

深度滤波器详细解读
深度滤波器详细解读
极品巧克力
前言
空间定位是VR\AR中的一项关键技术,计算机创建出来的虚拟图像必须要依赖空间定位技术才能与现实(Reality)联结在一起,所以它直接决定了用户体验的好坏。高精度的空间定位可以让VR用户体验到完全的沉浸感,AR中的虚拟物体更加逼真;而如果空间定位的精度比较差的话,则VR用户会头晕想吐,AR中的虚拟物体会漂移。
空间定位技术又可以分为两类,outside-in和inside-out。outside-in方案,需要在环境中架设定位基站,对用户进行定位跟踪,比如现在市面上的HTC Vive和Oculus Rift。


而inside-out方案,不需要在环境中架设基站,它只通过自身携带的传感器来进行定位,比如微软的HoloLens、WindowsMR头盔系列、HTC Vive Focus、苹果的ARKit、谷歌的ARCore和Project Tango,还有预计将在2018年发售的Oculus Santa Cruz、Magic Leap One。(当然,还有室内机器人、无人机、无人车)。





outside-in方案要架设定位基站,并且对用户的活动范围有限制,相当于"PC互联网时代",只适合PCVR。
而insiede-out方案更加轻便自然,就像人用眼睛观察,就能知道自己在环境中的位置一样。用户只需要戴着头盔,就能随意走动,没有运动范围限制,相当于"移动互联网时代"。从目前的发展趋势来看,inside-out方案正在逐渐走向成熟,被应用在越来越多的VR一体机和AR眼镜上。
而我接下来要探讨的是,如何让建立的地图点更加准确。因为无论哪种算法,准确跟踪定位的前提都是,要有准确的地图点。但是,由于传感器噪声和环境噪声的存在,总是会不可避免地创建出一些误差大的甚至假的地图点,这些错误的地图点会对跟踪定位的准确性造成很大的影响。
所以,我接下来就介绍一种可以让地图点更加准确的方法——深度滤波,它可以通过多次观测,计算出一个地图点是假的地图点还是真实地图点的概率,并且计算出其作为真实地图点的最有可能的位置。它最初是用在三维重建中的(http://george-vogiatzis.org/),后来被用在SVO(Semi-Direct Monocular Visual Odometry,https://github.com/uzh-rpg/rpg_svo)中,都取得了很好的效果。
本文主要是参考《Video-based, Real-Time Multi View Stereo》,按照我自己的理解,从最基础的贝叶斯公式开始推导,一步步推导出最后的迭代公式,用最通俗易懂的方式,把深度滤波方法的来龙去脉讲清楚。
1.测量值区间累加的方法
首先,是以前的基于投票的获取深度的方法。要有一个特征点,然后在其它帧找匹配。
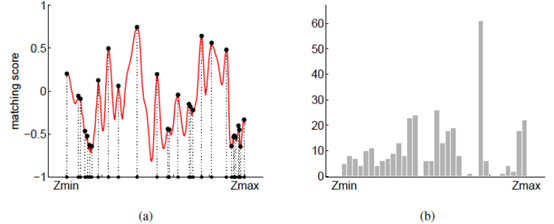
左图是该特征点在一幅图像上面的匹配,随着Z的变化,对应在极线上的不同投影点位置。该特征点图块经过仿射变化之后,与不同的投影点位置的图块进行NCC匹配,获取不同的匹配分数,然后记录极大值点,落在哪个Z值区间。从Zmin到Zmax分了50段区间。右图是把60幅图像这样的数组累加,把极大值点累加,记录在每个Z值区间出现的极大值的频数。
最后,会得到这样的结果,最后会收敛。分别对应5、10、20、100张图的时候的样子。

这种方法比较准确,但是需要记录大量的数据。比如上面(a),单是一幅图上,从Zmin到Zmax就分了50段,于是要用50个元素的数组来记录每段有无极大值。然后把60幅图像的数组都合并起来,得到(b)。
而且,即便能知道累加后最高的那个直方图对应的深度值,但不能知道,根据所有的测量结果所推算出来的深度值,也不知道,那个特征点对应的外点(假地图点)的概率。
2.能推算深度值也能算外点概率的方法——穷举法
所以,要想出其它的办法,既可以综合所有的测量结果推算出深度值,也可以推算出这个特征点对应的外点的概率。
那么,就用另外一种方法,不再记录单幅图像上的所有极大值,而是只记录单幅图像上的最大值。同样地,也把所有的数组累加起来。积累了150幅图像的测量值之后,可以得到下图。
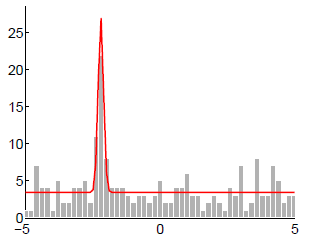
那么,在这样的测量数据 的情况下,从这些测量数据中,可以反映出这个点的真正的深度值应该是多少呢?是外点的概率又是多少呢?
的情况下,从这些测量数据中,可以反映出这个点的真正的深度值应该是多少呢?是外点的概率又是多少呢?
