

Pandas学习笔记 05 变形
第五章 变形总结
1 长宽格式的变形
pivot、 pivot_table 、melt、 wide_to_long均为某一列或几列元素与索引之间的转换。
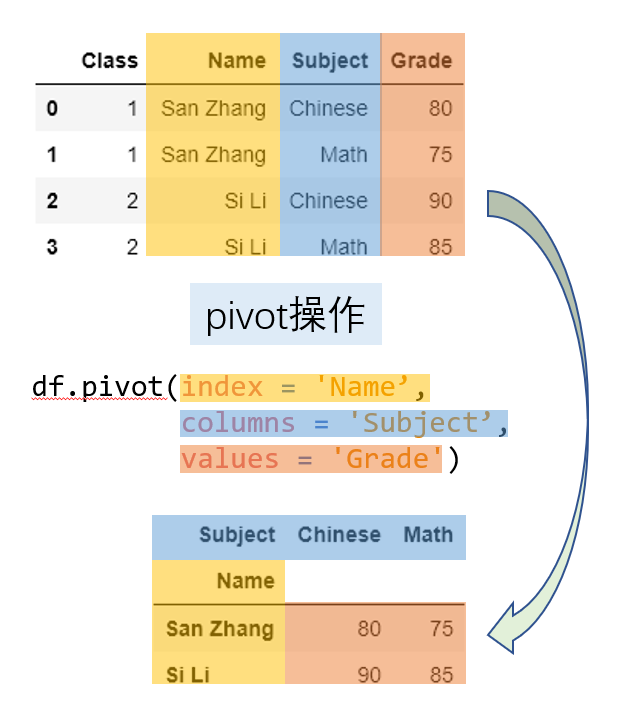
1.1 pivot
DataFrame.pivot(index=None, columns=None, values=None)
通过给定的index、columns和values重塑数据表,将长格式转换为宽格式。
注意:pivot其实就是用set_index创建层次化索引,再用unstack重塑
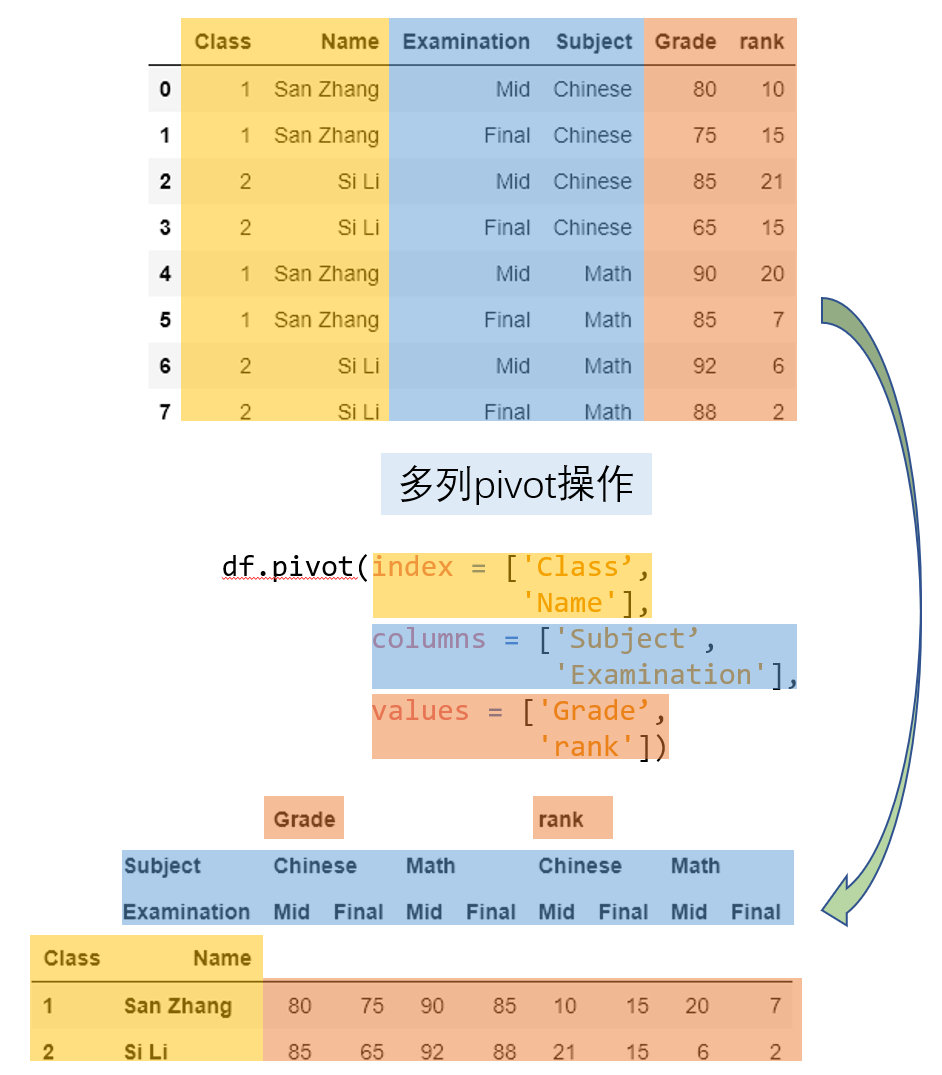
1.2 pivot_table 透视表
