CUDA profilier
profiler
nvprof
最早期的profiler,只提供cli
nvvp
进化版本的nvprof,提供了gui
ncu
写这个记录的时候,cuda已经不再支持nvprof,nvvp也变得异常难用(因为很多功能,比如metrics,去掉了)。现在推荐用nsight compute,这个工具分为gui和cli版本。
看懂profile kernel
GPU speed of light
这一页表示达到的利用率和理论最大值的比值,可以直接看roofline和recommendations.
roofline包含【memory bandwidth boundary/ridge point/peak performance boundary/achieved value】如下图
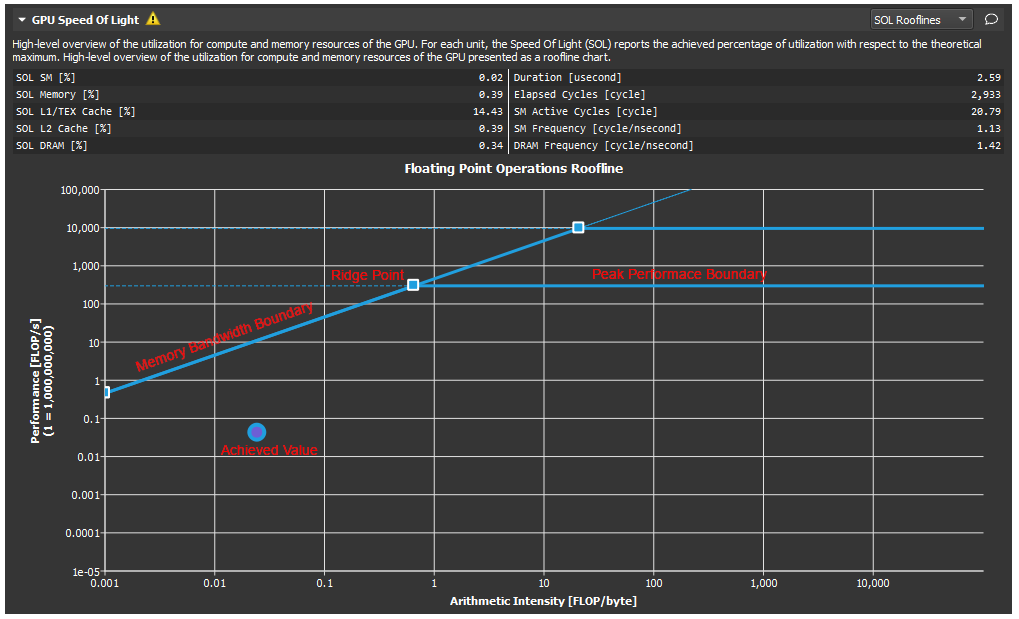
画图过程是:
- 首先根据硬件水平,查询理论峰值带宽(GB/s,每秒读取多少字节数据)和理论峰值计算能力(flop/s,每秒运算浮点数)。
0.1 峰值性能(flop/s)是由硬件水平决定的,可以直接画一条横线,记峰值性能为\(P_{peak}\).(roofline模型有多种,例如多条byte/s和多条flop/s的roofline,多条flop/s一般分别表示单线程和多线程的峰值水平,而多条byte/s表示多级存储(L1/L2/DRAM)的性能,可以参见NERSC的介绍:https://www.nersc.gov/assets/Uploads/Tutorial-ISC2019-Intro-v2.pdf )
0.2 峰值带宽的单位是byte/s 有硬件决定,由于x轴是flop/byte, y轴是flop/s。因此y/x的单位是byte/s,既形成一条斜线,存储器硬件越好,这个斜线越陡(显然, larger byte/s)。此外,这条线y=kx+b中b=0,因为当Intensity为0时,Performance(flop/s)也为0. 记理论峰值带宽为\(B_{peak}\)
0.3 求ridge point. \(y = Bx = P_{peak} => x = P_{peak} / B_{peak}\) - 确定当前kernel的计算密集度(一种方法来自对代码的估算,另一种方法来自硬件计数器直接提供采集结果),画一条垂线,那么当前kernel的性能必处于这条垂线上。
