【0基础学爬虫】爬虫框架之 feapder 的使用

前言
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫。
学习爬虫的过程中,一般都会接触到一些框架,常见的比如 Scrapy、Pyspider 等等,不同的框架都有着各自的特点。不过就上述两款爬虫框架而言,Pyspider 久未维护,且安装到使用的过程较为坎坷;Scrapy 生态良好,功能丰富,但是对于初学者来说,学习成本相对较高。feapder 框架近年来较为火热,正好也有群友提到了:
因此,本期将讲解一款上手更为简单,功能同样强大的爬虫框架 —— feapder。
简介
feapder 是一款上手简单,功能强大的 Python 爬虫框架。内置 AirSpider、Spider、TaskSpider、BatchSpider 四种爬虫解决不同场景的需求:
- AirSpider:轻量级爬虫,适合简单场景、数据量少的爬虫;
- Spider:分布式爬虫,基于 Redis,适用于海量数据,并且支持断点续爬、自动数据入库等功能;
- TaskSpider:任务型爬虫,支持对接任务表,如 mysql、redis 等;
- BatchSpider:分布式批次爬虫,主要用于需要周期性采集的爬虫。
feapder 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。更有功能强大的爬虫管理系统 Feaplat 为其提供方便的部署及调度。
feapder 官方资料:
GitHub:https://github.com/Boris-code/feapder
官方文档:https://feapder.com/
官方公众号:feader爬虫教程
架构设计
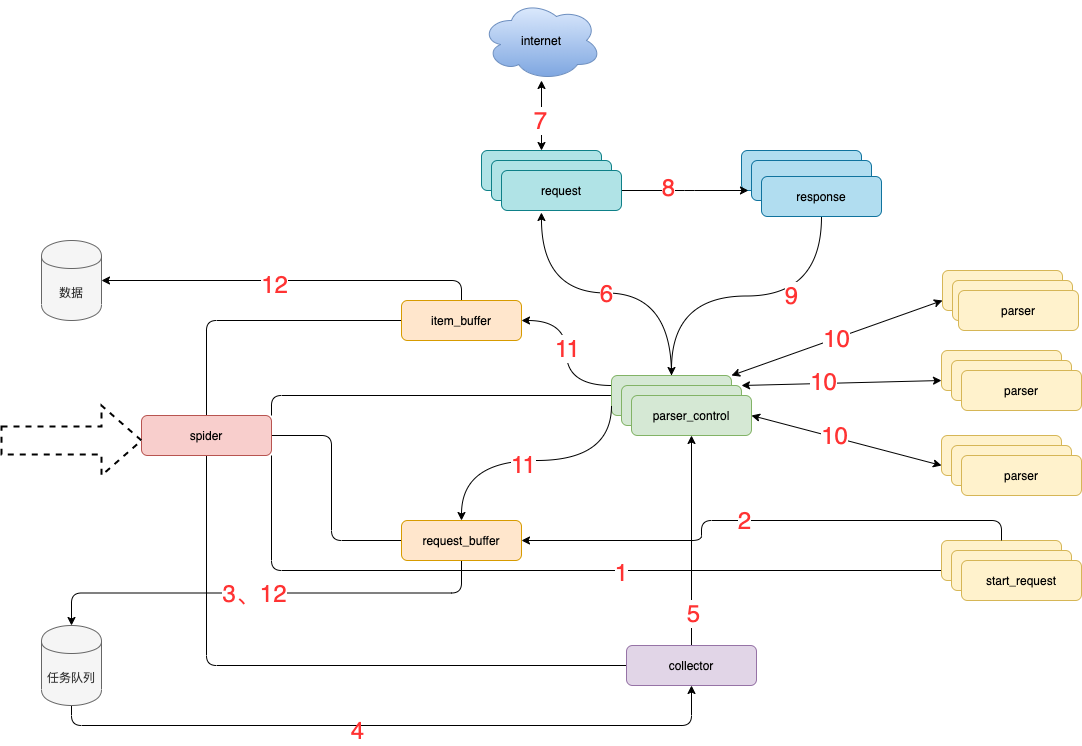
官方框架流程图
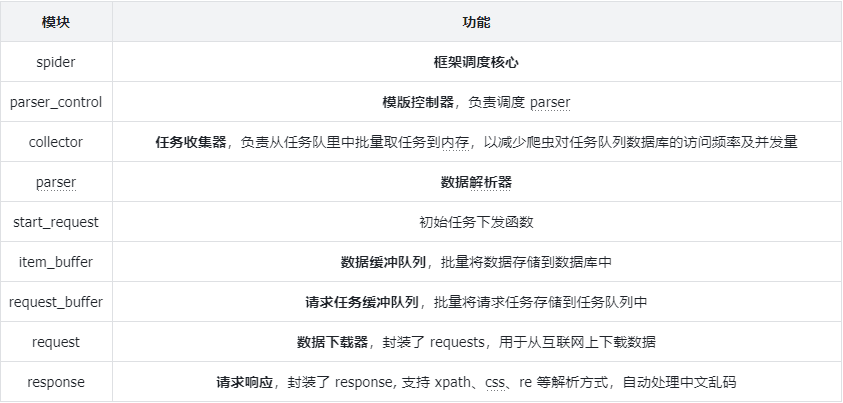
模块说明
流程说明
根据上文框架流程图,按流程序号分析功能:
- spider 调度 start_request 生产任务;
- start_request 下发任务到 request_buffer 中;
- spider 调度 request_buffer 批量将任务存储到任务队列数据库中;
- spider 调度 collector 从任务队列中批量获取任务到内存队列;
- spider 调度 parser_control 从 collector 的内存队列中获取任务;
- parser_control 调度 request 请求数据;
- request 请求与下载数据;
- request 将下载后的数据给 response,进一步封装;