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
在pivot的基础上增加聚合操作等。

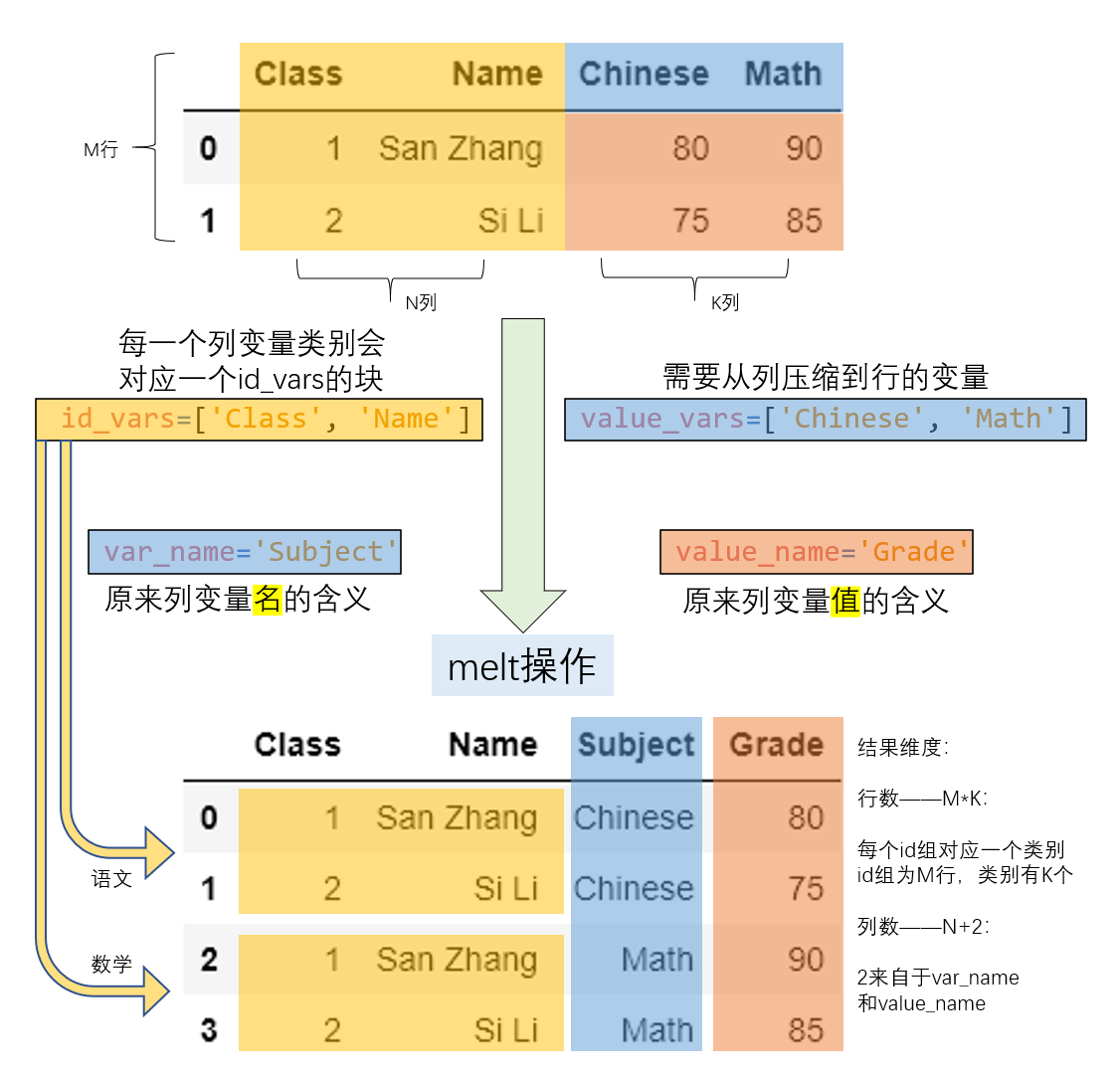
1.3 melt
pivot的逆运算,可以把宽格式转换为长格式,合并多个列成为一个,产生一个比输入长的DataFrame。
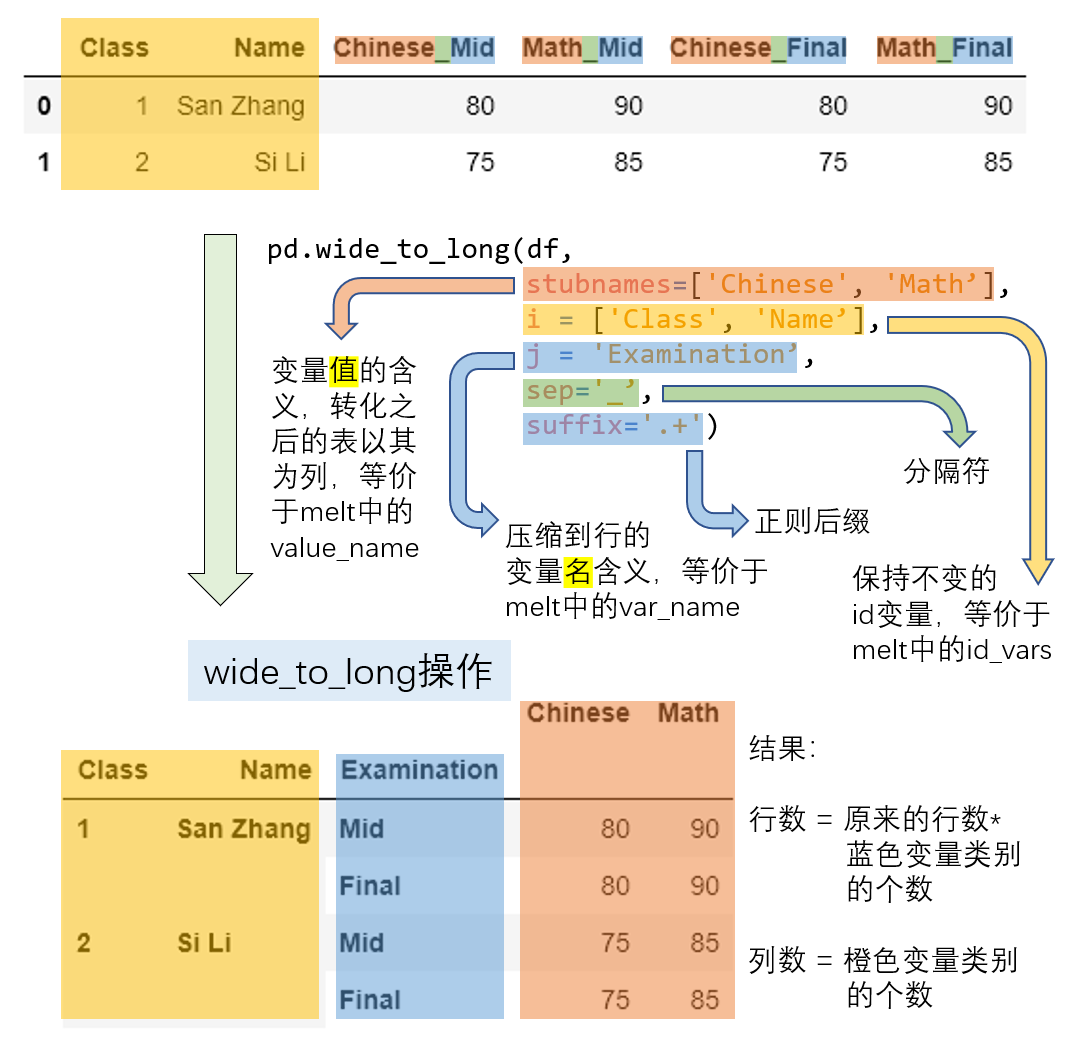
1.4 wide_to_long
同样是把宽格式转换为长格式
2 索引的变形
stack与unstack均为行列索引之间的交换。
2.1 stack与unstack
stack:将数据的列“旋转”为行
unstack:将数据的行“旋转”为列
两者均可传入分层级别或名称来指定操作层,默认转化最内层,移动到列索引的最内层,同时支持同时转化多个层。
2.2 聚合与变形的关系
分组聚合values的个数发生了变化,不带聚合效果的变形函数不会造成values个数的改变。
3 其他变形函数
3.1 crosstab 交叉表
交叉表是一种用于计算分组频率的特殊透视表,传入行索引和列索引,默认返回频数统计,也可以通过aggfunc指定聚合函数。(功能均可由pivot_table实现)
3.2 explode
对某一列的元素进行纵向展开,被展开的元素必须是list-like类型,包括列表、元组、集合、序列、np.ndarray。
3.3 get_dummies
主要用于特征构建,将分类变量转换为指标变量(0-1)。
参考:
