MCP|MZL|Accurate Estimation of Context- Dependent False Discovery Rates in Top- Down Proteomics 在自顶向下蛋白组学中精确设定评估条件估计假阳性
一、 概述:
自顶向下的蛋白质组学技术近年来也发展成为高通量蛋白定性定量手段。该技术可以在一次的实验中定性上千种蛋白,然而缺乏一个可靠的假阳性控制方法阻碍了该技术的发展。在大规模流程化的假阳性控制手段中,假阳性的判断取决于蛋白鉴定的检索条件,包括谱图的质量,检索的数据库的大小,检索引擎,检索参数等。本文提出了一个一种依据蛋白鉴定条件设定假阳性的方法。该方法的可靠性在一个人工确认的包含546个蛋白的数据集中进行了验证。目前该方法已被封装成一个开源工具,TDCD_FDR_CALCULATOR,可以整合到任何的鉴定搜索引擎中。
二、 研究背景:(简要介绍研究进展动态、研究目的和意义)
对于大规模高通量的自顶向下的蛋白质组学研究,自动高效的假阳性校正是必不可少的。在之前的自顶向下的蛋白质组学研究中,通过人工核验鉴定到的谱图与目标蛋白的理论谱图来确认鉴定结果的过程是不适用于高通量的研究的。目前自下而上向上的蛋白质组研究已经建立了丰富的假阳性控制的方法和工具,而在自顶向下的蛋白组学研究中尚缺乏这样的假阳性控制工具。本文建立了一套适用于自顶向下蛋白质组的假阳性分析工具,并评估了其可靠性。
三、实验设计:
本文开发了一种基于鉴定条件/鉴定的上下文来评估FDR的方法,并整合成为一个工具TDCD_FDR_CALCULATOR。该方法在鉴定时首先计算非参数的FDR值。同时在鉴定到的不同分子水平上依据鉴定的条件,构建该鉴定条件下的反库,并计算在反库中的匹配得分。