
使用requests库爬取并下载梨视频
url分析
以梨视频 https://www.pearvideo.com/video_1728019 为例,检查元素可以找到video链接,页面源代码没有,在Network中筛选XHR可找到
inspect element链接(有效):https://video.pearvideo.com/mp4/adshort/20210427/cont-1728019-15665358_adpkg-ad_hd.mp4
Network srcUrl链接(404):https://video.pearvideo.com/mp4/adshort/20210427/1629376413683-15665358_adpkg-ad_hd.mp4
只有加粗部分有区别,1728019为视频id,1629376413683为systemTime,获取srcUrl后replace即可得到视频下载链接。
headers找到url:https://www.pearvideo.com/videoStatus.jsp?contId=1728019&mrd=0.6482209940899077
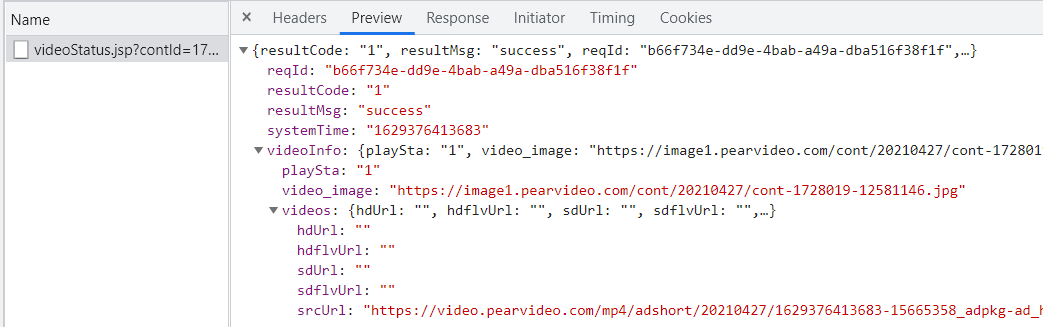

此时需要进行防盗链处理,找到referer(本次请求的上一级url):
代码
"""
输入梨视频网页地址,下载该地址视频
"""
import requests
# 1. 网页链接 以 https://www.pearvideo.com/video_1728019 为例
url = input("请输入梨视频地址:")
# 2. 视频id
contId = url.split('_')[1]
# 3. ua,防盗链
headers_dict = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
# 防盗链:溯源(referer)
"referer": url
}
# 4. 网页视频链接
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.6783504423465614"
response = requests.get(videoStatusUrl, headers=headers_dict)
# 5. 获取response
result = response.json()
response.close()
# 6. 获取视频源链接
src_url = result['videoInfo']['videos']['srcUrl']
systemTime = result['systemTime'] # 1629376413683
# 防盗链: https://video.pearvideo.com/mp4/adshort/20210427/1629376413683-15665358_adpkg-ad_hd.mp4
# 真实链接: https://video.pearvideo.com/mp4/adshort/20210427/cont-1728019-15665358_adpkg-ad_hd.mp4
# 通过比较可以发现,将系统时间替换为cont-{contId},即为真实链接
videoUrl = src_url.replace(systemTime, f"cont-{contId}")
print(videoUrl)
# 7. 下载视频
with open(f".\\videos\\pearvideo_{contId}.mp4", mode="wb") as video_f:
video_f.write(requests.get(videoUrl).content)
print(f"pearvideo_{contId} has been downloaded.")
