手把手教你使用Git管理你的软件代码
什么是分布式版本控制系统?Git有哪些常用命令?什么是仓库?Git的操作区域包括哪些?Git有哪些常用对象(object)?git rebase和git merge的区别是什么?git reset,git revert和git checkout的区别是什么?git submodule和git subtree的区别又是什么?git push和git push -u的区别又是什么?.gitignore如何使用?Git跟GitHub有没有关系?如何推送自己代码到GitHub?怎么在Gitee建立GitHub的镜像?pull request跟git pull有没有关系?本文将对以上问题进行阐述。
目录
1. Git概述
1.1 大神Linus Torvalds简介
2. 创建第一个Git仓库(Repository)
3. Git工作原理简介
3.1 Git操作区域
3.2 Git对象(数据结构)
3.3 Git命令
3.4 Git flow
4. Git进阶示例
4.1 git merge – fast forward
4.2 git reset和git revert - 删除某个commit
4.3 git checkout,git revert和git reset
4.4 git merge - 手动解决冲突
4.5 .gitignore – 忽略某些文件的追踪
4.6 git push - 把本地代码推送到远程服务器
4.7 git rebase – 团队协作
4.8 git merge和git rebase区别
4.9 git submodule - 引用第三方模块
4.10 git subtree – 包含第三方模块
4.11 git tag – 发布软件版本
4.12 将GitHub仓库导入到Gitee – 解决GitHub访问速度慢问题
4.13 pull request – 贡献自己的代码
5. 常用Git命令说明
5.1 git config
5.2 git init
5.3 git clone
5.4 git add
5.5 git commit
5.6 git diff
5.7 git reset
5.8 git status
5.9 git rm
5.10 git log
5.11 git show
5.12 git tag
5.13 git branch
5.14 git checkout
5.15 git merge
5.16 git rebase
5.17 git remote
5.18 git push
5.19 git fetch
5.20 git pull
5.21 git revert
5.22 git restore
5.23 git reflog
5.24 git stash
5.25 git submodule
5.26 git subtree
5.27 git cherry-pick
5.28 git grep
5.29 git apply
5.30 git cat-file
5.31 git ls-files
5.32 git merge-file
6. Git重要术语列表
1. Git概述
当我们开发软件的时候,会创建很多源代码文件,这些源代码文件一般会放在一个目录里面,这个就是我们的code base,对这些源代码文件,我们每天都在迭代开发,因此需要对其进行管理,这样我们就能知道这些源代码文件的历史,比如前天改了什么,今天又改了什么。一个人自己写代码对软件开发管理感觉还不深,如果是多个人一起开发一个项目,这个时候怎么保证每个人的修改别人可以获取到而又不影响到其他人的代码,这就需要软件版本管理工具或者软件,Git就是这样一款软件。
Git是一款分布式版本控制系统(Distributed Version Control System),它可以用来追踪任何文件的修改,协调多个开发者之间的工作,Git具有速度快,数据完整性校验,分布式开发,以及支持非线性工作流等众多特点。Git最初由Linus Torvalds创作(Linus Torvalds还创作了大名鼎鼎的Linux操作系统,我们后面会对Linus进行一个简单介绍,以示对大神的敬意),它是一款开源的免费的GPL2.0版权的软件。Git的官网地址是:https://git-scm.com/,scm表示source code management,跟前面提及的版本控制系统一个意思。
1.1 大神Linus Torvalds简介
前面说过Git是由Linus Torvalds创作的,我觉得有必要对Linus Torvalds进行一个简单介绍,以让更多的人了解这个人(不感兴趣的人可以直接跳过这一节!)。Linus于1969年12月28号出生于芬兰,他11岁开始接触编程,没过多久,就会直接写机器代码去操作8-bit CPU(iini评论:从这件事就可以看出,Linus非同寻常,我们现在很多程序员不要说写汇编代码,就是读汇编代码都是很大问题,更何况直接写机器码;这件事也侧面告诉我们,作为一个顶级的OS开发程序员,汇编语言功底是少不了的)。Linus上中学的时候就接触了操作系统,并尝试对其进行改进。1988年,Linus被赫尔辛基大学录取,然后在1996年硕士毕业,他的硕士毕业论文就是:Linux,一个可移植的操作系统(iini评论:惭愧啊,感觉我硕士毕业的时候,脑子基本上还是一团浆糊)。Linux原型机于1991年第一次发布,这个原型机只花费了Linus几个月的时间,并没有大家想象的那么复杂(iini评论:这个也侧面反应出Linux kernel有可能没有大家想象得那么难)。Linux 1.0版本则是在1994年发布的,中间隔了2年多时间。Linux原型机发布之后,一开始采用的人也并不多,直到它开始支持GUI(X Window System)以及SMP,Linux才开始变得慢慢流行起来。大学毕业之后,Linus就去了美国,然后就一直在OSDL和Linux Foundation工作直到现在。一开始Linux是没有版本控制系统的,所有的版本管理工作都是由Linus手工完成的,由于Linux变得越来越大,贡献者也越来越多,如何自动和高效地去管理Linux的版本,是摆在Linus面前的一项课题。一开始Linus使用第三方的私有版本控制系统去管理Linux,后来出于种种原因无法继续,于是Linus在2005年创作出了Git以管理Linux版本。创作出Git之后,Linus自己都感叹:没想到在自己36岁之际还能做出一点成绩出来(其实有人统计过,大部分大师的高光时刻都是在40岁之前的几年,比如爱因斯坦26岁提出狭义相对论,36岁提出广义相对论,目前看起来Linus也是符合这个规律的)。
我觉得这里有必要说说Linux和Git两个名字的由来,大家由此也可以看出Linus本人以及他周围环境的一些特质,Linux是从Unix发展过来的,在开发Linux过程中,其实Linus没有想好用什么名字,他一开始给这个项目取的名字是:Freax,意思是Free/Freak uniX,即自由怪异的Unix,当他把这个项目上传到一个ftp服务器以供其他人下载的时候,FTP管理员觉得Freax这个名字不好,在没有咨询Linus前提下,直接把这个项目的名字改为"linux",意思是Linus Unix,这个名字后来得到了Linus的同意,并诠释为:Linux Is Not UniX,这个应该是向GNU致敬(GNU Not Unix)(iini评论:iini这个id其实也是在向Linux和GNU致敬哦,大家猜猜看它是什么意思)。如果Linux这个名字取得有点乌龙的感觉,那么Git这个名字那就是Linus蓄谋已久。Git英文本义是"饭桶,蠢货",Linus本意是找一个三个字母组合的单词,而且不属于Unix的命令关键字,在这个前提下,可选的单词就不多,Git被选上也是情理之中的(iini评论:在英语中,越是重要而常见的意义,它对应的单词越简单,比如go,do,三个字母组成的单词他们在英语中的地位是很重要的,建议大家去理一理这些单词,说不定对你英语学习会有一个很大的帮助),再加上Linus认为自己是一个非常自我的人,正好可以用Git的英文原意来自嘲一下自己的产品:愚蠢的信息追踪系统。从Linux和Git两者的名字,可以看出Linus骨子里的那种不走寻常路的信念,以及周围环境对他的包容和理解。(iini评论:古今中外,能不能取一个好名字是一个好作品或者好作者的重要标准,大家看看这些耳熟能详的名字:如意金箍棒,降龙十八掌,阿Q,Java,Python,一听就感觉是大师之作啊)
Linus是一个自由软件的爱好者和拥护者,一生都致力于自由软件的创作和推广工作。自从Android采用Linux内核后,Linux就成为世界上最流行的操作系统,也就是说Linux的装机量已经超过了Windows和苹果的MacOS,Windows创始人Bill Gates是世界首富,苹果公司是全球第一市值公司,而Linus自始至终都是一个工程师,因为他的操作系统是免费的。Linus创作的第二个产品Git,在此基础上创立的公司有GitHub/Gitlab/Bitbucket/Gitee等,拿GitHub为例,微软收购他的时候价格为75亿美元,但是GitHub跟Linus没有任何关系,Linus还是在认认真真地做他的工程师。在中国,当我们谈自主知识产权操作系统的时候,大部分都是在讲Linux二次开发,像倪光南院士目前很大一部分工作就是在推广Linux操作系统。
11岁开始编程,然后一辈子专注在编程,一生只做一件事:Linux,顺带搞出一个副产品:Git,这就是Linus。(iini评论:想想我们一生,想做的事情太多了,不过到最后,我们大部分人回顾自己一生:生于哪年,卒于哪年,妻或者夫是谁,小孩是谁,仅此而已)
以上纯粹是节外生枝,下面回归正题。
2. 创建第一个Git仓库(Repository)
现在我们开始创建自己的第一个Git仓库。
首先前往Git官网下载Git工具:https://git-scm.com/downloads,安装成功后,可以在cmd或者其他shell(比如Bash)中输入如下命令来验证是否安装成功:
git --version

注:如果Git官网下载很慢的话,可以自行去其他地方下载Git,或者使用choco安装(choco install git)。
本文将基于Windows讲解Git,所有命令交互通过CMD来输入,但相关命令可以直接运行在Linux或者MacOS的Bash中。
为了让后面的讲解更直观一些,这里我们以一个基于Zephyr的C语言工程(hello_world)为例来说明。大家对Zephyr不熟也没关系的,你就把它当成一个目录下包含了几个文件,仅此而已。这个工程代码获取链接为:https://github.com/zephyrproject-rtos/zephyr/tree/main/samples/hello_world,将其下载下来(大家可以一个文件一个文件复制粘贴下来),放在自己的目录下:(注:如果GitHub访问不了,请多试几次。如果还是不行,请访问https://gitee.com/minhua_ai/sdk-zephyr/tree/main/samples/hello_world这个镜像网站获取相关代码)
上面这个工程目前还没有任何版本控制功能,它目前就是一个纯粹的源代码文件集,即code base,大家如果去修改src目录下面的main.c,是没法记录下来历史的,为此我们需要Git来完成这件事。
打开cmd,进入上面目录,然后依次执行下面三条命令:
git init git add . git commit -m "my first Git repo"

如果你是第一次跑Git,那么最后一条commit指令会报如下错:

请按照上面的英文提示,添加自己的用户名和邮箱,比如我是这么做的(注:下面是我的邮箱和用户名,请换成你自己的邮箱和用户名,邮箱选择一个你在用的即可,用户名选择你喜欢的即可):
git config --global user.email "aimh@qq.com" git config --global user.name "Kevin Ai"
然后再次执行git commit -m "my first Git repo",就可以了。
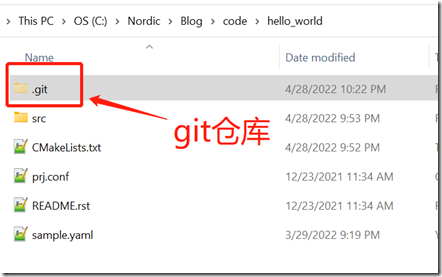
上面三条命令成功执行后,我们的Git仓库就创建成功了。Git仓库在物理上就是下面的.git目录:
点进去,我们可以看到:
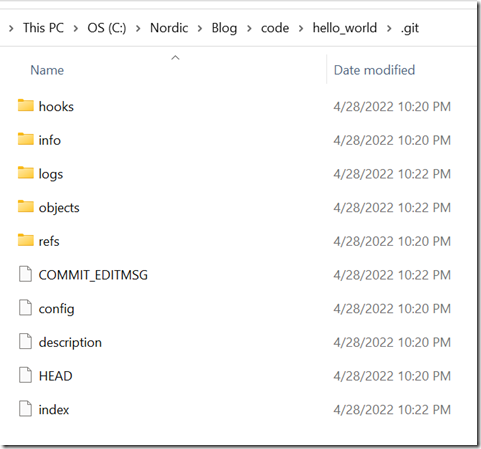
大家可以把这个目录以及目录里面的文件都点进去看看(文件通过Notepad++就可以查看),以加深对Git仓库的印象和了解。从这个目录我们可以看到如下名字:HEAD,index,refs,head,tag,object,commit,pack等,这些都是Git非常重要的术语,我们后面会对其进行一一阐述。
仓库(Repository,简写Repo),可以看成是一个本地数据库,Git的所有命令都是对这个数据库进行各种操作。比如前面的"git init"可以看作是创建这个数据库,而"git add"可以看作是把你当前工作目录下所有的文件添加到这个数据库,而"git commit"就是提交本次操作,形成一个版本或者历史记录。有人会问,我们工作目录下的所有文件都在Git仓库哪里?怎么找不到?其实Git仓库的实际数据都放在objects目录下,我们工作目录下的所有文件都转成了BLOB对象存在objects目录下,这个后面再细讲。
在我们成功执行"git commit"后,cmd会有回显信息,里面会提到"master",我们可以先在CMD中输入如下命令:
git branch
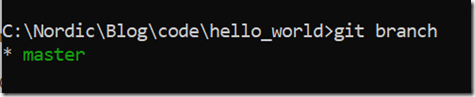
可以看出,CMD也输出master。"git branch"表示查看当前仓库中包含哪些分支(branch),branch英文原意就是树枝,"git branch"返回"master",告诉你目前仓库只有一个master树枝,即主干(trunk),这个就是Git仓库初始化后的状态:只有一个主分支,这个主分支默认名字是master。这里强调一下,主分支的默认名字是可以改的,大家可以使用
git config --global init.defaultBranch main
就可以把默认分支的名字改成main了,实际上GitHub这个第三方托管平台已经这么做了,在GitHub创建Git仓库,默认分支名就是main;还有的程序员把这个默认分支名改为trunk,这都是可以的。
我们现在跟国际接轨,也把我们的默认分支名改为main,大家执行"git config --global init.defaultBranch main"即可。我们现在把刚才创建的仓库删掉,怎么删掉仓库?直接把.git目录删掉即可。删完之后,我们再执行
git init git add . git commit -m "my first Git repo" git branch
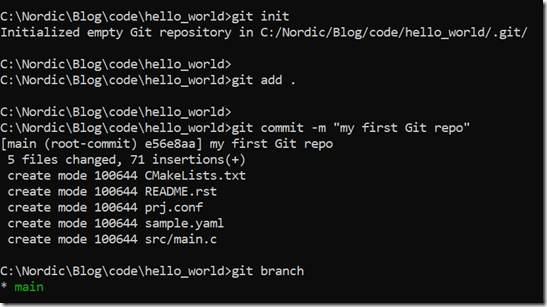
可以看出,主分支名字已改成main了。
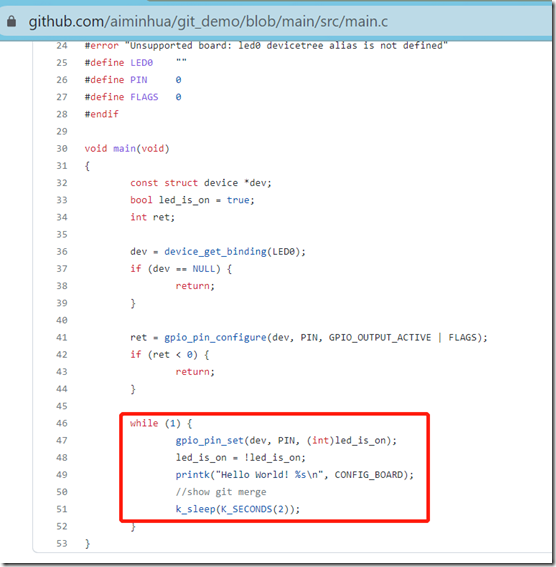
我们打开src/main.c,然后修改这个文件,main函数变成:
void main(void) { while(1) { printk("Hello World! %s\n", CONFIG_BOARD); k_sleep(K_SECONDS(1)); } }
我们在CMD输入如下命令以查看Git的最新状态
git status
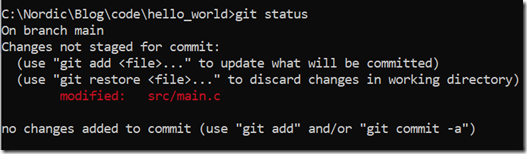
日志提示你:main.c文件已修改(注意:日志中还出现了not staged for commit字样,以及git add字样,后面解释他们的意思),我们可以输入如下命令以查看具体的修改:
git diff

删除了什么(-表示删除),插入了什么(+表示插入),一目了然。
然后我们把相应的修改提交到仓库。提交到仓库之前,我们需要一个缓冲区,即先把修改提交到缓冲区,然后再提交到仓库(数据库),这个缓冲区在Git中称为stage或者index,如何把修改添加到缓冲区?根据上面git status的日志提示,大家应该也猜到了:git add,我们使用如下指令将所有修改都添加到stage(.表示所有修改,所有修改不仅指所有的修改文件,又指所有新添加的文件和删除的文件)
git add .
这样所有修改都添加到stage了,然后我们提交修改,输入如下指令:
git commit –m "Changed main() to a print loop"
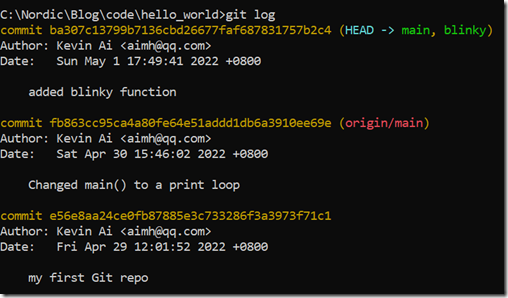
加上第一次创建仓库时的提交,到目前为止我们就有2次提交了,我们查看一下git历史
git log
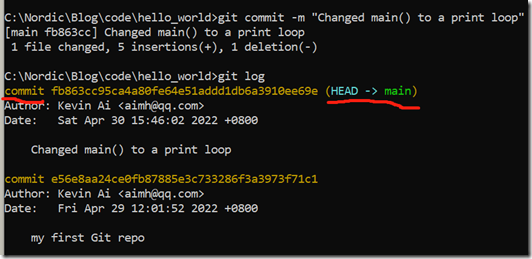
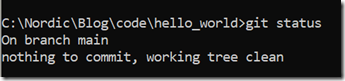
这个时候,你再输入git status,我们将得到如下日志(请大家仔细看下面的日志,体会里面每句话的意义):
现在hello_world已经可以跑起来了,代码也完成了,我们再添加一个新功能:把一个板子上的LED灯循环点亮,即Blinky程序,为此我们再新建一个分支(branch):blinky,大家使用如下命令新建一个分支:
git branch blinky
这样一个新的分支:blinky就创建成功了,我们可以通过git branch查看目前仓库包含哪几个分支:
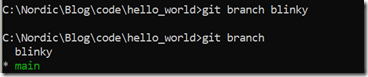
大家可以看到当前仓库包含两个分支:main和blinky,main左边的*表示当前分支是main,如前所述,我们现在想在新分支blinky上开发,以验证blinky程序能否正常运行,为此,我们需要先切换到blinky分支,然后再在blinky分支上进行开发,切换到blinky分支的命令为:
git checkout blinky
然后我们通过git branch来验证切换是否成功,日志如下所示:
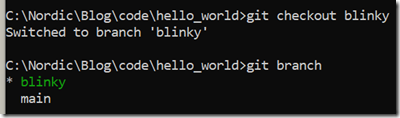
现在我们已经在blinky分支上,然后我们把blinky代码加上去,Blinky程序代码获取链接为:https://github.com/zephyrproject-rtos/zephyr/tree/main/samples/basic/blinky(注:如果GitHub访问不了,请多试几次。如果还是不行,请访问https://gitee.com/minhua_ai/sdk-zephyr/tree/main/samples/basic/blinky这个镜像网站获取相关代码),大家只要把src/main.c和prj.conf两个文件下载下来,然后直接替换我们本地的同名文件,整个blinky程序就算开发结束了。我们可以用git status和git diff查看一下我们的修改:
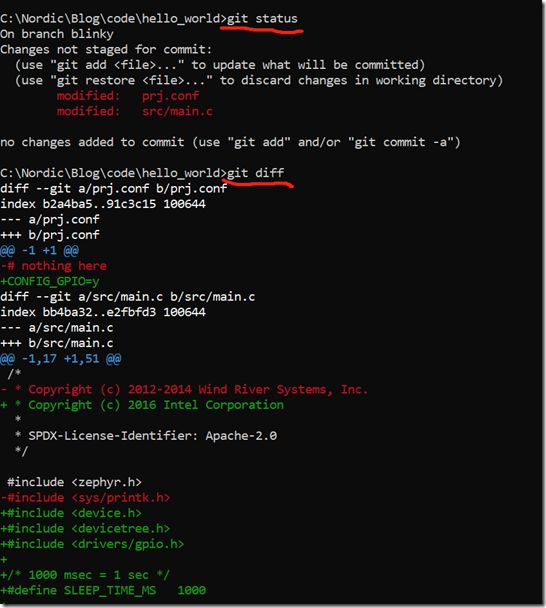
提示:按空格键继续查看内容,按字母q键退出内容查看。空格键和字母q键是两个常用的快捷键,适用范围非常广,大家一定要记住他们的用法。
然后我们提交此次修改,即输入
git add . git commit –m "added blinky function"
至此我们两个分支的内容都开发结束了,一个是hello_world的输出,一个是点亮LED灯,我们可以通过git checkout来回切换main和blinky两个分支,看一下src/main.c的内容是不是随着git checkout切换而跟着变化,比如:
git checkout main
这个时候src/main.c的内容又会切到之前的hello_world内容。
我们可以通过git log查看一下每个分支的历史,以加深大家对分支和历史的了解:

从上面可以看出,使用Git管理代码,根本不需要服务器,特别适合一个人自己开发,自己管理自己的代码。
如果这个项目需要多个人一起协同开发,那么就必须建一个服务器,这样大家可以通过这个服务器进行代码同步。支持Git的第三方免费的服务器有很多,比如GitHub/Gitee,这里我们以GitHub为例,把我们的代码上传到GitHub服务器(Gitee服务器的做法与此类似,这里就不再演示了)。另外你也可以使用自己的服务器,Git本身就支持服务器搭建功能。目前在国内访问GitHub服务器速度比较慢,下面有关GitHub服务器的操作,如果碰到失败情况,建议大家多刷几次,有可能就成功了;或者找一个人少的时候去访问GitHub服务器,比如凌晨,这个时候肯定速度很快。如果大家还是无法访问GitHub服务器,那么建议大家使用Gitee服务器,大家可以自己上网去搜一下如何注册Gitee账号以及如何创建Gitee仓库,大家也可以参考本文的4.12节,里面有关于Gitee仓库的一些操作说明。
首先你需要注册自己的GitHub账号,然后进入your repositories标签页,选择"new"
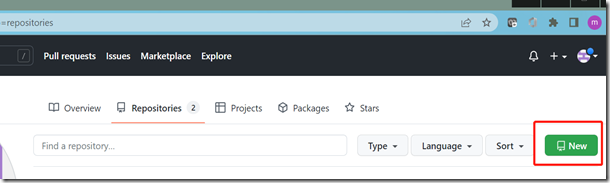
我们把这个新创建的仓库命名为:git_demo

创建成功后,我们将得到这个git仓库的HTTP或者SSH地址,我们可以通过HTTP或者SSH地址访问这个仓库,这里我们以HTTP为例。
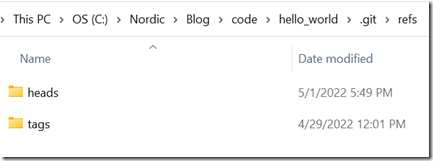
回到我们电脑本地,回到刚才的cmd操作界面,我们可以把我们刚刚创建的hello_world仓库跟GitHub上的git_demo仓库关联起来,并使二者保持同步。关联之前,我们可以查看一下.git/config文件,它的内容如下所示:

并查看一下.git/refs目录,里面只包含两个目录:
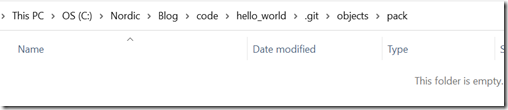
并查看.git\objects\pack目录,此时会发现此目录为空:
然后我们把GitHub服务器HTTP地址添加到本地仓库,如下:
git remote add origin https://github.com/aiminhua/git_demo.git
这样本地仓库就跟远程的GitHub仓库关联起来了,然后我们把本地仓库的main分支推送到GitHub仓库main分支上:
git checkout main
git push -u origin main
上述命令成功执行后,GitHub仓库内容就跟本地仓库内容同步起来了,如下:

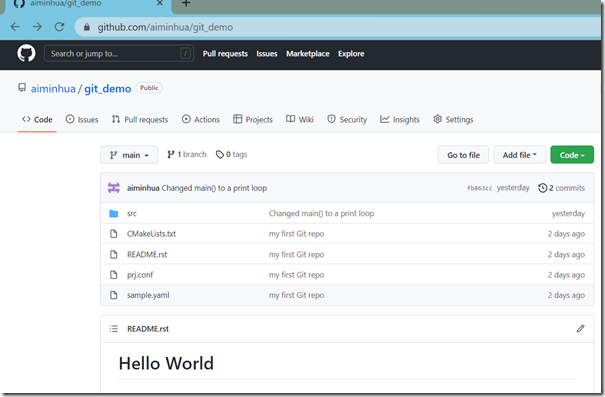
本地仓库和远程仓库关联起来后,我们再次查看.git/config文件内容,如下:
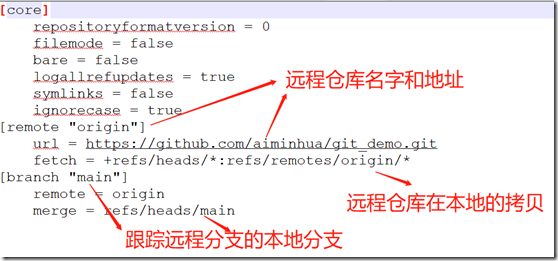
再次查看.git/refs目录,里面多了一个remotes目录,remotes目录下面包含origin目录,而origin目录下面又包含一个main文件,这个main文件其实就代表远程GitHub仓库的main分支,而.git/refs/heads目录下包含main和blinky两个文件,分别代表本地的main和blinky两个分支。
.git\objects\pack这个目录大家如果去查看,此时还是空的。
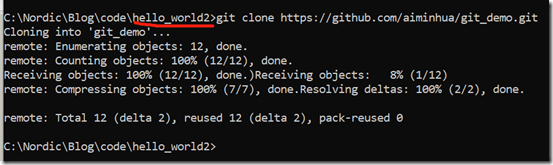
我们现在模拟两个开发者协同开发的情况,现在开发者1已经把代码上传到GitHub仓库上,开发者2则直接可以把GitHub上的仓库克隆(clone)到自己的本地机器上,为此我们另建一个目录hello_world2,以模拟开发者2的本地仓库,然后我们执行如下命令把远程仓库内容克隆下来:
git clone https://github.com/aiminhua/git_demo.git

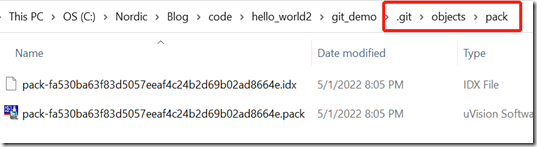
大家可以看到,这个clone下来的仓库跟GitHub仓库基本上一模一样,而且这个仓库的.git\objects\pack目录下面是有内容的:
下面我们将对Git工作原理进行说明。
3. Git工作原理简介
如果你对Git不是很熟,建议你按照第2章"2. 创建第一个Git仓库(Repository)"先实际操作一遍,然后再看本章,效果会更好。
Git是一个分布式版本控制系统(distributed version control system),这意味着每一个开发者或者电脑都拥有一个本地仓库,而且每个仓库(包含服务器上的那个仓库)关系同等,即每个仓库都可以独立工作,同步之后,每个仓库都拥有所有仓库的修改历史记录。跟分布式版本控制系统相对的是集中式版本控制系统(central version control system),比如SVN(Subversion)就是集中式版本控制系统,集中式版本控制系统对服务器依赖比较高,服务器一旦出问题,版本历史就会丢失,当多个人同时修改一个文件的时候,还需要文件锁机制。根据最新的统计结果,Git已经成为全球使用最广泛的版本控制系统,而且远远超过第二名。
3.1 Git操作区域
下图显示了Git管理代码仓库的一个示意图:

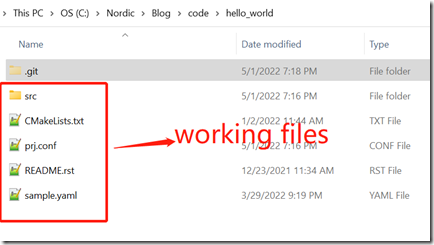
Git的管理对象主要包括5个区:remote,clone,branches,working files和stage。remote表示远程服务器,clone/branches/working files/stage都存在本地机器上,working files(working files在英文中也可以称为working directory或者working space,他们都是一个意思)就是大家真正面对的code base文件,即除.git目录外其他所有文件都属于working files,比如下图红框所有文件都是working files:
branches和clone都在.git目录中,属于本地仓库的一部分,branches就是本地分支,比如前述的main和blinky,branches的引用在如下目录:

branches引用的内容都在objects目录中。
clone就是把远程服务器的内容直接克隆到本地机器上,算是本地机器上的一个备份,clone区也叫upstream或者remote-tracking branches。我们一般使用origin来引用远程服务器仓库或者clone区,当我们pull或者push的时候,origin指的是远程服务器仓库,当我们checkout origin/main的时候,此时就是指clone区,clone的本地引用在如下目录:
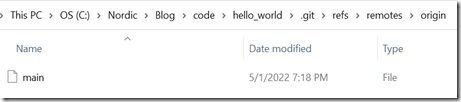
clone指向的内容也是在objects目录。
stage区,又称index区,以前也称为cache(缓冲区),它就是指.git目录下的index文件:
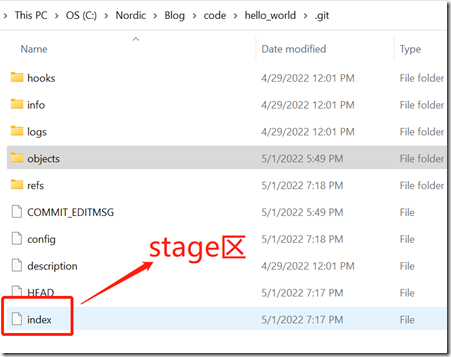
当你把新的修改提交到objects数据库之前,需要先把修改放在stage区,起到一个缓冲的作用。
3.2 Git对象(数据结构)
如大家熟悉的,对一般用户来说,Git呈现给大家的是一系列命令,而命令就要有操作数据对象,命令我们在下一节介绍,本节我们介绍Git的数据结构。
Linus说,Git不是传统的SCM,它更像一个文件管理系统。这句话道出了Git的核心设计理念,对于文件管理系统来说,最重要的就是它的数据结构以及对数据的引用。前面说过,Git像是一个小型数据库,这个是站在接口层面上说的,但Git的底层实现说到底还是文件系统,但Git又不是大家常见的那种文件系统,我们常见的文件系统描述一个文件的时候一般包括两部分:文件的meta data以及文件内容,比如一个txt文件,它的meta data就包括文件类型,文件名字,文件大小等,但是在Git中,由于它要处理的文件类型多种多样,为了使用同一套算法去处理这些不同的文件类型,Git舍弃了meta data部分,直接把文件内容本身以二进制形成存储下来,这些文件内容在Git中叫blob。blob没有文件名,没有时间戳等任何meta数据,它储存的是文件的纯二进制内容,blob文件本身在内部是以它内容的hash值来命名的,其中前2个字符为目录名,剩下的字符为文件名。blob文件都放在objects目录:
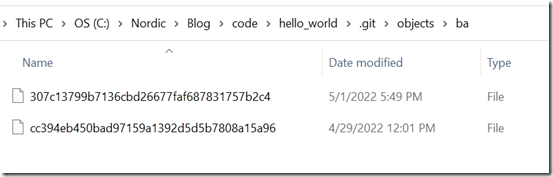
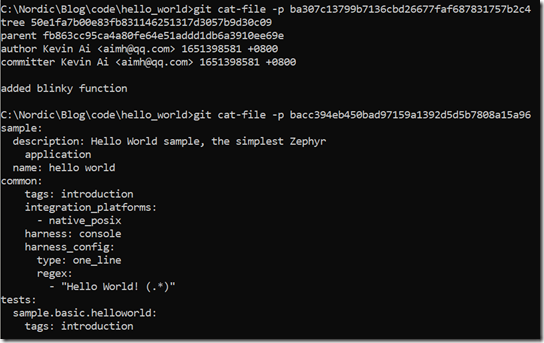
如上两个blob文件的hash值分别为:ba307c13799b7136cbd26677faf687831757b2c4和bacc394eb450bad97159a1392d5d5b7808a15a96。hash值就是这两个文件的ID,我们以后都是直接通过hash值来访问他们。这两个对象代表什么意思呢?我们可以使用git cat-file来获取hash值对应的对象的信息,由下图可知,这两个blob,一个是commit对象,一个是sample.yaml文件的内容。关于git cat-file和commit对象后面会有详细论述。
由于hash值就是对象的ID,一旦对象有任何修改,它的hash值就改变了,换言之,它的ID也就变了,它就变成了另一个对象了。在Git中,每提交一次版本,如果文件有修改,那么这个文件就会重新生成一个新的blob,所以说,blob只是某个文件的一个版本,如果这个文件有多次提交记录,那么在数据库中,它会对应多个blob文件。另外,blob本身只是位于工作目录中的原始文件内容的一个快照(snapshot),snapshot有两层含义:一blob和原始文件内容一一对应,可以相互恢复,二blob对原始文件内容做了一定的处理,简要地说,blob对原始文件内容做了无损压缩。
除了blob这个对象外,Git还包含tree,commit,tag和pack等对象,每个对象都有一个对象名或者ID,像blob一样,每个对象的ID都是其内容的hash值,Git包含的主要对象如下所示:
-
blob:文件内容本身,不带任何meta数据。
-
tree(树):blob不包含meta数据,如何找到它?我们的工程是包含很多目录的,这些目录信息存在哪里?这些就是tree对象要做的,tree对象包含一系列文件名以及子树,所以我们通过tree对象找到blob对应文件的文件名,子树本身也是tree对象,它又可以递归下去。Git中的tree是Merkle tree。
-
commit(提交):每commit一次,形成一个commit对象。commit对象把tree对象,日志信息,父commit对象,时间戳等连接在一起,形成一个完整的历史记录。
-
tag:tag其实就是对某一个特殊commit的引用,如果我们要发布某一个版本的时候,它对应的commit是一个hash值,大家根本记不住,为此引入了tag对象,tag对象指向一个commit,而且对这个commit加上一些额外meta数据,比如取个名字:v1.0.0。
-
pack:如前所述,每个文件每提交一个版本,都会生成一个blob,这样做,虽然提高了文件系统访问效率,但是当我们把他们上传到远程服务器时,这种做法就会浪费我们很多带宽和时间,为此Git引入pack对象,对blob数据进行压缩(zlib压缩),并打包成pack文件。
除了上述数据对象(他们都是保存在.git/objects中),Git还会保存引用(references,简写refs),refs就是对commit的引用,用来找到需要的commit,refs保存在.git/refs目录,主要有如下引用类型:
-
heads (branches):每个分支的最顶端,也是下一个新的提交的引用,每执行一次提交,自动向前推进。
-
HEAD:当前分支的head,跟工作目录相对。
-
Tags:用来引用某一个特殊的commit。
如前所述,Git使用hash标识所有的对象,确切说,Git使用SHA-1来计算每个对象的hash值,通过hash我们可以得到对象所有的信息,我们可以使用命令:
git cat-file -p hash值
来得到该hash值对应的对象的所有信息,比如前面我们有一个blinky的提交对象: ba307c13799b7136cbd26677faf687831757b2c4,输入如下命令:
git cat-file -p ba307c13799b7136cbd26677faf687831757b2c4
我们得到如下日志:
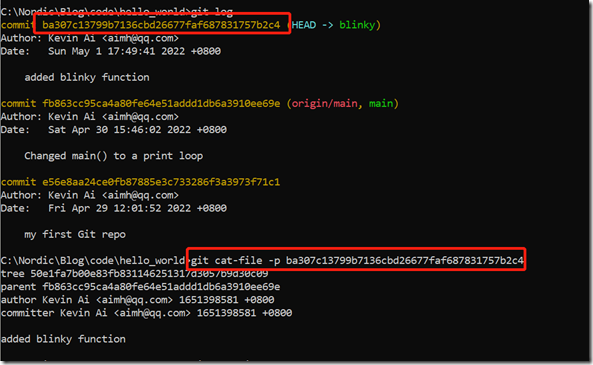
可以看出,ba307c13799b7136cbd26677faf687831757b2c4这个对象包含一个tree对象(50e1fa7b00e83fb831146251317d3057b9d30c09),一个父对象(fb863cc95ca4a80fe64e51addd1db6a3910ee69e),以及相关的提交日志。我们可以进一步通过git cat-file查看tree对象和父对象信息:
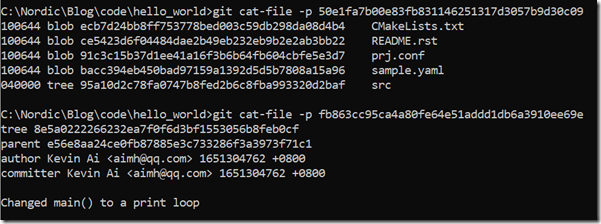
可以看出tree对象就是工作目录的顶级目录的快照,而父对象就是前一次的commit对象。
SHA-1是40个字符,我们可以截取SHA-1的前几个字符来代表整个SHA-1,比如取前6个字符或者取前8个字符,前提是这些截取的字符不会在当前Git仓库中出现重复情况,截取的做法会让我们的命令或者文字看起来更简洁。
我们可以使用git cat-file一一查询我们hello_world仓库目前所有的对象,最终我们将得到如下的对象关系图(左上角的是对象hash的前6位):
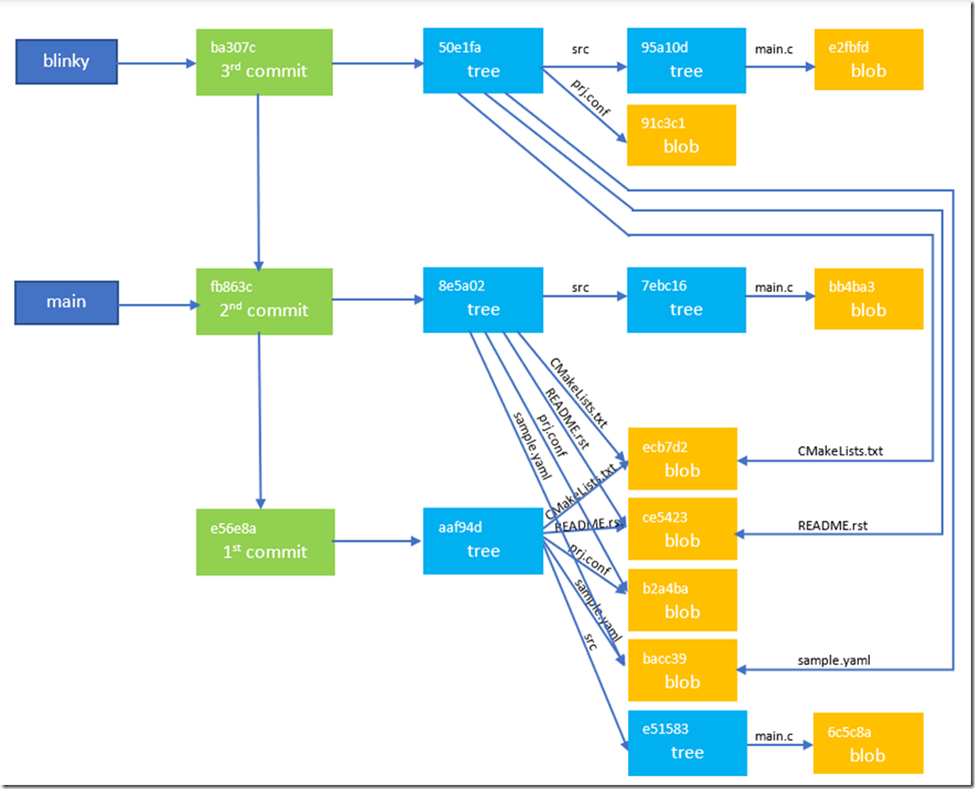
从上面可以看出,工作目录中的每个文件都在Git仓库中有一个blob对象,每次提交都会生成一棵树,这棵树会保留工作目录每个文件的快照(snapshot)。如果这个文件本次提交没有修改,snapshot还是之前的blob;如果这个文件本次提交有修改,则会生成一个全新的blob,并指向它。提交是有继承关系的,不管branch最后如何演变,所有branch不断递归,都将找到git init创建仓库时的那个commit为总根节点。上面这个图,希望大家仔细研读,最好自己去画一画,这对大家理解Git的内部对象非常有帮助。
3.3 Git命令
最初Git不是用来直接管理源代码版本的,而是为第三方SCM工具提供底层命令支撑,也就是说,大家操作第三方SCM工具,第三方SCM工具再调用Git底层命令。后来Git逐渐发展,大家也可以直接使用Git命令来直接管理源代码版本了。为此,Git命令分两种:plumbing和porcelain。plumbing命令,亦称Git core,属于底层命令,它是供第三方SCM工具或者脚本使用,对我们普通用户来说,一般是不需要了解的,像git cat-file, git hash-object,git ls-files就是这种命令,这些命令比较稳定,利于脚本进行解读。porcelain命令,就是大家面对的那些命令,比如git add,git diff,git commit,这些命令更友好,但也意味着容易演化,所以他们是人类可读的,而不是脚本解析的。
如第2章"2. 创建第一个Git仓库(Repository)"描述的那样,Git是通过命令行进行交互的,Git命令一般通过shell输入,最常见的就是bash,bash目前同时兼容Linux,Windows和MacOS。前面大家安装好Git之后,其实Windows版的Git bash也自动装好了,第2章里面的所有命令都可以通过bash去输入,如下所示:
我们之所以采用CMD来演示,主要是因为Windows用户众多,而且大家比较熟悉CMD,大家如果去网上搜索Git常用命令的用法的话,大部分人都是以bash为例来阐述的,因为有些操作CMD是不支持的。这也提醒大家,如果大家按照网上的提示去操作总是不成功的话,建议换成bash试一下。
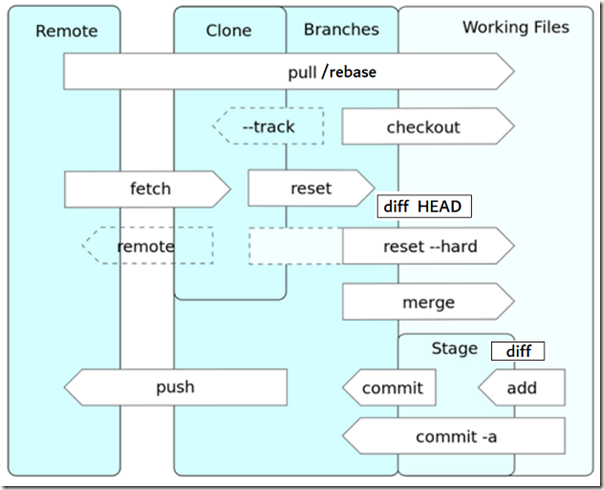
上面这个图把一些常用Git命令的操作对象通过图形化的方式展示出来了,比如git pull这个命令,表示把服务器的代码拉到本地机器上,如图所示,我们知道原来git pull是把远程代码直接放在工作目录,而不是其他区域。再比如git add这个命令,由图可知,它是把修改放在了stage区域;而git commit命令则是把stage的内容提交到branches区域(确切说branch以及branch引用的objects,这个大家读过3.2节就能理解了),这也是为什么当你修改了文件而没有先执行git add,而直接执行git commit,系统会提示你"nothing added to commit"。其他命令我们这里就不一一解读了,我们会在第5章对一些常用的Git命令进行统一说明。
3.4 Git flow
从前面描述可知,我们可以随时随地创建一个新的branch(分支),然后新分支又可以引出其他分支,最后我们又可以把新分支merge(合并,后面会讲述它的含义)到main分支。随着开发的不断发展,branch也将不断发展,这里面就有一个git的工作流问题,即该建哪些分支?这些分支该如何演变?有人总结了如下的branch模型(原文链接为:https://geekiam.io/how-to-use-git-flow/),可供大家参考。
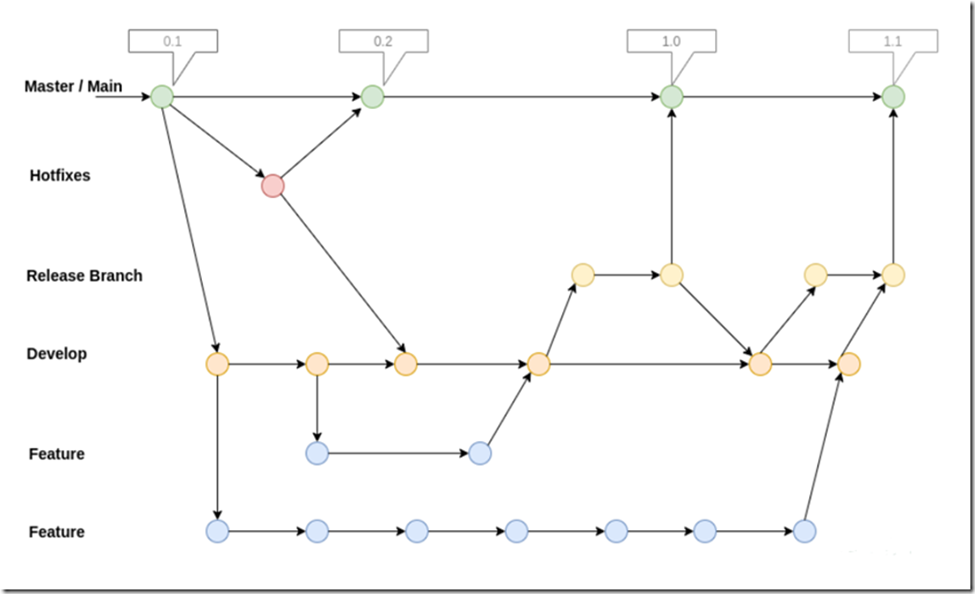
上图每一个圆点就是一次commit,每一条横线表示一个分支,总共有6个分支:main,hotfixes,release,develop,feature和feature',main分支用来发布,开发主要在develop分支,每次增添新功能的时候,另起一个feature分支,在把develop分支推送到main之前,先合并到release分支。从上面的分支演化图,我们可以看出,分支可以相互引用,错综复杂,但从根本上来说,我们的开发从main分支开始,也从main分支结束。
4. Git进阶示例
我们现在在第2章Git工程的基础上,继续演示Git的一些高级应用。
4.1 git merge – fast forward
我们首先查看一下分支情况,并切换到主分支:
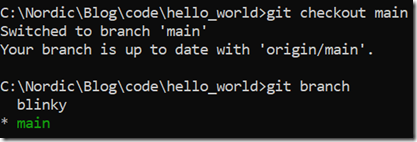
这2个分支的功能是不一样的,main分支循环打印"hello world",blinky分支循环点亮板子上的LED灯,我们现在把这两个分支合并(merge),即让程序同时具备打印"hello world"功能和点亮LED功能,我们使用如下命令进行merge:
git merge blinky
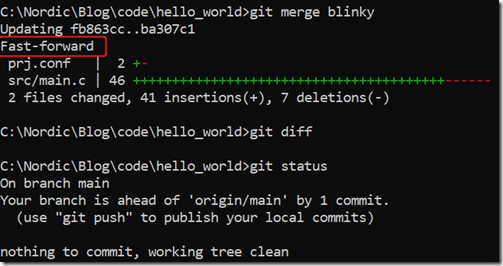
从日志可以看出,此次merge是fast-forward(快速)合并,因为blinky分支的head就在main分支head之上进行的修改提交,期间main分支没有做任何其他修改,所以merge的时候,直接把main的head指向blinky的head,这就是fast forward。我们后面输入git diff和git status查看状态,可以看出此时index和working tree都是干净的。此时我们打开src/main.c文件,可以发现该文件已经完全被blinky分支的src/main.c覆盖,而老的main分支里面的src/main.c内容全都不见了:
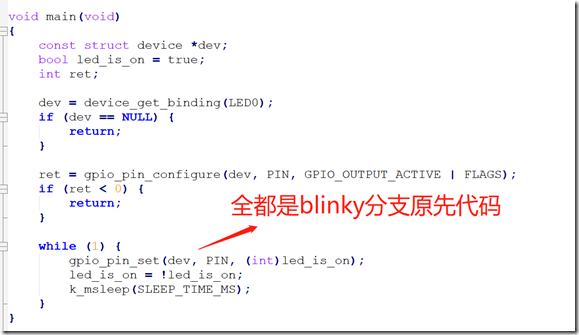

