cs152 hw1
problem1
How many bytes is the program? For the above x86 assembly code, how many bytes of instructions
need to be fetched if x = 0x01020304 and n = 5? Assuming 32-bit data values, how many
bytes of data memory need to be loaded? Stored?
the program is 7x2+1 bytes;
becasue n = 5, so the loop structure will executed entirely for 5 times, plus one test instruction and one jz instruction. therefore, 5 * 15 + 4 bytes need to be fetched;
0 bytes of data memory need to be loaded or stored.
problem 1.B

1. loop |
2. | beq x2, x0, done
3.
4. | srli x3, x1, 31
5. | slli x1, x1, 1
6. | or x1, x1, x3
7. | addi x2, x2, -1
8. | jal x0, loop
9. done |
how many bytes is the riscv program using your direct translation?
4B for each inst, so there is 4Bx6=24B
how many bytes of riscv insts need to be fecthed for x = 0x01020304 n = 5 with your translation?
5 times loop plus one beq inst, 5 x 24B + 4B = 124B
how many bytes of data mem need to be loaded or store?
0 B
problem 1.C
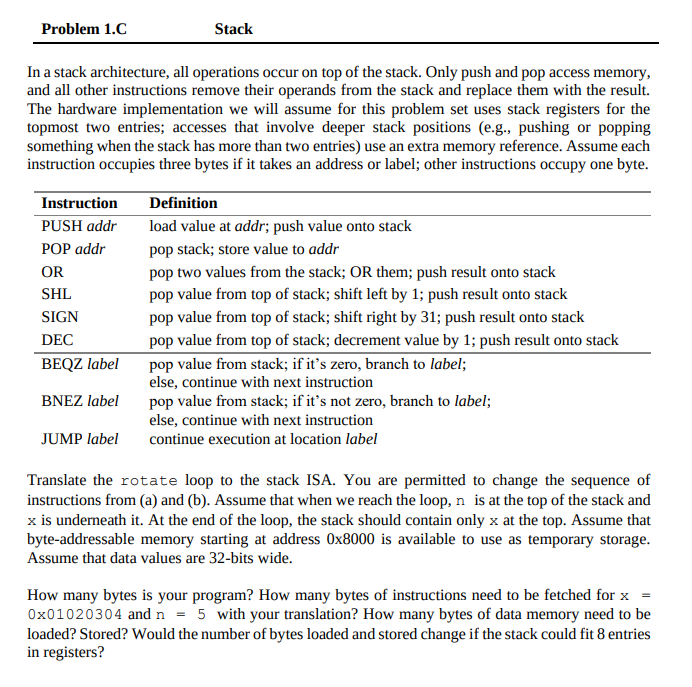
translation to stack ISA.
[bottom] -> [top]: x,n;
loop:
// x,n
POP 0x8000 // 3B
// x
PUSH 0X8000 // 3B
// x,n
BEQZ done // 3B
// x
POP 0X8004 // 3B
// []
PUSH 0X8004 // 3B
// x
SIGN // x >> 31 then push to stack // 1B
// x>>31
PUSH 0X8004 // 3B
// x>>31, x
SHL // x << 1 then push to stack // 1B
// x>>31, x<<1
OR // 1B
// x>> 31 | x<<1
PUSH 0X8000 // 3B
// x>>31|x<<1, n
DEC // 1B
// x>>31|x<<1, n-1
JUMP loop // 3B
done:
how many bytes is your program?
28B
how many bytes of inst need to be fetched ...?
5x28+9B=149B
how many bytes of data mem need to be loaded/stored?
PUSH(load) 4B for 4times each loop, one PUSH for final loop. => 4Bx4x5+4B= 84B
POP(store) 4B for 2times each loop, one POP for final loop. => 4Bx2x5+4B = 44B
if stack could fit 8 entries to regsiter, would number of B loaded and stored?
yes. i think number of B changes to 0
problem 1.D
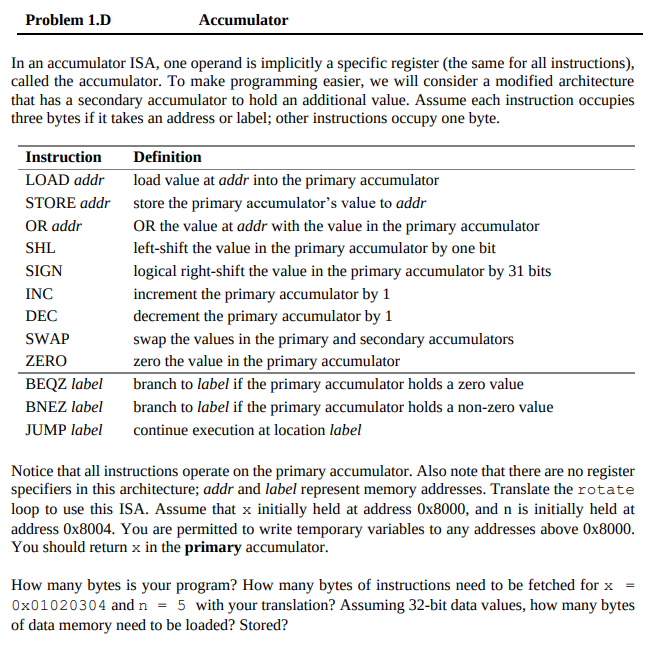
LOAD 0x8000 // 3B
SWAP // 1B
LOAD 0x8004 // save n into prim, 3B
loop:
BEQZ done // 3B
DEC // 1B
SWAP // save n into second , 1B
SIGN // x>>31, 1B
STORE 0x8008 // wb x>>31 to mem, 3B
LOAD 0X8000 // load x to prim, 3B
SHL // x << 1, 1B
OR 0X8008 // 3B
STORE 0X8000 // save new x, 3B
SWAP // load n into prim, new x into second, 1B
JUMP loop // 3B
done:
SWAP // 1B
- 8x3B + 7B = 31B
- 7B + 5x(3Bx6+5B) + 3B + 1B = 126B
- load = 4Bx(1+1+5x(2)) = 48B; store = 4Bx(5x(2))=40B
problem 2
problem 2.A
略
problem 2.B
略
problem 2.C