用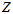 表示该特征点真正的深度值,用
表示该特征点真正的深度值,用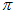 表示内点的概率。
表示内点的概率。
所以,可以用概率方法表示如下,也就是后验概率。
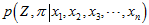
要求出一组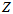 和
和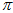 ,使得上面的
,使得上面的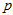 最大。但是,直接算,算不出来。用贝叶斯公式来转换。
最大。但是,直接算,算不出来。用贝叶斯公式来转换。
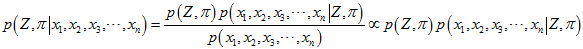
又因为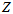 和
和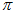 的区间分布的先验值,就是每处都相同。
的区间分布的先验值,就是每处都相同。
这里的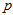 都是指概率密度,就像是把1千克的质量分散在这么大的体积里,每个地方的密度。要变成概率,还需要乘以一个微分段
都是指概率密度,就像是把1千克的质量分散在这么大的体积里,每个地方的密度。要变成概率,还需要乘以一个微分段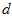 ,但因为在等式两边都乘以同样的微分段,所以可以约掉了。贝叶斯公式也就可以同样适用于概率密度的推算了。概率密度与实际概率的关系,参考《从贝叶斯到beta分布》。
,但因为在等式两边都乘以同样的微分段,所以可以约掉了。贝叶斯公式也就可以同样适用于概率密度的推算了。概率密度与实际概率的关系,参考《从贝叶斯到beta分布》。
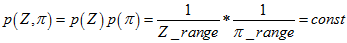
所以,
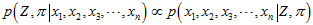
又因为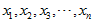 之间互相独立,所以,
之间互相独立,所以,
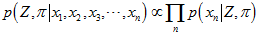
也就是,找出一组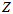 和
和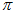 ,使得
,使得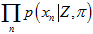 这个累乘结果最大。
这个累乘结果最大。
而对其中的每一个元素,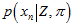 可以认为是,内点的高斯分布概率,加上,外点的概率,表示成如下公式。其中,
可以认为是,内点的高斯分布概率,加上,外点的概率,表示成如下公式。其中,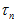 是匹配点在极线上的一个像素的扰动,造成的对应点在深度上的变化。参考《视觉SLAM十四讲》13.2.3的《高斯分布的深度滤波器》。这里的
是匹配点在极线上的一个像素的扰动,造成的对应点在深度上的变化。参考《视觉SLAM十四讲》13.2.3的《高斯分布的深度滤波器》。这里的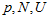 都是指概率密度。
都是指概率密度。
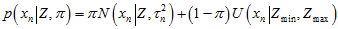
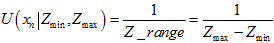
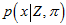 在
在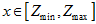 上,随着
上,随着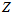 和
和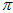 的调节,会变成如下不同的概率曲线,
的调节,会变成如下不同的概率曲线,


所以,现在已知有这样的确定的测量值。
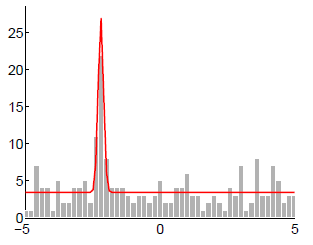
每个测量值都对应一个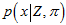 ,所有的累乘。目标是,通过调节
,所有的累乘。目标是,通过调节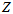 和
和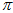 ,调节曲线的形状,使得
,调节曲线的形状,使得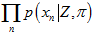 这个累乘结果最大。其实,即便
这个累乘结果最大。其实,即便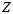 和
和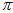 相同,
相同,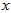 所在的区间相同,
所在的区间相同,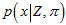 也是不同的,因为
也是不同的,因为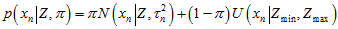 里面的
里面的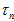 是由两帧相机的相对位置以及特征点的像素位置决定的,所以每个测量值的
是由两帧相机的相对位置以及特征点的像素位置决定的,所以每个测量值的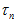 都不相同。因为在该帧上面,假设在极线上测到的极大值点
都不相同。因为在该帧上面,假设在极线上测到的极大值点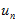 ,满足方差为1个像素的高斯分布,即真实的极大值点与测量点
,满足方差为1个像素的高斯分布,即真实的极大值点与测量点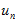 间满足这样的高斯分布。则计算出来的深度点
间满足这样的高斯分布。则计算出来的深度点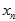 也会满足高斯分布,方差用
也会满足高斯分布,方差用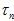 表示,参考《视觉SLAM十四讲》的《深度滤波器》。
表示,参考《视觉SLAM十四讲》的《深度滤波器》。