这个时候,大家可以手动把hello_world里面的代码加到merge后的main.c,问题就解决了。
git merge实际上就是一次新的commit,这个可以通过git log日志看出端倪:
从日志可以看出,git merge后main分支多了一次commit。
4.2 git reset和git revert - 删除某个commit
为了下面演示另一种merge情况,我们需要把刚才的merge动作撤销,刚刚说过了,git merge就相当于一次commit,撤销git merge的操作跟撤销git commit的操作两者是一样的,如何撤销一次commit呢?我们有两种选择:一是git revert,二是git reset,我们先看看git revert,它的语法是:
git revert (commit ID)
其中HEAD是一个特殊的commit ID引用,指向当前分支的最顶端commit。
比如我们输入
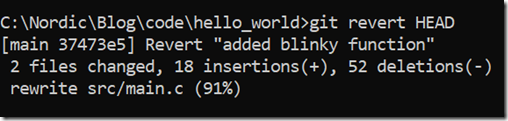
git revert HEAD
(注:当前环境下,该命令等价于:git revert fb863cc95ca4a80fe64e51addd1db6a3910ee69e)
我们将得到如下结果:
此时使用git log查看日志:
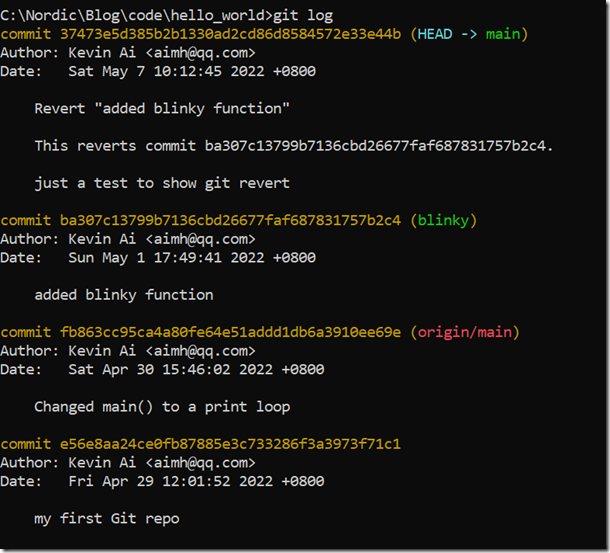
可以看到,git revert其实是一个新的commit,它把fb863cc95ca4a80fe64e51addd1db6a3910ee69e对应的commit重新提交在最新的head之上。git revert之后,main分支总共有4个commit了,而且第2个commit和第4个commit两者追踪的文件是一模一样的。
现在我们再来看git reset。有人觉得git revert这种做法有点怪,希望直接把第3个commit删掉,然后把head指向第2个commit,这就是git reset要实现的功能。git reset语法跟git revert有点像:
git reset (commit ID)
与git revert类似,你也可以使用HEAD这个特殊的commit ID引用。
执行git reset后,分支的head指向指定的commit,而这个commit之后提交的所有commit都将丢失,所以建议大家慎用git reset。git reset经常跟着三个输入参数--mixed,--soft和--hard,默认选择--mixed选项,这3个参数有非常强大的副作用,大家一定要记住他们的区别,其中--mixed选项表示同时要复位index区,但保持working directory不变,--soft选项表示保持index区和working directory当前状态不变,而--hard选项表示同时复位index区和working directory。据此,我们输入如下命令:
git reset --hard fb863c

此时我们再使用git log查看一下历史:
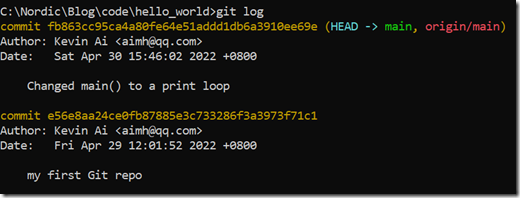
可以看出main分支只剩下2条commit了,成功删除了后面的commit。
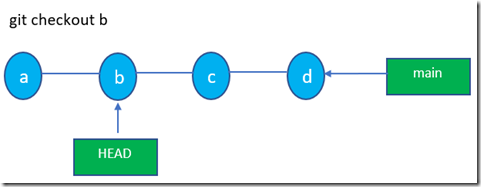
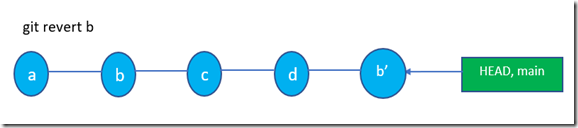
4.3 git checkout,git revert和git reset
git checkout,git revert和git reset这三者的区别示意图如下所示:

4.4 git merge - 手动解决冲突
如果你一直按照我们的步骤来操作,那么前面的fast forward的merge应该已经删掉了,此时main分支只有两条commit,而blinky分支有3条commit,我们还是切换到main分支,然后修改src/main.c文件:
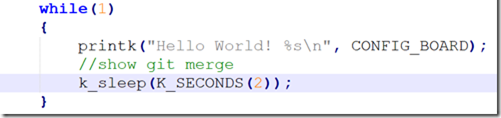
做完上述修改后,我们再执行:
git add . git commit -m "updated main.c to prepare for a merge"
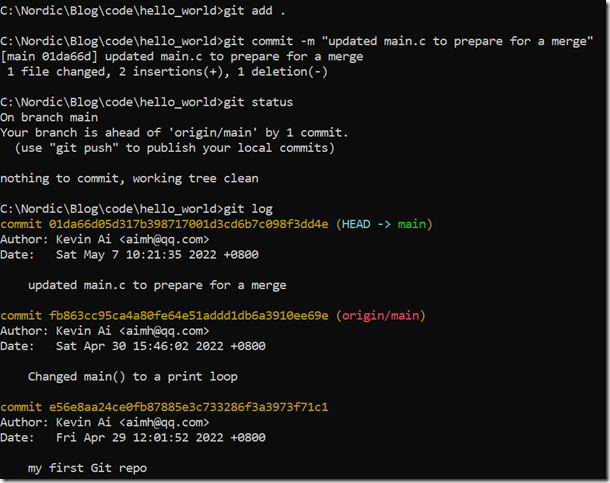
此时,main分支已有3个commit了,而blinky分支也有3个commit,此时我们再merge这两个分支:git merge blinky,有如下conflict报错:

然后我们打开src/main.c文件,发现它已经变成:
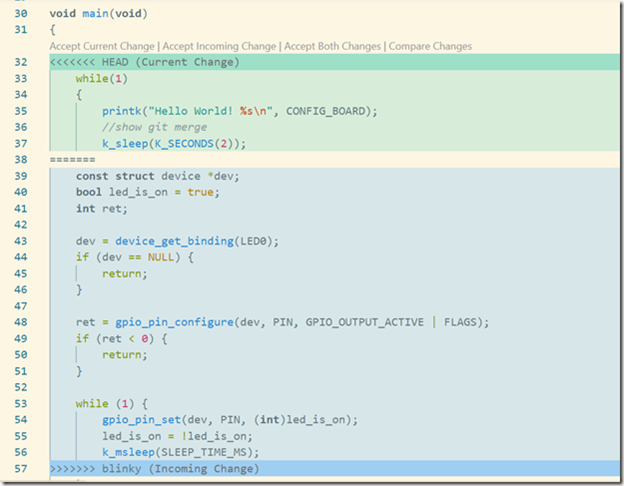
此时git status会有如下输出:
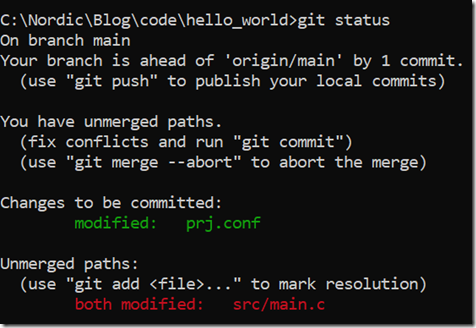
怎么解决这个冲突?手动修改src/main.c,简言之,改到符合你期望为止,main.c最后变成:
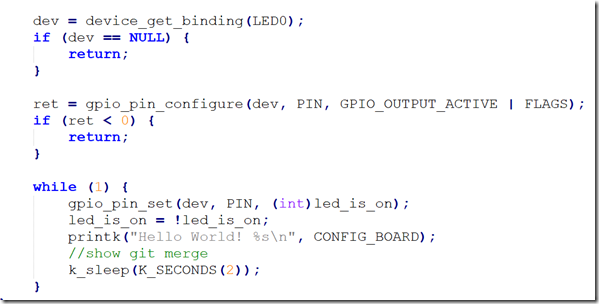
此时的main.c同时具备hello_world和blinky功能。然后我们重新提交,本次merge就成功结束,即输入:
git add .
git merge --continue
注意:git merge --continue后,会跳出一个文本编辑器让你写提交信息,写好保存,然后关闭即可。
merge是分布式版本控制系统的一个核心概念,因为分布式版本控制系统支持merge,所以它可以允许多个开发者同时修改一个文件,而不必像集中式版本控制系统那样每次更新文件都需要对文件进行锁定,每时每刻只允许一个开发者修改同一个文件。一般来说,merge采用three-way合并算法进行merge,假设我们有两个文件A和B,他们有共同祖先C,A和B合并并生成D,它的算法是这样的:如果A和B的内容是一样的段落,直接输出到D;如果A和C的内容是一样的段落,将B对应的段落内容输出到D;如果B和C的内容是一样的段落,将A对应的段落内容输出到D;如果A,B和C三者内容都不一样的段落,即是存在冲突的段落,这个就需要用户手工去调整和修改。

4.5 .gitignore – 忽略某些文件的追踪
我们现在把这个工程编译一下(注:没有安装Zephyr编译系统的,大家可以只观看,不用实际操作),编译成功后,我们会有如下build目录:
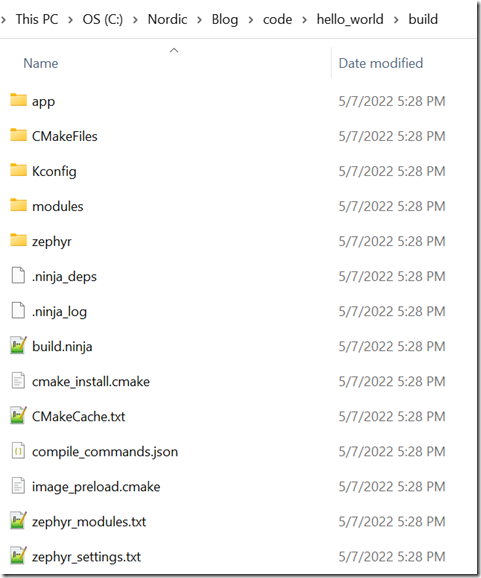
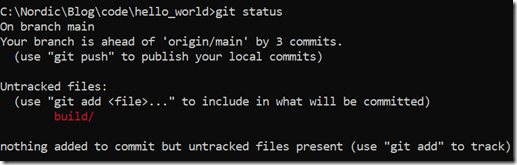
此时git status输出也会显示我们新增了这个build目录:
这个build目录里面的内容都是编译系统自动生成,我们去追踪他是毫无意义的,更重要的是,一旦追踪了这个build目录,那么每次执行git diff或者git status,你都将得到一个长长的diff表,无用信息将掩盖有用信息,阅读特别费劲。为此需要引入.gitignore文件,忽略某些特定文件或者目录,我们可以直接把zephyr工程里面的.gitignore文件拷到我们工程:https://github.com/zephyrproject-rtos/zephyr/blob/main/.gitignore,如下:

这样我们的git就不再追踪build目录了。
关于.gitignore的用法,大家可以自己上网搜一下,这里不再赘述。我给大家的建议是:直接使用类似的第三方开源项目里面的.gitignore文件,省得自己去研究。
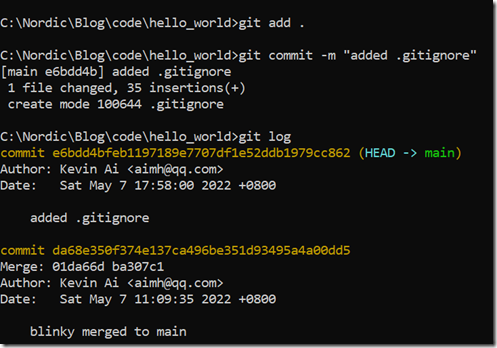
既然我们增加了新文件:.gitignore,我们就再次提交一下项目修改:
特别提醒,如果你已经追踪了build目录,此时再添加.gitignore文件,虽然之后build目录内容不再提交到仓库,但是,你会发现,git diff还是会去比较build目录里面的内容,这是因为git diff比较的是index和working tree两者的不同,而index已经包含build目录了,加上.gitignore并不会自动清理index区。此时为了得到忽略(ignore)目的,我们需要把index里面的build目录删掉,可使用如下命令:
git rm --cached build
有时为了简单化,你可以直接把整个index区清空,然后重新添加所有working files并提交,这样肯定可以保证.gitignore文件立即生效,即使用下面命令:
git rm -r --cached . git add . git commit -m "added .gitignore"
4.6 git push - 把本地代码推送到远程服务器
我们在第2章已经把仓库push到服务器了,现在我们在本地又做了多次提交,本地仓库跟远程仓库已经不同步了,这个也可以通过git status的输出看出:
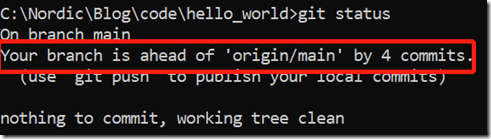
此时我们有4个本地提交没有推送到服务器,为此输入如下命令:
git push -u origin main
其中参数-u表示upstream的意思,即同时让本地分支追踪远程分支。强烈建议大家加上这个-u,尤其在推送分支的时候,比如git push -u origin blinky,这个-u会让你省去很多事情!
这样本地仓库就与远程仓库同步了,这可以通过GitHub服务器上的src/main.c来验证同步是否成功:
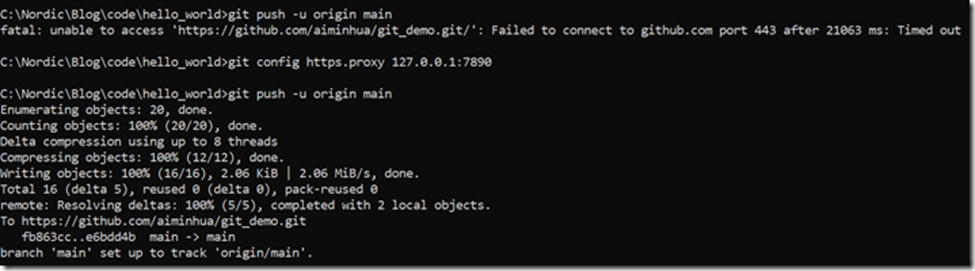
目前国内访问GitHub服务器经常出错,上述的git push命令有可能会报错"Failed to connect to github.com port 443 after 21063 ms: Timed out",碰到这种情况,你需要人少的时候去访问GitHub,比如凌晨;或者使用VPN,此时需要对git进行配置,以支持vpn通道访问服务器,配置指令如下所示:
git config https.proxy 127.0.0.1:7890 git config http.proxy 127.0.0.1:7890
相关shell输出日志如下所示:
4.7 git rebase – 团队协作
我们现在进入开发者2的仓库目录:C:/Nordic/Blog/code/hello_world2/git_demo,并且使用bash来演示接下来的git命令交互(CMD其实也一样),首先输入:
cd C:/Nordic/Blog/code/hello_world2/git_demo
然后:
git branch

可以看出此时只有一个分支:main,我们现在创建一个新分支:rtt_log,这个分支将实现一个功能:把日志从串口打印切换到RTT viewer打印,创建分支命令如下:
git branch rtt_log
然后切换到rtt_log分支:
git checkout rtt_log
然后我们对prj.conf做如下修改:
然后提交本次修改
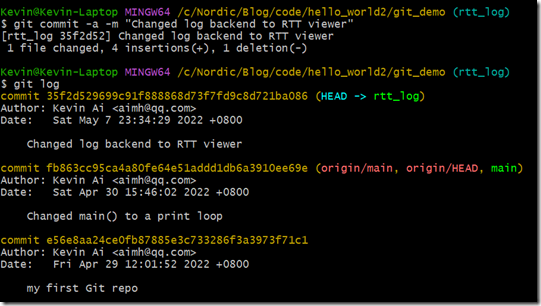
git commit -a -m "Changed log backend to RTT viewer"
此时一次新的提交已经成功了,相关日志输出如下所示:
现在开发者2已经有了自己的commit了,而GitHub服务器也已经同步了开发者1的commit,此时我们能不能直接把开发者2的commit push到服务器上呢?我们先试一下:
git push -u origin main
我们得到如下输出:
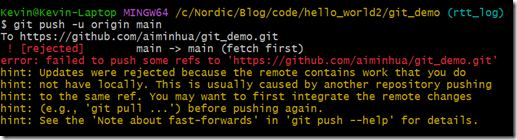
push被拒绝了,因为push只能接受fast forward类型的merge(本文4.1节有fast forward类型merge示例),即快速转发式的合并开发者2和开发者1的工作。为此我们需要先把服务器的更新拉下来,然后跟本地的修改merge,然后再次push。
先拉下服务器更新:
git fetch origin
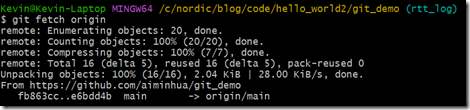
大家可以使用:
git checkout origin/main
来查看远程仓库是否更新到本地(local),注意:origin/main表示的是远程仓库的本地clone,而不是本地main分支哦。

