StarRocks调研
StarRocks调研
简介
StarRocks
StarRocks原名DorisDB,是新一代极速全场景MPP数据库。StarRocks 是 Apache Doris 的 Fork 版本。
官网地址:https://www.starrocks.com/zh-CN/index
StarRocks 分为社区版和企业版,社区版为开源,企业版需付费使用。社区版支持了大部分的功能,但不支持StarRocks Manager(可视化运维监控平台),在数据库管理上不太方便。
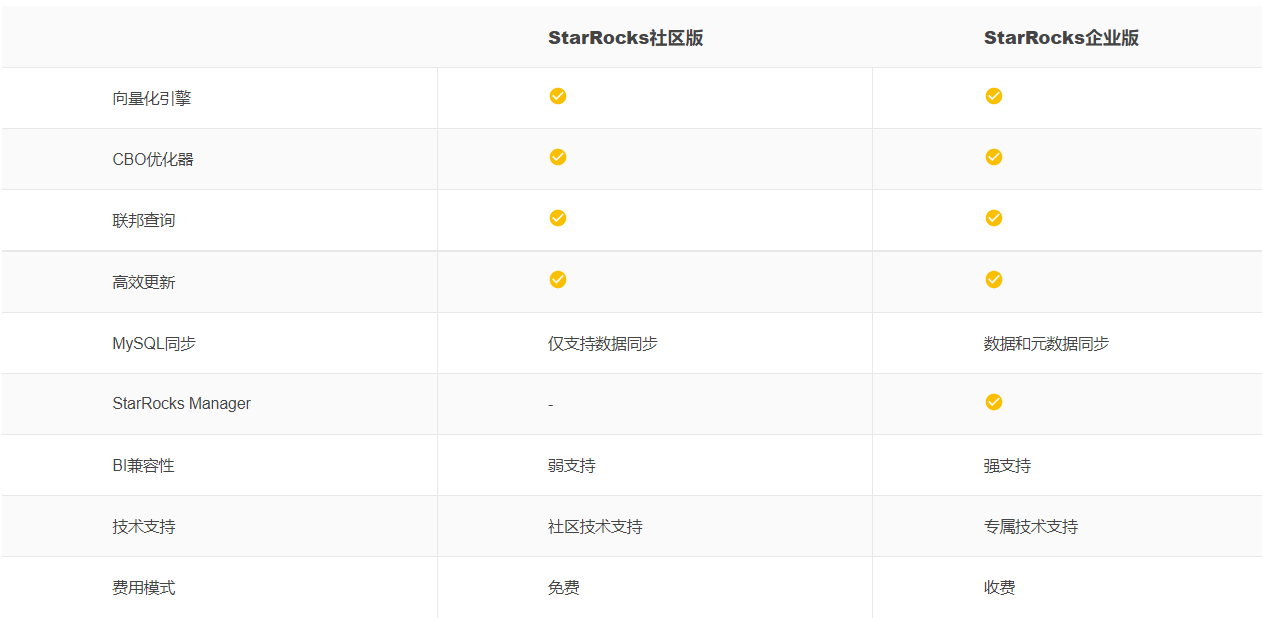
StarRocks特性
StarRocks的架构设计融合了MPP数据库,以及分布式系统的设计思想,具有以下特性:
架构精简
StarRocks内部通过MPP计算框架完成SQL的具体执行工作。MPP框架本身能够充分的利用多节点的计算能力,整个查询并行执行,从而实现良好的交互式分析体验。 StarRocks集群不需要依赖任何其他组件,易部署、易维护,极简的架构设计,降低了StarRocks系统的复杂度和维护成本,同时也提升了系统的可靠性和扩展性。
标准SQL
StarRocks支持标准的SQL语法,包括聚合、JOIN、排序、窗口函数和自定义函数等功能。StarRocks可以完整支持TPC-H的22个SQL和TPC-DS的99个SQL。StarRocks还兼容MySQL协议语法,可使用现有的各种客户端工具、BI软件访问StarRocks,对StarRocks中的数据进行拖拽式分析。
全面向量化引擎
StarRocks的计算层全面采用了向量化技术,将所有算子、函数、扫描过滤和导入导出模块进行了系统性优化。通过列式的内存布局、适配CPU的SIMD指令集等手段,充分发挥了现代CPU的并行计算能力,从而实现亚秒级别的多维分析能力。
智能查询优化
StarRocks通过CBO优化器(Cost Based Optimizer)可以对复杂查询自动优化。无需人工干预,就可以通过统计信息合理估算执行成本,生成更优的执行计划,大大提高了Adhoc和ETL场景的数据分析效率。
联邦查询
StarRocks支持使用外表的方式进行联邦查询,当前可以支持Hive、MySQL、Elasticsearch三种类型的外表,用户无需通过数据导入,可以直接进行数据查询加速。
高效更新
StarRocks支持多种数据模型,其中更新模型可以按照主键进行upsert/delete操作,通过存储和索引的优化可以在并发更新的同时实现高效的查询优化,更好的服务实时数仓的场景。
智能物化视图
StarRocks支持智能的物化视图。用户可以通过创建物化视图,预先计算生成预聚合表用于加速聚合类查询请求。StarRocks的物化视图能够在数据导入时自动完成汇聚,与原始表数据保持一致。并且在查询的时候,用户无需指定物化视图,StarRocks能够自动选择最优的物化视图来满足查询请求。
流批一体
StarRocks支持实时和批量两种数据导入方式,支持的数据源有Kafka、HDFS、本地文件,支持的数据格式有ORC、Parquet和CSV等,StarRocks可以实时消费Kafka数据来完成数据导入,保证数据不丢不重(exactly once)。StarRocks也可以从本地或者远程(HDFS)批量导入数据。
极简运维
StarRocks具有高可用易扩展的特性,元数据和数据都是多副本存储,并且集群中服务有热备,多实例部署,避免了单点故障。集群具有自愈能力,可弹性恢复,节点的宕机、下线、异常都不会影响StarRocks集群服务的整体稳定性。
StarRocks采用分布式架构,存储容量和计算能力可近乎线性水平扩展。StarRocks单集群的节点规模可扩展到数百节点,数据规模可达到10PB级别。 扩缩容期间无需停服,可以正常提供查询服务。 另外StarRocks中表模式热变更,可通过一条简单SQL命令动态地修改表的定义,例如增加列、减少列、新建物化视图等。同时,处于模式变更中的表也可也正常导入和查询数据。
StarRocks是一个自治的系统。节点的上下线,集群扩缩容都可通过一条简单的SQL命令来完成。
系统架构

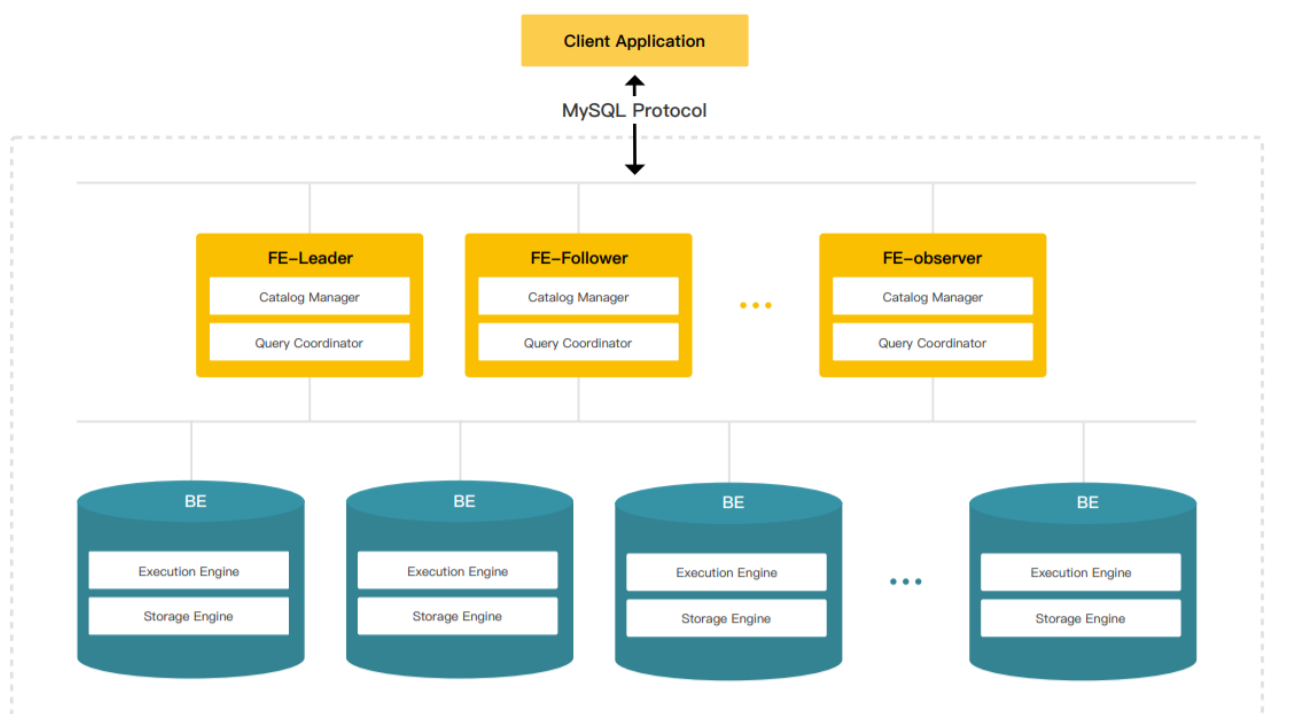
组件介绍
StarRocks集群由FE和BE构成, 可以使用MySQL客户端访问StarRocks集群。
FE(FrontEnd)
FE接收MySQL客户端的连接, 解析并执行SQL语句。
- 管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
- FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
- FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
- FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
- FE协调数据导入, 保证数据导入的一致性。
BE(BackEnd)
- BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
- BE受FE指导, 创建或删除子表。
- BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
- BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。
- BE后台执行compact任务, 减少查询时的读放大。
- 数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
其他组件
-
管理平台(StarRocks Manager), 管理工具,提供DorisDB集群管理、在线查询、故障查询、监控报警的可视化工具。
-
Hdfs Broker: StarRocks 中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。
StarRocks优势
极速SQL查询
- 全新的向量化执行引擎,亚秒级查询延时,单节点每秒可处理多达100亿行数据。
- 强大的MPP执行框架,支持星型模型和雪花模型,极致的Join性能。
- 综合查询速度比其他产品快10-100倍
- 查看性能测试报告
实时数据分析
- 新型列式存储引擎,支持大规模数据实时写入,秒级实时性保证。
- 支持业务指标实时聚合,加速实时多维数据分析。
- 新型读写并发管理模式,可同时高效处理数据读取和写入。
高并发查询
- 灵活的资源分配策略,每秒可支持高达1万以上的并发查询。
- 可高效支持数千用户同时进行数据分析。
极简运维
- 支持在大数据规模下进行在线弹性扩展,扩容不影响线上业务。集群可扩展至数百节点,PB量级数据。
集群运行高度自治化,故障自恢复,运维成本低。
国产核心软件
- 完全自主创新,全球领先。
- 更完善的本地化专家服务体系。
StarRocks VS ClickHouse
| 指标 | ClickHouse | StarRocks |
|---|---|---|
| MPP架构 | Scatter-Gather模式,聚合操作依赖单点完成,操作数据量大时有瓶颈 | 现代化MPP架构,可以实现多层聚合、大表Join |
| 架构 | 依赖ZooKeeper进行DDL和Replica同步 | 内置分布式协议进行元数据同步Master/Follower/Observer节点类型 |
| 事务性 | 100万以内原子性,DDL无事务保证 | 事务保证数据ACID |
| 数据规模 | 单集群 < 10PB | 单集群 < 10PB |
| 标准SQL的支持 | 不支持标准的SQL语言 | 支持,兼容Mysql协议 |
| 分布式Join | 不支持Join,仅支持大宽表模式 | 支持主流分布式Join,不仅支持大宽表模型,还支持星型和雪花模型 |
| 高并发查询 | 不支持高并发 | 支持高并发 |
| 外表 | 支持MySQL/Hive的表 | 外查MySQL/ES/Hive的表 |
| Exactly Once语义 | 不支持事务,无法保证数据写入不丢不重 | 支持事务,可实现数据不丢不重 |
| 集群扩容 | 扩容需人工操作,工作量巨大,且影响线上服务 | 扩容只需要迁移部分数据分片,系统自动完成,不影响线上服务 |
| 运维要求 | 依赖ZK,运维和维护成本高 | 不依赖外部系统,极简运维 |
| 成熟程度 | 高 | 中 |
使用场景
StarRocks可以满足企业级用户的多种分析需求,包括OLAP多维分析,定制报表,实时数据分析,Ad-hoc数据分析等。具体的业务场景包括:
适用场景
-
OLAP多维分析
-
实时数据分析
-
多用户高并发查询
-
Hadoop数仓加速
不适用场景
- StarRocks目前主要解决 PB 级别的数据量(如果高于 PB 级别,不推荐使用 StarRocks解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。
- 不适合做大规模的批处理(处理过程不会落盘,因此会占用内存)
哪些大厂在使用
- 小红书
- 58同城
- 贝壳
- 联想
- 好未来
- 猿辅导
- 中移物联网
性能测试
因资源限制,暂未进行实际的性能测试。以下测试报告均来源于官网(https://www.starrocks.com/zh-CN/blog/1.8)。
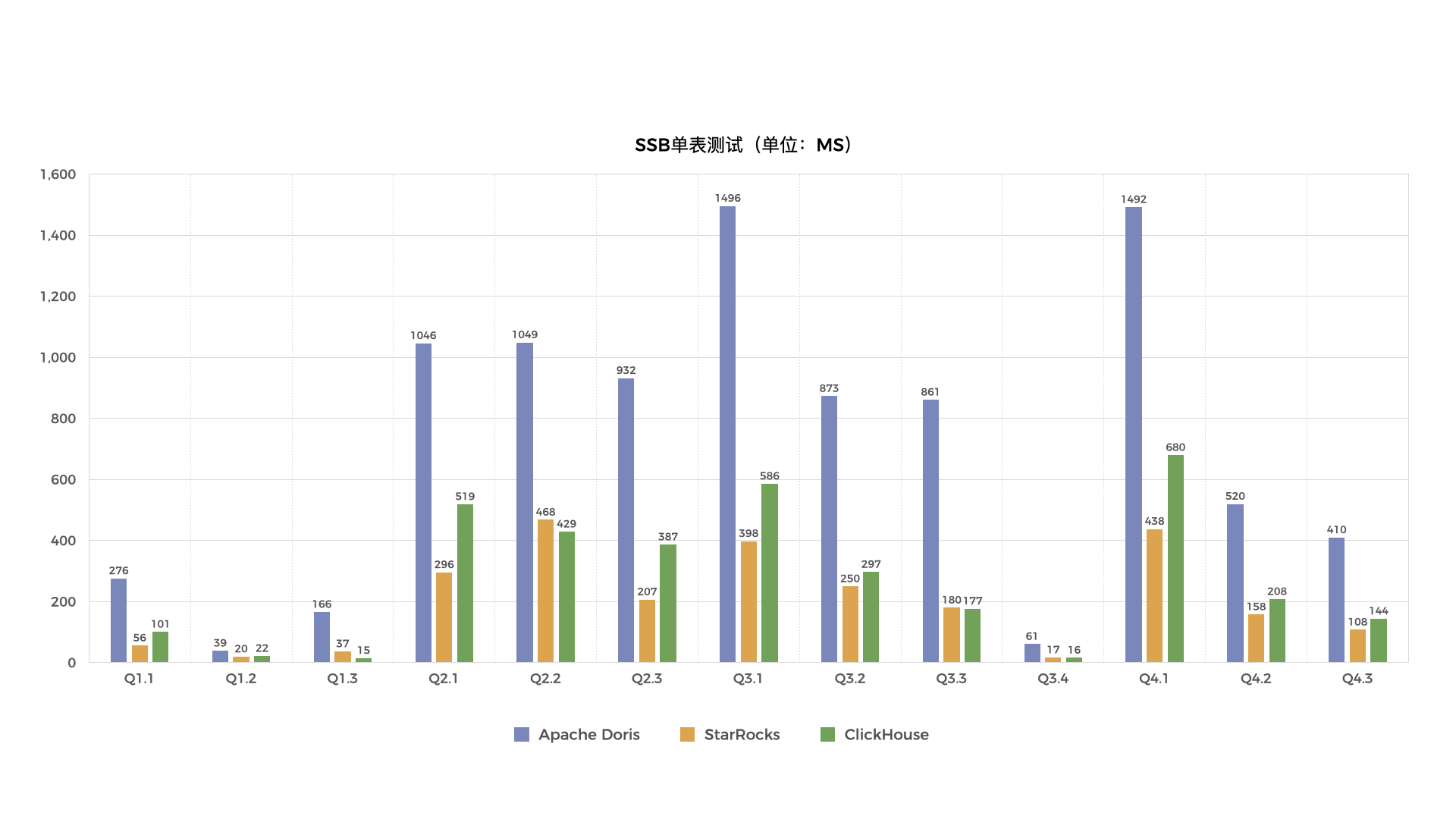
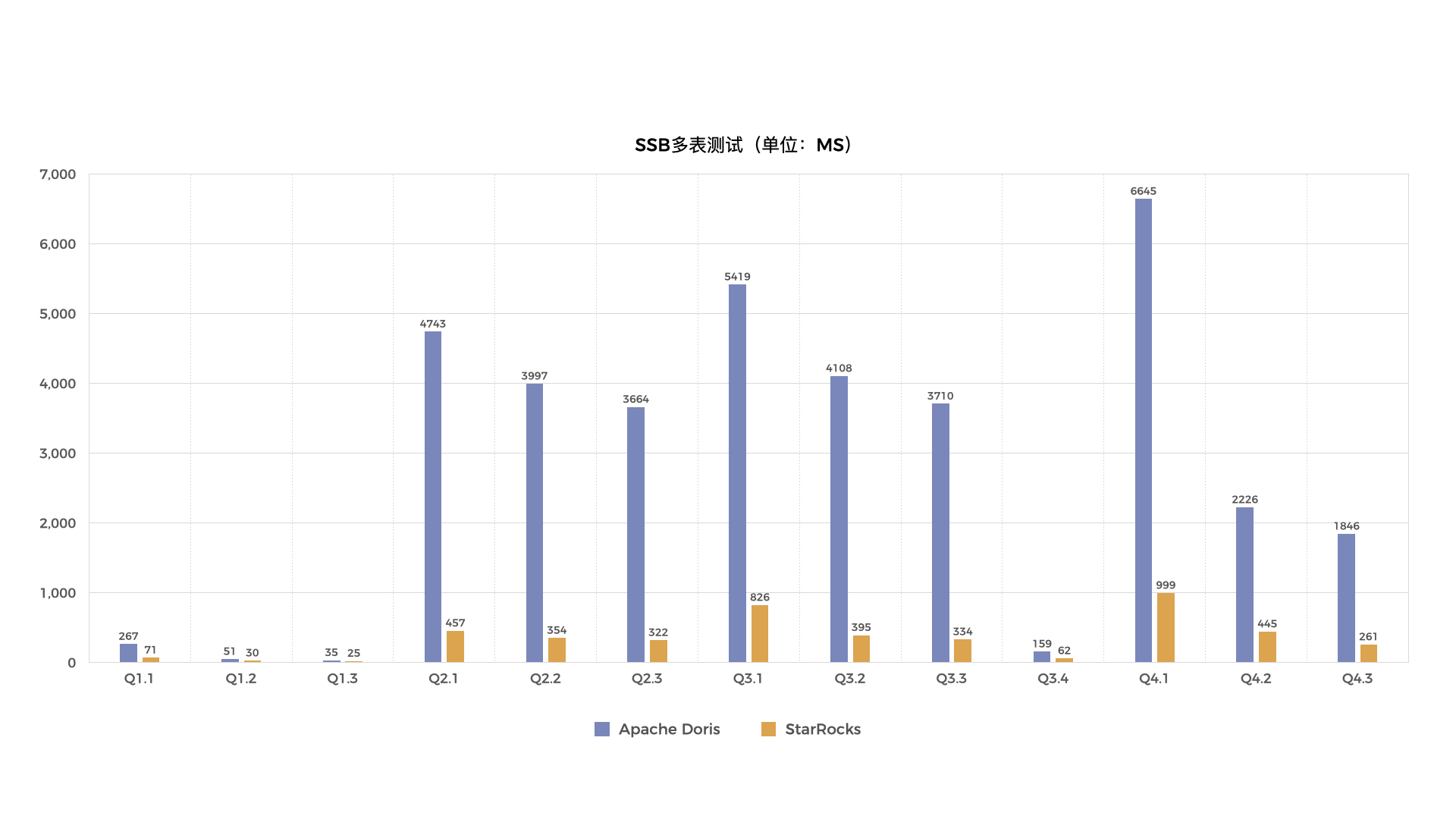
Star schema benchmark(以下简称SSB)是学术界和工业界广泛使用的一个星型模型测试集,通过这个测试集合可以方便的对比各种OLAP产品的基础性能指标。Clickhouse 通过改写SSB,将星型模型打平转化成宽表,改造成了一个单表测试benchmark。本报告记录了StarRocks、ApacheDoris和Clickhouse在SSB单表和多表数据集上进行了性能对比测试的结果。
测试环境
硬件环境:
| 机器 | 3台 阿里云主机 |