但由于实际上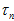 差别不大,为了思考上的方便,这里就先忽略掉
差别不大,为了思考上的方便,这里就先忽略掉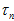 的差别。但实际计算上,还是会根据公式计算,考虑公式中
的差别。但实际计算上,还是会根据公式计算,考虑公式中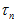 的差别。
的差别。
将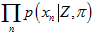 展开,得到,
展开,得到,
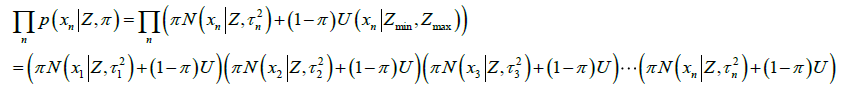
通过思考,会发现,测量值都是已知的固定的,就是上面的灰色的直方图,为了使得累乘结果最大,需要调节曲线,使得直方图高的地方概率高,就是曲线的形状接近于直方图的形状的时候,所有测量值对应的概率的累乘结果会是最大的。
还是直接用穷举的方法来找,怎么样的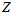 和
和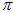 可以让累乘结果最大。通过穷举所有的
可以让累乘结果最大。通过穷举所有的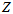 和
和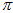 ,得到每个组合对应的累乘结果
,得到每个组合对应的累乘结果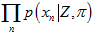 的值,画成三维图表示如下。分别对应5、10、20、100张图的时候的样子。
的值,画成三维图表示如下。分别对应5、10、20、100张图的时候的样子。

最后,可以收敛。根据穷举的结果,可以找到让累乘结果最大时的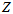 和
和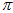 ,也就是最终想得到的
,也就是最终想得到的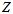 和
和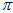 。
。
其实,上面的方法的本质是基于这样的一个假设,如果那个特征点是内点的话,最后形成的直方图会是中间非常凸起的形状。如果那个特征点是外点的话,则最后形成的直方图会是非常平坦的长方形的形状。所以,上面的方法也可以近似理解为,看最后形成的直方图的形状,分布与凸起形状和平坦的长方形形状的相似度。
但是,对一张直方图都要进行这样的穷举,计算量太大(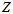 分50段,
分50段,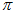 分100段,要算5000种组合),而且还只是对应单个特征点。而且,每新来一张图片,新来一个测量值
分100段,要算5000种组合),而且还只是对应单个特征点。而且,每新来一张图片,新来一个测量值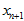 ,调整直方图后,针对这个新的测量值
,调整直方图后,针对这个新的测量值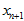 ,再穷举出一幅三维图
,再穷举出一幅三维图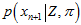 ,然后之前算出来的三维图
,然后之前算出来的三维图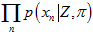 再乘以新的这幅三维图
再乘以新的这幅三维图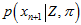 ,也就是每种组合的计算结果对应相乘,得到新的累乘三维图
,也就是每种组合的计算结果对应相乘,得到新的累乘三维图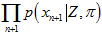 ,再在上面找峰值。公式如下。
,再在上面找峰值。公式如下。
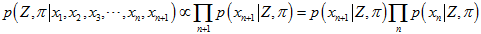
问:上面的这种已知所有的测量值(直方图),然后穷举所有的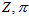 ,求概率最大的地方,与卡尔曼滤波的用测量值更新得到真值的方法,有什么不同呢?首先,卡尔曼滤波只针对高斯分布成立,所以只对
,求概率最大的地方,与卡尔曼滤波的用测量值更新得到真值的方法,有什么不同呢?首先,卡尔曼滤波只针对高斯分布成立,所以只对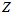 有效。那么就把
有效。那么就把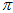 都当成零,认为全是内点的情况下,两者的区别呢?
都当成零,认为全是内点的情况下,两者的区别呢?
答:本质上是一样的,结果上也会是一样的,只是使用场景不同。这种方法的特点是,知道每一个测量值各自对应的方差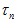 ,然后穷举所有的
,然后穷举所有的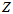 ,使得累乘结果最大,就认为得到最大后验概率。这种穷举的方法,适合离线方法。而卡尔曼滤波,一步步迭代的,通过第一个测量值得到,预测值和对应的协方差。认为真值是不动的。然后用后面的测量值和各自对应的协方差,来更新。最后得到一个较准确的值。卡尔曼滤波的方法,适合在线的迭代的方法。在只有一个测量值的情况下,两者是几乎相同的。
,使得累乘结果最大,就认为得到最大后验概率。这种穷举的方法,适合离线方法。而卡尔曼滤波,一步步迭代的,通过第一个测量值得到,预测值和对应的协方差。认为真值是不动的。然后用后面的测量值和各自对应的协方差,来更新。最后得到一个较准确的值。卡尔曼滤波的方法,适合在线的迭代的方法。在只有一个测量值的情况下,两者是几乎相同的。
如果在只有第一个测量值的情况下,上面的穷举方法,穷举的结果会发现,当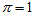 ,
,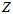 等于测量值的情况下,后验概率会是最大的。也就是说,在只有一个测量值的情况下,就直接认为它是内点。所以,需要多一些测量值才比较好。
等于测量值的情况下,后验概率会是最大的。也就是说,在只有一个测量值的情况下,就直接认为它是内点。所以,需要多一些测量值才比较好。
3.穷举法的改进方法,已知是否内点,推导出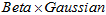 形式,用迭代加速计算
形式,用迭代加速计算
但是,每新来一个测量值都要针对新的测量值穷举,然后再两幅三维图相乘,计算量还是蛮大的,还有没有更方便计算的方法呢?