再使用参数检验计算不同分子水平上的鉴定得分是否高于最好的反库匹配得分,更高的才认为是阳性。这个方法在PROSIGHT Absolute Mass, PROSIGHT Biomarker, 和INFORMED PROTEOMICS MSPathFinder上进行了测试。TDCD_FDR_CALCULATOR的适用性较广,可以适用于所有的自顶向下的搜索引擎。其输入文件为CSV格式,每个run一个CSV文件。TDCD_FDR_CALCULATOR的可靠性在一个546个人工验证的蛋白的数据集上进行了测试评估。这个数据集以及TDCD_FDR_CALCULATOR软件都是公开的。
四、研究成果:
在细胞中,基因被转录、剪切、翻译和修饰,成为一个蛋白群组。因此基于谱图的鉴定报道的是一个蛋白群组。在报道一个蛋白群组的假阳性的时候,所有的支持该蛋白群组的谱图都需要被考虑,来计算可信度与假阳性。同样的道理,在计算isoform的假阳性的时候也要考虑与其相关的谱图。

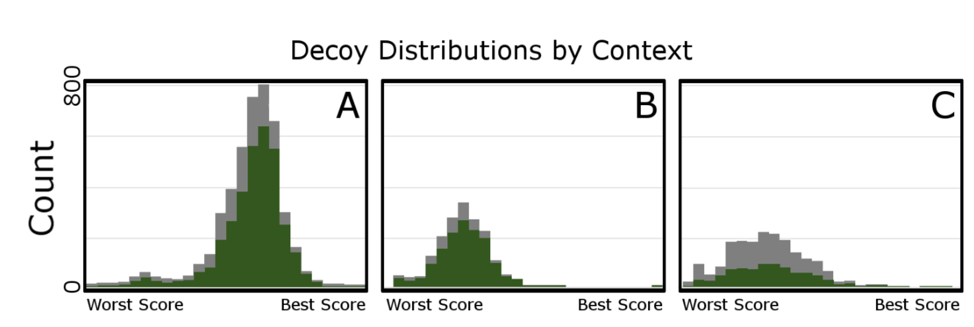
在自顶向下的蛋白质组学中,因为每个分子的鉴定都是有特定的谱图支持、搜索的数据库和搜索的参数,可以依据这些条件得到每个分子的反库,因此,每个分子水平的鉴定都有其自身的反库的搜索得分分布。下图展示了蛋白水平和蛋白群组水平的反库搜索得分的分布。绿色表示蛋白水平,灰色表示蛋白组水平,A,B,C分别表示对于同一个蛋白在不同的数据库、搜索引擎下,得到的不同的反库的得分分布。
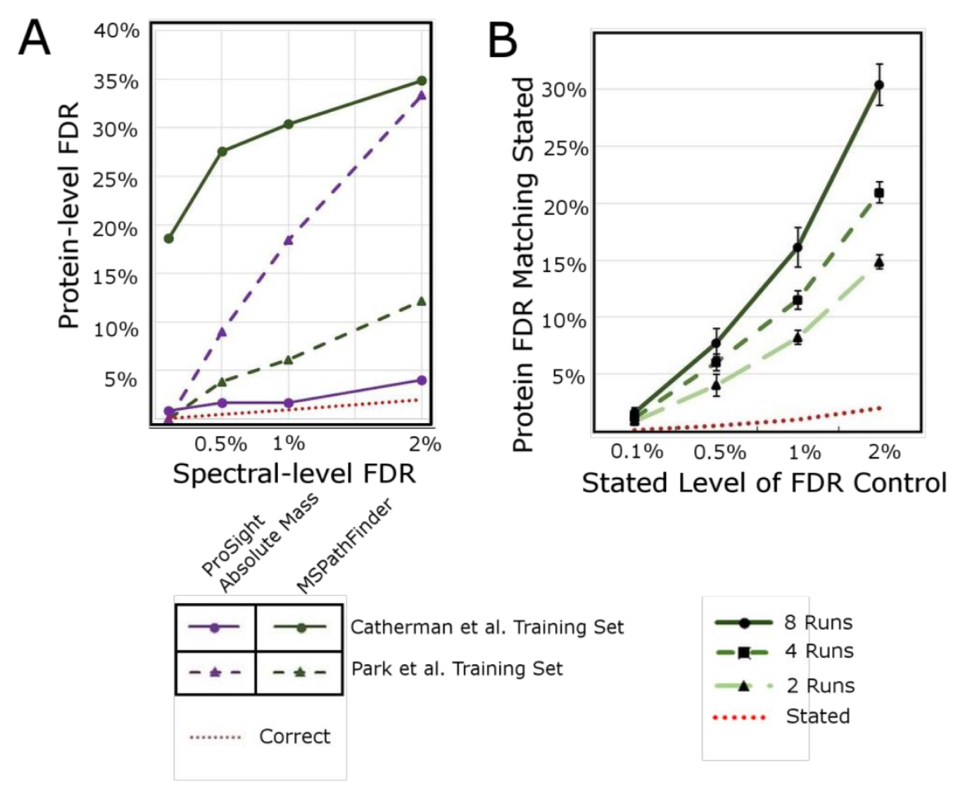