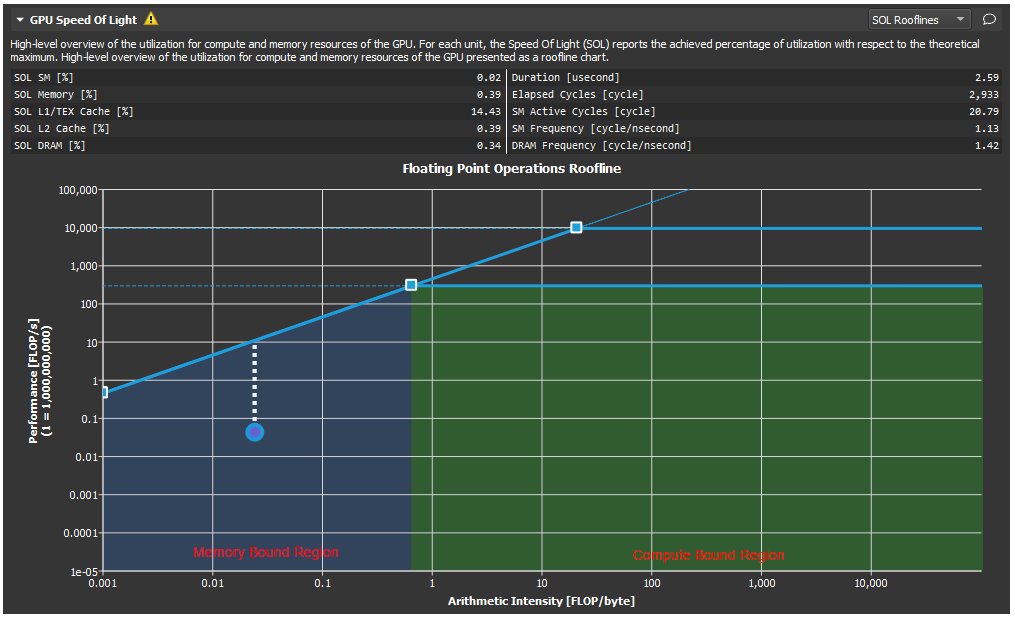
- 那么,此时就可以看一下这个计算密集度是处于mem bound区域还是performance bound区域。
- 如果处于mem bound区域,此时实测的点可能接近mem bound斜线,或可能远达不到mem bound斜线。由于flop/s是由 \(flop/bytes * byte/s\) 算出来,所以更临近mem bound斜线的点的访存效率是比远离的点更好的(同一个flop/bytes条件下,flops/s 越大,即byte/s越大)。当然,此时这个计算密集度所能获得flop/s由于受限于mem bound,还无法接近peak performance,所以,应该增加计算密集度,即增大每byte的flop,以便使achieved value point右移,进入perf bound区域,从而才有可能达到更高的flop/s. (有些kernel理论上限intensity < ridge point,那就只能在mem bound区域尽量提高perf)
- 如果处于performace bound区域,假设A和B两个点,具有相同的flop/byte,A的flop/s高于B的flop/s,也说明A的byte/s优于B的byte/s
- 所以,总结3 and 4两点,如果位于同一个计算密集度条件下,应该尽可能接近bound线(mem bound/performance bound)。如果距离很远,都是访存需要优化。如果位于mem bound区域,总应该提高计算密集度,使得优化访存带来的提升能够接近理论峰值性能
- 如果两个点A和B都位于performance bound线上,但是A的计算密集度大于B的计算密集度。那么flop/byte中,A的访问byte更小,对内存数据的依赖更小。不过这可能并不反映什么问题,需要结合具体使用场景来看。
- 在当前这个程序的计算密集度下,程序可获得最大flop/s = min(峰值浮点性能,计算密集度*峰值内存性能)(公式推导见NERSC的link)。例如在斜线上(这时的斜线指的是可能超过屋脊点的延伸斜线),给定了一个计算密集度的值,根据硬件水平得到峰值内存性能,乘积后得到flop/s。而横线部分就是公式直接去min的第一个参数,使得这个乘积所得flop/s不能继续线性增长(不可能超过理论计算性能峰值)。
