cs61c - proj3
proj3
objects
-
实现alu和regfile, cpu数据通路用于执行addi指令
-
实现一个完整的cpu
tips
- 只能使用logisim内建的元器件
✅ Wiring( ✖️Transistor/Transmission Gate/POR/Pull Resistor/Power/Ground/Do not connect)
✅Gates( ✖️ PLA )
✅Arithmetic( ✖️ Divider )
✅Memory( ✖️RAM/Random Generator )
✅Plexers
-
经常保存和commit logism
-
.circ文件很难merge,所以不要merge就好了!
-
不要移动locked input/output pins
-
检查cpu.circ的同时检查harness circ,确保电路和testing harness是适配的
-
不要新增.circ文件,电路图都应该画在已经给出的.circ中
-
命名要全局唯一,给定代码中的名称不要动
-
实现要高效,测试太久不行
-
写PartA前先完成lab05
-
写PartB前先完成lab06
常见logism错误
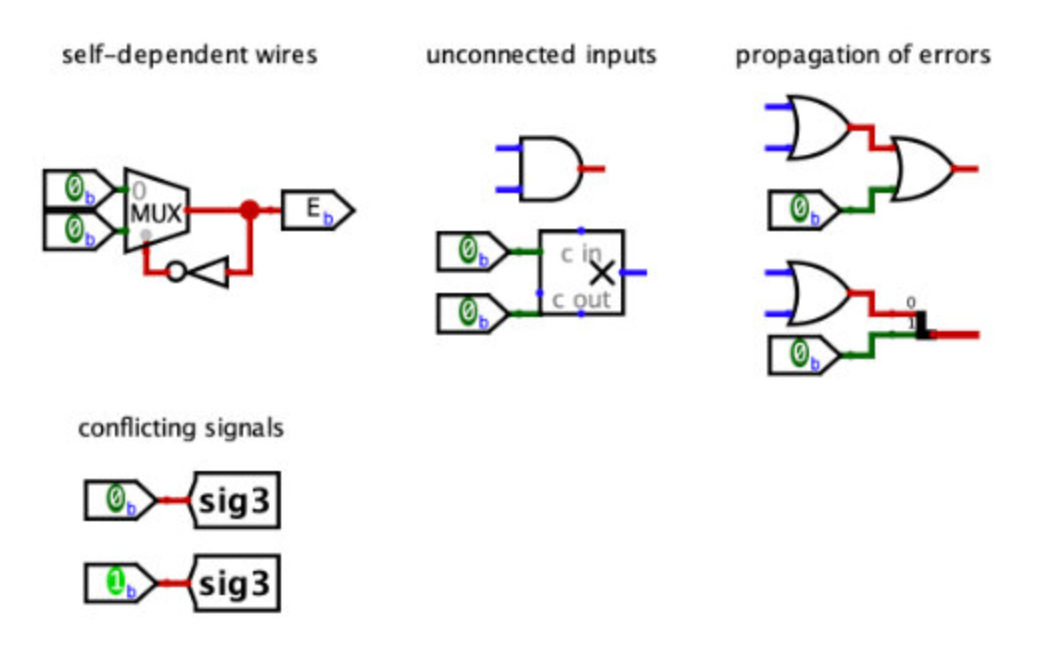
Part A
Task1 ALU
实现一个alu能够支持实验所需要运行的指令,不处理溢出。
在cpu/alu.circ中提供了一个alu的基本结构,三个输入和一个输出分别如下:
| Input Name | Bit Width | Description |
|---|---|---|
| A | 32 | Data to use for Input A in the ALU operation |
| B | 32 | Data to use for Input B in the ALU operation |
| ALUSel | 4 | Selects which operation the ALU should perform (see the list of operations with corresponding switch values below) |
| Output Name | Bit Width | Description |
|---|---|---|
| Result | 32 | Result of the ALU operation |
下面是需要实现的操作
| ALUSel Value | Instruction |
|---|---|
| 0 | add: Result = A + B |
| 1 | sll: Result = A << B |
| 2 | slt: Result = (A < B (signed)) ? 1 : 0 |
| 3 | Unused |
| 4 | xor: Result = A ^ B |
| 5 | srl: Result = (unsigned) A >> B |
| 6 | or: `Result = A |
| 7 | and: Result = A & B |
| 8 | mul: Result = (signed) (A * B)[31:0] |
| 9 | mulh: Result = (signed) (A * B)[63:32] |
| 10 | Unused |
| 11 | mulhu: Result = (A * B)[63:32] |
| 12 | sub: Result = A - B |
| 13 | sra: Result = (signed) A >> B |
| 14 | Unused |
| 15 | bsel: Result = B |
在PartA的测试中,只使用ALUSel值和指定的一些指令,所以暂时不需要考虑其他的问题
可以对alu.circ做一些修改,但是必须遵守以上描述的要求。如果创建子电路,必须也放在alu.circ中。alu的实现必须能够适配alu-harness.circ,这表示输入和输出都不要改,以免对应不上harness。为了保证所实现的内容的正确性,可以打开harness看一下是否有logisim的报错。
tips
- 实现移位操作的时候,注意使用splitter和extender
- 使用tunnel,可以让电路变得好看
- 当从多个输出中进行选择时,使用MUX。
info:testing
在tests/路径下提供了一些测试
例如alu的测试放在了tests/part-a/alu中,测试结果放在student-output/中。
进行alu测试:
python3 test.py tests/part-a/alu/
也可以进行单一测试:
python3 test.py tests/part-a/alu/alu-add.circ
python3 test.py tests/part-a/
python3 test.py tests/
alu的测试完以后,输出放在tests/part-a/alu/student-output/中,并且带有-student.out后缀。与之相应的参考输出放在tests/part-a/alu/reference-output/并且带有-ref.out后缀
format-output.py会接受一个输出文件的路径,把输出文件展示了可阅读的格式,例如 把alu-add测试打印出可阅读的格式,使用:
python3 tools/format-output.py tests/part-a/alu/reference-output/alu-add-ref.out
如果为了对比不同点,可以使用diff
inspecting tests
在logisim中可以使用类似gdb的功能
在logisim中打开tests/part-a/alu/alu-add.circ,有一些roms输入到Input_A,Input_B,ALUSel中,这些会输入到你的alu的右上角。每个时钟周期,左上角的加法器加一,将 ROM 的输出推进一个条目,并将一组新的输入提供给您的 ALU。
如果点击File -> Tick Full Cycle几次,可以看到测试电路接受了一个输入并产生了一些输出。
可以右键alu,点击view alu看一下你的alu电路,poke tool非常有用
Task2 register file
这一个任务是实现所有的riscv寄存器
register file要根据给定的riscv指令对register进行读写,但是x0永远不要写。
时钟信号要直接连接register file
| Register Number | Register Name |
|---|---|
| x1 | ra |
| x2 | sp |
| x5 | t0 |
| x6 | t1 |
| x7 | t2 |
| x8 | s0 |
| x9 | s1 |
| x10 | a0 |
| Input Name | Bit Width | Description |
|---|---|---|
| Clock | 1 | Input providing the clock. This signal can be sent into subcircuits or attached directly to the clock inputs of memory units in Logisim, but should not otherwise be gated (i.e., do not invert it, do not AND it with anything, etc.). |
| RegWEn | 1 | Determines whether data is written to the register file on the next rising edge of the clock. |
| rs1 (Source Register 1) | 5 | Determines which register’s value is sent to the Read_Data_1 output, see below. |
| rs2 (Source Register 2) | 5 | Determines which register’s value is sent to the Read_Data_2 output, see below. |
| rd (Destination Register) | 5 | Determines which register to write the value of Write Data to on the next rising edge of the clock, assuming that RegWEn is a 1. |
| wb (Write Data) | 32 | Determines what data to write to the register identified by the Destination Register input on the next rising edge of the clock, assuming that RegWEn is 1. |
| Output Name | Bit Width | Description |
|---|---|---|
| Read_Data_1 | 32 | Driven with the value of the register identified by the Source Register 1 input. |
| Read_Data_2 | 32 | Driven with the value of the register identified by the Source Register 2 input. |
ra Value |
32 | Always driven with the value of ra (This is a DEBUG/TEST output.) |
sp Value |
32 | Always driven with the value of sp (This is a DEBUG/TEST output.) |
t0 Value |
32 | Always driven with the value of t0 (This is a DEBUG/TEST output.) |
t1 Value |
32 | Always driven with the value of t1 (This is a DEBUG/TEST output.) |
t2 Value |
32 | Always driven with the value of t2 (This is a DEBUG/TEST output.) |
s0 Value |
32 | Always driven with the value of s0 (This is a DEBUG/TEST output.) |
s1 Value |
32 | Always driven with the value of s1 (This is a DEBUG/TEST output.) |
a0 Value |
32 | Always driven with the value of a0 (This is a DEBUG/TEST output.) |
在regfile.circ顶部的test output是用来测试和debug的,实现真实register file时要忽略这些输出。不过,在本作业内,要包含这些输出,否则测试不能通过。
tips
- 使用复制粘贴来节省工作量
- MUXes很有用,DeMUXes也用得上
- 建议不要使用MUXes的
Enable信号线,建议把Enable和Three state关掉 - 想一下,在一条指令执行完后,register file会发生什么,值会变成什么,哪些值保持不变,寄存器是时钟触发的这意味着什么?
