【验证码逆向专栏】某安登录流程详解与验证码逆向分析与识别

声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
前言
最近知识星球有粉丝表示自己在逆向某安的过程中有一些疑惑,过来咨询,K 哥一向会尽力满足粉丝需求。本文就对某安进行深入研究,包括登录接口逆向、验证码识别、风控等方面进行全方位的分析。
逆向目标
- 目标:某安登录界面
- 网址:
aHR0cHM6Ly9hY2NvdW50cy5iaW5hbmNlLmNvbS96aC1DTi9sb2dpbg==
抓包分析
进入登录页,随便输入账号和密码,打开开发者工具,点击下一步,会弹出九宫格点选验证码,抓包如下:
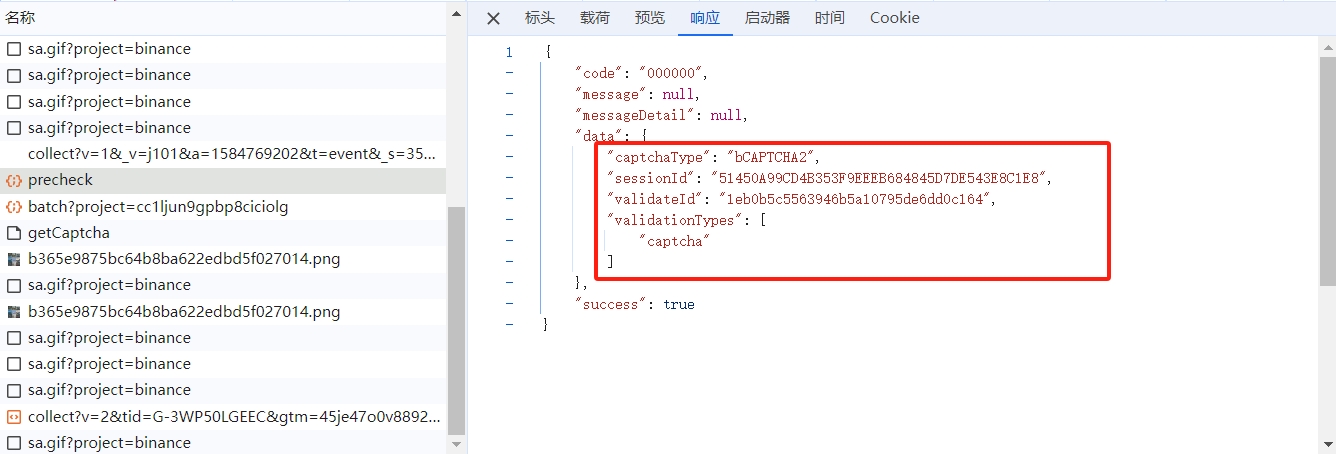
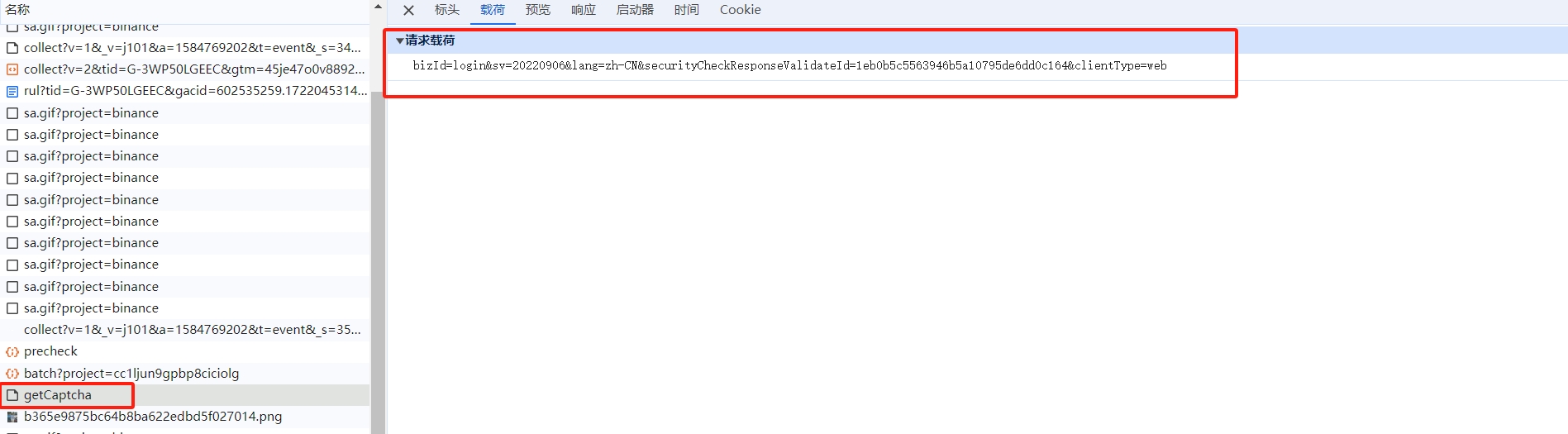
通过返回值我们可以看见,该接口给我们返回的验证码的类型以及 sessionId 还有 validateId 参数,接下来是获取图片的接口,将我们上个接口获得的 validateId 传入:
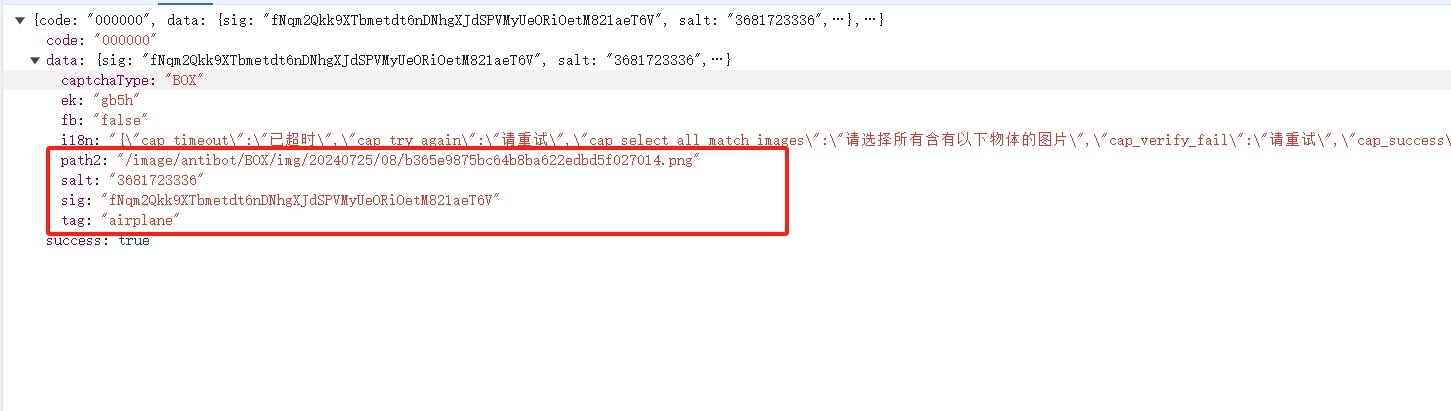
然后该接口给我们返回图片地址,盐值 salt,还有 sig 以及点选问题 tag:
接着是验证接口,需要提交 validateId、sig、data 参数,验证成功则会返回 token 值:

然后携带 token 值在接口 check/result 传入进行校验:

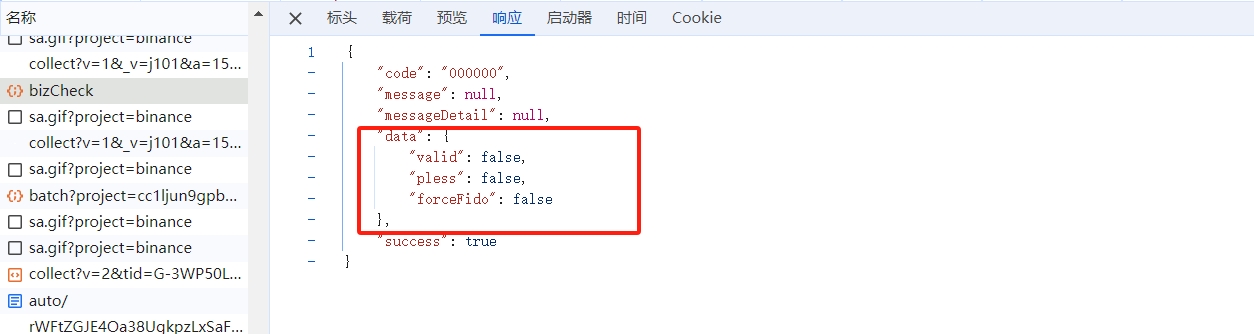
若通过则返回如下参数:

该参数可以在后续登录接口进行使用,如通过 valid 参数判断账号是否注册等:
该网站主要验证码类型为九宫格,本文将主要对九宫格进行详细的剖析:

验证码逆向分析
data 参数
九宫格验证接口中,data 参数为唯一加密参数,定位方式有很多种,这里我们直接采用跟栈的方式进行定位:
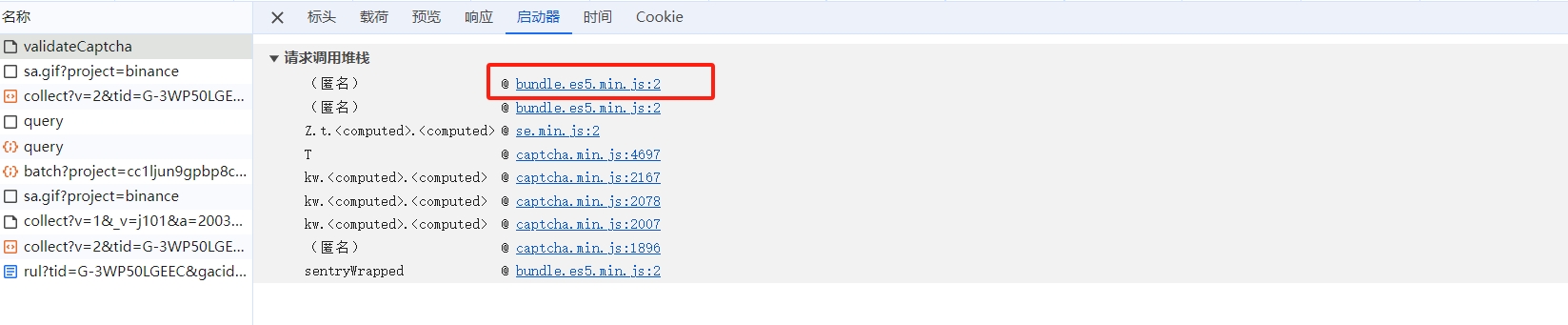
从第一个堆栈进入,在 t.apply 这一行打上断点,点击验证按钮,成功断了下来,如下:

继续向前跟栈,找到 T 函数跟进去:
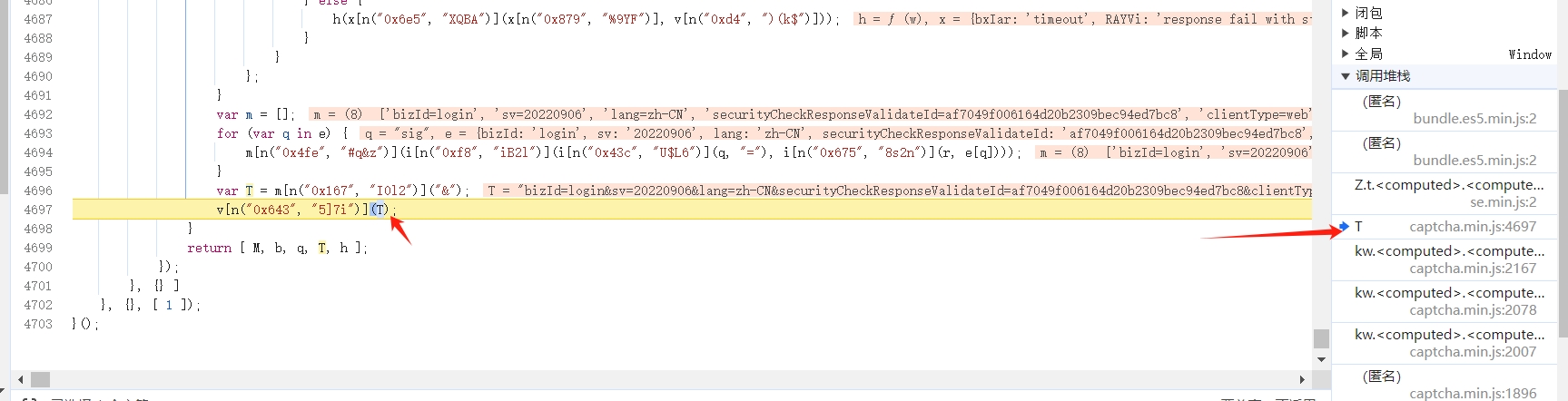
然后继续向前跟,找到参数 D 生成的地方,即为 data 参数加密的位置:
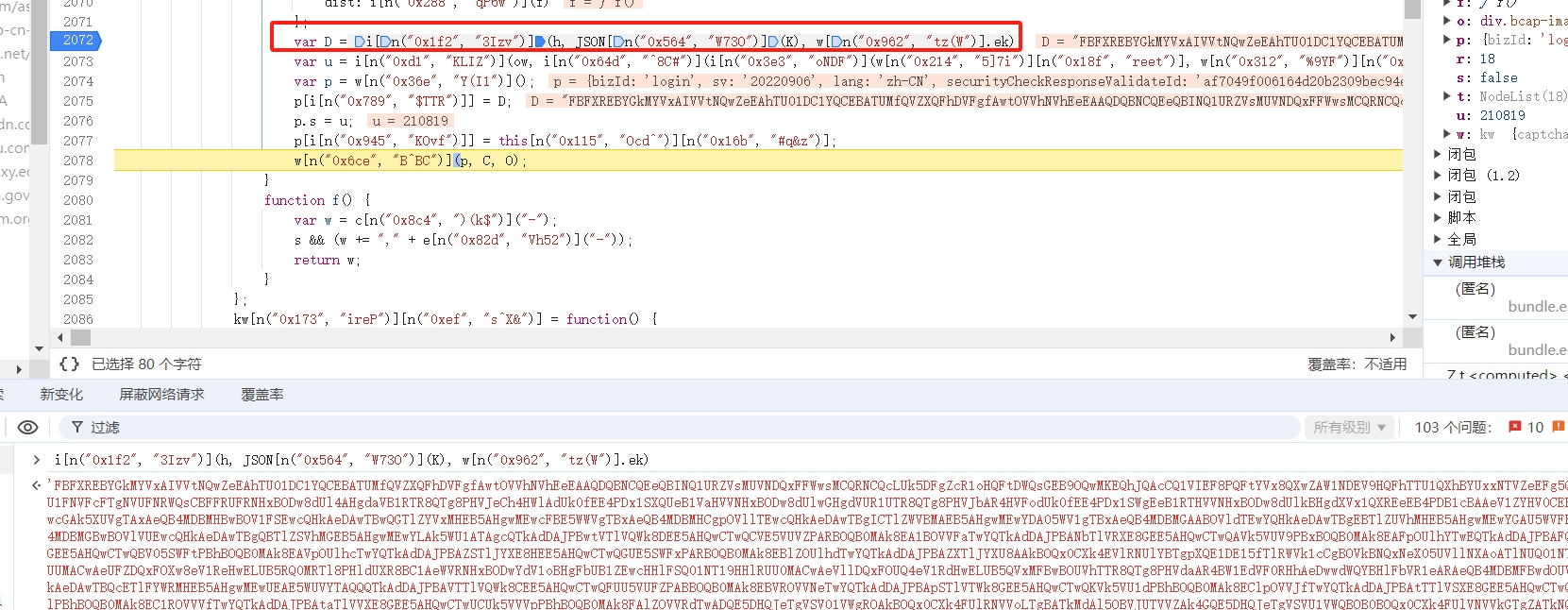
发现这个 JS 被混淆了,我们可以用 v_jstools 