|---|---|
| CPU | 16coreIntel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHzcache size : 36608 KB |
| 内存 | 64GB |
| 网络带宽 | 10Gbits/s |
| 磁盘 | ESSD高效云盘 |
软件环境:
内核版本:Linux 3.10.0-1127.13.1.el7.x86_64
操作系统版本:CentOS Linux release 7.8.2003
软件版本:StarRocks 社区版 1.10,Aapche Doris 0.13,Clickhouse 20.13
测试数据
| 表名 | 行数 | 解释 |
|---|---|---|
| lineorder | 6亿 | SSB商品订单表 |
| customer | 300万 | SSB客户表 |
| part | 140万 | SSB 零部件表 |
| supplier | 20万 | SSB 供应商表 |
| dates | 2556 | 日期表 |
| lineorder_flat | 6亿 | SSB打平后的宽表 |
测试结论
测试结论如下:
- 在单表测试的13个查询中,Apache Doris耗时最长;有9个查询StarRocks查询速度最快,另外4个查询Clickhouse速度最快。
- 单表测试中,13个查询Clickhouse总耗时是StarRocks的1.33倍。
- 在多表测试的13个查询中,StarRocks平均比Apache Doris快6.8倍,部分查询快10倍以上。
表设计
稀疏索引
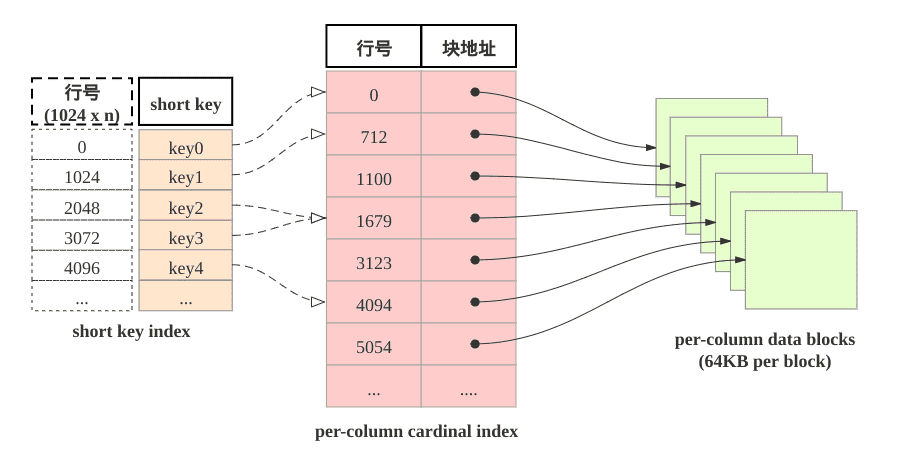
表中数据组织有主要由三部分构成:
- shortkey index表: 表中数据每1024行, 构成一个逻辑block。 每个逻辑block在shortkey index表中存储一项索引, 内容为表的维度列的前缀, 并且不超过36字节。 shortkey index为稀疏索引, 用数据行的维度列的前缀查找索引表, 可以确定该行数据所在逻辑块的起始行号。
- Per-column data block: 表中每一列数据按64KB分块存储, 数据块作为一个单位单独编码压缩, 也作为IO单位, 整体写回设备或者读出。
- Per-column cardinal index: 表中的每列数据有各自的行号索引表, 列的数据块和行号索引项一一对应, 索引项由数据块的起始行号和数据块的位置和长度信息构成, 用数据行的行号查找行号索引表, 可以获取包含该行号的数据块所在位置, 读取目标数据块后, 可以进一步查找数据。
由此可见, 查找维度列的前缀的查找过程为: 先查找shortkey index, 获得逻辑块的起始行号, 查找维度列的行号索引, 获得目标列的数据块, 读取数据块, 然后解压解码, 从数据块中找到维度列前缀对应的数据项。
加速数据处理
-
预先聚合
StarRocks支持聚合模型, 维度列取值相同数据行可合并一行, 合并后数据行的维度列取值不变, 指标列的取值为这些数据行的聚合结果, 用户需要给指标列指定聚合函数。 通过预先聚合, 可以加速聚合操作。
-
分区分桶
事实上StarRocks的表被划分成tablet, 每个tablet多副本冗余存储在BE上, BE和tablet的数量可以根据计算资源和数据规模而弹性伸缩。 查询时, 多台BE可并行地查找tablet快速获取数据。 此外, tablet的副本可复制和迁移, 增强了数据的可靠性, 避免了数据倾斜。 总之, 分区分桶保证了数据访问的高效性和稳定性。
-
RollUp表索引
shortkey index可加速数据查找, 然后shortkey index依赖维度列排列次序。 如果使用非前缀的维度列构造查找谓词, 则无法使用shortkey index。 用户可以为数据表创建若干RollUp表索引, RollUp表索引的数据组织和存储和数据表相同, 但RollUp表拥有自身的shortkey index。 用户创建RollUp表索引时, 可选择聚合的粒度, 列的数量, 维度列的次序; 使频繁使用的查询条件能够命中相应的RollUp表索引。
-
列级别的索引技术
Bloomfilter可快速判断数据块中不含所查找值, ZoneMap通过数据范围快速过滤待查找值, Bitmap索引可快速计算出枚举类型的列满足一定条件的行。
数据模型
-
明细模型
表中存在主键重复的数据行, 和摄入数据行一一对应, 用户可以召回所摄入的全部历史数据。
-
聚合模型
表中不存在主键重复的数据行, 摄入的主键重复的数据行合并为一行, 这些数据行的指标列通过聚合函数合并, 用户可以召回所摄入的全部历史数据的累积结果, 但无法召回全部历史数据。
-
更新模型&主键模型
聚合模型的特殊情形, 主键满足唯一性约束, 最近导入的数据行, 替换掉其他主键重复的数据行。 相当于在聚合模型中, 为数据表的指标列指定的聚合函数为REPLACE, REPLACE函数返回一组数据中的最新数据。
需要注意:
- 建表语句, 排序列的定义必须出现在指标列定义之前。
- 排序列在建表语句中的出现次序为数据行的多重排序的次序。
- 排序键的稀疏索引(Shortkey Index)会选择排序键的若干前缀列。
下载安装部署
StarRocks的集群部署分为两种模式,第一种是使用命令部署,第二种是使用 StarRocksManager 自动化部署。自动部署的版本只需要在页面上简单进行配置、选择、输入后批量完成,并且包含Supervisor进程管理、滚动升级、备份、回滚等功能。因 StarRocksManager并未开源,因此我们只能使用命令部署。
生产环境使用官方推荐配置:BE推荐16核64GB以上(StarRocks的元数据都在内存中保存),FE推荐8核16GB以上
下载地址:
https://www.starrocks.com/zh-CN/download/request-download/4
此部分文档申请到虚机后进行完善。
服务器配置
| IP | host | 配置 | 部署 |
|---|---|---|---|
| 192.168.130.178 | fe1 | 4C16G | FE主节点 |
| 192.168.130.183 | be1 | 4C8G | BE节点 |
| 192.168.130.36 | be2 | 4C8G | BE节点 |
| 192.168.130.149 | be3 | 4C8G | BE节点 |
下载社区版最新版本:StarRocks-1.19.1,因资源限制(使用4台虚机),FE采取单实例部署,BE部署三个实例。
FE单实例部署
# 修改fe配置
cd StarRocks-1.19.1/fe
# 配置文件conf/fe.conf
# 根据FE内存大小调整 -Xmx4096m,为了避免GC建议16G以上,StarRocks的元数据都在内存中保存。
# 创建元数据目录
mkdir -p meta
# 启动进程
bin/start_fe.sh --daemon
# 使用浏览器访问8030端口, 打开StarRocks的WebUI, 用户名为root, 密码为空
StarRocks UI
http://192.168.130.178:8030/ 打开StarRocks的WebUI,,用户名为root, 密码为空。
使用MySQL客户端访问FE
第一步: 安装mysql客户端(如果已经安装,可忽略此步):
Ubuntu:sudo apt-get install mysql-client
Centos:sudo yum install mysql-client
wget http://repo.mysql.com/mysql57-community-release-sles12.rpm
rpm -ivh mysql57-community-release-sles12.rpm
# 安装mysql
yum install mysql-server
# 启动mysql
service mysqld start
第二步: 使用mysql客户端连接:
mysql -h 127.0.0.1 -P9030 -uroot
注意:这里默认root用户密码为空,端口为fe/conf/fe.conf中的query_port配置项,默认为9030
第三步: 查看FE状态:
MySQL [(none)]> SHOW PROC '/frontends'\G
*************************** 1. row ***************************
Name: 192.168.130.178_9010_1636811945380
IP: 192.168.130.178
HostName: fe1
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 985620692
Join: true
Alive: true
ReplayedJournalId: 43507
LastHeartbeat: 2021-11-15 14:41:48
IsHelper: true
ErrMsg:
1 row in set (0.05 sec)
Role为FOLLOWER说明这是一个能参与选主的FE;IsMaster为true,说明该FE当前为主节点。
如果MySQL客户端连接不成功,请查看log/fe.warn.log日志文件,确认问题。由于是初次启动,如果在操作过程中遇到任何意外问题,都可以删除并重新创建FE的元数据目录,再从头开始操作。
BE部署
BE的基本配置
BE的配置文件为StarRocks-1.19.1/be/conf/be.conf,默认配置已经足以启动集群,不建议初尝用户修改配置, 有经验的用户可以查看手册的系统配置章节,为生产环境定制配置。 为了让用户更好的理解集群的工作原理, 此处只列出基础配置。
192.168.130.183
# 修改fe配置
cd StarRocks-1.19.1/be
# 配置文件conf/fe.conf
# 调整BE参数,默认配置已经足以启动集群,暂不做调整。
# 创建元数据目录
mkdir -p storage