testing
python3 test.py tests/part-a/regfile/
task3 the addi instruction
info:memory
mem.circ已经包含了实现好的内存单元,并且已经适配好了cpu-harness.circ
addi指令不使用memory,所以目前为止,可以忽略DMEM和I/O pins
memory单元的输入输出表如下
| Signal Name | Direction | Bit Width | Description |
|---|---|---|---|
| WriteAddr | Input | 32 | Address to read/write to in Memory |
| WriteData | Input | 32 | Value to be written to Memory |
| Write_En | Input | 4 | The write mask for instructions that write to Memory and zero otherwise |
| CLK | Input | 1 | Driven by the clock input to the CPU |
| ReadData | Output | 32 | Value of the data stored at the specified address |
info: branch comparator
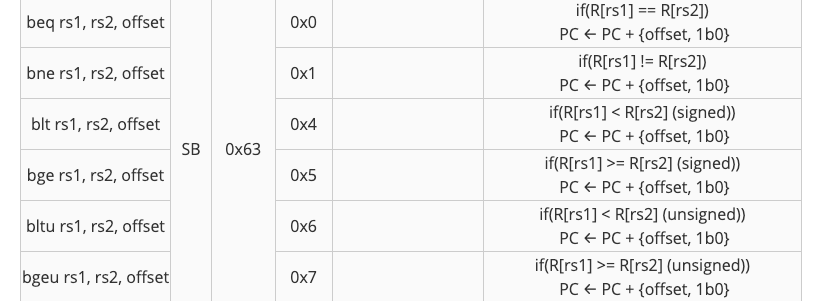
分支单元放在了branch-comp.circ,但是没有实现完,addi指令不需要使用分支单元,所以可以暂时不管她
branch单元的输入输出表如下
| Signal Name | Direction | Bit Width | Description |
|---|---|---|---|
| rs1 | Input | 32 | Value in the first register to be compared |
| rs2 | Input | 32 | Value in the second register to be compared |
| BrUn | Input | 1 | Equal to one when an unsigned comparison is wanted, or zero when a signed comparison is wanted |
| BrEq | Output | 1 | Equal to one if the two values are equal |
| BrLt | Output | 1 | Equal to one if the value in rs1 is less than the value in rs2 |
info: immediate generator
立即数生成单元放在了imm-gen.circ,没有实现,addi指令需要使用这个单元。对于目前的part来说,可以hard-wire来给addi指令生成立即数
编辑了imm-gen.circ以后,需要重新打开cpu.circ以加载所做的修改
| Signal Name | Direction | Bit Width | Description |
|---|---|---|---|
| inst | Input | 32 | The instruction being executed |
| ImmSel | Input | 3 | Value determining how to reconstruct the immediate |
| imm | Output | 32 | Value of the immediate in the instruction |
info: processor
在partA,需要实现一个单指令周期(非流水线)且支持addi指令的数据通路。在partB,将会实现两级流水线。
进程会输出指令的地址,然后接受这个地址的指令作为输入。同时,要输出data mem address,data mem write enable,接受这个地址的数据作为输入。
仔细看一下run.circ和cpu-harness.circ,了解一下整个过程是怎么回事。
处理器接受三个输入,这三个输入来自harness
| Input Name | Bit Width | Description |
|---|---|---|
| READ_DATA | 32 | Driven with the data at the data memory address identified by the WRITE_ADDRESS (see below). |
| INSTRUCTION | 32 | Driven with the instruction at the instruction memory address identified by the FETCH_ADDRESS (see below). |
| CLOCK | 1 | The input for the clock. As with the register file, this can be sent into subcircuits (e.g. the CLK input for your register file) or attached directly to the clock inputs of memory units in Logisim, but should not otherwise be gated (i.e., do not invert it, do not AND it with anything, etc.). |
处理器要给出以下输出
| Output Name | Bit Width | Description |
|---|---|---|
| ra | 32 | Driven with the contents of ra (FOR TESTING) |
| sp | 32 | Driven with the contents of sp (FOR TESTING) |
| t0 | 32 | Driven with the contents of t0 (FOR TESTING) |
| t1 | 32 | Driven with the contents of t1 (FOR TESTING) |
| t2 | 32 | Driven with the contents of t2 (FOR TESTING) |
| s0 | 32 | Driven with the contents of s0 (FOR TESTING) |
| s1 | 32 | Driven with the contents of s1 (FOR TESTING) |
| a0 | 32 | Driven with the contents of a0 (FOR TESTING) |
| tohost | 32 | Driven with the contents of CSR 0x51E (FOR TESTING, for Part A leave it as-is) |
| WRITE_ADDRESS | 32 | This output is used to select which address to read/write data from in data memory. |
| WRITE_DATA | 32 | This output is used to provide write data to data memory. |
| WRITE_ENABLE | 4 | This output is used to provide the write enable mask to data memory. |
| PROGRAM_COUNTER | 32 | This output is used to select which instruction is presented to the processor on the INSTRUCTION input. |
info:Control Logic
control-logic.circ还没有实现,这个内容的实现是partB中最难的
对于partA,可以为每一个控制信号设置一个常数,因为partA只要实现addi指令,对应的控制信号是固定的
在这个文件中可以增加更多的input/output pin,以实现控制逻辑
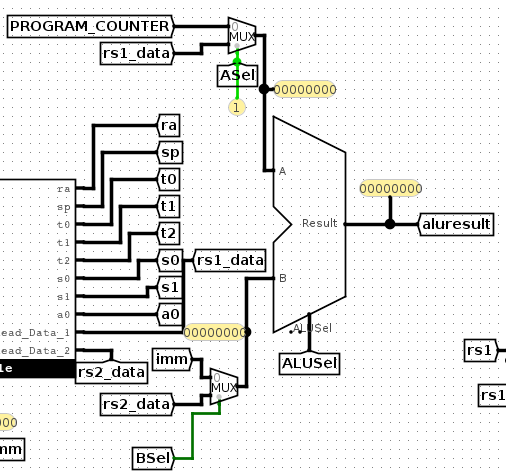
单级CPU: A Guide
回顾一下cpu的五个stage,下面每个stage提出一些问题,能够帮助理解问题!
Stage1: IF
主要的问题是,我们如何取得当前的指令?根据教材,指令是从指令内存中取出来的,每一条指令可以根据给定的内存地址来获取
-
哪一个.circ包含了指令内存?如何连接到cpu.circ?
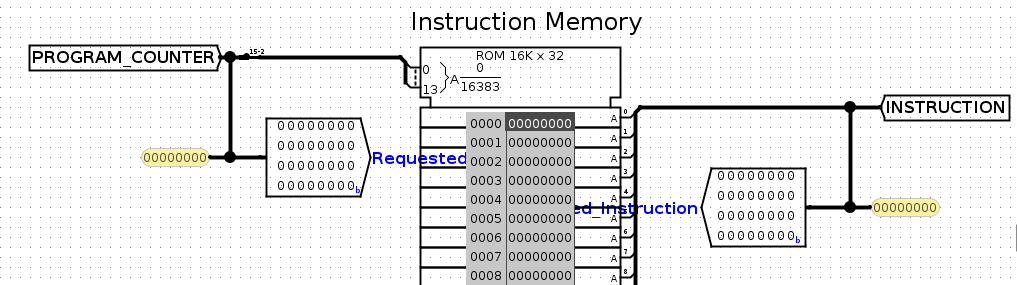
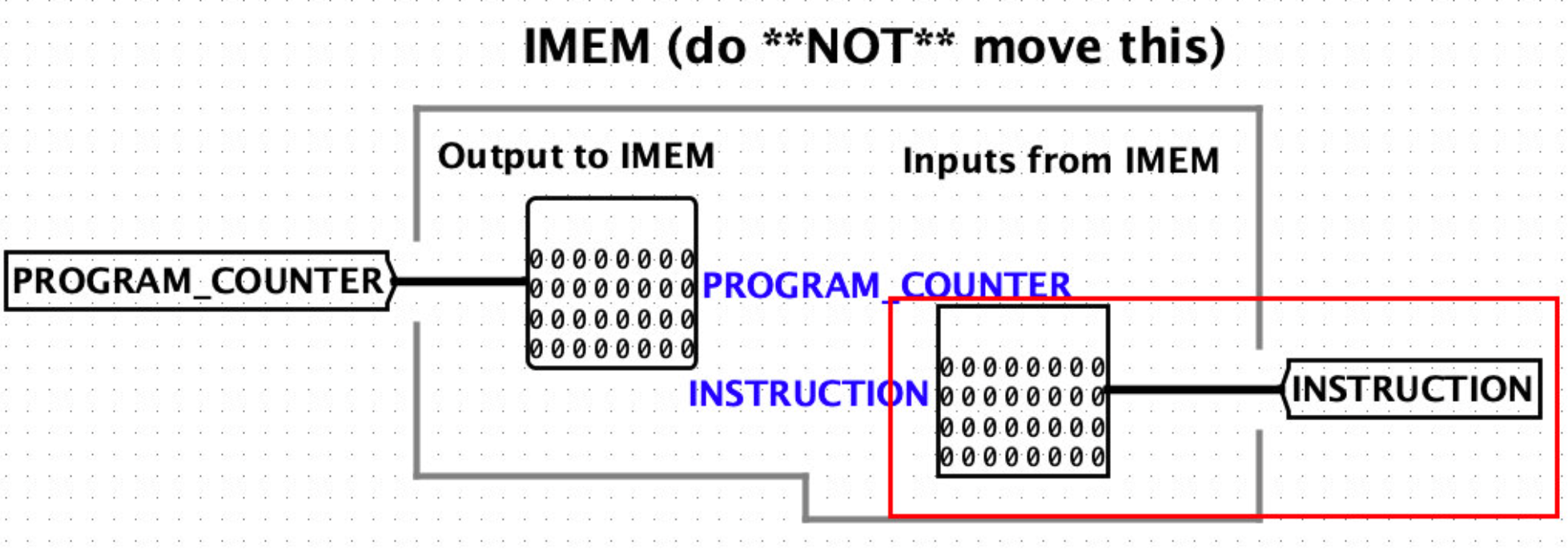
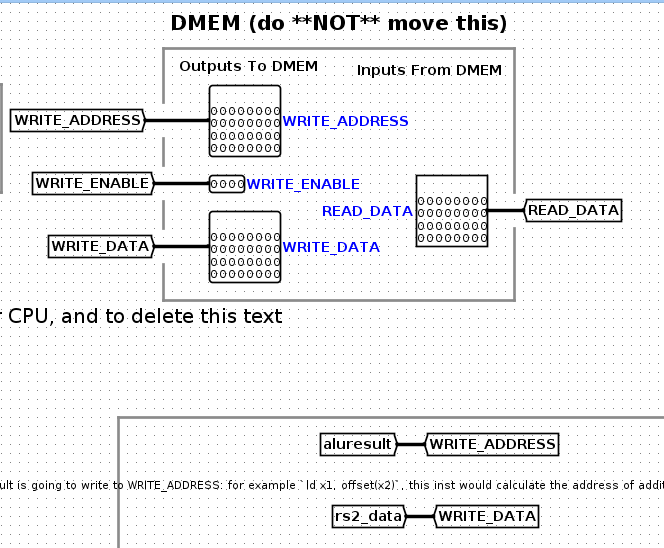
INSTRUCTION MEMORY在run.circ中,把PROGRAM_COUNTER输入到INSTRUCTION MEMORY,并且输出到INSTRCUTION中
如下图所示
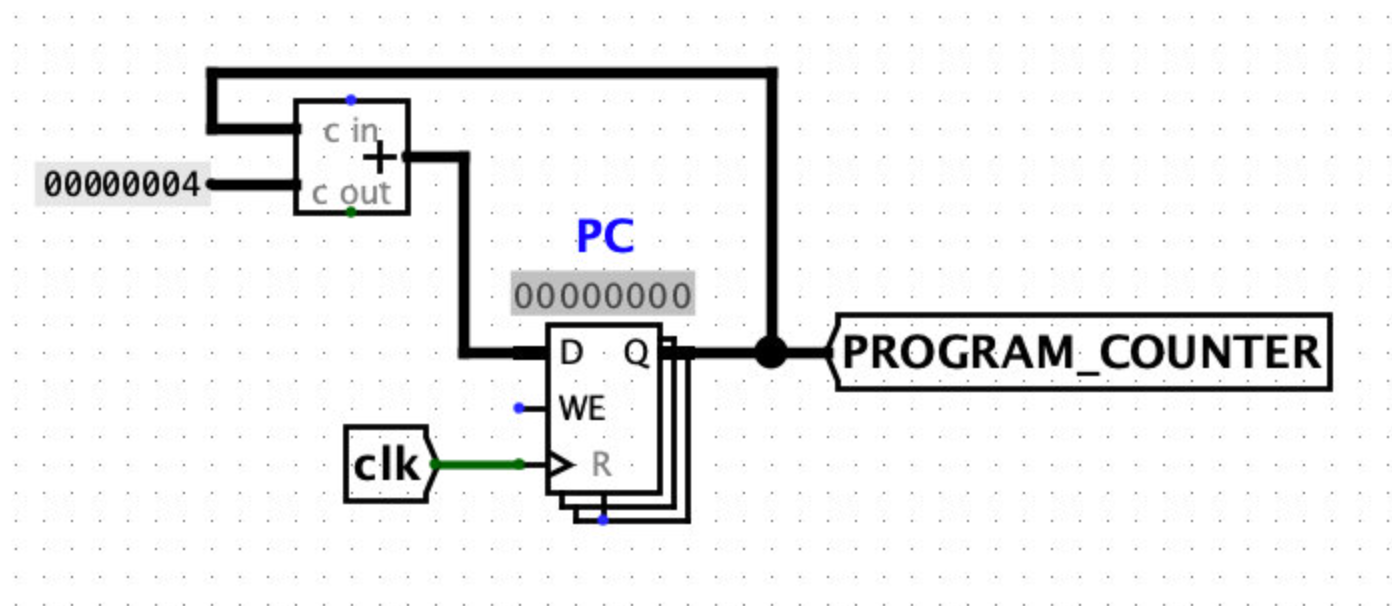