- 将封装好的 response 返回给 parser_control(图示为多个 parser_control,表示多线程);
- parser_control 调度对应的 parser,解析返回的 response(图示多组 parser 表示不同的网站解析器);
- parser_control 将 parser 解析到的数据 item 及新产生的 request 分发到 item_buffer 与 request_buffer;
- spider 调度 item_buffer 与 request_buffer 将数据批量入库。
feapder 的使用
环境
- Python 3.6.0+
- Works on Linux,Windows,macOS
安装
① 精简版
pip install feapder
不支持浏览器渲染、不支持基于内存去重、不支持入库 mongo。
② 浏览器渲染版
pip install "feapder[render]"
不支持基于内存去重、不支持入库 mongo。
③ 完整版
pip install "feapder[all]"
支持所有功能。
常见安装问题:
安装成功,查看版本及可用命令:
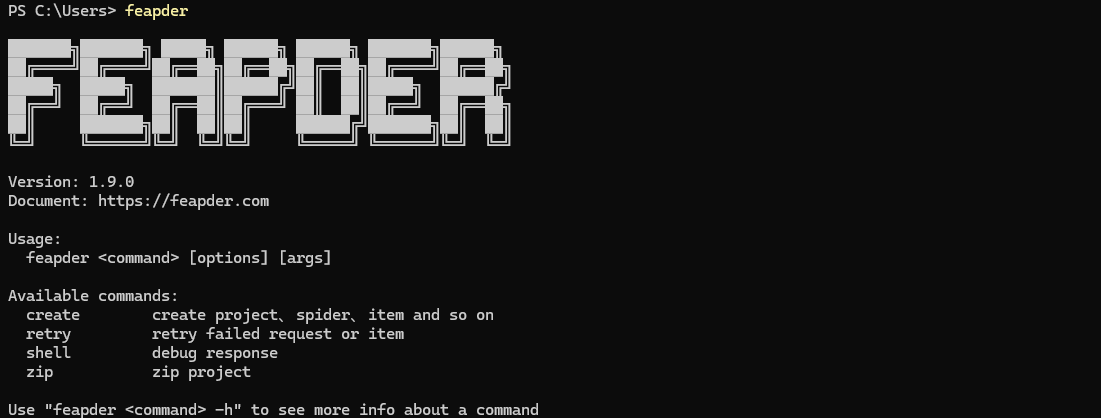
feapder 支持 create、retry、shell 及 zip 四种命令,feapder <command> -h 查看使用帮助。
详细资料:
AirSpider
轻量爬虫,学习成本低,面对一些数据量较少,无需断点续爬,无需分布式采集的需求,可采用此爬虫。
① 创建爬虫项目
命令如下:
feapder create -p <project_name>

和 Scrapy 一样,创建新项目时,会自动生成一系列的文件和目录结构,有助于理解与使用框架:

相关文件简介:
- items: 文件夹存放与数据库表映射的 item;
- spiders: 存放爬虫脚本的文件夹;
- CHECK_DATA.md:数据审核建议;
- main.py: 运行入口(附代码样例);
- setting.py: 详细的框架配置文件。
② 创建爬虫程序
命令如下:
feapder create -s <spider_name>
选择需要创建的爬虫模板,按上下键更换模版,这里选择 AirSpider 模板,回车即可创建成功:

代码样例如下:
# -*- coding: utf-8 -*-
"""
Created on xxx
---------
@summary:
---------
@author: kg_spider
"""
import feapder
from loguru import logger
class FeapderSpiderDemo(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.kuaidaili.com/free")
def parse(self, request, response):
# 提取网站 title
logger.info(response.xpath("//title/text()").extract_first())
# 提取网站描述
logger.info(f"网站地址: {response.url}")
if __name__ == "__main__":
FeapderSpiderDemo().start()
- feapder.AirSpider:轻量爬虫基类;
- start_requests:初始任务下发入口;
- feapder.Request:基于 requests 库类似,表示一个请求,支持 requests 所有参数,同时也可携带些自定义的参数;
- parser:数据解析函数;
- response:请求响应的返回体,支持 xpath、re、css 等解析方式。
运行结果:
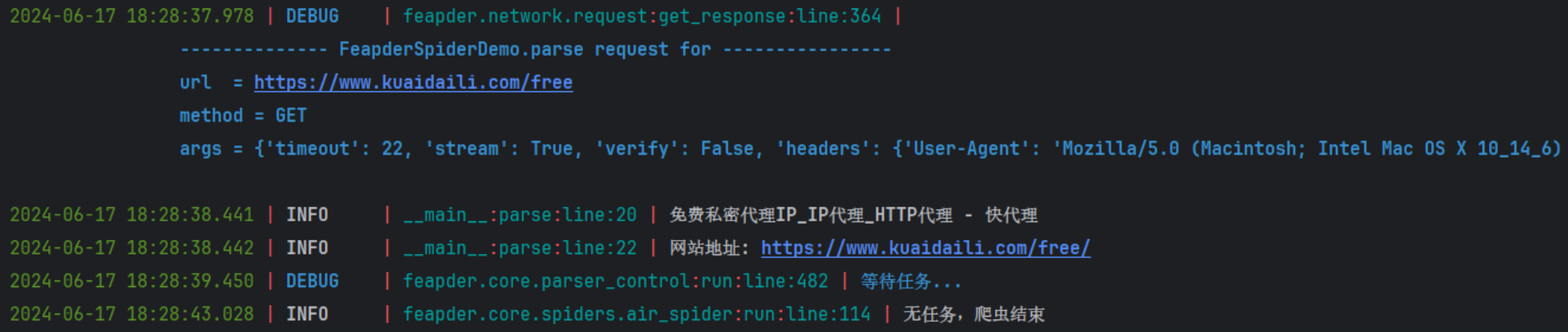
可以看到,默认会输出请求链接(url)、请求方式(method)以及请求头相关信息(args),不需要的可以跟进到 requests.py 文件中,将 log 部分注释掉即可:
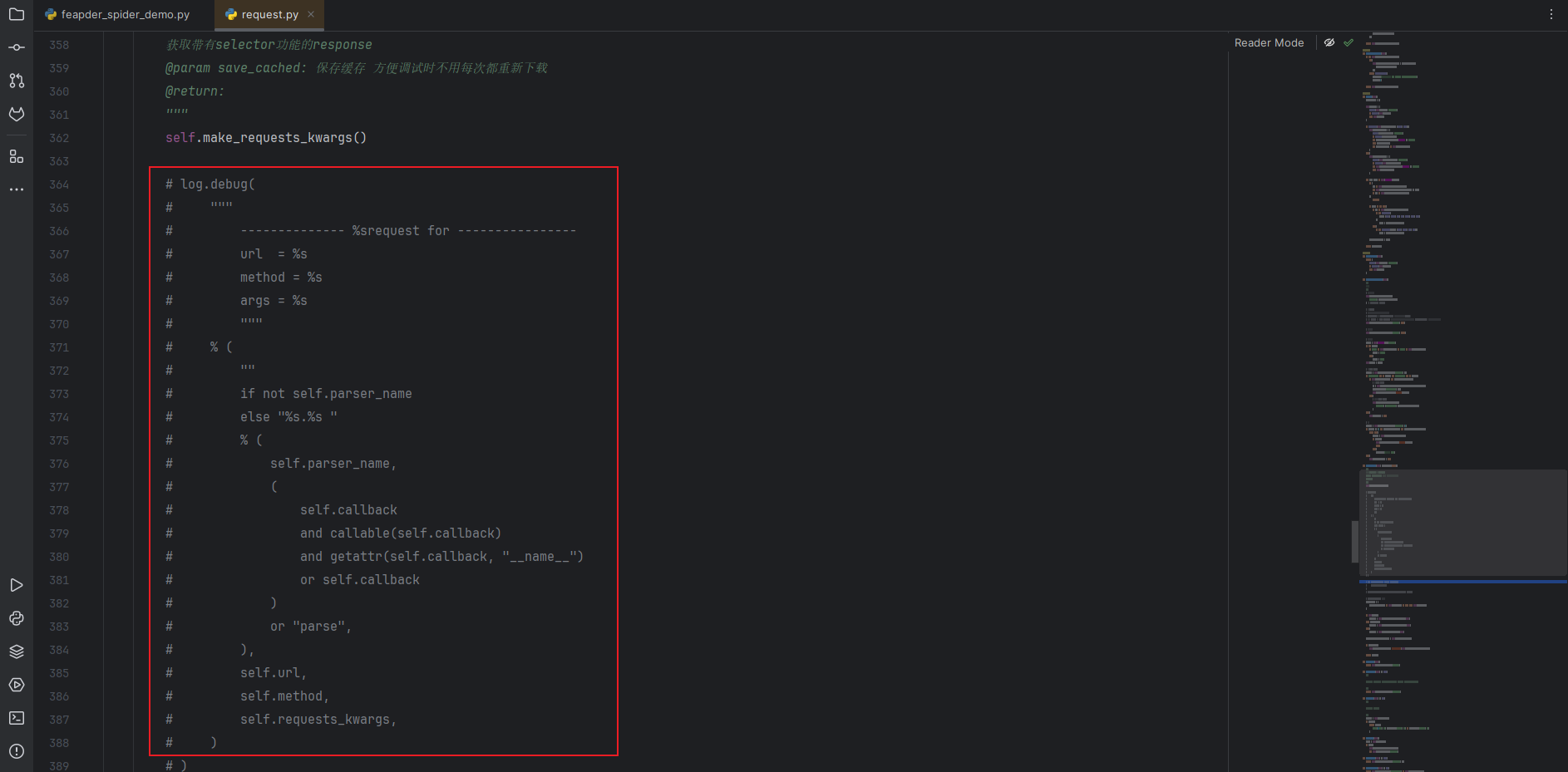
③ AirSpider 的基本使用方法
如果需要解析的函数不止一个的话,可以自定义解析函数(默认失败重试 10 次)、下载中间件(cookies、headers 等)以及失败重试等等,囊括在下面的代码样例中:
# -*- coding: utf-8 -*-
"""
Created on xxx
---------
@summary:
---------
@author: kg_spider
"""
import feapder
from loguru import logger
class FeapderSpiderDemo(feapder.AirSpider):
# 自定义配置项
__custom_setting__ = dict(
SPIDER_MAX_RETRY_TIMES=5,
)
def start_requests(self):
yield feapder.Request("https://www.baidu.com", download_midware=self.download_midware) # 不指定 callback, 任务会调度默认的 parser 上
yield feapder.Request("https://www.kuaidaili.com/free", callback=self.spider_kdl) # 指定了 callback, 任务由 callback 指定的函数解析