# 通过mysql客户端添加BE节点。
# 这里IP地址为和priority_networks设置匹配的IP,portheartbeat_service_port,默认为9050
mysql> ALTER SYSTEM ADD BACKEND "be1:9050";
# 启动be
bin/start_be.sh --daemon
添加BE节点如出现错误,需要删除BE节点,应用下列命令:
alter system decommission backend "be_host:be_heartbeat_service_port";alter system dropp backend "be_host:be_heartbeat_service_port";
具体参考扩容缩容。
# 查看防火墙状态
[root@be1 be]# systemctl status firewalld
# 如已开启,需关闭防火墙,防止网络不通,导致BE和FE无法连接
[root@be1 be]# systemctl stop firewalld
第四步: 查看BE状态, 确认BE就绪。同样步骤添加另外两个BE节点,mysql客户端中执行
MySQL [(none)]> SHOW PROC '/backends' \G;
*************************** 1. row ***************************
BackendId: 163038
Cluster: default_cluster
IP: 192.168.130.183
HostName: be1
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2021-11-21 13:56:47
LastHeartbeat: 2021-11-21 14:58:35
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 5
DataUsedCapacity: .000
AvailCapacity: 33.451 GB
TotalCapacity: 36.974 GB
UsedPct: 9.53 %
MaxDiskUsedPct: 9.53 %
ErrMsg:
Version: 1.19.1-65e87c3
Status: {"lastSuccessReportTabletsTime":"2021-11-21 14:57:48"}
DataTotalCapacity: 33.451 GB
DataUsedPct: 0.00 %
*************************** 2. row ***************************
BackendId: 163066
Cluster: default_cluster
IP: 192.168.130.36
HostName: be2
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2021-11-21 14:56:34
LastHeartbeat: 2021-11-21 14:58:35
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 5
DataUsedCapacity: .000
AvailCapacity: 33.452 GB
TotalCapacity: 36.974 GB
UsedPct: 9.53 %
MaxDiskUsedPct: 9.53 %
ErrMsg:
Version: 1.19.1-65e87c3
Status: {"lastSuccessReportTabletsTime":"2021-11-21 14:58:35"}
DataTotalCapacity: 33.452 GB
DataUsedPct: 0.00 %
*************************** 3. row ***************************
BackendId: 163072
Cluster: default_cluster
IP: 192.168.130.149
HostName: be3
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2021-11-21 14:58:15
LastHeartbeat: 2021-11-21 14:58:35
Alive: true
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 3
DataUsedCapacity: .000
AvailCapacity: 33.521 GB
TotalCapacity: 36.974 GB
UsedPct: 9.34 %
MaxDiskUsedPct: 9.34 %
ErrMsg:
Version: 1.19.1-65e87c3
Status: {"lastSuccessReportTabletsTime":"2021-11-21 14:58:16"}
