MCP|WJ|Identification of candidate plasma protein biomarkers for cervical cancer using the multiplex proximity extension assay(利用多重邻位延伸分析技术进行宫颈癌血浆蛋白候选生物标记物的鉴定研究)
文献名:Identification of candidate plasma protein biomarkers for cervical cancer using the multiplex proximity extension assay(利用多重邻位延伸分析技术进行宫颈癌血浆蛋白候选生物标记物的鉴定研究)
期刊名:Molecular & Cellular Proteomics
发表时间:2019.04.01
IF:5.232
单位:
1. 乌普萨拉大学
2. 乌普萨拉科学园
3. 于默奥大学
物种:人类血浆
技术:靶向蛋白质组学
一、概述:
该研究利用多重邻位延伸分析技术(PEA)进行宫颈癌患者的的血浆蛋白质进行鉴定。在宫颈癌患者和对照组中共靶向测定并准确定量了100个蛋白,其中80个蛋白在癌症患者组中含量增加,11种蛋白(PTX3, ITGB1BP2, AXIN1, STAMPB, SRC, SIRT2, 4E-BP1, PAPPA, HB-EGF, NEMO, IL27)在区分患者组和对照组中具有0.96的灵敏度(真阳性率)和1.0的特异度(真阴性率)。在前瞻性复制队列研究中,该模型在区分诊断为宫颈癌时收集的样本和诊断为宫颈癌前收集样本中,具有0.78的灵敏度和0.56的特异度。若将诊断前样本或治疗后样本与对照组进行比较,则蛋白组上并无显著差异。
二、研究背景:
在女性癌症中,宫颈癌是第三大常见癌症。宫颈癌是由于致癌型人乳头瘤病毒(HPV)的持续感染所致。在有宫颈癌监测的国家中,宫颈细胞学检测手段(Pap smear)是最为普遍的。但由于细胞学检测灵敏度较低,故美国也将HPV检测作为联合检测手段。虽然与细胞学检测相比HPV检测具有更高的灵敏度,但由于HPV暂时性感染的高患病率,单独的HPV检测对于宫颈癌诊断呈现出较低的特异度。目前,虽然有许多代谢物研究力图在HPV阳性的女性中进行宫颈癌的早期检查,但目前尚无任何一个可应用到临床。该研究通过PEA的方法,力图在可能发展为宫颈癌的女性中鉴定到合适的血浆蛋白生物标记物。
三、实验设计:

四、研究成果:
1.经过质控过滤和数据前处理后,在发现队列和重复队列中鉴定并定量到100个蛋白;在发现队列中,48个蛋白存在显著性差异;28个蛋白在病人组显著上调。在重复队列中,诊断当日收集的血浆组(Case)和至少诊断前3年收集的血浆组(Ctrl)之间,13个蛋百存在显著差异;其中p-value最小(5.97 x 10-17)的蛋白为PTX3,其归一化后箱线图见图1。
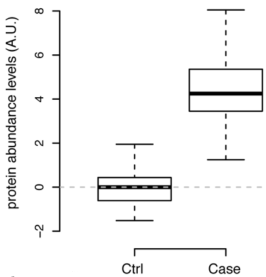
图1.重复队列中PTX3归一化后在Case组和Ctrl组中含量箱线图
2.发现队列中,共有80个蛋白在病人组中高于对照组,通过朴素贝叶斯的机器学习方法建立模型,在训练集中灵敏度0.98(95% CI 0.93-1.0),特异度1.0(95% CI 1.0-1.0),见图2-1;验证集中灵敏度0.96(95% CI 0.89-1.0)特异度1.0(95% CI 1.0-1.0),见图2-2。
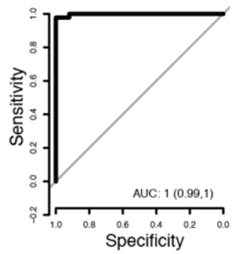

图2-1,80个蛋白模型中,训练集ROC曲线 图2-2,80个蛋白模型中验证集ROC曲线
将该模型应用到重复队列的数据中,其各组在朴素贝叶斯模型下输出值,各组与对照组进行分类的ROC曲线下AUC值以及ROC曲线分别展示于图2-3,2-4,2-5中,其中[-6166,-1328]代表该组数据的采集时间为诊断前6166天到1328天之间;[-1323,-1] 代表该组数据的采集时间为诊断前1323天到1天之间;[0,0]代表该组数据的采集时间为诊断当天;[28,1605]代表该组数据的采集时间为诊断后28天到1605天之间;[1629,7022]代表该组数据的采集时间为诊断前1629天到7022天之间。