PC的计算过程:
输出PROGRAM_COUNTER到tunnel
PROGRAM_COUNTER输出到INSTRUCTION MEMORY。当然这里并没有真的输入到instruction mem,只是展示了pc的值。pc的值会保存在tunnel中。
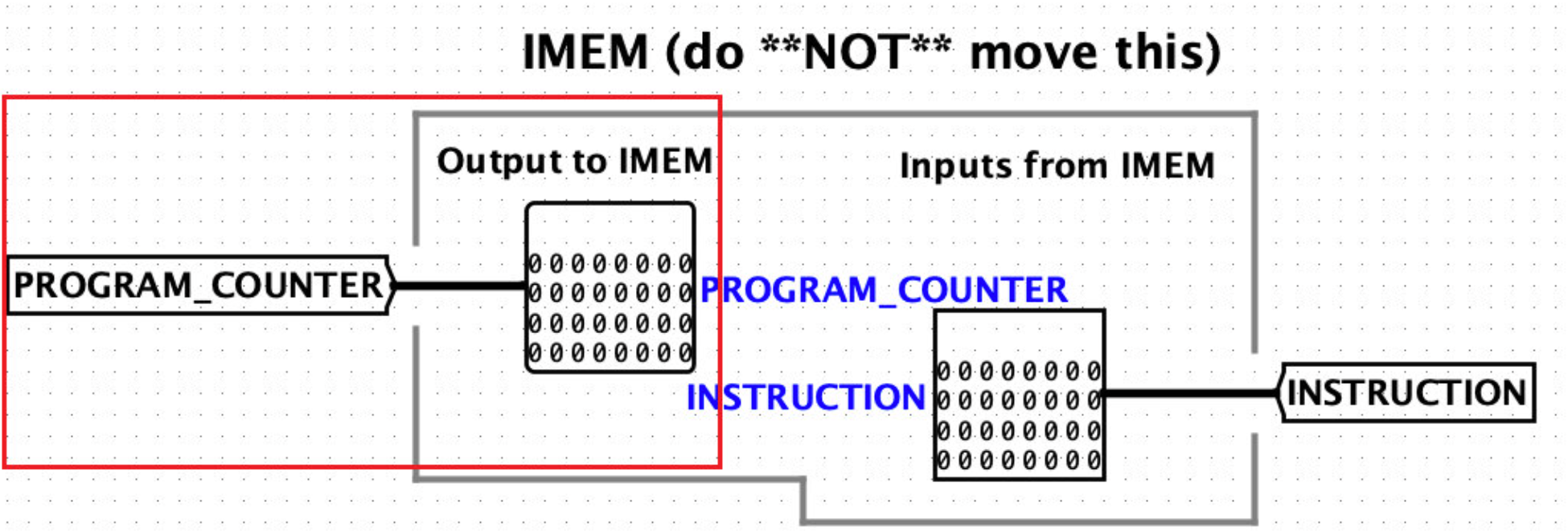
INSTRUCTION MEMORY输出INSTRUCTION到cpu。这里只是展示instruction的值
-
在这个cpu中,更改了pc后,是如何影响指令输入的?
更改pc后,从
INSTRUCTION MEMORY取出不同的指令给cpu -
你怎么知道pc应该是什么值
答案:PROGRAM_COUNTERis the address of the current instruction being executed, so it is saved in the PC register. For this project, your PC will start at 0, as that is the default value for a register. -
对于没有跳转和条件指令的程序,执行过程中pc是如何变化的
直接+4
Stage2: Instruction Decode
现在有了从instruction得到的指令输入,我们把这个指令按照riscv指令格式对其进行解码。
addi指令的类型是什么?这种指令的位域是什么样的?每个位域的bit是什么?
I type. The fields are: -imm [31-20]-rs1 [19-15]-funct3 [14-12]-rd [11-7]-opcode [6-0]- 在logisim中,使用什么工具来把这些位域拆分开?
The Splitter! - 使用这个instruction作为输入,将指令进行解码。应该用到tunnel,然后把位域进行分组。
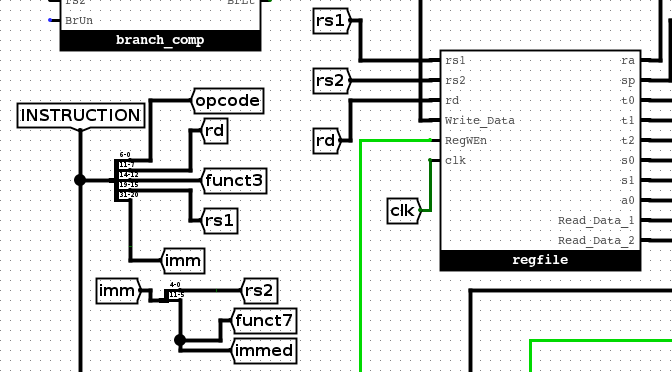
这个分组格式主要考虑I型和R型。
- 现在我们需要从regfile中相应的寄存器中获取数据,指令中哪一个位域要链接到regfile?链接到regfile中的哪个位置?
Instruction field rs1 will need to connect to read register 1.
I型指令是没有rs2的,所以当前在regfile的rs2应该是不需要链接的。
-
实现从regfile中读取数据的功能。你需要从partA中找到regfile,记得链接上clk
-
imm-gen需要做什么?
对于addi,即时生成器从指令中输入12位,并产生一个有符号的32位即时。你需要在立即生成器子电路中实现这个逻辑!
Stage3: execute
指令执行阶段是很多指令计算真正执行的阶段。在这个阶段介绍控制模块的思想。
- 对于
add指令,ALU的输入是什么?
Read Data 1 (rs1) and the immediate produced by the Immediate Generator. - 在
ALU中,ALUSel的作用是什么?
It determines which operation the ALU will perform.见task1中alu的说明 - 尽管目前可以只给
ALUSel赋值一个常量,但为什么这会对实现更多的指令造成阻碍?
With more instructions, the input to the ALU might need to change, so you will need to have some sort of circuit that changes ALUSel depending on the instruction being executed. - 把ALU链接好,ALU是否需要链接clk?说明原因。
应该是不需要的,alu直接根据设置的alusel信号选择执行的计算电路就行了
Stage4: memory
内存阶段是内存可以被存储指令操作写入、读取指令的阶段。因为addi指令不需要使用内存,目前在内存阶段还不需要花太多时间。目前还不需要给mem接线。
Stage5: write back
(因为目前addi指令不需要mem,所以写到这里时没有增加mem的信号写回到regfile的操作,而是直接将alu的计算结果链接到了regfile)
写回阶段是操作的结果存储到寄存器的阶段。
addi指令的结果是否需要写回到寄存器?
Yes.additakes the output of a an addition computation in the ALU and writes it back to the register file.- 在写回阶段,可以把
ALU和MEM的结果输出到regfile。之后当需要实现分支/跳转时,可以想mux元件增加更多的内容。那时,我们需要在ALU和MEM的输出之间做选择,他们之中只有一根线可以作为regfile的输入。把ALU和READ_DATA的线连接到MUX上。 mux元件上的选择信号应该用什么作为输入?这个输入依赖什么计算?
This input should be able to choose between three MUX inputs: (1) ALU, (2) MEM [READ_DATA], and (3) PC + 4 (when will you use this?) The control signal that determines which of these inputs is written back is called WBSel. For now, there should only be one value that WBSel can take on -- whatever it should be foraddi.- 现在我们已经理清了MUX的输入,我们需要为输出布线。输出应该连接到哪里?
Because the output is the data that you want to write into the Register File, it should connect to the Write Data input on the Register File. - 在regfile上还有两个输入端,对写入数据很重要:RegWEn和rd。其中一个来自指令解码阶段,另一个是你需要为part B设计的新的控制信号,请通过RegFile上的这些输入正确完成回写阶段。
info: cpu testing
在本测试部分,我们了解了测试的一般文件夹结构,并理解了运行测试和解释输出时涉及的命令。现在,让我们深入了解一下CPU测试,你将在项目的剩余时间里与之打交道。
understanding cpu tests
每个CPU测试都是包含在启动代码中的run.circ文件的副本,该文件将指令加载到其IMEM中。当你从命令行运行Logisim时,时钟滴答作响,程序计数器递增,每个输出中的值被打印到stdout。
让我们以单周期的cpu-addi-basic理智测试为例。它有4条addi指令(见test/part-a/addi/cpu-addi-basic.s)。在Logisim中打开test/part-a/addi/cpu-addi-basic.circ,仔细看一下测试文件的各个部分。在顶部,你会看到你的CPU连接到测试输出的地方。在启动代码中,你会看到很多UUU或XXXX;当你的CPU工作时,不应该出现这种情况。你的CPU接受一个输入(INSTRUCTION),连同每个寄存器中的值,它有一个额外的输出:PROGRAM_COUNTER,或从IMEM获取的指令地址,以便在下一个时钟周期执行。
正如你所看到的,有许多特定位置的导线连接到CPU的特定输入/输出引脚上。请确保你不要编辑所提供的输入/输出引脚或添加新的引脚,因为这将改变CPU电路的形状,结果是测试文件中的连接可能不再正常工作。
在CPU的下面,你会看到指令存储器。用于addi指令的hex已经被加载到指令存储器中。指令存储器接受一个输入(称为PROGRAM_COUNTER)并在该地址输出指令。PROGRAM_COUNTER是一个32位的值,但是由于Logisim将ROM单元的大小限定为2^16字节,我们必须使用一个分割器来从PROGRAM_COUNTER中只获得14位(忽略最下面的两位)。请注意,PROGRAM_COUNTER是一个字节地址,而不是一个字地址。
那么,当时钟跳动时,会发生什么?时钟的每一次滴答都会增加测试文件中一个叫做Time_Step的输入。时钟将继续滴答,直到Time_Step等于该测试文件的停止常数(对于这个特定的测试文件,停止常数是5)。在这一点上,Logisim命令行将把每个输出中的值打印到stdout。我们的测试将把这个输出与预期的进行比较;如果你的输出不同,你的测试将失败。
addi tests(part A)
我们在test/part-a/addi/目录中为addi(任务3)提供了一些合理性测试。你可以用以下方法运行这些测试:
$ python3 test.py tests/part-a/addi/
关于使用这些测试的更多信息,见上文。
task 3.5 Part A README Update
你在A部分的最后一项任务是填写README.md。写下你是如何实现这部分的电路和元件的(包括ALU和RegFile,因为你把它们用于addi!),并解释你的设计选择背后的原因。这里没有特定的格式或长度要求,所以请自由发挥创造力吧!
part A: submission
在这一点上,如果你已经完成了任务1-3.5,你就完成了项目的A部分!