def download_midware(self, request):
"""
下载中间件
在请求之前, 对请求做一些处理, 如添加 cookie、header 等
"""
# 添加 headers
request.headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
return request
def parse(self, request, response):
# 提取网站 title
logger.info(response.xpath("//title/text()").extract_first())
# 提取网站描述
logger.info(f"网站地址: {response.url}")
# 异常重试
if response.status_code != 200:
raise Exception("未正常获取到有效页面")
@staticmethod
def spider_kdl(request, response):
# 提取网站 title
logger.info(response.xpath("//title/text()").extract_first())
# 提取网站描述
logger.info(f"网站地址: {response.url}")
if __name__ == "__main__":
FeapderSpiderDemo().start()
运行结果:

feapder 框架内置了能够停止整个爬虫程序的方法:
import feapder
class AirTest(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.kuaidaili.com/free")
def parse(self, request, response):
self.stop_spider() # 停止爬虫,可以在任意地方调用该方法
if __name__ == "__main__":
AirTest().start()
④ 数据入库
feapder 框架内封装了 MysqlDB、RedisDB,与 pymysql 不同的是,MysqlDB 使用了线程池,且对方法进行了封装,使用起来更方便:
- 线程池:MysqlDB 使用了线程池来管理数据库连接。这意味着在执行数据库操作时,可以复用现有的数据库连接,而不是每次操作都新建一个连接,从而提高了性能和效率,特别是在高并发场景下。
- 方法封装:MysqlDB 对常用的数据库操作进行了封装,使得开发者可以更简便地进行增删改查等操作,而不需要直接编写繁琐的 SQL 语句。
MysqlDB 具有断开自动重连特性,支持多线程下操作,内置连接池,最大连接数 100。同时,封装了增删改查等方法,使相关操做更为方便,可自行测试。