每条micro inst一个时钟周期
FETCH的时钟周期:3个

cycles count:
- 3+fetch = 6

- 3+fetch = 6

- 5 + fetch = 8

- x1==x2; 4 + fetch = 7

- x1 != x2; 3 + 4 + fetch = 10

- x1 != x2; 4 + fetch = 7

- x1 == x2; 3 + 4 + fetch = 10
- 6 + fetch = 9

- 6 + fetch = 9
- 6+ fetch = 9

- 4 + fetch = 7

problem 3
problem 3.A
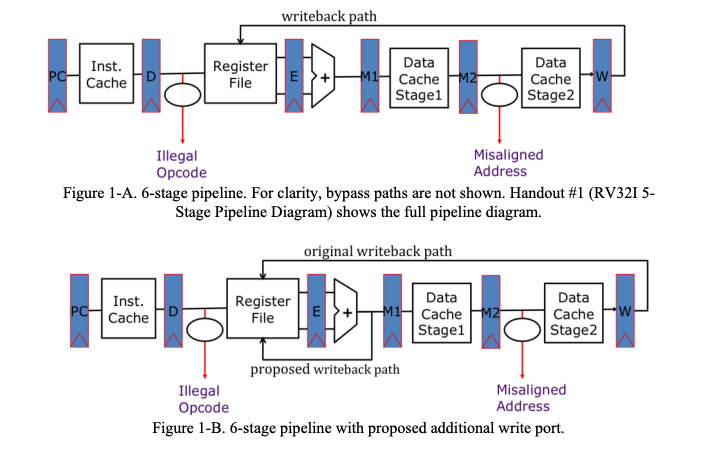
The second write port allows some bypass paths to be removed without adding stalls in the decode
stage. Explain how the second write port improves performance by eliminating such stalls and give
a short code sequence that would have required an interlock to execute correctly with only a single
write port and with the same bypass paths removed.
对于下面这种,second write port无法在不引入流水线停顿的情况下去掉bypass。因为,所提出的second write port就是图中从EX到ID的一个路径。但显然,如果在不引入流水线停顿的情况下,去掉bypass,只通过这个second write port解决x1的data hazard,是不可能的(时间顺序是逆向的)。如果希望在第二条指令的ID stage中,reg read时可以读到写完的值,需要在当前ID stage的write(前半个周期)就将值pass过来。