首先,对于这种穷举找最大值的方法,现在一般都是用凸优化方法来代替了。如果能计算出优雅的雅克比解析式的话,就可以用梯度下降法,高斯牛顿法或LM方法来快速找到极大值点(可以转换成极小值点来算,比如被1减)。但是,从展开的公式上看,也没有方便地计算雅克比的方法。如果不能方便地计算雅克比,那么就用数值扰动的方法来求雅克比,这就接近于穷举法了,但只是用数值扰动来算雅克比,沿着梯度变化找到极大值点,计算量应该还是比穷举法要小的。这就是一般的穷举法,凸优化法(有雅克比解析式,和,无雅克比解析式用数值扰动算雅克比)的关系。(http://www.cnblogs.com/ilekoaiq)但这些凸优化方法的前提都是,三维曲面上,只有一个极大值点。
通过对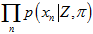 展开,
展开,
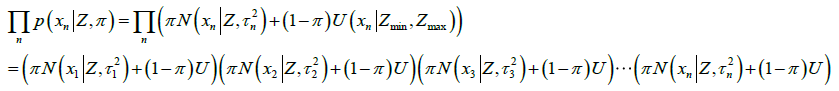
发现并没有什么方便计算的方法。主要是,其中的每个大括号里,都是由两项加在一起的,这样子,整个公式拆开来算的话,会非常庞大,而且找不出规律(虽然有点像快速傅里叶变换的蝶形乘法)。那么,有没有办法,把其中的加法消除掉呢?通过观察发现,其中的加法,是因为不知道这个点是内点还是外点,于是就两种情况都算。但是,如果通过其它方法,已经可以知道对应的这个点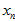 是真实点高斯分布产生的,还是外点均匀分布产生的。那样子,就可以把大括号里面的加法消除掉,只保留对应的一项。要么是真实点高斯分布产生的,要么是外点均匀分布产生的。为了方便理解,可以先想象一种情况,就是它们全都是真实点高斯分布产生的。在论文中,是在极线上搜索,在一定搜索范围内能否找到极大值,如果能找到极大值,就把极大值测量点转换成的
是真实点高斯分布产生的,还是外点均匀分布产生的。那样子,就可以把大括号里面的加法消除掉,只保留对应的一项。要么是真实点高斯分布产生的,要么是外点均匀分布产生的。为了方便理解,可以先想象一种情况,就是它们全都是真实点高斯分布产生的。在论文中,是在极线上搜索,在一定搜索范围内能否找到极大值,如果能找到极大值,就把极大值测量点转换成的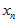 认为是真实点高斯分布产生的;如果不能找到极大值,就把最大值测量点转换成的
认为是真实点高斯分布产生的;如果不能找到极大值,就把最大值测量点转换成的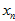 认为是外点均匀分布产生的,其实这时候,也无所谓选取的最大值测量点的位置和转换后的
认为是外点均匀分布产生的,其实这时候,也无所谓选取的最大值测量点的位置和转换后的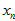 的位置,因为产生它们的都是外点的均匀分布
的位置,因为产生它们的都是外点的均匀分布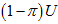 。
。
再回到原来的公式。
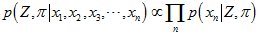
设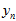 表示这个测量点转换成的
表示这个测量点转换成的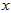 是否是真实点高斯分布产生的。
是否是真实点高斯分布产生的。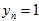 ,表示是真实点高斯分布产生的。
,表示是真实点高斯分布产生的。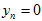 ,表示是外点的均匀分布产生的。则其中的每一项,可以表示如下,这也是最根本的推导。其中,
,表示是外点的均匀分布产生的。则其中的每一项,可以表示如下,这也是最根本的推导。其中,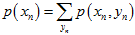 ,来自于
,来自于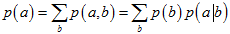 。单个字母
。单个字母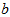 表示某个取值的时候,
表示某个取值的时候,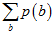 表示所有取值的概率累加,且
表示所有取值的概率累加,且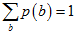 。要思考清楚各个变量之间的关系,参考《贝叶斯与维恩图》。
。要思考清楚各个变量之间的关系,参考《贝叶斯与维恩图》。
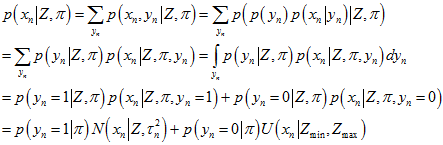
(其中,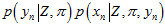 (或者
(或者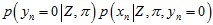 ),也可以先看右边的这项
),也可以先看右边的这项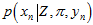 (或者
(或者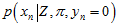 ),再看左边的这项
),再看左边的这项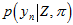 (
(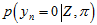 ),会更好理解。)
),会更好理解。)
那么,现在,我们已经通过了之前的那种策略,知道了当前点是否内点,记为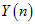 ,相比只知道
,相比只知道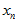 ,又增加了信息。则在已知
,又增加了信息。则在已知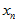 、
、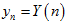 的情况下,
的情况下,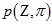 的概率如以下公式所示。因为最根本的贝叶斯公式就是,
的概率如以下公式所示。因为最根本的贝叶斯公式就是,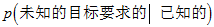 。
。
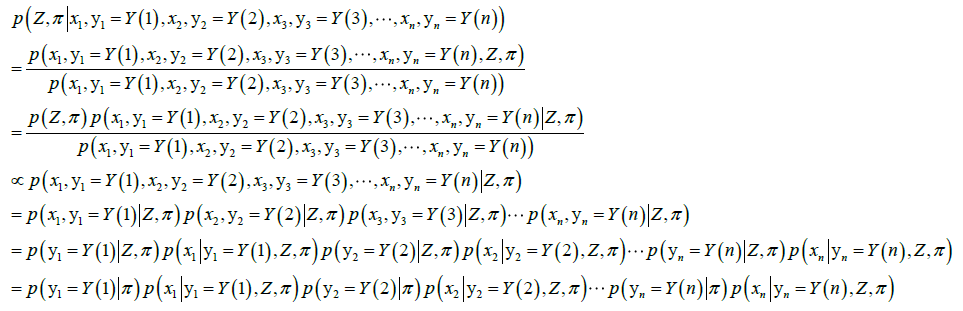
上式中,有些是内点,有些是外点,根据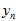 来决定,各项的实际表达式会不同。为了数学形式上的简洁与统一,上式中的各项可以用以下公式来表示,同时表示了内点和外点的情况。
来决定,各项的实际表达式会不同。为了数学形式上的简洁与统一,上式中的各项可以用以下公式来表示,同时表示了内点和外点的情况。
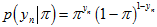
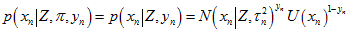
所以,上上式可以简洁地表示成,
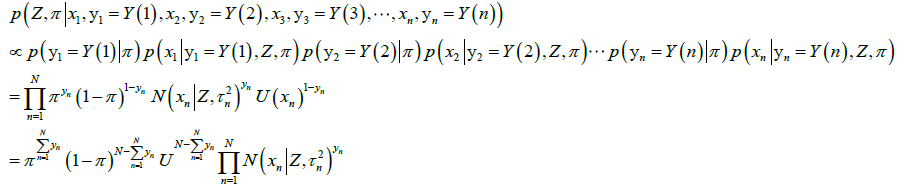
我们要算的公式中,自变量是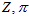 ,其它的量都是已知的。
,其它的量都是已知的。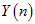 是已知的,用
是已知的,用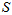 表示累加结果,
表示累加结果,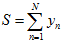 。
。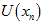 都是已知的常数,就算
都是已知的常数,就算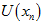 会随着
会随着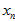 的变化而变化,那也没关系,变量
的变化而变化,那也没关系,变量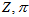 的变化不经过它们影响因变量结果,所以它们的累乘结果可以认为是一个已知的常数。参考《从贝叶斯到Beta分布》,其实最后要算的是各个(
的变化不经过它们影响因变量结果,所以它们的累乘结果可以认为是一个已知的常数。参考《从贝叶斯到Beta分布》,其实最后要算的是各个(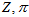 组合)概率之间的比例,也可以理解为其实是要归一化的。所以,上式还可以写成更简洁的形式。(《Video-based, Real-Time Multi View Stereo》的附加材料的第一部分讲的就是这样的推导,但是它转成了
组合)概率之间的比例,也可以理解为其实是要归一化的。所以,上式还可以写成更简洁的形式。(《Video-based, Real-Time Multi View Stereo》的附加材料的第一部分讲的就是这样的推导,但是它转成了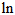 ,又转回来,反而有些麻烦)。
,又转回来,反而有些麻烦)。
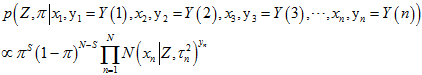
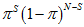 是一个
是一个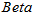 分布。
分布。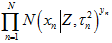 是高斯分布的累乘,根据高斯分布的性质(以及2中的那个"隐含"高斯分布概率的推导),仍然还是高斯分布。所以,就用
是高斯分布的累乘,根据高斯分布的性质(以及2中的那个"隐含"高斯分布概率的推导),仍然还是高斯分布。所以,就用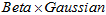 的形式来表示。
的形式来表示。
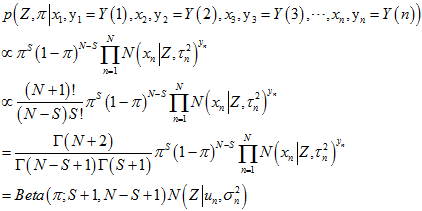
然后,就可以很方便地迭代计算了。其中,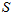 比较好算,
比较好算,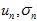 可以根据高斯分布乘法的性质,从
可以根据高斯分布乘法的性质,从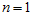 开始,一步步迭代计算出来。
开始,一步步迭代计算出来。