A部分的autograder使用的测试与启动代码中提供的测试文件相同。换句话说,A部分没有隐藏的测试。
对于addi测试,autograder接受单周期或流水线的CPU。这是为在B部分开始工作,对CPU进行流水线处理,然后意识到你想重新提交到A部分的情况。
仔细检查你是否没有编辑你的输入/输出引脚,以及你的电路是否适合所提供的测试线束。确保你没有创建任何额外的.circ文件;自动测试器将只测试你在A部分被允许编辑的电路文件(alu.circ, branch-comp.circ, control-logic.circ, cpu.circ, imm-gen.circ, and regfile.circ)。然后,将你的Repo提交给Gradescope上的项目3A任务。
本规范的其余部分描述了B部分的任务。
Part B
Task4 : more instructions
在任务3中,你连接了一个能够执行addi指令的基本单周期CPU。现在,你要实现对更多指令的支持!
你的CPU最终会有很多部分--试着把它分解成几块,先从简单的部分开始。你如何处理这项任务完全取决于你,但建议的开始顺序是:branch compare和imm-gen(比 control logic/datapath 简单),然后是I型计算指令(因为你已经实现了addi),然后是R型计算指令(因为与I型计算指令有一些重叠),依此类推。
我们强烈建议你同时进行任务4和任务5(自定义测试),因为增量测试将帮助你更快地捕捉到错误。为你计划实现的指令(或指令组)编写测试,然后以你的测试为参考,实现指令。一旦你的测试通过了,就提交你的修改,这样你就可以在以后发现回归时再回来,然后继续执行另一条指令。
ISA
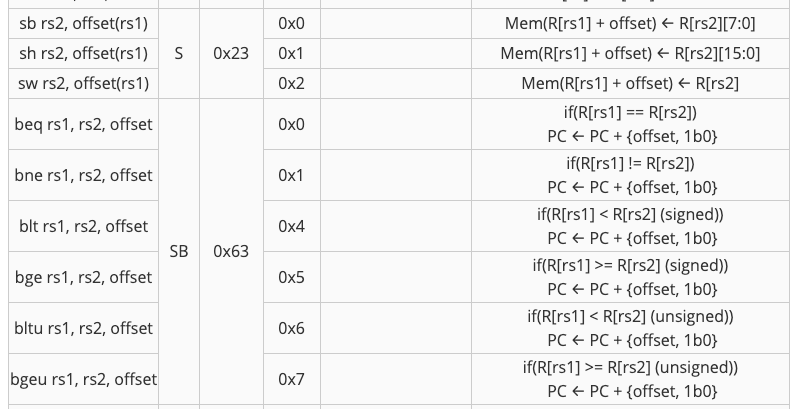
此proj只会测试下表中所列出的指令。
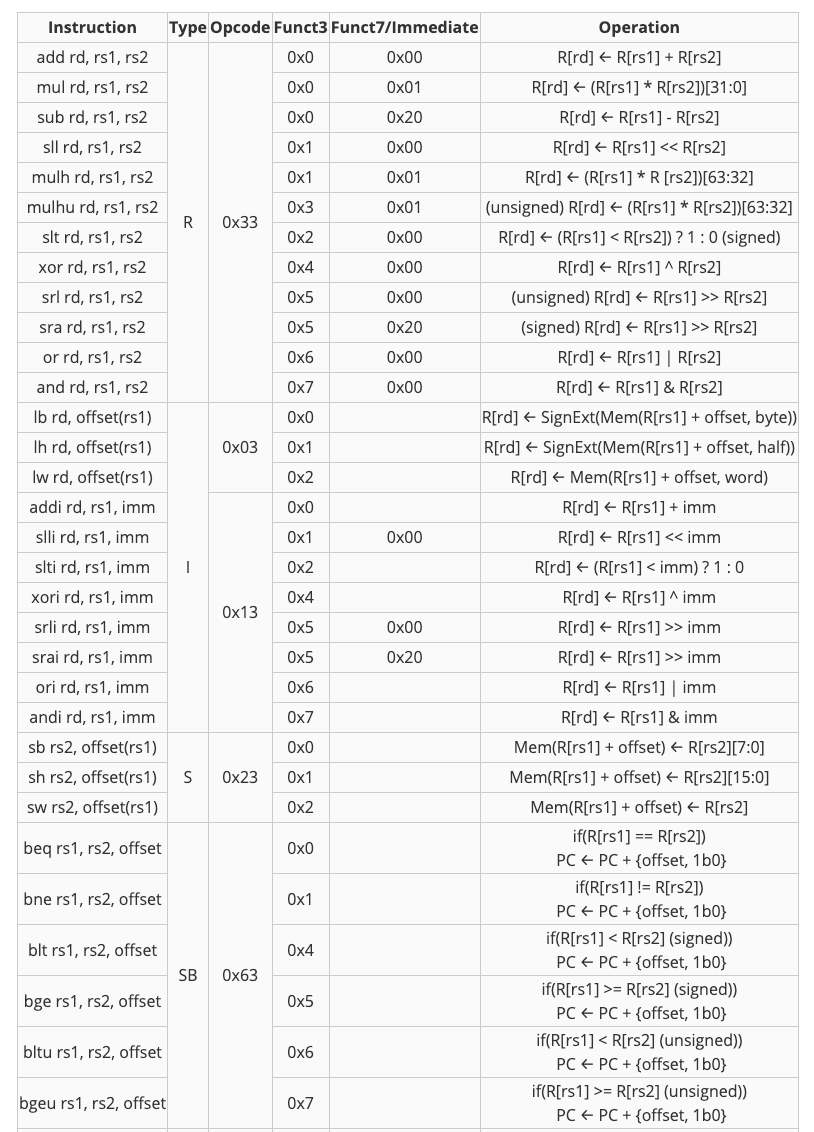
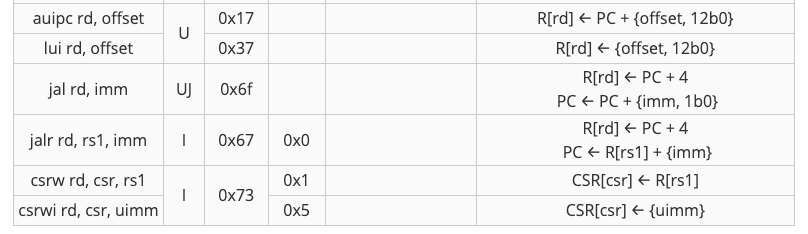
Info: Branch Comparator
分支比较器单元(位于 branch-comp.circ 中)比较两个值,并输出控制信号,这些信号将被用来做分支决策。你将需要为这个电路实现逻辑。
要编辑这个子电路,请编辑 branch-comp.circ 文件,而不是 cpu.circ 中的 branch_comp。注意,如果你修改了这个电路,你将需要关闭并重新打开cpu.circ,以便在你的CPU中加载这些变化。
同样,这里有一个关于其输入和输出的快速总结:

Info: Immediate Generator
即时生成器("Imm Gen")单元(位于imm-gen.circ中)从I、S、B、U和J类型的指令中提取适当的imm。请记住,在RISC-V中,所有imm-gen中生成的imm都是32位的,并且是符号扩展的!请看下表,了解每个imm信息应该如何格式化:

我们没有指定ImmSel的编码(也就是说,想出你自己的编码!),但要确保你的imm-gen和控制逻辑对ImmSel使用相同的值。
要编辑这个子电路,请编辑imm-gen.circ文件而不是cpu.circ中的imm_gen。注意,如果你修改了这个电路,你将需要关闭并打开cpu.circ,以便在你的CPU中加载这些变化。
同样,这里是对其输入和输出的一个快速总结:

Info: Control Logic
骨架中提供的控制逻辑单元(control-logic.circ)是基于讲课和讨论中使用的5级CPU中的控制逻辑单元。为了正确识别每条指令,控制信号在这个项目中起着非常重要的作用。然而,弄清所有的控制信号可能看起来很吓人。我们建议看一下讲座的幻灯片和讨论的工作表来开始学习。试着用不同类型的指令走一遍数据通路;当你看到一个MUX或其他组件时,想想该指令需要什么选择器/使能值。
我们欢迎你根据你的控制逻辑的需要在现有的启动器控制_逻辑电路上增加更多的输入或输出。你也可以根据需要使用所提供的端口中的任意数量或任意数量。也就是说,在这个过程中,请不要编辑、移动或删除任何现有的端口。
有两种主要的方法来实现控制逻辑,以便它能从指令中提取opcode/funct3/funct7并适当地设置控制信号。
推荐的方法是硬接线控制,正如讲座中所讨论的,这通常是MIPS和RISC-V等RISC架构的首选方法。硬接线控制使用各种门和其他组件(记住,我们已经学习了如何从AND/OR/NOT门中建立MUX等组件)来产生适当的控制信号。一个指令解码器接收一条指令并输出该指令的所有控制信号。
另一种方法是使用ROM控制。处理器执行的每条指令都映射到只读存储器(ROM)单元中的一个地址。在ROM中的这个地址是该指令的控制字。一个地址解码器接收一条指令并输出该指令的控制字的地址。这种方法在英特尔的x86-64等CISC架构中很常见,而且在现实生活中提供了一些灵活性,因为它可以通过改变ROM的内容来重新编程。
要编辑这个子电路,请编辑 control-logic.circ 文件,而不是 cpu.circ 中的 control_logic。注意,如果你修改了这个电路,你将需要关闭并打开cpu.circ以在你的CPU中加载这些变化。
提示
如果你是一个喜欢用电子表格的人,电子表格可能会帮助你组织你的控制逻辑!
硬接线控制:对于像ALUSel这样的信号,你可能想根据多个潜在的输入信号来输出某个数字,一个优先级编码器可能会有帮助!