如果achieved point位于斜线下方,表示kernel受限于内存性能
如果achieved point处于横线的下方,表明当前kernel受限于算力
无论achieved point处于哪个位置(只要没到线上),都应该通过优化访存和计算密集度来使point尽量接近roofline. 比如当前这个点,即便不能继续增强arithmetic intensity, 也可以通过其他常规优化方法提高perf
比如cuda renderer作业,之后的图如果非官方,均为该程序的测试结果link的roofline如下
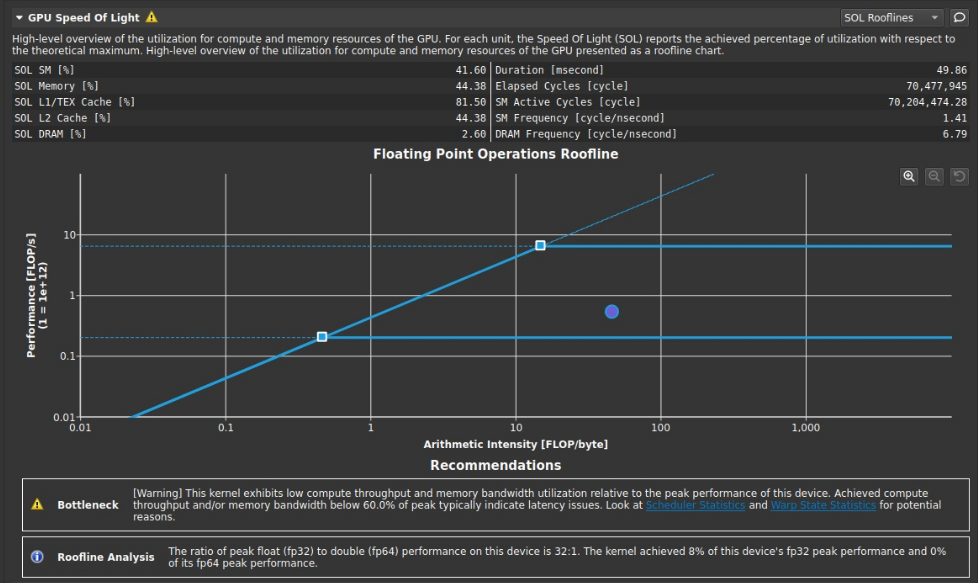
在下方给出了建议,提示是计算吞吐量和内存带宽利用率都非常低,需要查看scheduler和warp state统计结果。在计算吞吐量和内存带宽利用率方面不到60%,意味着存在latency时延问题。
compute workload analysis
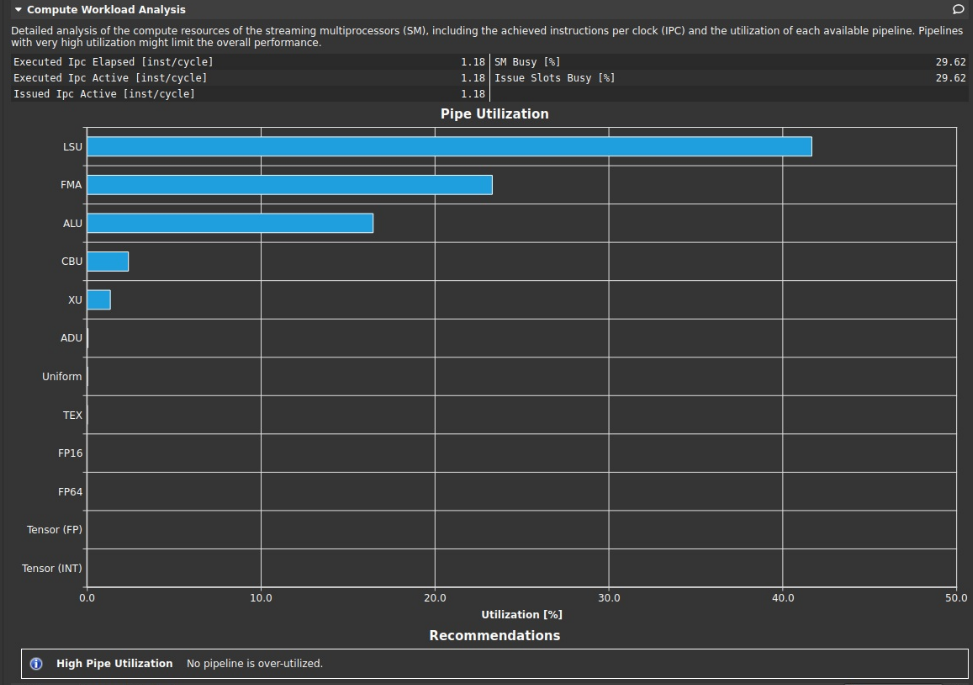
IPC是CPI的倒数,是每时钟周期的指令数。提示中写过高的流水线利用率会限制整体性能,但该测试结果显示没有过高的流水线利用率。
memory wordload analysis
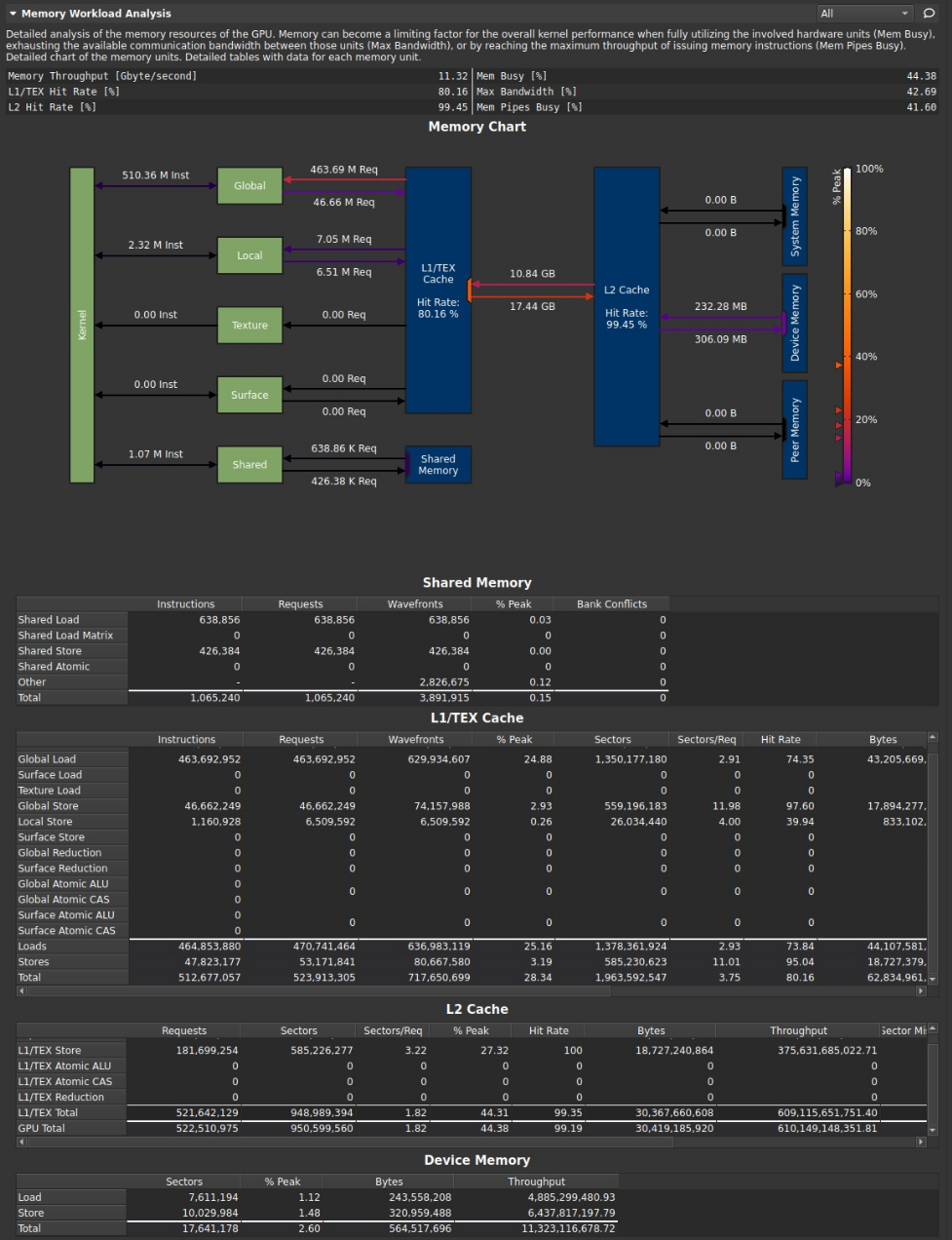
提高mem busy/max bandwidth/mem pipes busy的值很重要,是主要限制内存性能的指标.
- instructions是simd汇编指令的总数
- req是请求数(7.0算力及更新设备上,每一条指令只生成一个内存请求,而较早的设备中,每一条指令生成一个或多个内存请求),每个warp执行一条指令,所以一般是一个req.
- sector是一块对齐的32B内存,一个内存事务transaction可能是由1/2/4个sector组成。
- sectors/req表示每请求对应的sector数量,这个值越小越好。因为,越小的值表示cacheline中无重叠访问。如果是只用L2cache,一个trasaction是32B,如果是L1cache+L2cache,一个transaction是128B