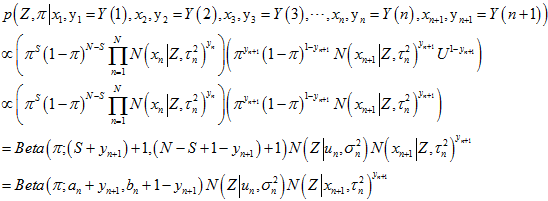
当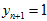 时,上式中
时,上式中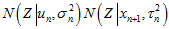 展开相乘,结合高斯分布乘法,可以得到,
展开相乘,结合高斯分布乘法,可以得到,
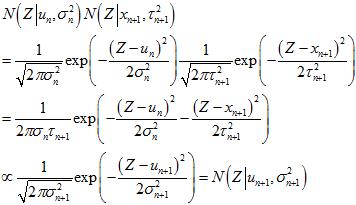
由高斯分布乘法可得,参考《高斯分布的加减乘除法》《直观理解高斯函数相乘》《卡尔曼滤波基础》。
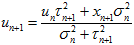
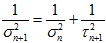
如果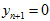 ,则
,则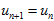 ,
,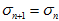 。
。
所以,迭代一下后,得到的新的表达式为,
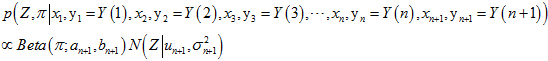
其中,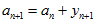 ,
,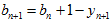 。这样子,每新来一个测量值,只需要迭代一下就可以,不用再两幅三维图相乘。
。这样子,每新来一个测量值,只需要迭代一下就可以,不用再两幅三维图相乘。
(而另一方面,如果不知道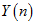 的话,是没办法明确推导出上面的这样的Beta和高斯分离出来的公式的,只能用近似的方法。通过观察最后的收敛的三维图像,思考发现。当
的话,是没办法明确推导出上面的这样的Beta和高斯分离出来的公式的,只能用近似的方法。通过观察最后的收敛的三维图像,思考发现。当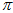 一定时,累乘结果峰值的位置主要是由
一定时,累乘结果峰值的位置主要是由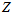 来决定的。也就是
来决定的。也就是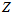 决定了曲线凸出来的地方,当曲线凸出来的地方的位置与直方图的高值地方接近的时候,累乘结果就能取到较大的值。当
决定了曲线凸出来的地方,当曲线凸出来的地方的位置与直方图的高值地方接近的时候,累乘结果就能取到较大的值。当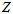 值一定时,
值一定时,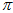 的分布也是一个中间凸的曲线。
的分布也是一个中间凸的曲线。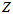 的分布和
的分布和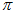 的分布是分别穷举的,但不是独立的,因为在
的分布是分别穷举的,但不是独立的,因为在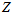 不同的地方,
不同的地方,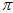 的分布会发生变化,
的分布会发生变化,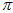 的顶点位置会发生变化。但是,为了简化计算,可以认为
的顶点位置会发生变化。但是,为了简化计算,可以认为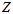 和
和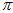 是独立的,所以分别用曲线去近似
是独立的,所以分别用曲线去近似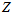 的分布和
的分布和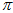 的分布。)
的分布。)
4.更完整形式的迭代计算
因为根据我们的策略,我们可以知道这个测量点对应的是内点还是外点。但是,我们之前的策略只能判定明显的外点,如果不是明显的外点的话,就认为是内点,但是,真实的情况是,这时候认为的内点,其实还是有可能是外点的。那么,就要考虑这种更真实的情况。
当用之前的策略判定当前测量点为外点产生的时候,就认为它是由外点产生的。直接使用第3部分中的迭代方法,更新这个外点。但是,当判定不是外点的时候,就仍然还是要用第2部分中的方法。
设之前的部分已经满足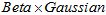 的形式,用公式表示如下。
的形式,用公式表示如下。
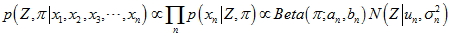
则,如果新来一个测量点,没有被判断为外点。则公式更新如下。

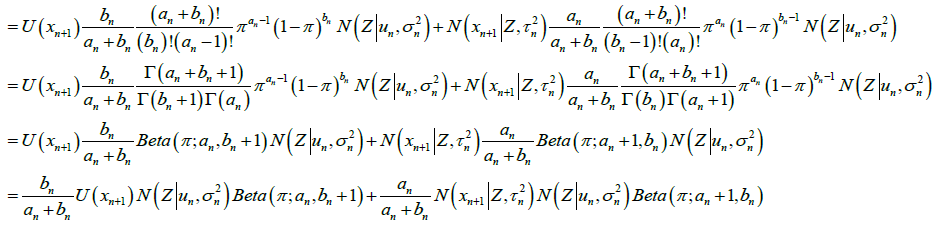
根据高斯分布乘法的性质,处理上式中的 ,参考《高斯分布的加减乘除法》。
,参考《高斯分布的加减乘除法》。
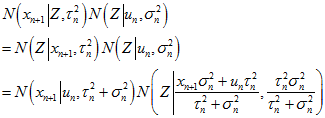
用 表示