DataTotalCapacity: 33.521 GB
DataUsedPct: 0.00 %
如果isAlive为true,则说明BE正常接入集群。如果BE没有正常接入集群,请查看log目录下的be.WARNING日志文件确定原因。
至此,安装完成。
参数设置
- Swappiness
关闭交换区,消除交换内存到虚拟内存时对性能的扰动。
echo 0 | sudo tee /proc/sys/vm/swappiness
- Compaction相关
当使用聚合表或更新模型,导入数据比较快的时候,可在配置文件 be.conf 中修改下列参数以加速compaction。
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2
- 并行度
在客户端执行命令,修改StarRocks的并行度(类似clickhouse set max_threads= 8)。并行度可以设置为当前机器CPU核数的一半。
set global parallel_fragment_exec_instance_num = 8;
使用MySQL客户端访问StarRocks
Root用户登录
使用MySQL客户端连接某一个FE实例的query_port(9030), StarRocks内置root用户,密码默认为空:
mysql -h fe_host -P9030 -u root
清理环境:
mysql > drop database if exists example_db;
mysql > drop user test;
创建新用户
通过下面的命令创建一个普通用户:
mysql > create user 'test_xxx' identified by 'xxx123456';
创建数据库
StarRocks中root账户才有权建立数据库,使用root用户登录,建立example_db数据库:
mysql > create database test_xxx_db;
数据库创建完成之后,可以通过show databases查看数据库信息:
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| _statistics_ |
| information_schema |
| test_xxx_db |
+--------------------+
3 rows in set (0.00 sec)
information_schema是为了兼容mysql协议而存在,实际中信息可能不是很准确,所以关于具体数据库的信息建议通过直接查询相应数据库而获得。
账户授权
example_db创建完成之后,可以通过root账户example_db读写权限授权给test账户,授权之后采用test账户登录就可以操作example_db数据库了:
mysql > grant all on test_xxx_db to test_xxx;
退出root账户,使用test登录StarRocks集群:
mysql > exit
mysql -h 127.0.0.1 -P9030 -utest_xxx -pxxx123456
建表
StarRocks支持支持单分区和复合分区两种建表方式。
在复合分区中:
- 第一级称为Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
- 第二级称为Distribution,即分桶。用户可以指定某几个维度列(或不指定,即所有KEY列)以及桶数对数据进行HASH分布。
以下场景推荐使用复合分区:
- 有时间维度或类似带有有序值的维度:可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送DELETE语句进行数据删除。
- 解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做HASH分布。
下面分别演示两种分区的建表语句:
- 首先切换数据库:mysql > use test_xxx_db;
- 建立单分区表建立一个名字为table1的逻辑表。使用全hash分桶,分桶列为siteid,桶数为10。这个表的schema如下:
- siteid:类型是INT(4字节), 默认值为10
- city_code:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, StarRocks内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)。这里采用了聚合模型,除此之外StarRocks还支持明细模型和更新模型,具体参考数据模型介绍。
建表语句如下:
mysql >
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
- 建立复合分区表
建立一个名字为table2的逻辑表。这个表的 schema 如下:
- event_day:类型是DATE,无默认值
- siteid:类型是INT(4字节), 默认值为10