Info: Memory
内存单元(位于mem.circ中)已经为你完全实现了,并且在cpu-harness.circ中连接到了你的CPU的输出端你不能将mem.circ添加到你的CPU中;这样做将导致自动分析器失败,你将不会得到分数。
由于Logisim的限制,只有内存地址的低16位被使用,而高16位被丢弃。因此,本项目中的内存(IMEM和DMEM)的有效地址空间为2^16字节地址。
虽然你给内存的地址是一个字节地址,但内存单元返回的是整个字。存储器单元忽略了你提供给它的地址的底部2位,并将其输入视为字地址而不是字节地址。例如,如果你输入32位地址0x0000_1007,它将被视为字地址0x0000_1004,而输出将是地址为0x0000_1004、0x0000_1005、0x0000_1006和0x0000_1007的4个字节。
注意,对于lh、lw、sh、sw指令,RISC-V ISA支持无对齐访问,但实现它们是很复杂的。在这个项目中,我们将只实现对齐的内存访问。这意味着只有当操作不超过内存中一个连续字的边界时才会被定义。一个例子是任何对4的倍数的地址进行操作的lw或sw,由于地址是4的倍数,我们在一个字中加载了4个字节,所以获取的内存总量没有超过内存中一个连续字的边界。你不能实现无符号访问;你很可能需要使用停顿,这将导致你的输出与我们的预期输出不一致(对你的分数不利)。
记住,内存也是字节级的写入功能。这意味着Write_En信号是4位宽的,作为输入数据的写掩码(即掩码的每一位都能写到字的相应字节)。一些例子(W = 字节将被覆盖,空白 = 字节不受影响):
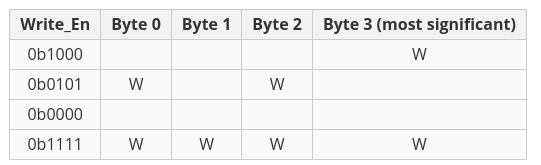
无论Write_En如何,ReadData端口都会返回所提供地址的内存中的值。
同样,这里是对其输入和输出的快速总结:

Info: Control Status Registers (CSRs)
为了运行决定你项目等级的测试平台,还需要增加一些指令。控制状态寄存器(CSR)持有关于机器指令结果的额外信息,它通常独立于寄存器文件和存储器而被存储。在你的处理器中,你将向其中一个CSR写入输出,这些输出将被更复杂的测试平台所监控。
下面是你需要实现的2条CSR指令。注意,虽然有2^12个可能的CSR地址,但我们只希望其中一个能工作(tohost = 0x51E)。对其他CSR地址的写入不应该影响到tohost的CSR。
csrw tohost, rs1 (简称csrrw x0, csr, rs1,其中csr=tohost=0x51E)
csrwi tohost, uimm (简称csrrwi x0, csr, uimm where csr=tohost=0x51E)
这些指令的指令格式如下:

请注意,即时形式使用在rs1字段中编码的5位零扩展即时(uimm)。
控制状态寄存器单元(位于csr.circ中)已经为你完全实现了!请不要编辑电路中的任何东西,包括输入/输出引脚或自动增益测试!请不要编辑电路中的任何东西,包括输入/输出引脚,否则自动编程器的测试可能失败。
如果你想了解更多关于CSR的信息,你可以参考RISC-V规范的第九章。
下面是它的输入和输出的一个快速总结:
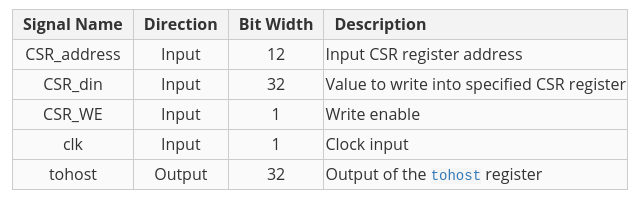
Info: Processor
主CPU电路(位于cpu.circ)实现了主数据通路,并将所有的子电路(ALU、分支比较器、控制逻辑、控制状态寄存器、即时生成器、存储器和RegFile)连接在一起。在完成这项任务后,你的CPU应该是利用了所有这些组件。
作为复习,这里是对其输入和输出的一个快速总结:
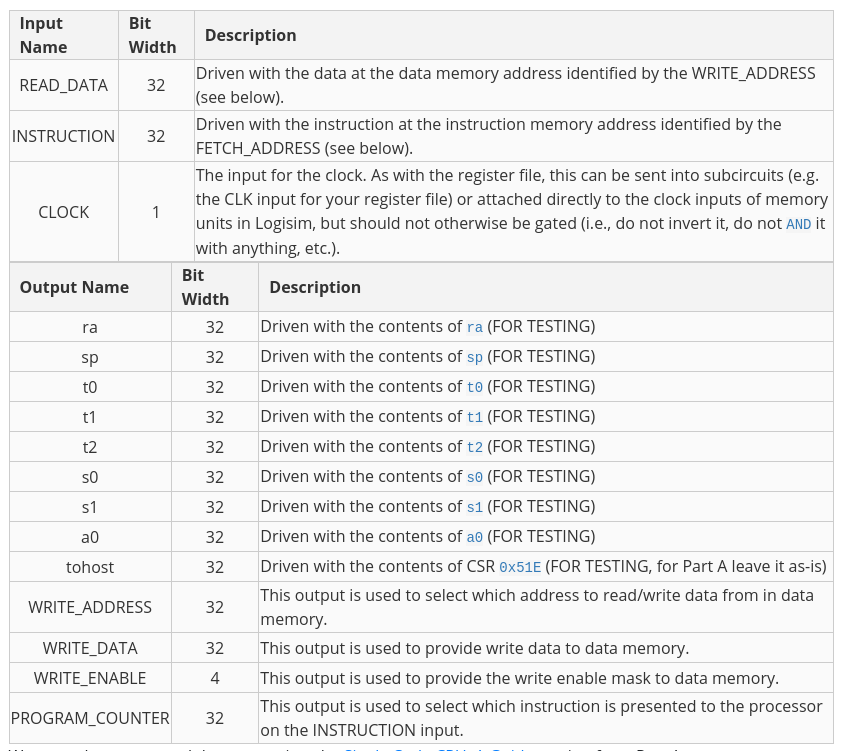
我们强烈建议你阅读A部分中的 "单周期CPU:A部分的指南部分。
同样,请确保你不要编辑输入/输出引脚或添加新的引脚!
Task 5: Custom Tests
对于 partB,我们在评分和初始代码中提供了一组相对基础的可见单元测试。这些测试旨在通过在测试的早期阶段提供一些指导来帮助减轻您的压力,但它们并不全面。您仍应为您的设计编写严格的测试,因为通过基本的合理性测试并不能保证您能通过任何隐藏测试。
partB的 autograder 测试分为三大类:单元测试、集成测试和边缘情况测试。我们不会透露所有 autograder 测试,但您可以使用我们提供的工具重新创建非常接近的测试,以便测试您的 CPU。
单元测试:单元测试通过单条指令对数据通路进行练习,以确保每条指令都已实现,并按预期运行。您应该为需要实现的每一条指令编写不同的单元测试,并确保彻底测试该指令的各种可能性。例如,单元测试 slt 应包含 rs1 < rs2、rs1 > rs2 和 rs1 == rs2 的情况。
集成测试:通过单元测试后,再进行使用多个功能的组合测试。尝试各种运行单个函数的简单 RISC-V 程序;如果运行正常,您的 CPU 应该能够处理这些程序。您可以尝试使用 riscv-gcc 将 C 程序编译到 RISC-V,但要注意我们使用的指令集有限(例如,您没有任何 ecall 指令)。我们建议您根据在实验室、讨论、项目和考试中的所见所闻,尝试自己编写简单的函数。
边缘情况测试:边缘情况测试会尝试你通常不会想到的输入,在某些情况下可能会触发错误。您应该查找哪些边缘情况?我们的一个小例子/提示:我们的两大类边缘情况来自内存操作和分支/跳转操作(其中两个测试是 mem-various-offsets(测试各种偏移量的内存指令)和 br-jump-limits(测试分支/跳转指令的限制))。思考这些操作可能引发潜在错误的其他方式。
Creating Custom Tests
我们提供了一个脚本(tools/create-test.py),它使用 Venus 来帮助您从 RISC-V 汇编生成测试电路!编写自定义测试的过程如下:
-
想出一个测试,并编写该测试的 RISC-V 汇编指令,将其保存在 tests/part-b/custom/inputs/ 文件夹中以 .s 结尾的文件中。该文件的名称就是测试的名称。如果有更多测试,请重复上述步骤。
比如说 tests/part-b/custom/inputs/sll-slli.s and tests/part-b/custom/inputs/beq.s -
使用 create-test.py 生成测试电路
python3 tools/create-test.py tests/part-b/custom/inputs/sll-slli.s tests/part-b/custom/inputs/beq.s -
现在可以运行刚才编写的测试了!
python3 test.py tests/part-b/custom/sll-slli.circ tests/part-b/custom/beq.circ
Test Coverage
省略,因为无法使用autograder
测试覆盖率:衡量测试覆盖指定代码库多少面积的指标。在本项目中,您将根据您的测试覆盖了多少所需的 ISA 来评分。
partB的autograder将检查位于 tests/part-b/custom/inputs/ 文件夹中的测试的覆盖率。当您将 B 部分提交给自动评定器时,自动评定器将输出一条信息,说明您的测试在我们的员工测试套件中的覆盖百分比,并在您的任何测试出现语法错误时通知您。
Task 6: Pipelining
到目前为止,您的 CPU 能够在一个周期内执行我们 ISA 中的指令。现在,是时候在 CPU 中实现流水线了!在本项目中,您需要实现一个两级流水线,其概念仍类似于讲座和讨论中涉及的五级流水线(如果您需要复习,请重温这些内容)。您要实现的两个阶段是
- 指令提取:从指令存储器获取指令。
- 执行:指令解码、执行和提交(写回)。这是正常五级 RISC-V 流水线其余四个阶段(ID、EX、MEM 和 WB)的组合。
由于所有的控制和执行都是在执行阶段进行的,因此除了一个周期的启动延迟外,您的处理器应该与单周期实现基本无异。不过,我们将采用两级流水线设计。一些需要考虑的事项:
-
IF 指令提取和 EX 执行 的 PC 值是相同还是不同?