进行简单的变量还原,替换进去即可,最终我们分析可得,data 参数是由 ek 和轨迹明文加密得到的,这里我们跟进加密函数 h 中,看看 data 是如何生成的:
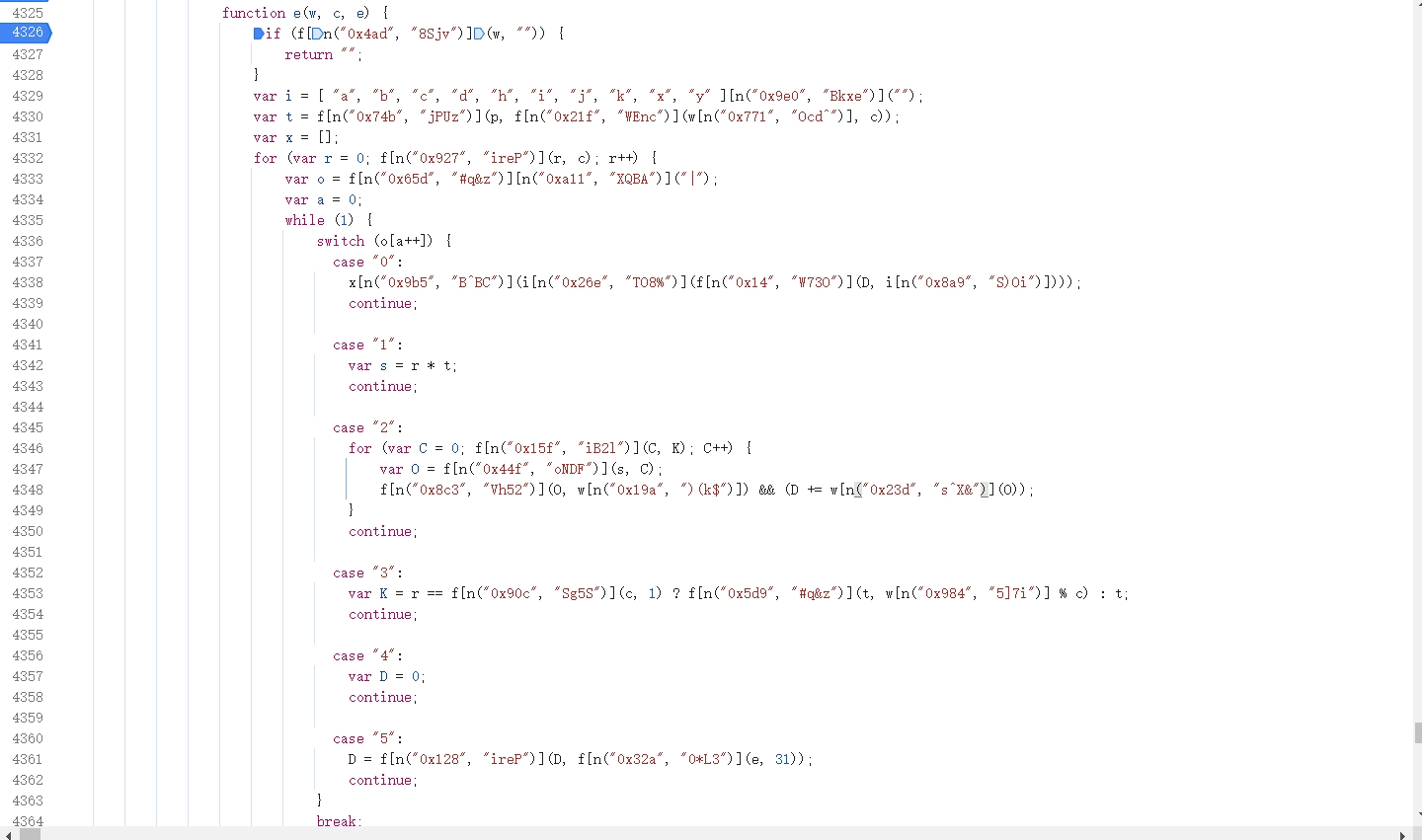
很明显这是平坦流,经过分析可知将传入的参数 ek 进行处理后,同 w 参入传入 m 函数进行处理:

最终通过 return f[n("0x916", "h1Kz")](m, w, t) 将处理结果进行返回,即生成最终的 data 参数,所以我们需要将 e 函数与 m 函数成功拿下,即可复现 data 参数的生成流程,接下来我们将用俩种扣代码的方法实现 data 参数复现。
第一种方法,我们可以首先将大数组、移位函数、解密函数这三个模块拿下来:

然后我们将大函数 h 整体拿下来,然后我们仿照源代码
var D = i[n("0x1f2", "3Izv")](h, JSON[n("0x564", "W73O")](K), w[n("0x962", "tz(W")].ek)
自己封装一个加密函数,对这个 h 函数进行调用,如下:
function encode(am, ek) {
word = JSON.stringify(am);
ms = h(word, ek)
return ms
}
然后会提示,v 或者 f 不存在:
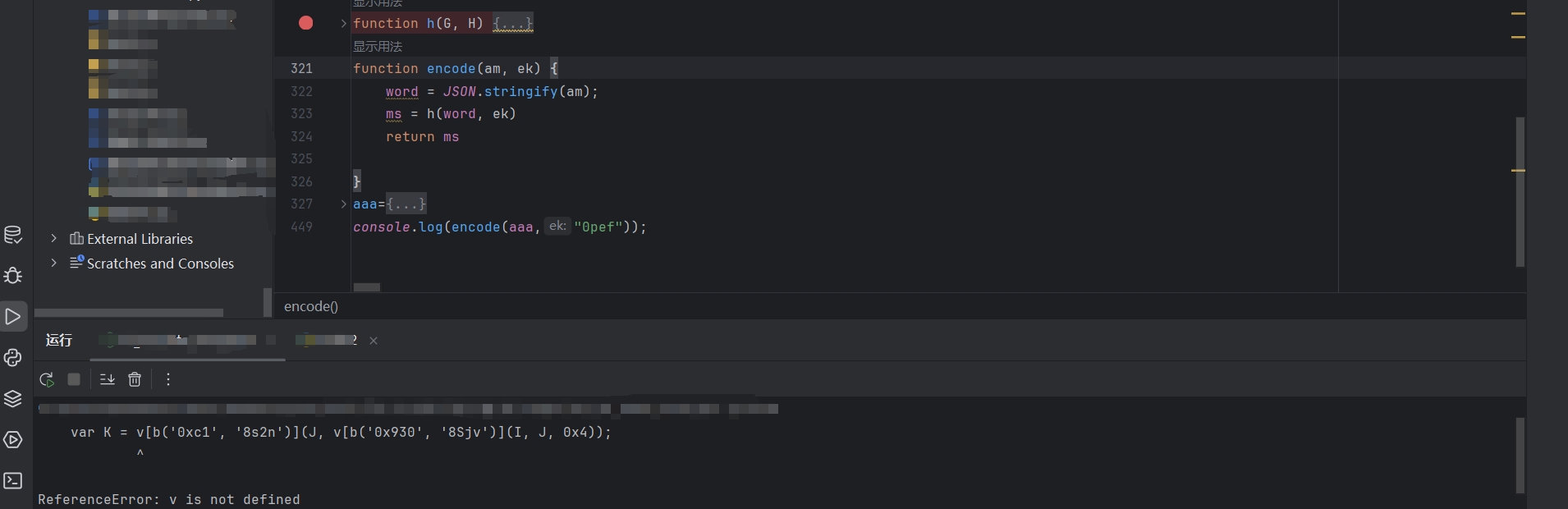
我们在网页相同的地方下断点,将 v 与 f 扣下来补到我们刚刚的 js 文件中。
接着继续调试,同样还会提示各种函数不存在:

我们同上的方法将缺失模块找到放到 js 文件种进行调试,最终 data 参数即可生成:

这种方法最后全部必要的 js 代码拿下来的话,代码 800 行左右。
第二种方法,我们可以跟进主要的加密函数进行代码分析,将主要代码扣下来,在大函数 h 中,首先对 ek 进行了翻转,如下:

复现如下:
var i = ek["split"]("")["reverse"]()["join"]("")
紧接着将翻转后的 ek 传入var t = f[n("0xc1", "8s2n")](i, f[n("0x930", "8Sjv")](e, i, 4)); 进行处理,我们可以看见翻转后的 ek 为 i ,同 4 被传入 e 中进行处理,跟进 e 中,看看他进行了哪些操作:

同样这部分操作也进行了平坦流的混淆,经过分析可知, 这个算法将输入字符串 w 按照参数 c 分块,对每个块的字符进行 Unicode 编码累加,乘以参数 e(默认 31),然后取模字符串 i 的长度,从中选出对应字符,最终生成一个新的字符串返回。 最终算法如下:
function eee(w, c, e) {
var i = "abcdhijkxy";
var t = 1;
var x = [];
for (var r = 0; r < c; r++) {
var D = 0;
var s = r * t;
var K = r == (c - 1) ? (t + w.length % c) : t;
for (var C = 0; C < K; C++) {
var O = s + C;
if (O < w.length) {
D += w.charCodeAt(O);
}
}
D = D * (e || 31);
x.push(i.charAt(D % i.length));
}
return x.join("");
}
同网站测试结果相同,说明我们算法正确:

最终我们再来分析 m 函数,进入 m 函数中,发现同样也是吃相极其难看的代码:

经过分析可知,m 函数初步流程为使用密钥 c 进行简单的编码,复现如下:
if (!w) {
return "";
}
var e = w;
var t = "";
for (var x = 0; x < e["length"]; x++) {
t += String.fromCharCode(e["charCodeAt"](x)^ c["charCodeAt"](x%c["length"]));
}
最终传入 d 函数进行最后的加密,最后我们进入 d 函数进行分析:

发现有我们很熟悉关键字 "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/",最终证实 d 函数确实是一个 base64 加密,只是通过平坦流将代码拆分,变成我们不熟悉的样子,至此所以加密流程分析完毕,将全部代码进行整合,即可复现 data 参数的生成:
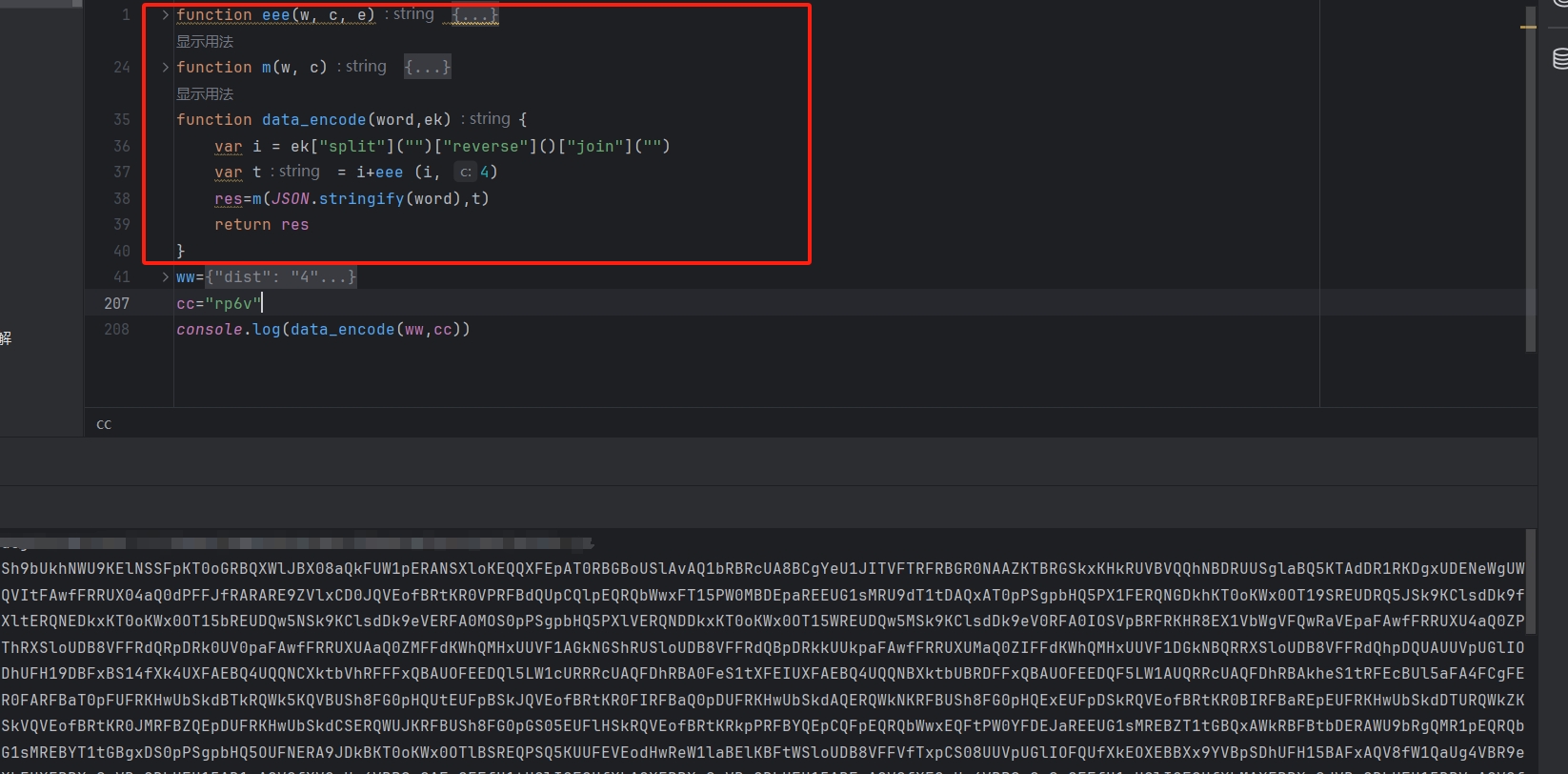
发现代码加密流程仅 40 行,相比之前的 800 多行,发现算法跟踪下来,我们生成的加密算法更加简洁,不同方法适应不同的人,总会找到一个适合你的方法。
九宫格模型训练
针对模型的训练,相信之前的文章大家也都了解的很多了,九宫格可以采用纯分类实现,也可以使用检测+分类去实现,具体实现方法参考往期文章:
import os
import shutil
import random
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import SGD
# 参数配置
config = {
'train_data': './data',
'val_data': './data',
'input_shape': (60, 60, 3),
'batch_size': 32,
'nb_epoch': 100,
'workers': 1,
'learning_rate': 0.001,
'momentum': 0.9,
'reduce_lr_patience': 4,
'early_stopping_patience': 10,
'model_name': 'tuili',
'base_model_path': '', # 预训练模型 为空就用 ResNet50
}
def split_dataset(dataset_dir, train_dir, val_dir, val_ratio=0.2):
"""
划分数据集为训练集和验证集
:param dataset_dir: str, 数据集文件夹路径
:param train_dir: str, 训练集文件夹路径
:param val_dir: str, 验证集文件夹路径
:param val_ratio: float, 验证集比例
:return:
"""
if not os.path.isdir(train_dir):
os.makedirs(train_dir)
if not os.path.isdir(val_dir):
os.makedirs(val_dir)
for class_name in os.listdir(dataset_dir):
class_dir = os.path.join(dataset_dir, class_name)
if not os.path.isdir(class_dir):
continue
train_class_dir = os.path.join(train_dir, class_name)
val_class_dir = os.path.join(val_dir, class_name)
if not os.path.isdir(train_class_dir):
os.makedirs(train_class_dir)
if not os.path.isdir(val_class_dir):
os.makedirs(val_class_dir)
img_list = os.listdir(class_dir)
img_num = len(img_list)
val_num = int(val_ratio * img_num)
random.shuffle(img_list)
val_list = img_list[:val_num]
train_list = img_list[val_num:]
for img_name in val_list:
src_path = os.path.join(class_dir, img_name)
dst_path = os.path.join(val_class_dir, img_name)
shutil.copyfile(src_path, dst_path)
for img_name in train_list:
src_path = os.path.join(class_dir, img_name)
dst_path = os.path.join(train_class_dir, img_name)
shutil.copyfile(src_path, dst_path)
print('Split dataset into train and val successfully!')
def prepare_data(data_dir, val_data_dir, input_shape, batch_size):
"""数据预处理和加载"""
train_datagen = ImageDataGenerator(rescale=1.0 / 255)
val_datagen = ImageDataGenerator(rescale=1.0 / 255)
train_ds = train_datagen.flow_from_directory(
data_dir,
target_size=input_shape[:2],
batch_size=batch_size,
class_mode='categorical',
seed=123
)
val_ds = val_datagen.flow_from_directory(
val_data_dir,
target_size=input_shape[:2],
batch_size=batch_size,
class_mode='categorical',
seed=123
)
return train_ds, val_ds
def build_model(input_shape, num_classes, base_model_path=None):
"""构建模型"""
if base_model_path:
model = tf.keras.models.load_model(base_model_path)
else:
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=input_shape)
x = base_model.output
x = Flatten()(x)
predictions = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(optimizer=SGD(learning_rate=config['learning_rate'], momentum=config['momentum']),
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
def main():