- city_code:类型是SMALLINT(2字节)
- username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
- pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, StarRocks 内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
我们使用event_day列作为分区列,建立3个分区: p1, p2, p3
- p1:范围为 [最小值, 2017-06-30)
- p2:范围为 [2017-06-30, 2017-07-31)
- p3:范围为 [2017-07-31, 2017-08-31)
每个分区使用siteid进行哈希分桶,桶数为10。
建表语句如下:
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ('2017-06-30'),
PARTITION p2 VALUES LESS THAN ('2017-07-31'),
PARTITION p3 VALUES LESS THAN ('2017-08-31')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
表建完之后,可以查看example_db中表的信息:
mysql> show tables;
+-------------------------+
| Tables_in_example_db |
+-------------------------+
| table1 |
| table2 |
+-------------------------+
2 rows in set (0.01 sec)
<br/>
mysql> desc table1;
+----------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-------+---------+-------+
| siteid | int(11) | Yes | true | 10 | |
| citycode | smallint(6) | Yes | true | N/A | |
| username | varchar(32) | Yes | true | | |
| pv | bigint(20) | Yes | false | 0 | SUM |
+----------+-------------+------+-------+---------+-------+
4 rows in set (0.00 sec)
<br/>
mysql> desc table2;
+-----------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-------+---------+-------+
| event_day | date | Yes | true | N/A | |
| siteid | int(11) | Yes | true | 10 | |
| citycode | smallint(6) | Yes | true | N/A | |
| username | varchar(32) | Yes | true | | |
| pv | bigint(20) | Yes | false | 0 | SUM |
+-----------+-------------+------+-------+---------+-------+
5 rows in set (0.00 sec)
MySQL [(none)]> use test_xxx_db;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MySQL [test_xxx_db]> insert into table1 values(1,3708,'zhaop',0);
Query OK, 1 row affected (0.20 sec)
{'label':'insert_d7aee4d4-52a4-11ec-be98-fa163e7a663b', 'status':'VISIBLE', 'txnId':'2005'}
MySQL [test_xxx_db]> select * from table1;
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 1 | 3708 | zhaop | 0 |
+--------+----------+----------+------+
1 row in set (0.03 sec)
导入数据
curl --location-trusted -u test_xxx:xxx123456 -T table1_data -H "label: table1_20211121" \
-H "column_separator:," \