不同的值。这才是流水线cpu设计的原因,当一个上升沿触发后,IF/ID寄存器存储的是EX阶段需要的PC,同时,这个上升沿会同时使得上升沿到来之前的PC到IMEM进行取指令。
例如
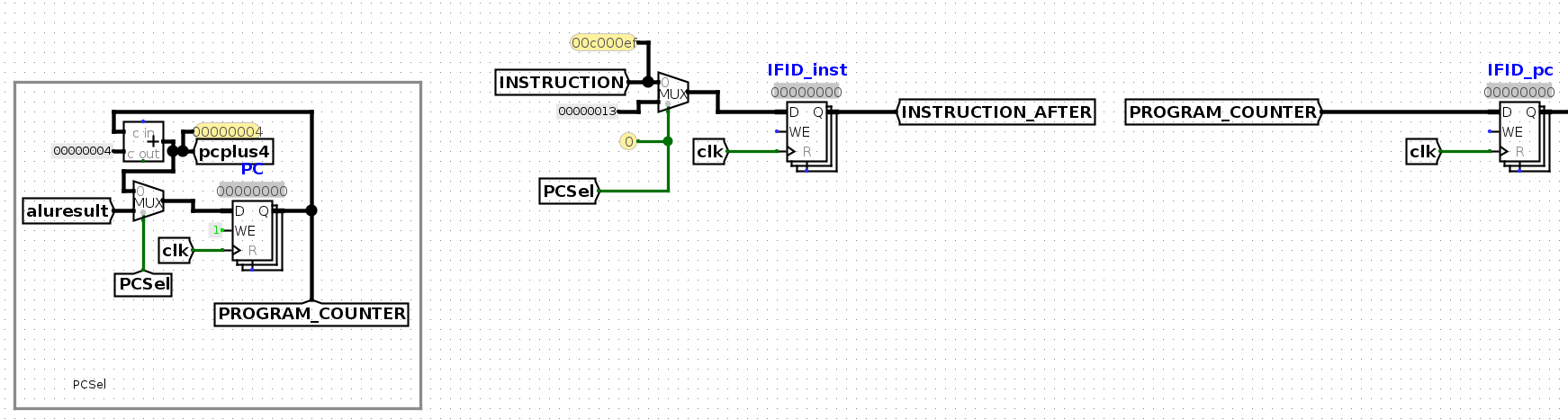
初始状态下,PROGRAM_COUNTER是0,这时IF阶段的INSTRUCTION是位于地址0的指令。第一个上升沿到来时,PC的寄存器会存储PC+4,将PROGRAM_COUNTER变为0+4,而IF/ID寄存器会存储上升沿到来之前的PC值,即0. 所以,第一个上升沿到来之后,当前INSTRUACTION是位于地址4的指令(第二个时钟周期(因为下降沿并不会产生影响,所以在这里可以看到第二个时钟周期的状态),第二条指令的IF阶段),而IF/ID存储的INSTRUCTION是位于地址0的指令(第一条指令的EX阶段)。 -
是否需要在流水线阶段之间存储 PC?
需要。因为EX阶段需要知道当前阶段的PC是多少(例如做pc+offset运算等等),如果不保存的话,那么EX阶段拿到的PC是IF阶段的PC。 -
这种两级流水线存在哪些冒险?
只有控制冒险。因为当前处于EX阶段的指令如果是跳转指令,那么处于IF阶段的指令就可以产生不符合预期的计算结果,应该让IF阶段的指令被杀掉。例如,EX阶段的指令是直接跳转到+8的指令,而+4的指令希望将一个寄存器的值递进1,那么,就不应该让+4这条指令进行EX阶段。这种2stage的cpu,一旦+4的指令进入Ex阶段,就会将错误结果写回,而按照程序的正常预期,这个+4所执行的寄存器值递进是完全不应该存在的。所以,直接应该直接将+4的指令杀掉,即替换为nop指令,等地址0的指令的EX阶段执行完,计算出跳转地址后,在第三个时钟周期再恢复执行。
您可能还会注意到一个起始问题:在第一个周期中,流水线阶段之间的指令寄存器不会包含从内存加载的指令。我们该如何处理这个问题呢?幸运的是,Logisim 会在复位时自动将寄存器置零,因此指令寄存器将以 nop 开始!如果你愿意,可以依赖 Logisim 的这种行为。
Control Hazards
由于 CPU 支持branch和jump指令,因此需要处理分支时出现的控制结构冒险。
如果执行了分支,紧接分支或跳转之后的指令将不会被执行。这使得您的任务变得更加复杂。当你发现分支或跳转处于执行阶段时,你已经访问了指令存储器,并取出了(可能是)错误的指令。因此,如果正在执行的指令是跳转或分支指令,则需要 "杀死 "正在获取的指令。
本项目中的 "杀死 "指令必须通过将 nop 与指令流放入MUX来完成,并将 nop 发送到执行阶段,而不是使用取回的指令。为此,您可以使用 0x00000013,或 addi x0, x0, 0;其他 nop 指令也可以使用。如果执行分支指令,则应执行 kill 指令(否则不执行 kill 指令)。每种类型的跳转都要执行 kill 指令。
注意:不要在 IF 阶段通过计算分支偏移来解决这个问题。如果我们每个周期都根据引用测试你的输出,而引用返回的是 nop,虽然这可能是一个概念上正确的解决方案,但这将导致你无法通过我们的测试。
还有一些需要考虑的问题:
-
要将 nop 放到指令流的MUX中,是放在指令寄存器之前还是之后?
我这里是放在了IF/ID寄存器之前。因为,IF/ID寄存器之后,是EX阶段需要使用的instruction,如果立即填充为nop,应该会影响EX阶段对instruction的ID。
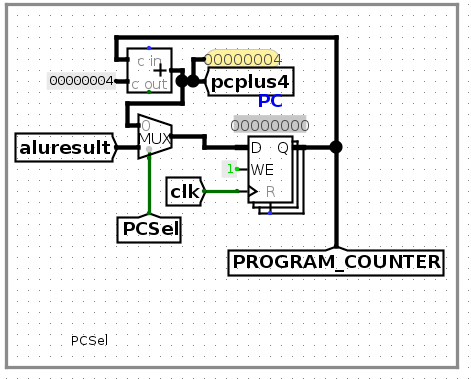
如果问题指的指令寄存器是这个pc后面的reg,那么需要修改mux为三路,添加一个nop指令的选项,从而会使pcsel的值需要有2bit. 改动较大。
-
在 EX 阶段执行 nop 时,下一步应该请求哪个地址?这是否与正常情况不同?
EX执行nop时,之前一条跳转指令计算的跳转地址已经写到了上图中的aluresult,所以,下一步的请求地址就是这个aluresult,并且在下一个上升沿触发到pc后面的reg中。这与正常情况相同。
Pipelined CPU Testing
我们在 tests/part-b/sanity/ 目录中为流水线 CPU 提供了一些基本的sanity测试(与任务 4 中的测试相同)。您可以使用
$ python3 test.py --pipelined tests/part-b/sanity/
注意:由于此时 CPU 已流水线运行,因此需要使用 --pipelined(或 -p)标记运行流水线测试。如果此时运行单循环测试(即不使用--pipelined 标志)(CPU 已流水线化),CPU 将无法通过这些测试!想想为什么会发生这种情况...
同样,您也可以运行流水线版本的自定义测试:
$ python3 test.py --pipelined tests/part-b/custom/
注意:由于您执行的是两级流水线处理器,第一条指令在第二个时钟周期的上升沿写入,因此您的指令效果将有 2 条指令的延迟。例如,让我们看一下 tests/part-b/sanity/inputs/addi.s 的第一条指令 addi t0, x0, -1。如果检查流水线参考输出(tests/part-b/sanity/reference-output/cpu-addi-pipelined-ref.out),就会发现 t0 直到第三个周期才出现变化。
请参阅信息:CPU 测试部分,了解使用这些测试的更多信息。请记住,从这项任务开始,您将使用流水线电路。
Task7: PartB README
How you designed your control logic
前提,注意当前proj3的PartB中需要处理的指令分别是什么,上面有张表格,列出了需要实现的指令,并且这些指令的详细格式
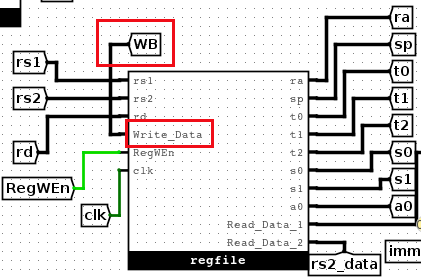
首先,注意control logic的输入和输出分别是什么
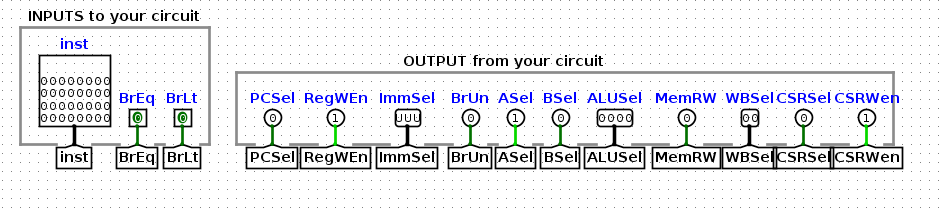
可以看到,BrEq和BrLt是输入进来的信号,这两个信号是在branch-compare.circ中生成的,用来表示被比较的值是否相等,高电平表示BrEq有效,即相等,BrLt同理。
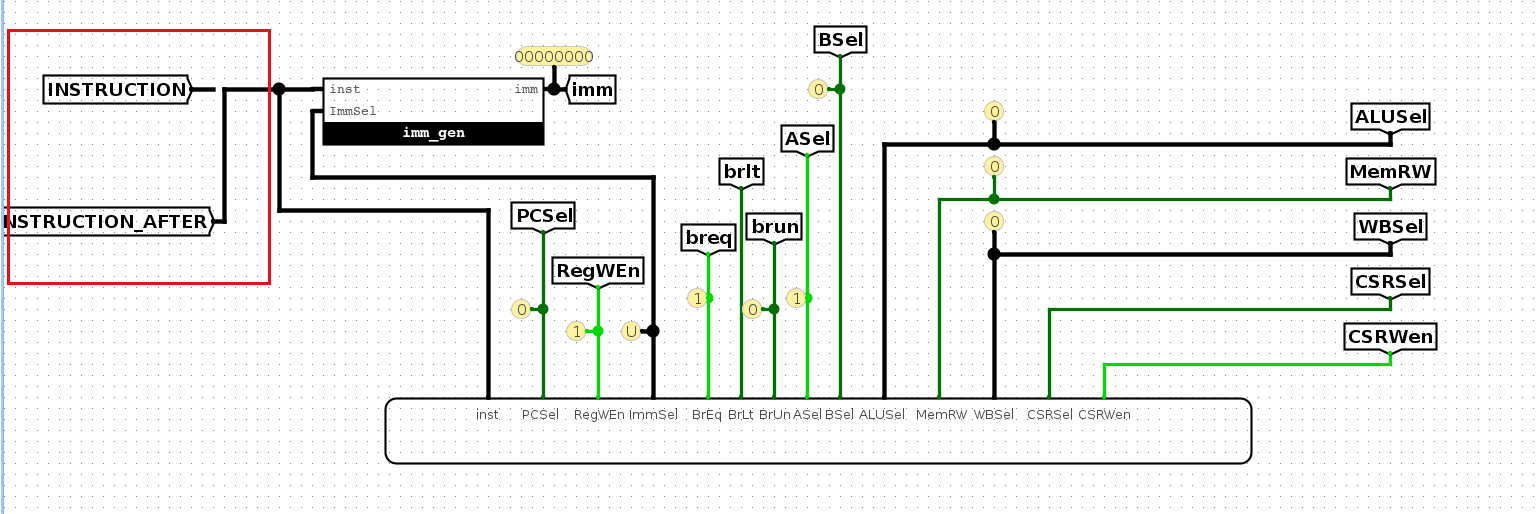
然后,control logic生成的控制信号是根据指令中具体的操作码、funct3、funct7等来生成的,所以将指令按照位拆解开来。
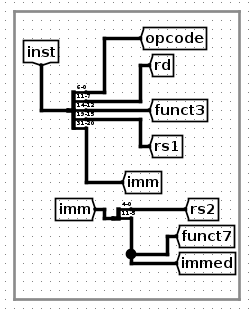
然后,判断当前这个指令是什么类型
比如是I类型?