# 数据集划分(如果需要)
# split_dataset(config['dataset_dir'], config['train_dir'], config['val_dir'])
train_ds, val_ds = prepare_data(config['train_data'], config['val_data'], config['input_shape'],
config['batch_size'])
# 获取类别数
num_classes = len(train_ds.class_indices)
# 构建模型
model = build_model(config['input_shape'], num_classes, config['base_model_path'])
# 模型摘要打印
model.summary()
# 设置回调
callbacks = [
tf.keras.callbacks.ModelCheckpoint(filepath=config['model_name'], monitor='val_accuracy', save_best_only=True,
mode='max'),
tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=config['reduce_lr_patience']),
tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=config['early_stopping_patience']),
]
# 训练模型
model.fit(
train_ds,
epochs=config['nb_epoch'],
validation_data=val_ds,
callbacks=callbacks,
workers=config['workers']
)
if __name__ == '__main__':
main()
最终在推理的时候,将模型转为 onnx (相关转换在上述付费文章中均有讲到),然后我们只需要将九宫格图片按照指定的大小切割出来去识别然后和标题对应就好了,关于打标的话,星球也有相关配套工具给大家使用:
推理如下:
import onnxruntime
import numpy as np
import cv2
from PIL import Image
class OCR():
def __init__(self, model_path):
self.ort_session = onnxruntime.InferenceSession(model_path)
def inference(self, img_tensor):
inputs = {self.ort_session.get_inputs()[0].name: img_tensor}
outInfo = self.ort_session.run(None, inputs)[0]
result_index = int(np.argmax(outInfo))
class_names = ['大象', '熊猫', '狗', '猫', '自行车', '船', '车', '飞机', '鱼', '鸟']
result = class_names[result_index]
return result
def preprocess_image(self, img):
img = cv2.resize(img, (110, 110))
img = np.asarray(img).astype(np.float32)
img = np.expand_dims(img, axis=0)
return img
def split_image(img):
content_box_list = []
height, width = img.shape[:2]
block_height = height // 3
block_width = width // 3
for i in range(3):
for j in range(3):
block = img[i * block_height:(i + 1) * block_height, j * block_width:(j + 1) * block_width]
content_box_list.append(block)
return content_box_list
def identify_grid_content(image_path, model_path):
ocr = OCR(model_path)
image = cv2.imread(image_path)
content_box_list = split_image(image)
result_list = []
for idx, image in enumerate(content_box_list):
img_tensor = ocr.preprocess_image(image)
identified_item = ocr.inference(img_tensor)
result_list.append((idx, identified_item))
return result_list
# Example usage
if __name__ == '__main__':
image_path = '1.jpg'
model_path = './mouan.onnx'
results = identify_grid_content(image_path, model_path)
print(results)
另外一种办法就是用 v8 去检测实现分类识别,关于相关文章在之前也有提过,训练完毕以后我们可以采用星球成员提出的方法进行推理部署:
基于 fastdeploy 的多方法图标推理:https://t.zsxq.com/Xndh3
不管哪种方法,只要能实现就是最好的办法,关于分类的数据集会整理上传到星球,星球成员可以自主下载数据集进行训练。
风控检测
风控会更新,以下是之前研究的时间段的测试结果,仅供参考。
环境正常,会弹九宫格,验证码类型随环境风险等级的提升而改变:
九宫格(bCaptcha2)、Cloudflare(turnstile)、reCaptcha(reCAPTCHA)、滑块(bCaptcha)
出现滑块,就是环境完全黑了,过了滑块也无法请求成功(网页端手动操作也一样)。
主要是三级风控:1. device-info;2. Cookies(BNC_FV_KEY_T、se_gsd 等等);3. 指纹,三级都黑了,就会风控区号(mobileCode),浏览器登录同样被限制(找朋友测试,区号黑了,地理位置、设备不同,登录都是一样的效果):
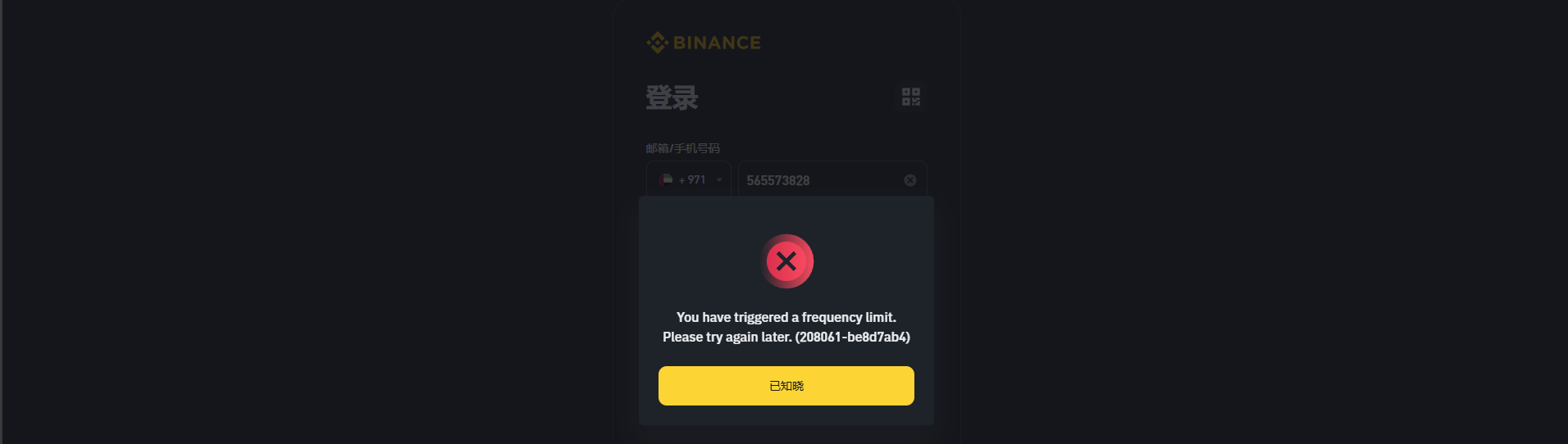
风控限制和请求速度无关,与请求量有关,区号被风控后会逐步恢复,1 小时左右会解除限制。对爱尔兰的 ip 风控相对较松。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号