dwconv2d wgrad direct epilogue simt
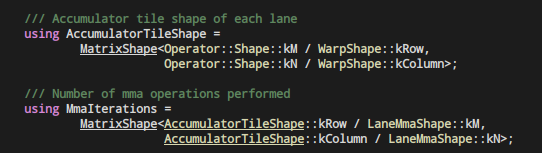
例如warpshape is 64x32, WarpShape::kRow = 8, WarpShape::kColumn = 4 => AccumulatorTileShape = 8x8
but LaneMmaShape::kM = 4, LaneMmaShape::kN = 4, represents each thread deal with 4x4 elemnt. thus, all 8x8 elements requires two iterations along both row and col axis.



mma_accum_start points to the red point (idx) of elements deal with one thread
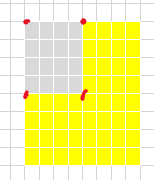
the mma_accum_coord is always same value for each thread, but points to global(warpshape level) coordinate. for example, mma_m = 0, mma_n = 1, mma_accum_coord is (0, 1*4*4) = 0,16. it also interpreted by coordinate indicates MMA iterations starting point.
as following fig depicted, the mma_accum_coord is the block left-top coordinate bounded by red box. iter(mma_m,mma_n) also drawed.
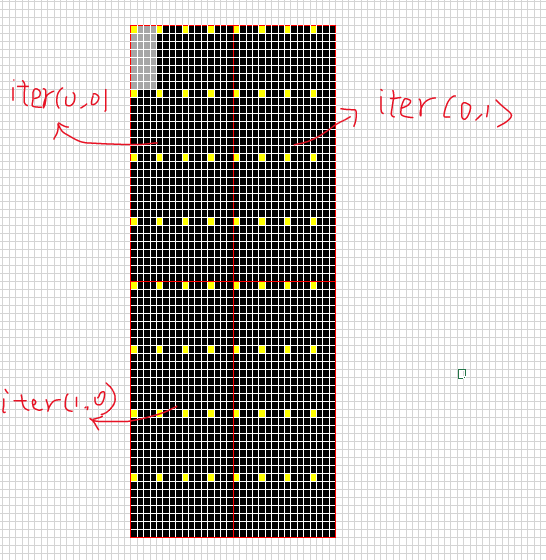
another things, accum_coord is itered along LaneMmaShape, represents elements deal with this thread within one outer mma iteration.
for example, the left topper blue block means row=0,col=0, right bottom blue block mean row=1,col=1, iterating along LaneMmaShape::kM,LaneMmaShape::kN.
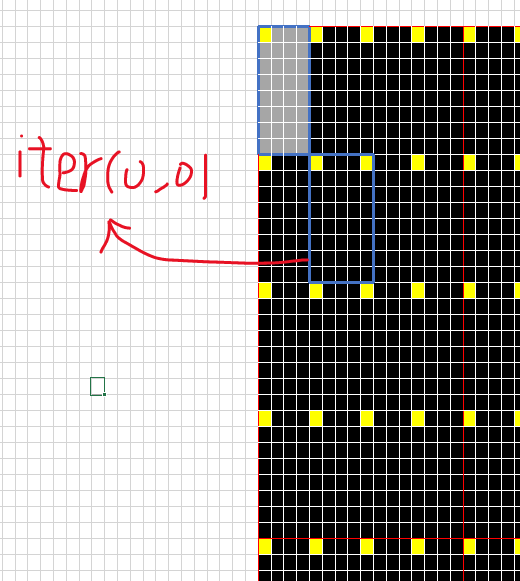
then, following 2 for unfold elements of one thread.
firstly glance at accum_coord = mma_accum_coord + MatrixCoord(row,col). it is a mma iterations starting coord added by a local elements offset. from here, the accum_coord is same for all threads
but, the coord(accum_coord) is added by thread_origin_ which contains threads info

therefore, the value coord_ passed into tile_map_() equals to threadblock_offset + warp_offset + lane_offset + mma_accum_coord + (row,col)
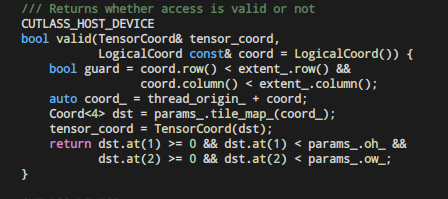
lane_offset return this coordinate of lane_idx, which is the thread idx within warp
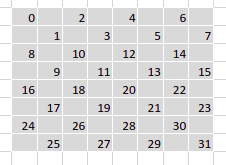
EVEN IF I DONT KNOW WHY THE LANE_OFFSET DEPLOY THE THREAD IN THIS LAYOUT, but the coord_ point to a absolute global coord of element.
本文来自博客园,作者:ijpq,转载请注明原文链接:https://www.cnblogs.com/ijpq/p/17024917.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号