依赖PrSM水平的FDR校正得到的蛋白水平的假阳性率会很高,如下图所示:在两个数据集上,使用PROSIGHT Absolute Mass search (AM)和and MSPATHFINDER (PF)来做谱图水平的FDR为x轴,由此得到的蛋白水平的FDR为y轴,红线表示真实值。可见谱图水平的1%的FDR,得到的蛋白鉴定结果有约30%是假阳性的。因此,需要更为精确的的FDR控制。
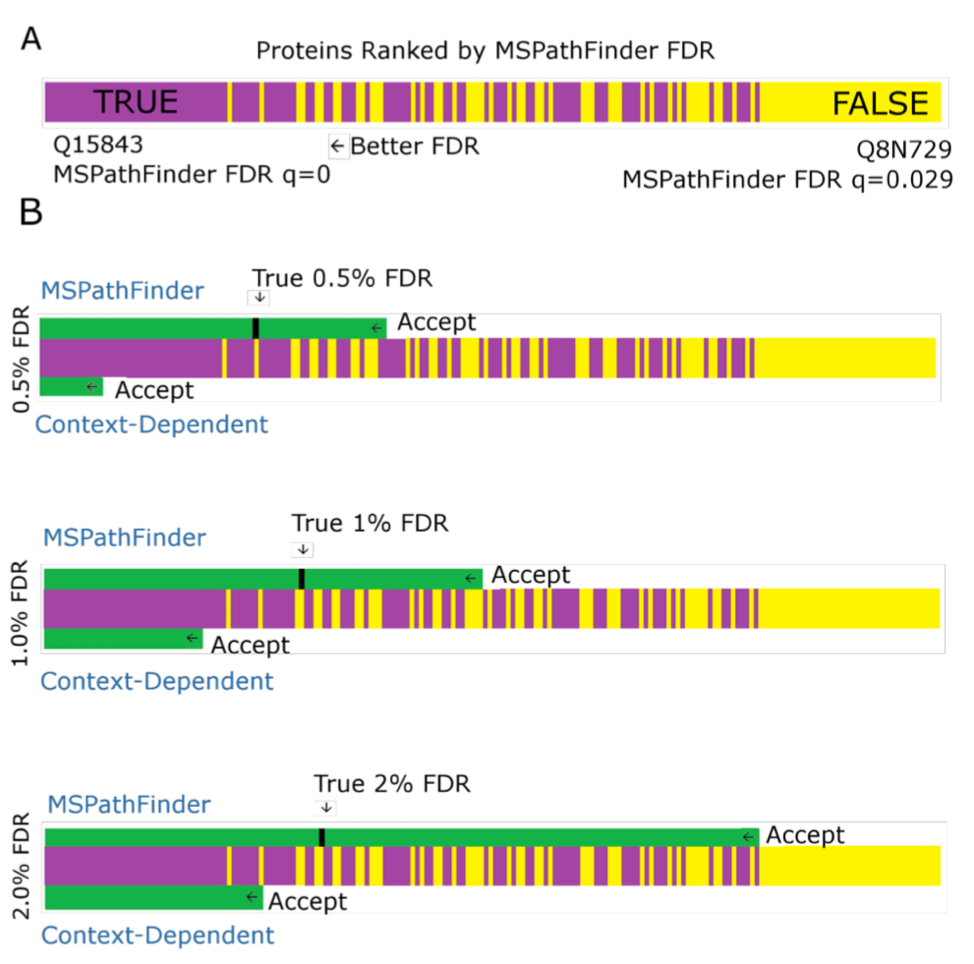
那么考虑鉴定条件的FDR究竟比常规的FDR的效果好在何处,作者通过可视化比较不同的FDR效果:A表示460个蛋白的q值得分,从最左边最低0到最右边的最高,0.029。从左到右q值逐渐增加。紫色表示人工验证的真阳性,黄色表示假阳性。B表示在不同的的FDR水平下,常规的FDR与基于上下文的FDR的效果。上面绿色表示常规FDR的水平下接受的蛋白的情况。如0.5%FDR接受的蛋白用绿色表示,黑色短竖线表示真实的0.5%所应当接受的蛋白。比较两种FDR计算策略在不同FDR水平下接受的蛋白的正确性来看,基于上下文的FDR校正方法更加保守,更加精确。
五、结论
蛋白或者蛋白组的鉴定的假阳性估计是与搜库的条件相关的。需要考虑搜库过程中设定的条件。我们提出了一种方便快捷的假阳性校正的方法。这个方法是可以根据蛋白鉴定的条件来设定不同的假阳性校正条件的,即每个蛋白组的假阳性校正都取决于其鉴定的参数。正式考虑了这些条件,该方法在假阳性校正方面更加的可靠与准确。该方法适合在大规模的自顶向下蛋白质组学中应用。为了提高这类方法的普适性,适当的包含一些假阳性结果比去除正阳性结果更为恰当。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号