
Redis缓存机制详解
redis读写策略
只要使用缓存,就一定会出现数据不一致的问题,读写策略就是来避免出现数据不一致的问题,有3种,平时用的比较多的是Cache Aside Pattern(旁路缓存模式)
基础
- 写 策略:
先更新 DB
然后直接删除 cache 。 - 读 策略:
从cache中读取数据,读取到就直接返回
cache中读取不到的话,就从 DB 中读取数据返回
再把数据放到 cache 中。
写数据的时候会出现数据不一致的两种情况:
先删除cache,再更新DB的场景:请求1先把cache中的A数据删除 -> 请求2从DB中读取数据->请求1再把DB中的A数据更新。
先更新DB,再更新cache的场景:请求1从DB读数据A->请求2写更新数据 A 到数据库并把删除cache中的A数据->请求1将数据A写入cache。
先更新DB,再更新cache会有小概率数据不一致的情况,因为缓存的写入速度比数据库的写入速度快很多。
Cache Aside Pattern 的缺陷
缺陷1:首次请求数据一定不在 cache 的问题
解决办法:可以将热点数据可以提前放入cache 中。
缺陷2:写操作比较频繁的话导致cache中的数据会被频繁被删除,这样会影响缓存命中率 。
解决办法:
数据库和缓存数据强一致场景 :更新DB的时候同样更新cache,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题。
可以短暂地允许数据库和缓存数据不一致的场景 :更新DB的时候同样更新cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
高并发下的redis常见场景
1.缓存击穿:
缓存击穿是当数据是存在的,但没有被缓存到,而缓存穿透是去访问根本不存在的值。
当某个缓存故障、或者在高峰期缓存突然无效了,就会导致所有请求都跑到数据库去排队,就造成了缓存击穿。
解决方案:
方案一、后台设置定时任务,主动去更新缓存数据;
方案二、分级缓存,配置两台业务机器,平时用第一台,第一台坏了马上用第二台,用第二台的时候修第一台,设置两级缓存保护层,1级缓存失效时间短,2级缓存失效时间长。有请求过来从1级缓存找,1级缓存找不到则对该线程加锁,这个线程再从数据库查询并更新到1、2级缓存,其他线程则直接从2级缓存中获取。
2、缓存穿透:
实质是没有该缓存,当用户请求参数为param=zsan 的时候,此时数据库不存在改数据null ,默认null不保存到Redis,这时候大量请求访问不存在数据,导致请求直接打在mysql数据库上。

解决办法:布隆过滤器
3、缓存雪崩:
高并发请求时缓存在同一很短的时间内几乎同时到期,此时就可能引发雪崩问题。
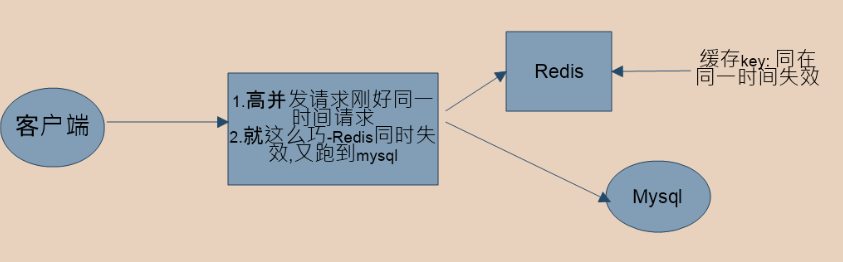
解决办法:
1、提前规划好系统中所有缓存的到期时间