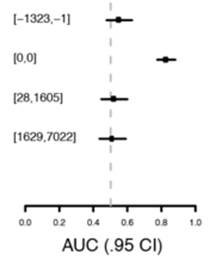
图2-3,80个蛋白模型中重复队列下各组输出值 图2-4,80个蛋白模型中,重复队列中各组与[-6166,-1328]组在ROC曲线下的AUC值
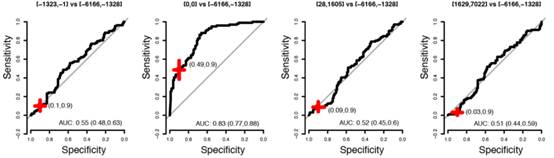
图2-5[-6166,-1328]与[-1323,-1],[-6166,-1328]与[0,0],[-6166,-1328]与[28,1605]以及[-6166,-1328]与[1629,7022]各组在80个蛋白模型中的ROC曲线
发现队里中,80个蛋白中利用caret包中的rfe函数选择变量后,运用朴素贝叶斯方法重新构建了一个有11个蛋白(PTX3, ITGB1BP2, AXIN1, STAMPB, SRC, SIRT2, 4E-BP1, PAPP-A, HB-EGF, NEMO , IL-27)组成的新模型,其在训练集中灵敏度0.96(95% CI 0.89-1.0),特异度1.0(95% CI 1.0-1.0);验证集中灵敏度0.96(95% CI 0.89-1.0)特异度1.0(95% CI 1.0-1.0)。将该模型应用到重复队列的数据中,其各组在朴素贝叶斯模型下输出值,各组与对照组进行分类的ROC曲线下AUC值以及ROC曲线分别展示于图2-6,2-7,2-8中。
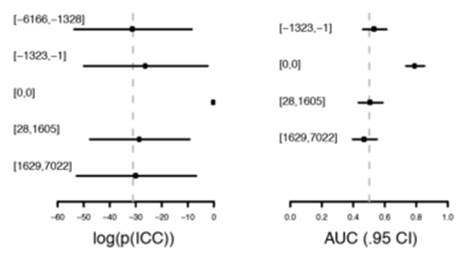
图2-6,11个蛋白模型中重复队列下各组输出值 图2-7,11个蛋白模型中,重复队列中各组与[-6166,-1328]组在ROC曲线下的AUC值
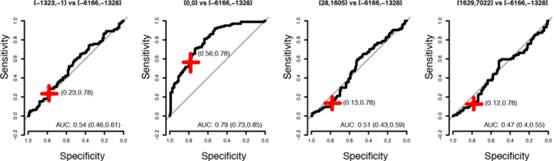
图2-8[-6166,-1328]与[-1323,-1],[-6166,-1328]与[0,0],[-6166,-1328]与[28,1605]以及[-6166,-1328]与[1629,7022]各组在11个蛋白模型中的ROC曲线
在重复队列中,不利用发现队列中的模型,而是利用该11个蛋白重新进行数据前处理以及建模,在新得到的模型(II)中,[-6166,-1328](对照组)与[0,0]两组的AUC为0.91,但其他组的AUC并无显著变化。该模型各组输出值,各组与对照组进行分类的ROC曲线下AUC值以及ROC曲线分别展示于图2-9,2-10,2-11中。
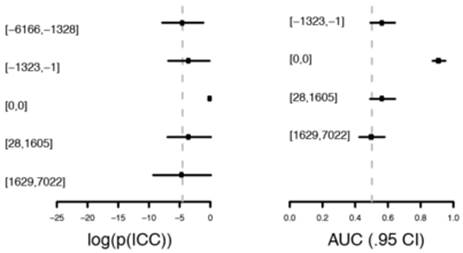
图2-9,11个蛋白模型II中重复队列下各组输出值 图2-10,11个蛋白模型II中,重复队列中各组与[-6166,-1328]组在ROC曲线下的AUC值
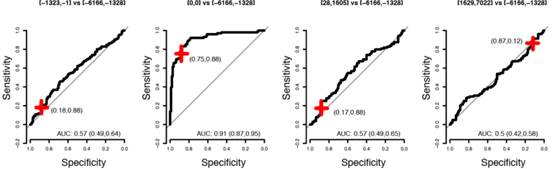
图2-11[-6166,-1328]与[-1323,-1],[-6166,-1328]与[0,0],[-6166,-1328]与[28,1605]以及[-6166,-1328]与[1629,7022]各组在11个蛋白模型(II)中的ROC曲线
3、上述80个蛋白的基因中有916个SNP,11个蛋白的基因中有24个SNP在疾病组和对照组中存在显著差异(P<0.05)。进行多重假设检验矫正后916个SNP中的137个基因依然差异显著,24个SNP中的11个基因依然差异显著。编码11个蛋白的24个显著差异的SNP中,p-value最小的基因为rs1405(p=0.003),位于编码PAPP-A的第一个内含子中。总而言之,疾病和对照组蛋白质丰度上的差异似乎并不受到编码这些蛋白的宫颈癌相关基因变异的显著影响。
4、通过进行蛋白与距确诊时间的线性模型的建立,来评估各个蛋白作为宫颈癌早期生物标记物的功效。多重假设检验下,80个蛋白中只有两个蛋白即CCL和FR-alpha在对照和疾病组中差异显著;11个蛋白中并无蛋白在对照和疾病组中差异显著。
5、发现队列中在疾病组中显著上调的28个蛋白中,在[-6166,-1328]组和[28,1605]组中并无差异显著的蛋白;[-6166,-1328]组和[0,0]组相比,有13个蛋白在[-6166,-1328]组显著上调;[-6166,-1328]组和[1,1323]组相比,只有FR-alpha存在显著差异,但在多重假设检验的校正下则不再显著。
文章亮点:
1、采用了基因组和蛋白质组的联合分析方法
2、根据不同条件选取蛋白质并作为机器学习的特征量构建多个模型
3、样本量较大,既存在生物标记物的发现队列,又对所建立的模型在重复队列中进行了验证,且结果较好
4、在重复队列中,根据距确诊时间的差异,将样本进行了多组分类,增加了文章的分析维度。
阅读人:王聚

 浙公网安备 33010602011771号
浙公网安备 33010602011771号