而对于下面这个情况:
在没有bypass的情况下,x1的值至少需要等到第一条指令的WB stage的后半个周期才可用(在doule pumping条件下)。因此,原先的第三条指令,需要一个流水线停顿后,从与第一条指令MEM stage相同的周期,开始IF,才能确保在double pumping条件下,ID的read可以读到第一条指令WB写回的正确x1。
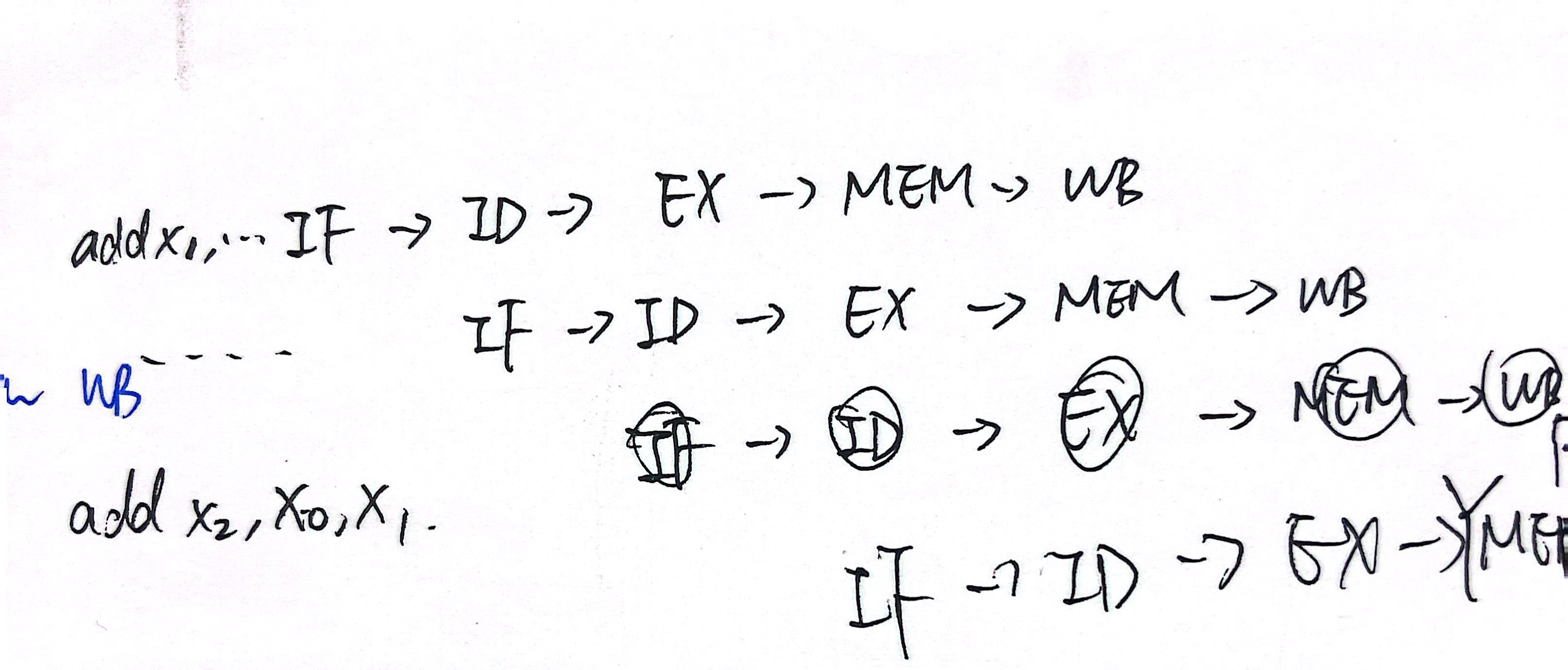
而当有了second write port后,就相当于建立一个bypass,从EX到EX/MEM流水线寄存器之间,或是EX结束后立即到ID stage的rising clock edge之前。
因此,有了second write port后,可以删掉bypass,并且不会引入stall
本文来自博客园,作者:ijpq,转载请注明原文链接:https://www.cnblogs.com/ijpq/p/17898805.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号