http://127.0.0.1:8030/api/test_xxx_db/table1/_stream_load
## 报错
curl: Can't open 'table1_data'!
curl: try 'curl --help' or 'curl --manual' for more information
问题
1.修改系统文件限制
2.执行sql报错
MySQL [test_xxx_db]> select * from table1;
ERROR 1064 (HY000): Could not initialize class com.starrocks.rpc.BackendServiceProxy
后台日志:
2021-11-21 16:03:49,835 WARN (starrocks-mysql-nio-pool-31|379) [StmtExecutor.execute():456] execute Exception, sql select * from table1
java.lang.NoClassDefFoundError: Could not initialize class com.starrocks.rpc.BackendServiceProxy
at com.starrocks.qe.Coordinator$BackendExecState.execRemoteFragmentAsync(Coordinator.java:1695) ~[starrocks-fe.jar:?]
at com.starrocks.qe.Coordinator.exec(Coordinator.java:522) ~[starrocks-fe.jar:?]
at com.starrocks.qe.StmtExecutor.handleQueryStmt(StmtExecutor.java:771) ~[starrocks-fe.jar:?]
at com.starrocks.qe.StmtExecutor.execute(StmtExecutor.java:371) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.handleQuery(ConnectProcessor.java:248) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.dispatch(ConnectProcessor.java:397) ~[starrocks-fe.jar:?]
at com.starrocks.qe.ConnectProcessor.processOnce(ConnectProcessor.java:633) ~[starrocks-fe.jar:?]
at com.starrocks.mysql.nio.ReadListener.lambda$handleEvent$480(ReadListener.java:54) ~[starrocks-fe.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_312]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_312]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_312]
解决:openjdk改为
[root@fe1 jre-1.8.0-openjdk]# java -version
openjdk version "1.8.0_312"
OpenJDK Runtime Environment (build 1.8.0_312-b07)
OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
# 修改为
[root@fe1 java]# java -version
java version "1.8.0_192"
Java(TM) SE Runtime Environment (build 1.8.0_192-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mod
- BE启动失败,java.net.NoRouteToHostException: No route to host (Host unreachable)
# 报错信息
W1128 23:13:56.493264 24083 utils.cpp:90] Fail to get master client from cache. host= port=0 code=THRIFT_RPC_ERROR
# 查看防火墙状态
[root@be1 be]# systemctl status firewalld
# 如已开启,需关闭防火墙,防止网络不通,导致BE和FE无法连接
[root@be1 be]# systemctl stop firewalld

 浙公网安备 33010602011771号
浙公网安备 33010602011771号