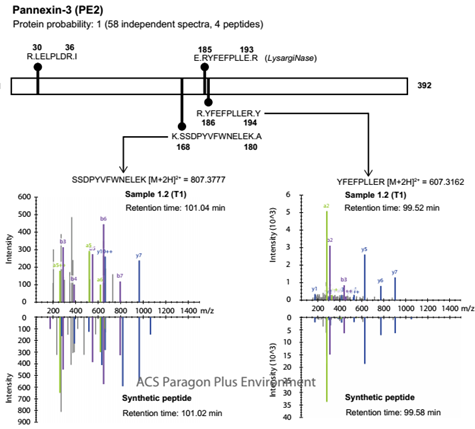
4. 在胰蛋白酶消化后,从G2不溶性高交联的胶原基质中鉴定出Pannexin-3(NX_Q96QZ0-1、PE2 category、PANX3、chromosome position 11q24.2) 。共获得58个PSMs,分别对应4个不同的肽段序列,其中一个肽段序列长度不超过9个氨基酸,其余符合HPP V2.1准则,并利用合成肽进行验证。
五、文章亮点(结论讨论):
本研究的亮点在于优化骨骼提取方法,首次使骨基质完全溶解;采用多种蛋白酶固相消化,从G1、E和G2不溶性交联蛋白中释放肽段, 提高了肽段覆盖度;首次分析了骨蛋白的N末端,并对健康个体骨骼的蛋白水解过程提供了新的见解。本研究的方法将有助于在未来人类疾病和动物模型中对骨骼和其他矿化组织的蛋白质组分析。
阅读人:卜繁宇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号