阅读cuda docs - best practice
cuda toolkit v11.8 docs, link:https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html
preface
assess评估 application
异构计算
application profile
parallel it
get started
获得正确答案
优化cuda applications
perf metrics 性能指标
timing
bandwidth
Bandwidth - the rate at which data can be transferred - is one of the most important gating factors for performance,表明了内存性能,是cuda优化最基础的门槛。
bandwidth包括理论值和有效值,一般有效值比理论值要低,要使用有效值来作为优化目标
effective
单位是GB/s,把读的字节数和写的字节数求和再除个运算时间。
例如

theoretical
// TODO
mem opt 内存优化
between host and device
从带宽的理论峰值来看,device上的数据传输高达890gb/s,而host2device的理论峰值只有16gb/s(受限于pcie总线)。所以,即便尽可能缩减了host2device的数据传输,对kernel本身的计算性能没啥影响,但是这个要求也是门槛级别的。具体做法上,应该把数据的生命周期都尽可能放在device上,不要让他沾到host的边。host2device的开销太大了,尽可能把数据做batching,一次性传输。(原文中写到,即便这些数据在mem不连续,但是把他们放到连续的buffer,以batching的格式传输,到device再拆开也值得)。
pinned mem
获得高带宽要用page lock mem,在锁页mem上进行alloc有专门的API,但同时也不是可以随意尽情使用锁页mem,因为空间不大。我们又没法提前预知锁页mem大小,所以应该根据不同的执行参数去看跑出来的结果?
使用计算来遮挡数据传输
简单的说就是异步进行内存拷贝。
异步拷贝需要使用pinned mem,而且还需要指定stream。stream指的是在device上执行指令的一个队列,不同的stream之间可以交错执行或者完全并行,并行地执行多个stream就可以实现用计算来掩盖数据拷贝。实现计算遮盖内存拷贝有两种方式:1)可以通过异步数据拷贝来遮盖host计算;2)用device计算遮盖host计算。
具体例子:
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, 0);
kernel<<<grid, block>>>(a_d);
cpuFunction();
异步内存拷贝使用了默认stream,即stream0,kernel的执行也同样使用默认stream。由于kernel需要使用拷贝好的数据,因此这里都使用默认stream,就不用进行kernel和内存拷贝的同步操作。
因为异步内存拷贝和kernel执行都会立即将控制权返回给host,所以下面的cpufunction可以立即执行,并且这个计算被内存拷贝和kernel执行遮盖掉了。
部分设备支持数据拷贝和device计算并行操作,也就是说用数据拷贝来遮盖device计算。(cudadeivceprop的asyncenginecount表示是否支持),进行这个操作还是需要pinned mem,此外要将数据拷贝和kernel放在不同的stream。
并行执行kernel和数据拷贝
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, stream1);
kernel<<<grid, block, 0, stream2>>>(otherData_d);
当存在数据依赖时,可以通过顺序和阶段并行来解决,顺序就是最愚蠢的方式了,主要是看下阶段性并行
顺序地拷贝和执行
cudaMemcpy(a_d, a_h, N*sizeof(float), dir);
kernel<<<N/nThreads, nThreads>>>(a_d);
阶段地并行拷贝和执行
// TODO

0拷贝
统一内存寻址
device 内存空间
合并全局内存访问
全局内存的读写由warp为单位进行,并且被尽可能少的transaction(事务)来完成。
重点: 尽可能地使用合并访问
不同具体设备的合并访问要求是不一样的,即和架构相关,要参考具体卡的架构说明
不过对于算力6.0以上的设备来说,总结起来就是:warp所访问的地址宽度以32字节每个内存事务来划分。
3.5/3.7/5.2算力设备的L1缓存可以手动开启,如果开启后,那么内存事务的宽度将提升为128字节。
对于算力6.0及以上的设备来说,L1缓存是默认开启的,不过与上一条不同,在这些设备上,global的读写无论是否cache到L1缓存中,内存事务仍然是32字节。
在ECC(error correcting code,错误检查,提高数据正确性,参考:https://stackoverflow.com/questions/23432834/cuda-ecc-performance-cost)开启的卡上,执行合并的内存访问更为重要,发散内存访问会带来更为严重的内存访问开销,尤其是往global写数据时。
简单访问模式
在32字节对齐的地址上,第k个线程访问第k个word(4B),比如是warp访问了连续的float数组。在下图中,4个连续的32B内存事务来提供这些内存访问操作。
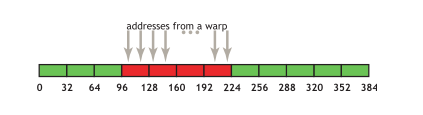
同时,如果warp中一旦有多个线程访问了相同的地址或者某些线程没有访问,虽然请求的地址不能填满4个内存事务,但是这4个内存事务仍然会进行读取。又或者是这个warp的线程不是像图中这样规矩访问的,比如是乱的,但仍然刚好填满对齐的4个内存事务,那么也仍然是这4个内存事务来完成访问操作(6.0算力及以上)。
顺序但不对齐的访问
如果访问的地址没有对齐32B这样的内存事务宽度,例如下图,那么就会请求5个内存事务。

使用cudamalloc这样的api申请内存时,至少保证是256B对齐的,因此要针对这个特点,布局自己的线程块。
非对齐内存访问的开销
// TODO
__global__ void offsetCopy(float *odata, float* idata, int offset)
{
int xid = blockIdx.x * blockDim.x + threadIdx.x + offset;
odata[xid] = idata[xid];
}
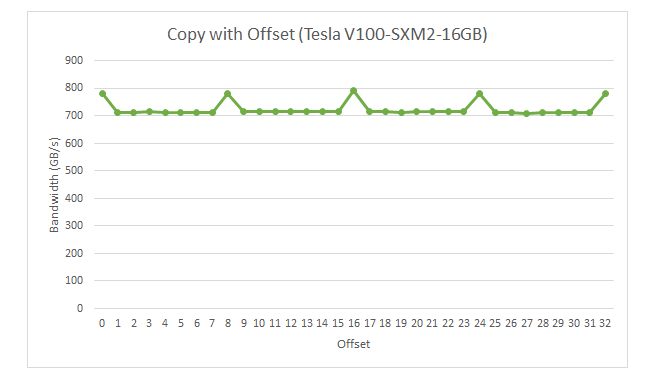
当offset=0,8,...时,带宽能达到相同的水平。例如offset=8,一个warp访问的地址空间是[0+8],[1+8],...,[32+8], 即32B, 36B, ..., 160B,共128B, 仍然是4个内存事务(每个32B)。4个内存事务的关键是8offset,在读float这种4B时,可以把地址对齐到32B,所以可以正好对齐内存事务。
其他offset时,是5个内存事务,所以耗时提高,带宽下降。
固定步长的访问
本文来自博客园,作者:ijpq,转载请注明原文链接:https://www.cnblogs.com/ijpq/p/16825905.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号