RedisDB 支持普通模式(单节点)、哨兵模式、集群模式:
- 哨兵模式:RedisDB 支持 Redis 的哨兵模式(Sentinel),这是一种用于实现高可用性的 Redis 配置,可以自动监测主从实例的状态并在主实例发生故障时自动完成主从切换。
- 集群模式:RedisDB 也支持 Redis 集群模式,这是一种用于分布式存储的 Redis 配置,可以将数据分布在多个 Redis 节点上,从而实现水平扩展和高可用性。
基本使用方法如下:
import feapder
from feapder.db.mysqldb import MysqlDB
from feapder.db.redisdb import RedisDB
class AirSpiderTest(feapder.AirSpider):
__custom_setting__ = dict(
MYSQL_IP="localhost",
MYSQL_PORT = 3306,
MYSQL_DB = "kgspider",
MYSQL_USER_NAME = "spider123",
MYSQL_USER_PASS = "123456"
)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db = MysqlDB()
⑤ 线程数配置
框架默认的线程数为 1,但在正常业务中,基本不可能只采用单线程的工作方式进行数据采集,feapder 的多线程配置有几种方式:
1、在启动函数中传递线程数:
if __name__ == "__main__":
AirSpiderTest(thread_count=10).start()
2、在配置文件 setting.py 中更改对应的配置项:
SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐 32
3、 在程序脚本中,使用类变量 __custom_setting__ 自定义配置项:
import feapder
class SpiderTest(feapder.AirSpider):
__custom_setting__ = dict(
SPIDER_THREAD_COUNT=10,
)
在程序脚本中自定义配置项,优先级会大于在 setting.py 中设置。
feapder 框架还支持浏览器(Chrome、Edge、PhantomJS、Firefox)渲染采集(自动化)的方式,功能很全面:

# 浏览器渲染
WEBDRIVER = dict(
pool_size=1, # 浏览器的数量