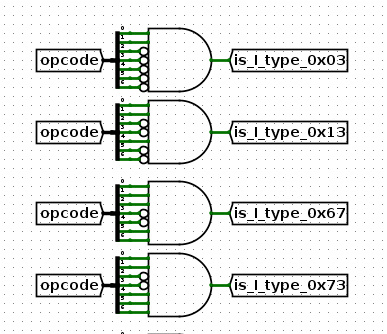
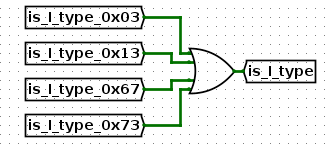
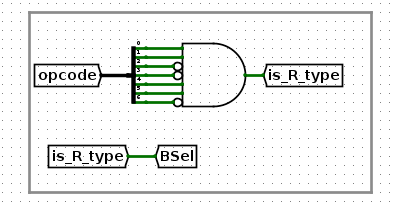
比如是R类型?图中BSel一会再说
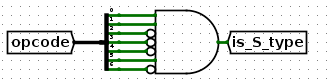
是S类型?
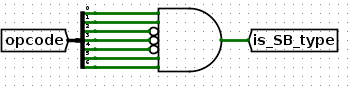
是SB类型(riscv的文档中也称为B类型)?
是U类型?
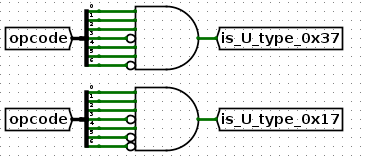
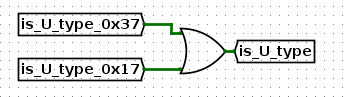
是UJ类型(也称J类型)?
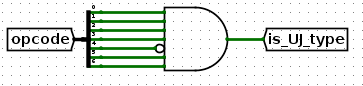
这些是一些基础的指令解码过程,后面会用到。
然后,依次开始看每个输出的控制信号如何实现
-
PCSel
PCSel的控制信号用来决定PC寄存器的值是取PC+4还是ALU计算结果,一般情况下PC都是按照PC+4来计算的,只有需要跳转时,PC才需要加一个偏移量来跳转到指定指令内存的位置
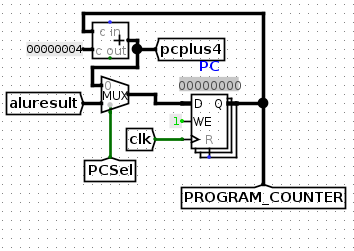
观察这些需要实现的指令,SB类型指令中都有一个条件,比如beq的PC+偏移量的条件是R[rs1]==R[rs2],即BrEq高电平。而jal是无条件跳转,jalr指令虽然类型写的是I,但也为无条件跳转,因为PC的结果是强制写为加上一个偏移量的。
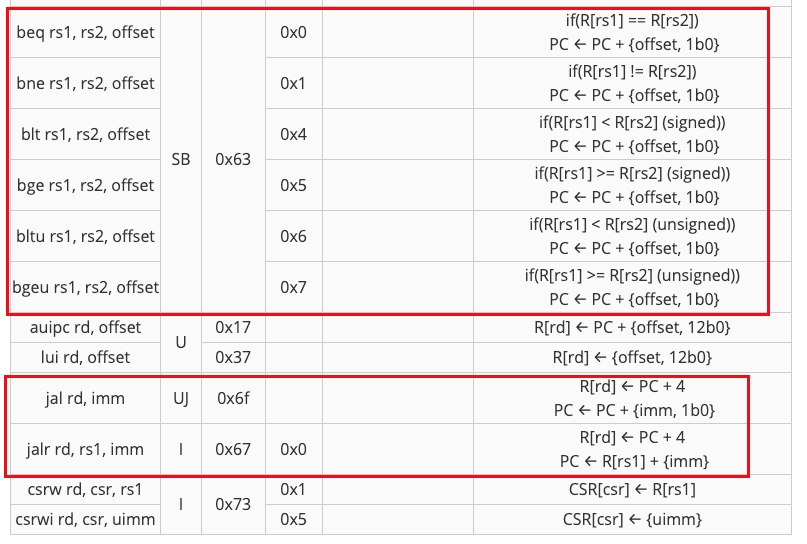
因此,就有了下面这个电路
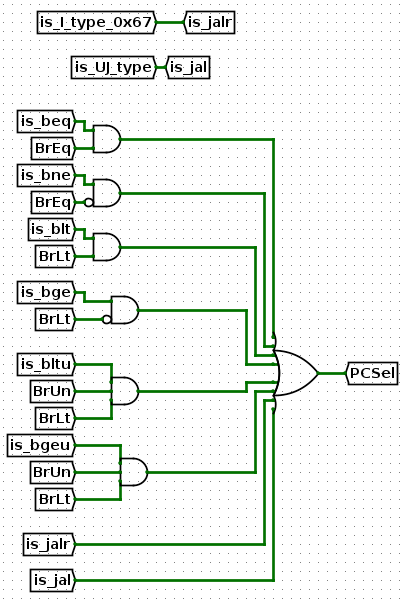
-
RegWEn
然后是RegWEn控制信号,该信号控制输入到regfile中,控制write_data是否写入到相应的寄存器中。RegWEn会传到write_en中,当这个信号是高电平时,由write_reg决定这个1bit高电平传到哪一个寄存器中。然后在相应的寄存器中,例如ra_we有效时,write_data会写入寄存器。
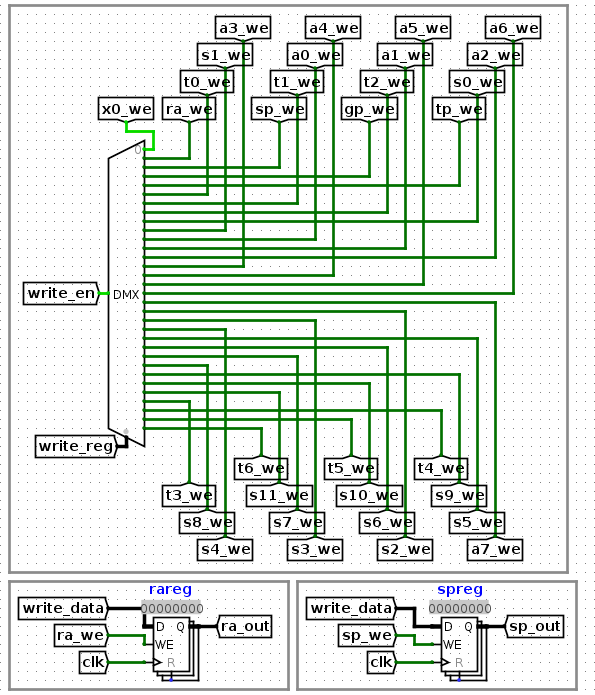
写回寄存器的操作,一般为R型指令,比如add,R[rd] = R[rs1] + R[rs2],即alu的运算结果。
而alu的运算结果,除了普遍的R型指令外,还有reg+imm和pc+imm。
所以,通过观察需要实现的指令列表,发现只有SB类型和S类型的指令是不需要写回寄存器的,如下
因此,可以这样实现RegWEn信号
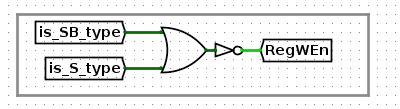
-
ImmSel
然后ImmSel信号
首先在imm-gen.circ中,看ImmSel信号的作用是什么,或者直接看proj3任务文档,这个信号用来控制如何从指令中提取出立即数imm

因此,看下riscv-spec


可以在imm-gen.circ 立即数生成电路中建立这样的结构
左侧这块的电路是完全根据指令中提取立即数的位,照搬的。右侧这个电路可以自己定义,只需要确保,ImmSel能够提供正确的值,来选取各种指令中的立即数就行。
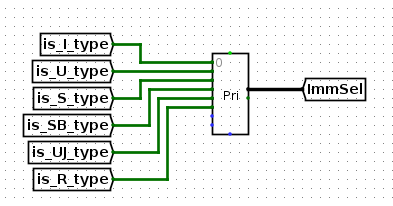
在当前这个结构中,ImmSel=0选择I类型指令中的imm,ImmSel=1选择U型指令中的imm,依次类推,而最后的000..表示选择R型指令,因为R型指令完全没有imm
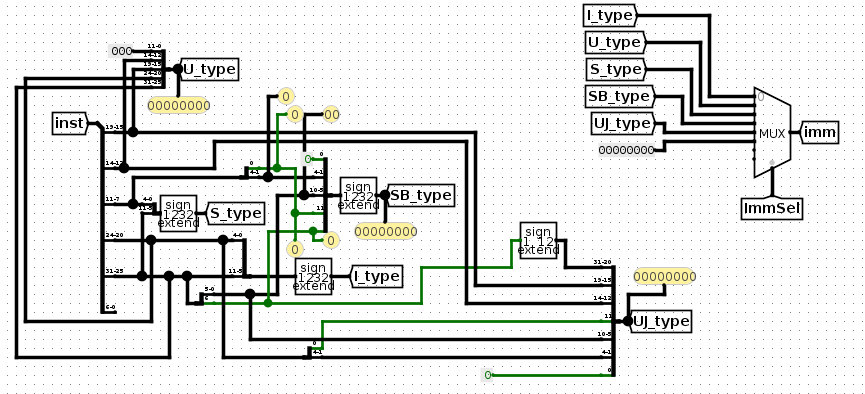
因此,在control logic中,就使用priority encoder来生成ImmSel,如下。PriorityEncoder的作用是,如果这些输入中,有多个高电平,那么输出是高电平输入索引的生序序列最后一个的索引。当然,目前只会有一个高电平,其他都是低电平,所以,这个ImmSel信号会得到高电平对应的索引。例如,如果是SB类型指令,那么ImmSel信号的值是3.对应imm-gen中,3这个值会在MUX中选择SB_type的立即数,输出到imm中。
- BrEq, BrLt
这两个是control logic的输入,是由branch_comp生成的。