表示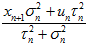 ,用
,用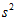 表示
表示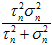 。(注意,这里与《Video-based, Real-Time Multi View Stereo》的附加材料里的公式不一样,因为我认为《Video-based, Real-Time Multi View Stereo》的附加材料里的
。(注意,这里与《Video-based, Real-Time Multi View Stereo》的附加材料里的公式不一样,因为我认为《Video-based, Real-Time Multi View Stereo》的附加材料里的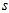 的表达式写错了。)则上上式可以表示为。
的表达式写错了。)则上上式可以表示为。
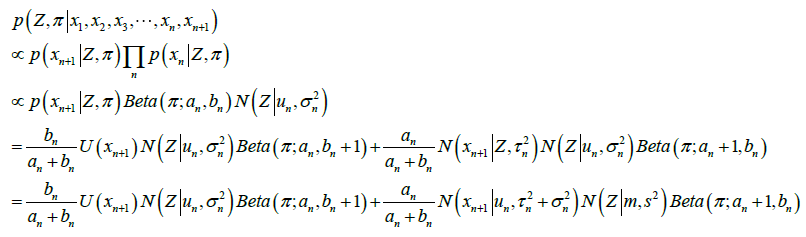
这时候,结果是,两个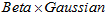 形式的相加。相当于两幅三维图叠加(想象两个高斯分布在概率轴方向上叠加在一起,形成了两个山峰)。相加之后的结果,不会再是
形式的相加。相当于两幅三维图叠加(想象两个高斯分布在概率轴方向上叠加在一起,形成了两个山峰)。相加之后的结果,不会再是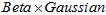 的形式,或者其它的单一模型的形式。在这里,只能近似地认为,相加后的结果接近于
的形式,或者其它的单一模型的形式。在这里,只能近似地认为,相加后的结果接近于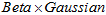 的形式,这要依赖于上式中的,(1)
的形式,这要依赖于上式中的,(1)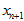 和
和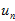 很接近使得
很接近使得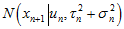 接近于1;(2)
接近于1;(2)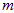 和
和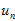 ,
,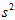 和
和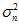 很接近,使得
很接近,使得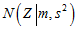 和
和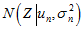 很接近;(3)
很接近;(3)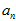 和
和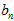 两个数都很大,使得
两个数都很大,使得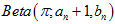 接近于
接近于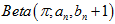 ;(4)
;(4)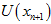 很小,使得左边项可以忽略。
很小,使得左边项可以忽略。
所以,如果近似地认为,相加后的结果接近于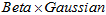 的形式的话,则用公式表示如下。
的形式的话,则用公式表示如下。
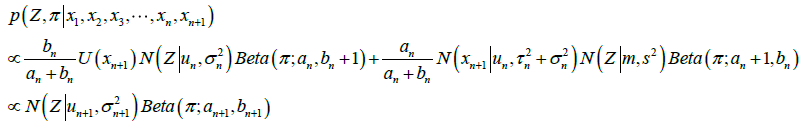
用一阶矩和二阶矩近似的方法,把新的参数估计出来。
就是用新的单一模型的概率密度三维图去近似旧的多模型叠加的概率密度的三维图。让两者的自变量轴(x、y轴)的一阶矩和二阶矩近似。用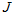 表示旧的多模型叠加的概率密度的三维图,用
表示旧的多模型叠加的概率密度的三维图,用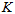 表示新的单一模型的概率密度三维图。其实这个三维图的
表示新的单一模型的概率密度三维图。其实这个三维图的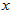 轴,就是表示
轴,就是表示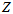 的那一个轴,是无穷大的,只是最后显示的时候,取了中间的
的那一个轴,是无穷大的,只是最后显示的时候,取了中间的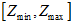 部分。
部分。
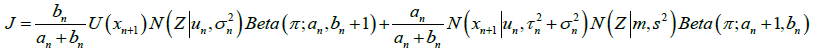
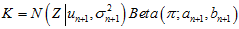
参考《高斯分布的各阶矩》,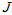 图上的
图上的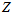 的一阶矩为