load_images=True, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为 user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
custom_argument=["--ignore-certificate-errors"], # 自定义浏览器渲染参数
xhr_url_regexes=None, # 拦截 xhr 接口,支持正则,数组类型
auto_install_driver=False, # 自动下载浏览器驱动 支持 chrome 和 firefox
)
更详细的功能介绍,推荐阅读官方文档,就不在此赘述了:
AirSpider:https://feapder.com/#/usage/AirSpider
Spider
Spider 是一款基于 redis 的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能。
① 创建爬虫项目
与 AirSpider 相同,命令如下:
feapder create -p <project_name>
② 创建爬虫程序
命令如下:
feapder create -s <spider_name>
选择需要创建的爬虫模板,按上下键更换模版,这里选择 Spider 模板,回车即可创建成功:

代码样例如下,默认给了 redis 的配置方式,连接信息需按真实情况修改:
# -*- coding: utf-8 -*-
"""
Created on xxx
---------
@summary:
---------
@author: kg_spider
"""
import feapder
class FeapderSpiderDemo(feapder.Spider):
# 自定义数据库,若项目中有 setting.py 文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379", REDISDB_USER_PASS="", REDISDB_DB=0
)
def start_requests(self):
yield feapder.Request("https://www.kuaidaili.com/free")
def parse(self, request, response):
# 提取网站 title
print(response.xpath("//title/text()").extract_first())
if __name__ == "__main__":
# 创建爬虫实例并启动爬虫
# redis_key 用于在 Redis 中存储请求队列和其他任务相关信息
FeapderSpiderDemo(redis_key="xxx:xxx").start()
配置信息:
- REDISDB_IP_PORTS: Redis 服务器的连接地址。若为集群或哨兵模式,多个连接地址用逗号分开,若为哨兵模式,需要加个 REDISDB_SERVICE_NAME 参数;
- REDISDB_USER_PASS: Redis 服务器的连接密码;
- REDISDB_DB:使用 Redis 的默认数据库,通常是 0。Redis 支持多数据库索引(从 0 到 15),可以通过更改此值来选择不同的数据库。
Spider 支持断点续爬,其利用了 redis 有序集合来存储任务,有序集合有个分数,爬虫取任务时,只取小于当前时间戳分数的任务,同时将任务分数修改为当前时间戳 +10 分钟(可自行配置),(这个取任务与改分数是原子性的操作)。当任务做完时,且数据已入库后,再主动将任务删除。
Spider 任务请求失败或解析函数抛出异常时,会自动重试,默认重试次数为 100 次(可自行配置)。当任务超过最大重试次数时,默认会将失败的任务存储到 redis 的 {redis_key}😒_failed_requsets 里,以供排查。
更详细的功能介绍,建议阅读官方文档:
TaskSpider、BatchSpider
TaskSpider:一款分布式爬虫,内部封装了取种子任务的逻辑,内置支持从 redis 或者 mysql 获取任务,也可通过自定义实现从其他来源获取任务。
BatchSpider:一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。会自动维护个批次信息表,详细的记录了每个批次时间、任务完成情况、批次周期等信息。会维护个批次时间信息,本批次未完成下一批次不会开始。
- 批次的含义:例如 2024.07.05 开始采集,2024.07.08 才采集完成,此间数据的批次都为 2024.07.05。方便业务做时序数据展示。
四种爬虫模板:AirSpider -> Spider -> TaskSpider -> BatchSpider,后一种都是基于前一种的优化,具体的使用说明,官方文档都写的很清楚了:
TaskSpider:https://feapder.com/#/usage/TaskSpider
BatchSpider:https://feapder.com/#/usage/BatchSpider
数据监控
feapder 还有配套的爬虫管理系统 ------ feaplat(暂时不支持 Apple 芯片),可以通过 docker 安装部署:
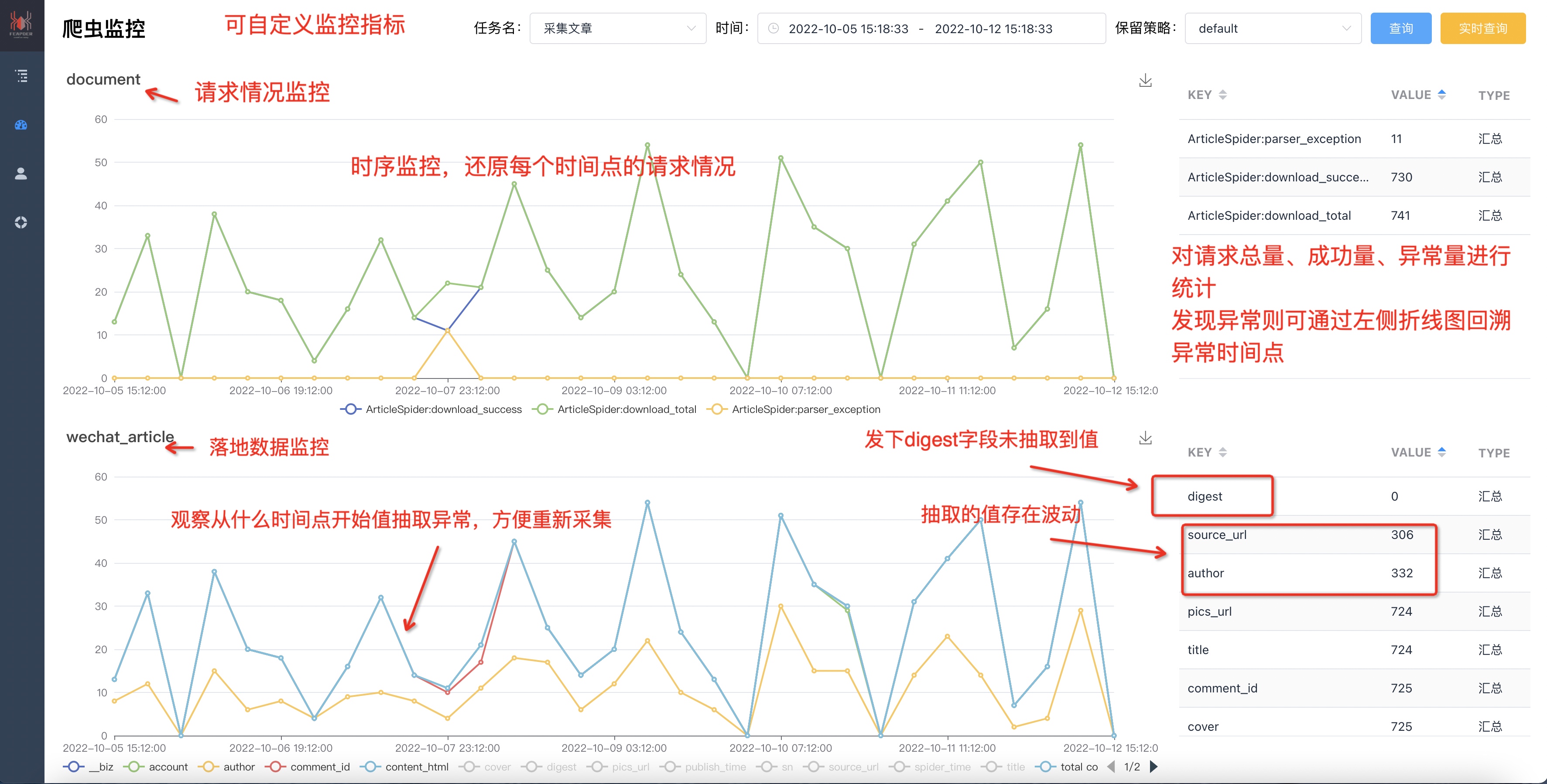
feapder 内置监控打点(feapder 版本大于等于 1.6.6),部署到 feaplat 爬虫管理系统即可实现对请求和数据监控:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号