-
BrUn
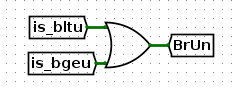
然后,BrUn信号如下,只要比较的是unsigned,给出BrUn高电平即可
-
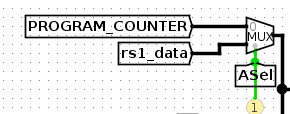
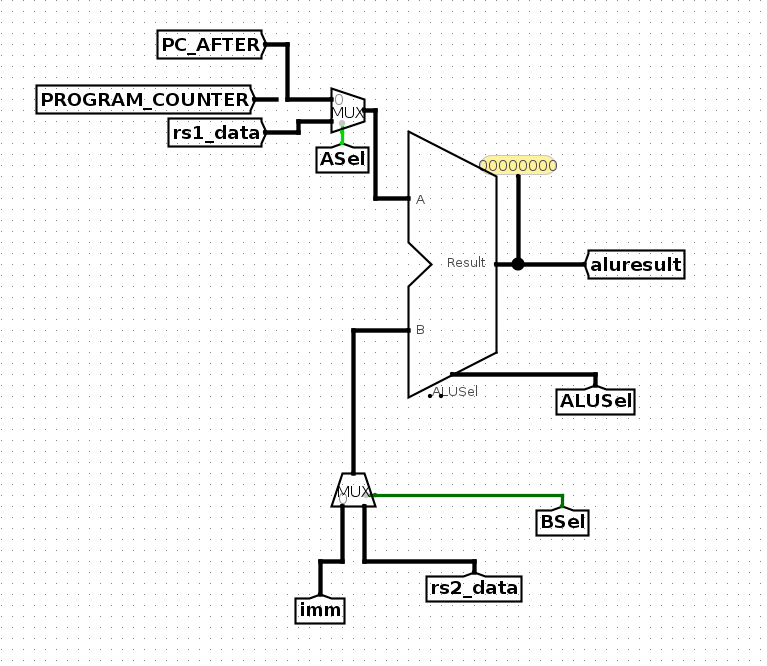
ASel
然后ASel,是选择pc和寄存器的。
ASel选择的是rs1或者pc,所以看一下需要实现的指令。SB、U、UJ这种指令都是使用PC来送进ALU,其中SB类型指令是有条件的,比如beq需要BrEq有效。
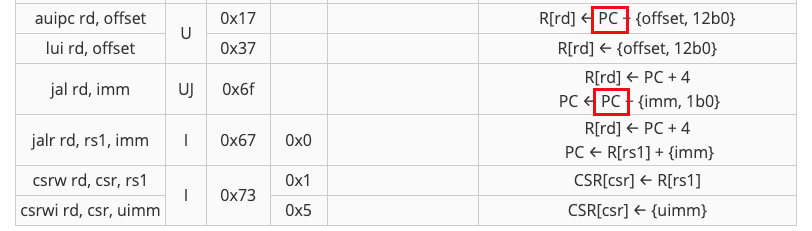
但是,即使SB类型指令中即使跳转条件没有满足,依然可以选择pc作为alu的输入,只需要在PCSel信号中,设置当跳转条件不满足时,PCSel选择到PC+4即可(在设计PCSel时已经得到满足),即使得alu计算结果无意义。
因此,ASel的信号可以按照如下设计。
-
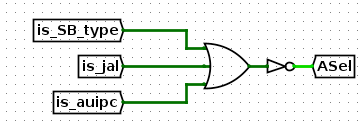
BSel
然后,BSel用来选择imm或者rs2
在指令列表中,S/SB/U指令也是使用imm作为alu的输入
SB指令时,alu的输入为pc和imm,这个imm即是offset
U指令中,auipc使用offset(imm)作为alu输入;lui指令也是使用offset(imm)作为输入,alu的运行模式设置为直接输出rs2即可,即mode 15
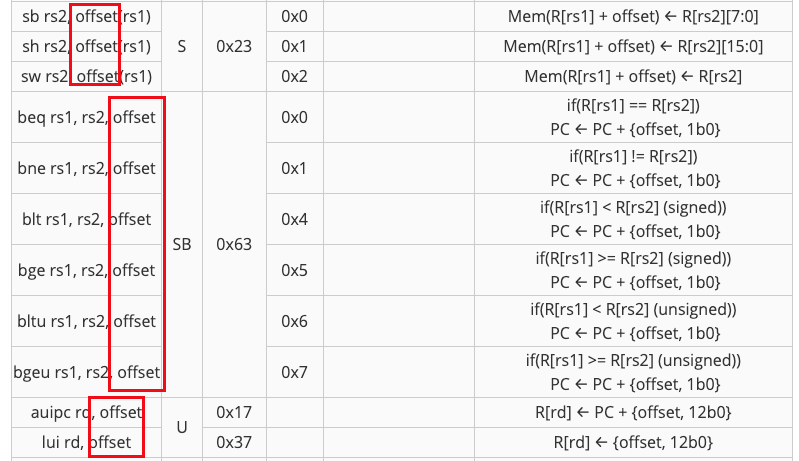
S指令中,Mem的写入地址是rs1+offset(imm),这个结果为alu计算结果,如下所示。
综上,只有R指令不需要选择imm,而是选择rs2,其他指令都选择imm
所以BSel设置如下
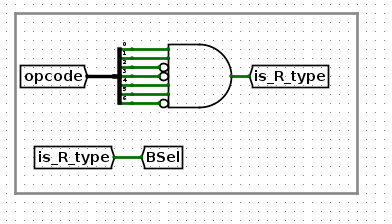
// TODO
7. ALUSel
-
MemRw
-
WBSel
-
CSRSel
-
CSRWen
Advantages/Disadvantages of your design
Best/Worst bug or design challenge you encountered, and your solution to it
- 在实现2stage流水线时,遇到了cpu-jump.circ测试失败的问题。
从non pipeline到pipelined,增加了IF/ID寄存器,如下

并且,将后续阶段使用的INSTRUCTION和PC都修改为IF/ID寄存器所传递的值,如下:
问题复现
cpu-jump的指令序列如下

c000ef指令是jal x1, 12,即跳转到地址12的指令,并将pc+4写入到x1,即ra
因为这是riscv32,所以每条指令占4B,按字节寻址,地址12是指令8067
8067是指令jalr x0, 0(x1),这条指令跳转到x1,即ra寄存器的地址,这个值是c000ef写入的pc+4,即0+4,即指令fff00413。
在8067执行到EX阶段时,
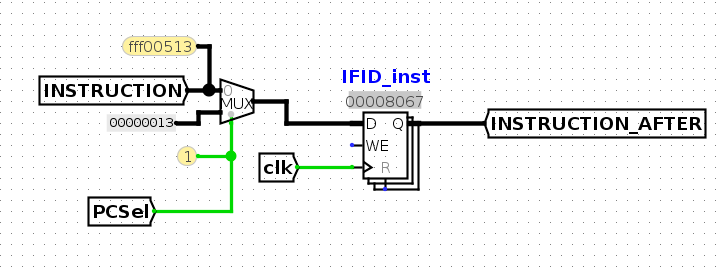
ra寄存器的值是8
由于ra寄存器的值使用过WB阶段写回的,
我们知道,在c000ef这条指令到了EX阶段,应该将pc+4,在WB写回到ra中。
看下面这张图
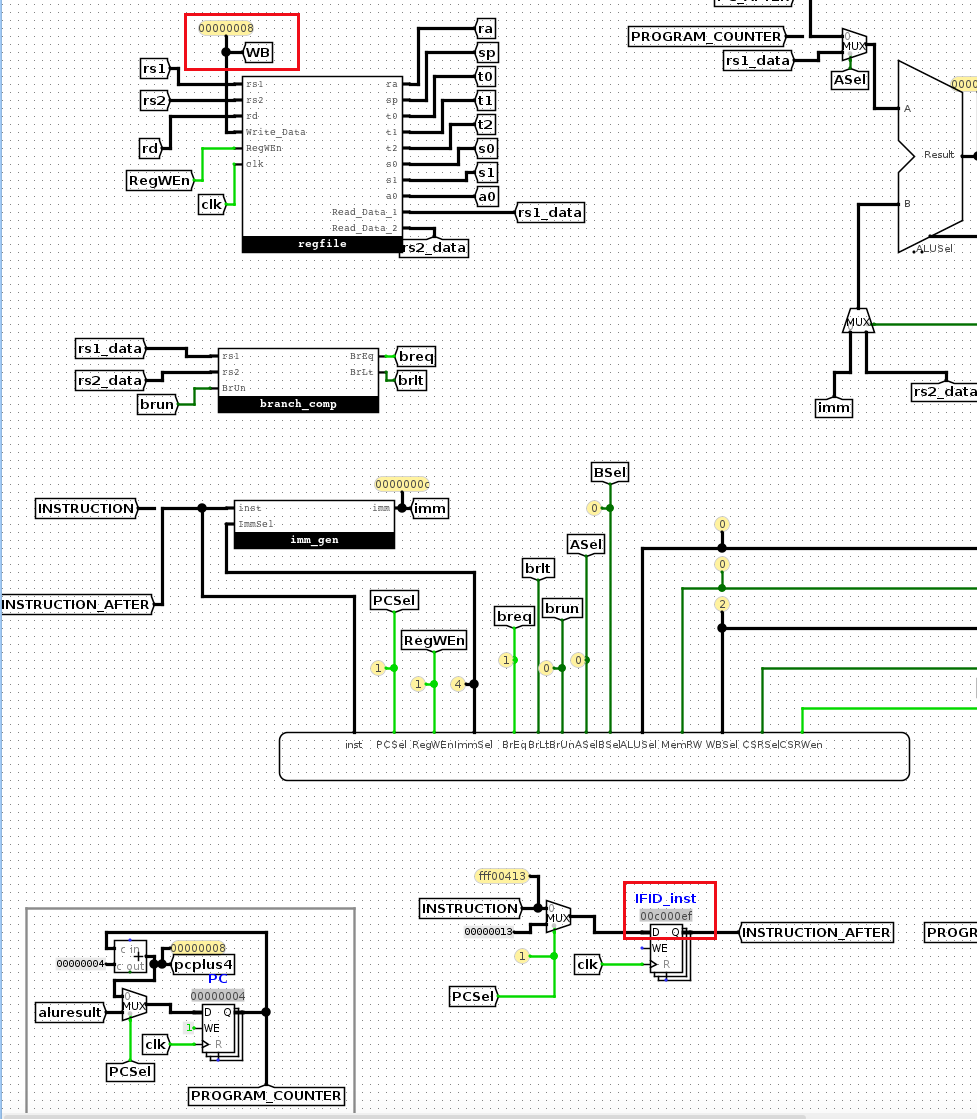
c000ef已经处于EX阶段,但是WB的值是8,WB的值是WBSel信号决定的,其是2,因此选择的是pc+4。
可以看到pc+4是8,因为pc目前已经是处于IF阶段的pc值,即4.
但是,处于EX阶段的指令c000ef,所要写回的pc+4,pc应该是c000ef的pc,即0+4.
所以这里应该将PC_AFTER+4喂给WBSel的mux
如下图
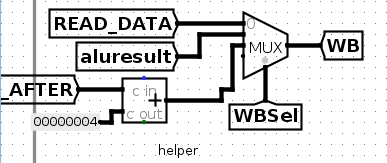
测试就通过了。
本文来自博客园,作者:ijpq,转载请注明原文链接:https://www.cnblogs.com/ijpq/p/17448021.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号