假设这个值是32=32个sector/1=1024B/1,分母1表示warp的一次内存请求, 那么除法结果32表示warp的一次内存请求申请了32个sector,(以L1+L2,128B每transaction为例), 32*32B/128B =8次内存事务。
理想情况应该是一个warp中的线程,每个线程访问一块独立且对齐的4B(假设是int)内存,这样的话sector数量 = 32*4B/32B = 128B/32B =4 ,而这4个sector正好对应一个transaction,因此一次内存事务可以满足一个warp的请求。4个sector被warp中32个线程请求到,每8个线程请求了一块连续的地址,且连续的地址位于同一个sector内。
shared mem

device mem
设备内存包括了global/constant/texture/surface/local

其他注意事项
将nsight compute的可执行文件添加到path
参考
https://docs.nvidia.com/nsight-compute/NsightCompute/index.html
https://docs.nvidia.com/nsight-compute/ProfilingGuide/
https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#roofline
https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#metrics-decoder__metrics-quantities
https://www.nersc.gov/assets/Uploads/Talk-NERSC-NVIDIA-FaceToFace-2019.pdf
https://developer.nvidia.com/blog/using-nsight-compute-to-inspect-your-kernels/
本文来自博客园,作者:ijpq,转载请注明原文链接:https://www.cnblogs.com/ijpq/p/16137109.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号