的一阶矩为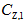 ,
,
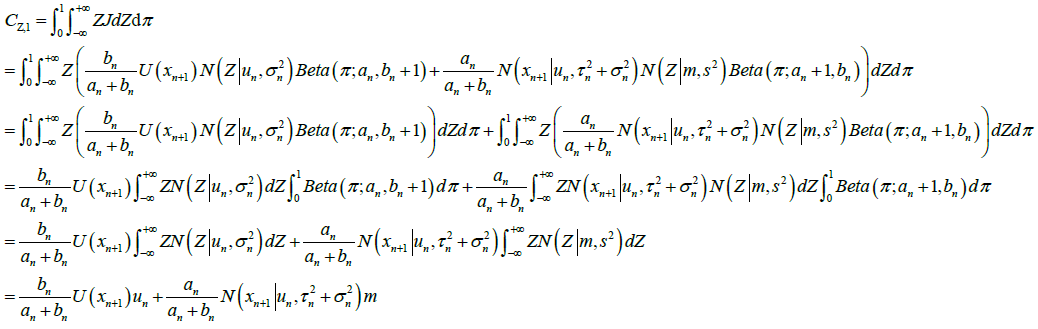
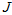 图上的
图上的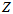 的二阶矩为
的二阶矩为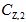 ,
,
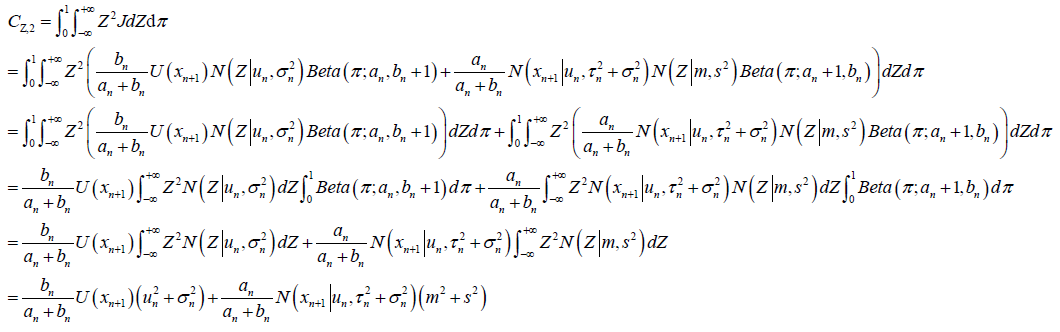
参考《常用分布函数及特征函数》,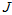 图上的
图上的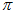 的一阶矩为
的一阶矩为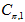 ,
,
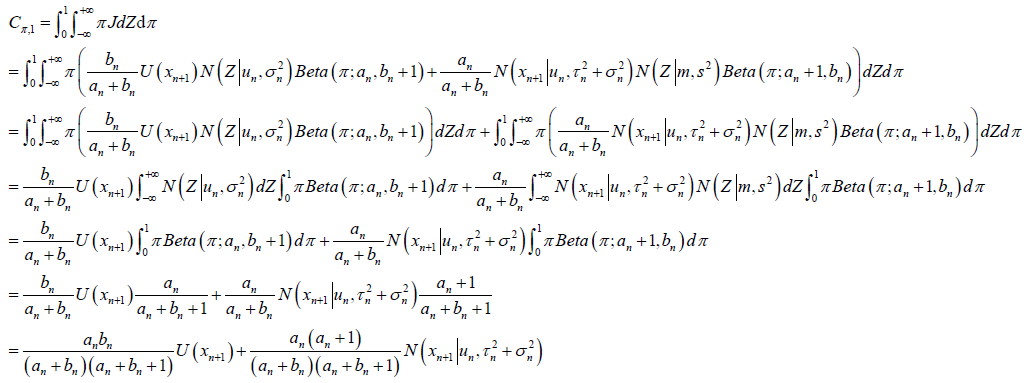
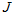 图上的
图上的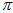 的二阶矩为
的二阶矩为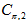 ,
,
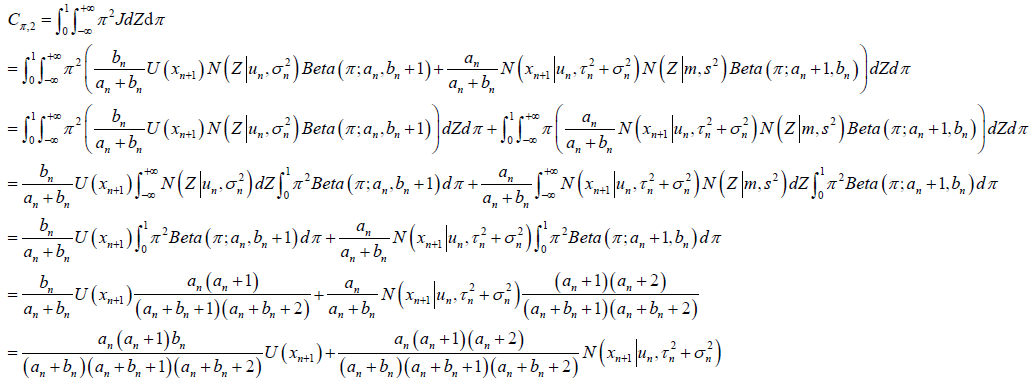
 图上的
图上的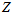 的一阶矩为,
的一阶矩为,
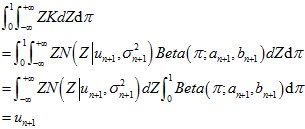
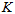 图上的
图上的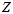 的二阶矩为,
的二阶矩为,
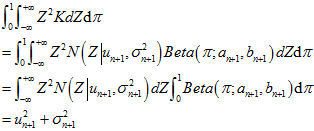
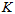 图上的
图上的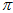 的一阶矩为,
的一阶矩为,
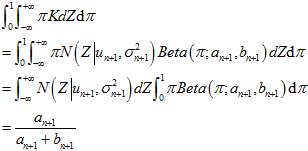
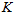 图上的
图上的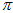 的二阶矩为,
的二阶矩为,
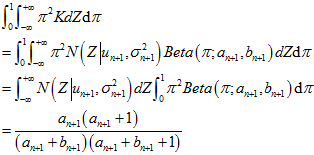
所以,联立方程,让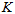 图的矩去等于
图的矩去等于 图的矩,也就是
图的矩,也就是 图上的参数所要满足的约束。
图上的参数所要满足的约束。
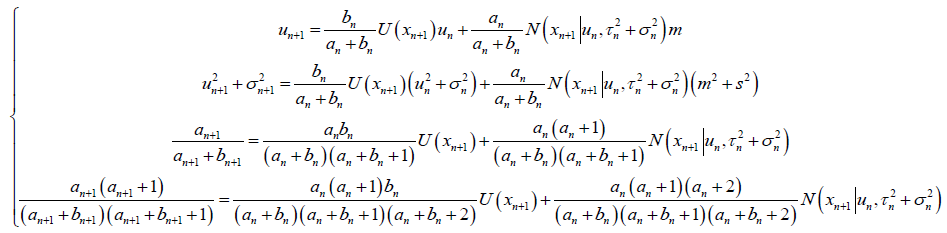
经过计算,最后得到迭代公式,

相当于是用一个Beta分布来近似 的分布,用一个高斯分布来近似
的分布,用一个高斯分布来近似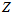 的分布。
的分布。
于是,最终就推导出了这么一种简洁的迭代公式。每新来一个测量值,迭代一下能快速计算出新的峰值点。相比第二部分,不用再针对新的测量值穷举所有的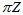 组合后再两幅三维图相乘;相比第三部分,更加接近真实的情况。
组合后再两幅三维图相乘;相比第三部分,更加接近真实的情况。

5.总结
深度滤波方法,理论推导非常优美,全部都由最简洁的贝叶斯公式推导而来,它尽可能地把所有的观测信息都利用上;还能进行快速迭代,实际运行的效果也很棒。应用在三维重建中,可以让三维重建出来的模型更加真实;应用在VR\AR空间定位中,可以让跟踪定位更加准确。相信它还可以被应用在更多的跟踪、建图算法中。
6.求赞赏
您觉得,本文值多少?

7.参考文献
-
George Vogiatzis, Carlos Hernandez. Video-based, real-time multi-view stereo [J]. Image & Vision Computing, 2011, 29(7):434-441.
-
Forster C, Pizzoli M, Scaramuzza D. SVO: Fast semi-direct monocular visual odometry[C]// IEEE International Conference on Robotics and Automation. IEEE, 2014:15-22.
-
Pizzoli M, Forster C, Scaramuzza D. REMODE: Probabilistic, monocular dense reconstruction in real time[C]// IEEE International Conference on Robotics and Automation. IEEE, 2014:2609-2616.
-
高翔.视觉SLAM十四讲[M].北京:电子工业出版社,2017:325-327.