2、设置超时时间,加上随机数,避免同一时间大量key失效
4、热点缓存 --本质还是缓存穿透
A用户访问param=sex消息,这时候刚好key缓存失效(正准备从数据库查询保存到Redis),这时候突然大量用户请求这个key,导致数据还没缓存的到Redis,又被请求到mysql中 【只要设置期时间,就有可能会引发热点缓存】
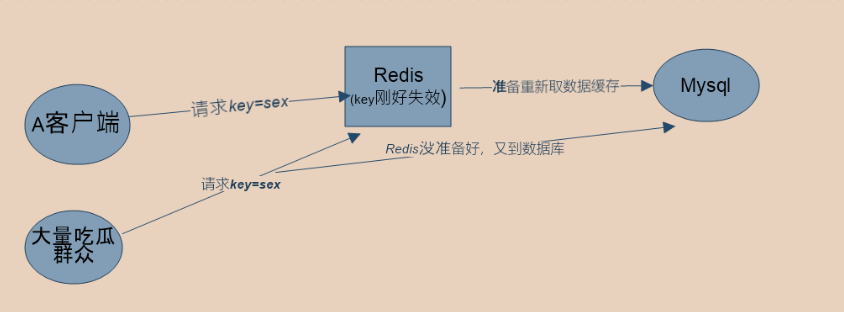
解决办法:
1、双重检测锁机制(见代码)
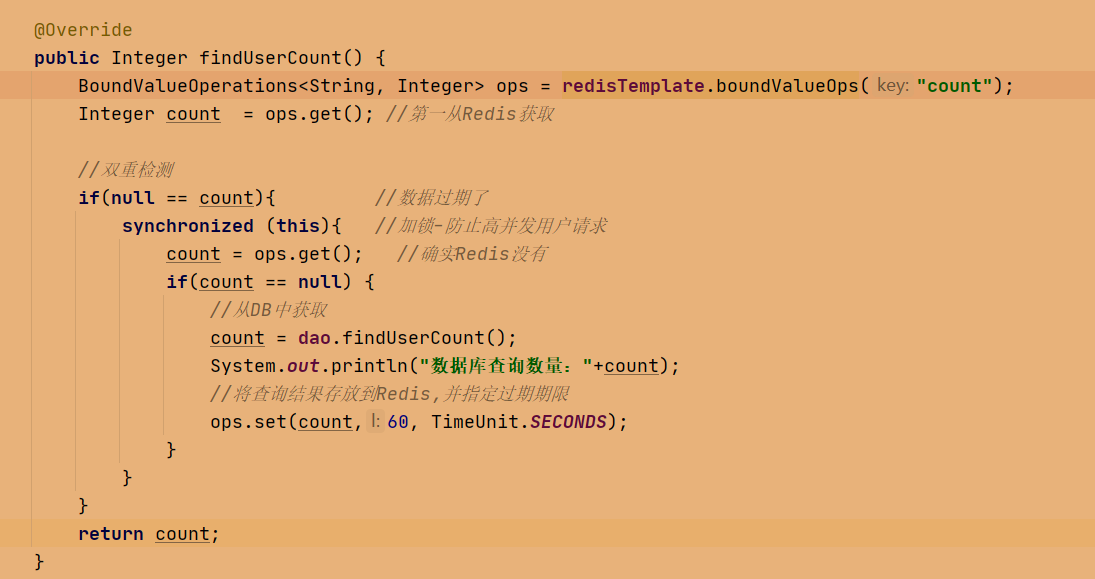
redis缓存失效策略 --redis key值过期策略
主库过期策略:惰性策略+定期扫描
1.1 惰性策略
在获取key的时候判断key值是否过期,过期则返回null并删除key值,否则正常返回数据。
1.2 定期扫描
首先将设置了过期时间的key放在一个独立的hash中,默认每秒定时扫描这个hash而不是整个空间:这里使用了简单的贪心算法。
1.1.1 从所有的key中随机找20个key
1.1.2 删除20个key中过期的key
1.1.3 如果删除的key/20超过1/4,则重复第一步操作
1.1.4 每次处理的时间都不会超过25ms
如果存在大量的key在同一时间内失效,就会造成数据库的集中访问,就是缓存雪崩。
从库过期策略:
主库删除数据时,会在aof文件中生成一条del指令,在主从同步时,从库会执行这条指令,删除过期的key。
redis内存淘汰策略
通过config get maxmemory-policy命令来查看当前内存淘汰策略
2.1.1 redis4.0及之前有6种
noeviction:不删除策略,达到内存限制时,写入如果需要更多的内存,直接返回错误信息;
allkeys-lru:优先删除最近最少使用的的key;
allkeys-random:随机删除任意key值;
volatile-lru:优先删除最近最少使用的设置了过期时间的key;
volatile-random:随机删除设置了过期时间的任意key值;
volatile-ttl:优先删除更早过期的key值;
2.1.2 reids4.0之后新增了2种
allkeys-lfu:从所有键值中淘汰最少使用的键值;
volatile-lfu:从所有设置了过期时间的键值中淘汰最少使用的键值;
2.2 内存淘汰算法
lru(最近最少使用)淘汰算法:最久没有使用的键值会被淘汰,基于链表结构实现,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要进行内存淘汰时,只需要删除链表尾部的元素即可;redis内存淘汰时,会随机取样5个值(可配置),然后淘汰最久没有使用的键值;
lfu(最不常用)淘汰算法:根据总访问次数来淘汰,它的核心思想是:如果数据过去被使用过很多次,那么将来被使用的频率会更高;它解决的是使用频率很低的缓存,只是最近使用过1次就不会被删除的问题;