上述日志表明,远程更新已拉取到本地。
我们再次回到main分支:
git checkout main

上面提示我们的main分支已经落后origin/main了,我们可以把origin/main直接merge到main分支上:
git merge origin/main
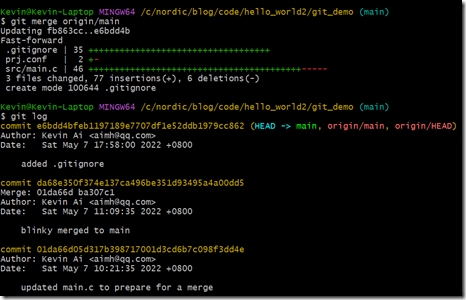
这样开发者2的本地main分支也跟远程main分支同步了。
这里提一下,上面git fetch origin和git merge origin/main两条命令其实可以用一条命令取代:
git pull origin master
这个大家从git pull --help的帮助页面说明也能看出。
现在我们再把rtt_log分支merge到main分支,我们先使用前面说的merge方式来做一下:
git merge rtt_log
提示有冲突,我们手动解决冲突后:
git add prj.conf
git merge --continue
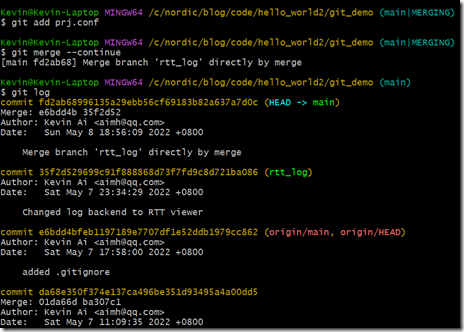
前面提过,merge本质就是一个新commit,我们看看这个新commit的父commit是谁:
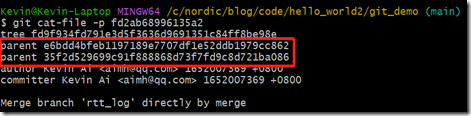
它有两个父节点,跟我们期望的有点不一样,我们希望main分支历史记录清晰,最好一一对应。
现在我们把刚才的操作复位:
git reset --hard origin/main
现在我们切换到rtt_log分支:
git checkout rtt_log
然后将其rebase到main分支,rebase的意思就是把rtt_log最新的commit基于main分支的顶端重新commit一次,rebase跟merge功能有点相似,具体区别我们后面讲。我们输入如下rebase命令:
git rebase main
此时会报conflict(冲突)错误,这个跟merge一样,手动解决conflict后,再执行如下命令:
git add .
git rebase --continue
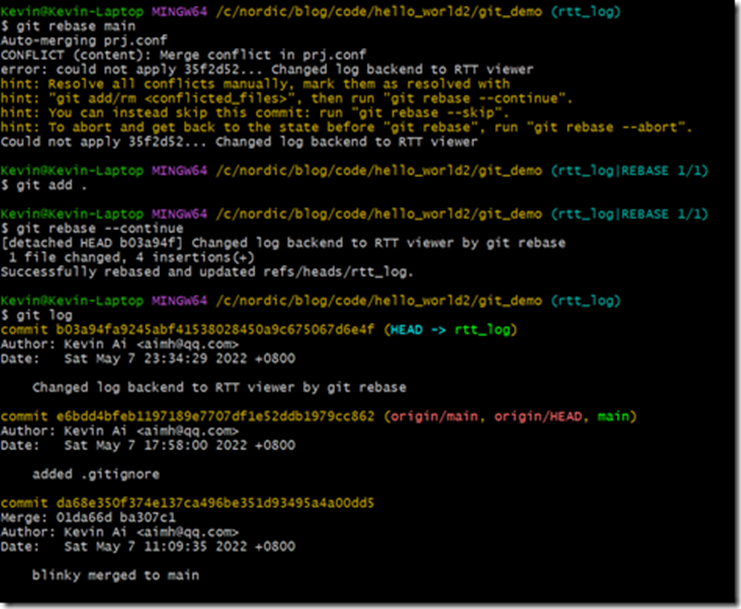
大家可以看到,rebase后的commit合并了最新的main分支和rtt_log分支,我们再看看rebase后的commit的对象关系:
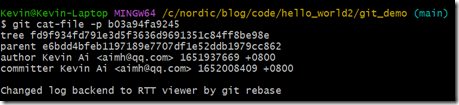
可以看出,新commit直接把rtt_log分支的修改重新在main分支顶端上重新提交了一遍,而且其只有一个parent,我们再看看它的parent到底是谁:

上面日志再次证明,rebase后的commit是基于main的head做的,而不是基于rtt_log之前的head做的。
此时rtt_log分支成功得rebase到最新的main分支,然后我们再把rtt_log分支merge到main分支:
git checkout main
git merge rtt_log
git log

此时的merge,就是一次fast-forward的merge。我们再看看这个时候的commit的对象关系图:
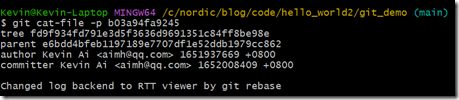
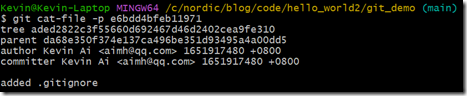
从上面输出可以看出,最新的commit只有一个parent,而且parent就是前一次的commit,这样历史记录就非常清晰了。
这个时候我们就可以再次推送本地更新到远程服务器了:
git push -u origin main
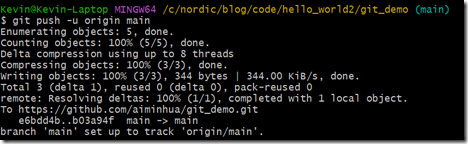
这样开发者2也成功把自己的代码推送到服务器了,从而开发者1和开发者2完成了协作开发。
4.8 git merge和git rebase区别
假设我们有如下分支,即main分支和feature分支,而且他们两个分支都是从同一个commit分叉出来的。
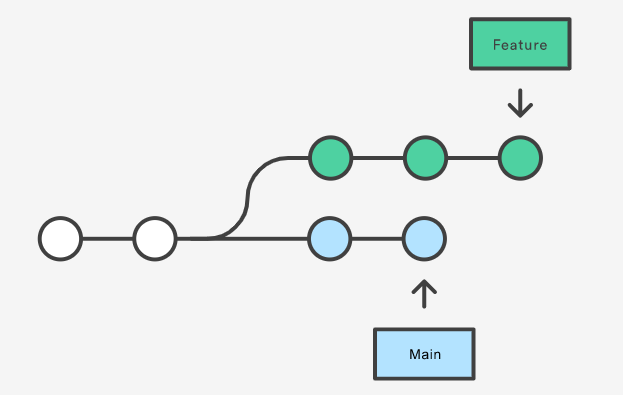
假设我们现在在feature分支上,然后把main分支merge到feature分支上,merge成功后,我们将得到如下分支结构图:
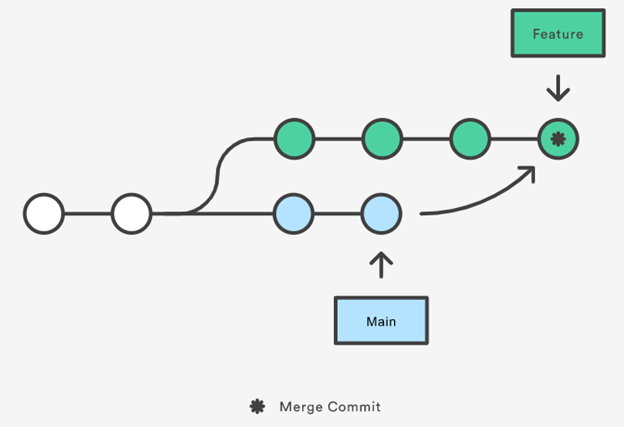
可以看出,merge只创建了一个新commit,而且它的父节点包含2个。
如果我们不使用git merge,而采用git rebase,那么rebase后的分支结构图如下所示:
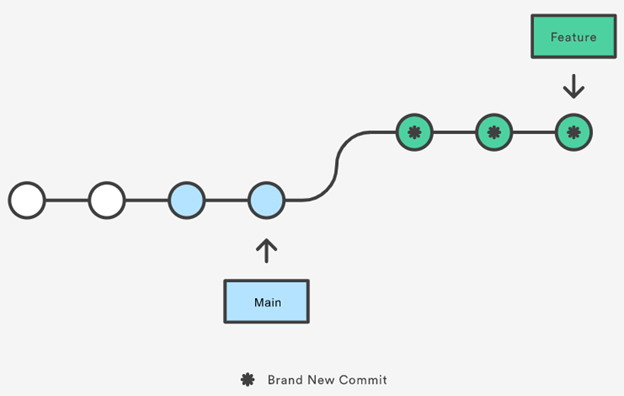
可以看出rebase后,feature分支以前老的3个commit全部删除,然后他们重新在main分支顶端一一再次提交,形成3个新的commit。Rebase后历史记录呈线性关系,非常干净清晰。
使用git rebase有一条基本原则:不要rebase公共的branch,比如上面的例子,如果我们把main rebase到feature分支上:
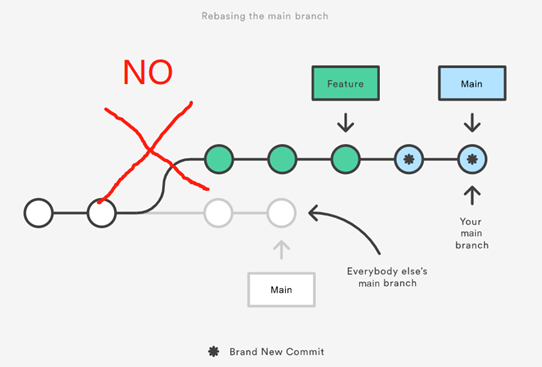
执行这个操作后,main分支历史被改写,这样远程的main或者其他开发者的main分支,在Git看来,就跟你的main分支分叉了,后面你就没法直接push了。所以执行git rebase操作的时候,我们总是在开发者分支上进行,然后fast-forward merge到main分支。
4.9 git submodule - 引用第三方模块
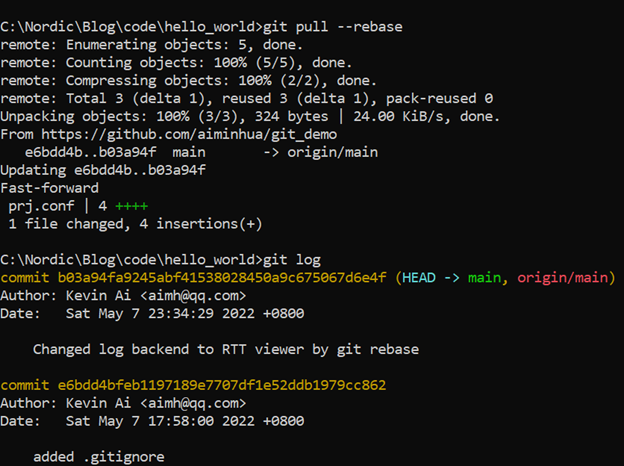
现在我们回到开发者1的仓库,前面开发者2已经提交了一次commit到服务器,所以我们先更新一下开发者1的仓库,这次我们使用git pull来做:
git pull --rebase
说明一下,在这里你也可以使用
git pull
这个命令实际上就是:
git pull --merge
即git pull默认采用merge方式,即把远程分支merge到本地分支,前面说过merge和rebase的区别,在这里也是适用的。
另外再提一个事,我们经常在网上看到有人说pull request,这个pull request跟我们的git pull是完全不沾边的两码事,pull request是当你要贡献自己的修改给一个第三方的repo时,你需要发起pull request,repo主人同意后,你的代码才能提交上去,具体请见本文4.13节。
对了,现在我们使用git log查看日志的时候,日志已经比较多了,一屏无法显示全部,这个时候你可以使用"空格键"继续浏览后续日志,或者按字母"q"退出目前操作界面。"空格键"和字母"q"是两个经常用到的快捷键,他们适用的地方非常广,大家一定要记住。
下面我们来看看软件开发中经常碰到的一个场景:引用第三方开源的模块,这些模块放在GitHub/Gitee等代码托管平台上,这些模块由第三方维护,而且第三方也一直在迭代开发或者维护中。
我们现在在hello_world工程中引用https://github.com/aiminhua/ncs_samples这个仓库里面的代码,怎么做呢?有两种做法:一是使用git submodule,二是使用git subtree,为了保持第三方仓库的独立性和完整性,我们一般使用git submodule的做法。
我们可以使用如下命令把上面这个第三方仓库添加到本地ncs目录下:
git submodule add https://github.com/aiminhua/ncs_samples.git ncs
执行成功后,我们会有如下日志:

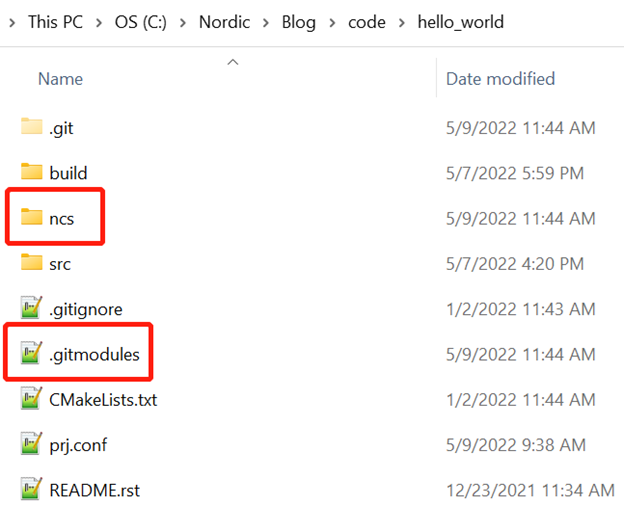
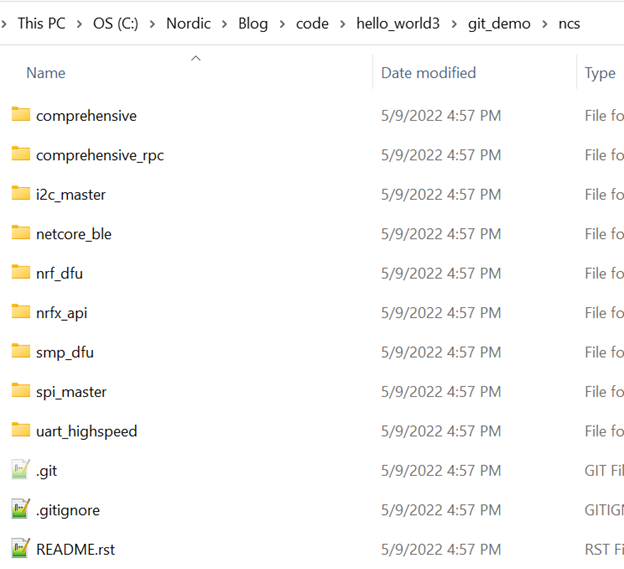
仔细再查看我们的hello_world目录,可以看到它多了一个ncs目录和.gitmodules文件,如下:
进入ncs目录,我们可以看到:
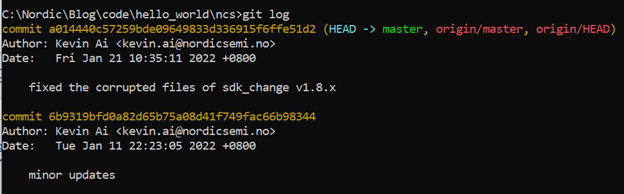
此时我们在ncs目录下使用git命令,我们可以发现,命令将直接操作ncs目录里面的git仓库,而不是我们的hello_world仓库,我们可以像操作普通git仓库一样去操作ncs这个第三方仓库,比如修改文件然后提交,这个时候的提交是针对第三方仓库的,相当于第三方仓库又多了一条commit,跟hello_world主仓库没关系,感兴趣的读者可以自己去操作一下(注意:由于这个第三方仓库不是你的,如果你想把修改push上去,是会被拒绝的,这个时候你需要走pull request流程了)。其实,我们可以通过git log的输出日志就能直观理解上面的描述:
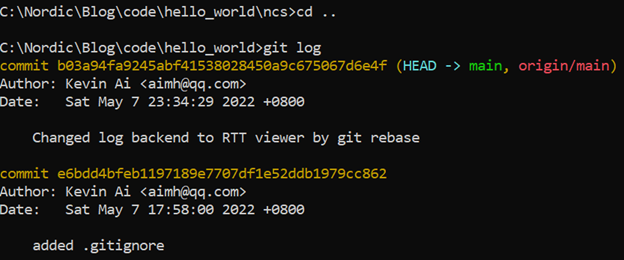
可见,git操作完全跟hello_world主仓库不搭架,全都是第三方仓库本身的东西。但是我们回到hello_world主目录,此时所有的git操作又是针对我们的hello_world主仓库了,还是看看git log的输出就有体会了:
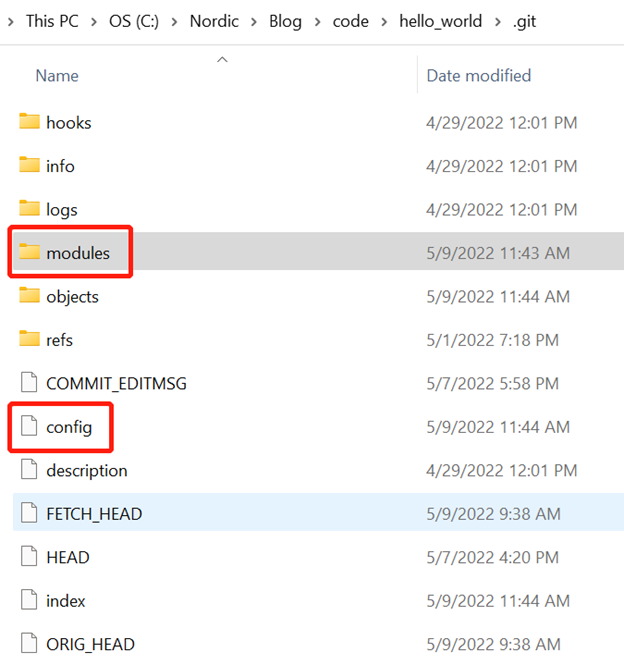
大家可以进到.git目录,看看git submodule后它发生了哪些变化?.git目录里面会增加一个modules目录,而且config文件会被修改:
感兴趣的读者可以把前面提到的有关文件一一点击进去,看看他们的内容到底是什么,这里就不再演示了。
我们现在把刚才的修改提交,并push到服务器,输入如下命令:
git commit -a -m "added submodule: ncs" git push

成功后,我们再看一下服务器的情况:
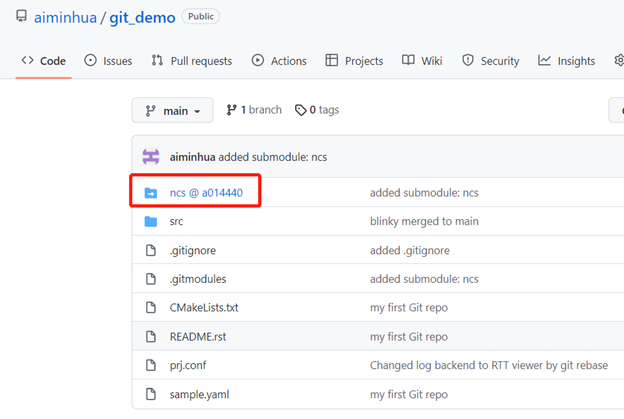
可以看出,ncs这个第三方仓库对应的代码并没有clone到服务器上,服务器只有第三方仓库的引用链接,点击这个链接,自动跳转到第三方仓库原始地址。
开发者1已经把第三方仓库引用上传到服务器了,开发者2怎么把这个第三方仓库clone下来呢?这里分两种情况,如果你是第一次clone这个工程,你只需在git clone中加入--recursive参数,即:
git clone https://github.com/aiminhua/git_demo.git --recursive
另一种情况是你已经clone了这个工程,这个时候就是update操作了,目前开发者2碰到的情况就是这种类型。为此我们先git pull主仓库更新:
cd C:\Nordic\Blog\code\hello_world2\git_demo
git pull --rebase

此时虽然把ncs目录拉下来了,但里面是空的。为此,我们还需要执行如下命令:
git submodule update --init


至此我们的git submodule演示就结束了。
4.10 git subtree – 包含第三方模块
前面提过,我们还可以使用git subtree来包含第三方模块。git submodule是引用第三方模块,第三方模块是一个独立的git 仓库,跟主仓库完全剥离。git subtree则是包含第三方模块,第三方模块代码是主仓库的一部分,对第三方模块的修改会全部体现在主仓库的历史记录中,使用git subtree推送第三方模块,第三方模块代码会完整clone到服务器上。
我们现在把https://gitee.com/minhua_ai/ncs_samples这个仓库里面的代码包含到我们的hello_world工程中,输入如下命令:
cd C:\Nordic\Blog\code\hello_world git subtree add --prefix ncs_subtree https://gitee.com/minhua_ai/ncs_samples.git master --squash
其中,ncs_subtree是本地目录以存储第三方模块代码,master表示的是远程仓库的master分支,squash表示只将第三方模块最新的一条历史记录合并到主仓库中。

此时再去查看hello_world工程目录,你会发现它下面多了一个目录:ncs_subtree,而且ncs_subtree目录已经包含了模块所有代码:
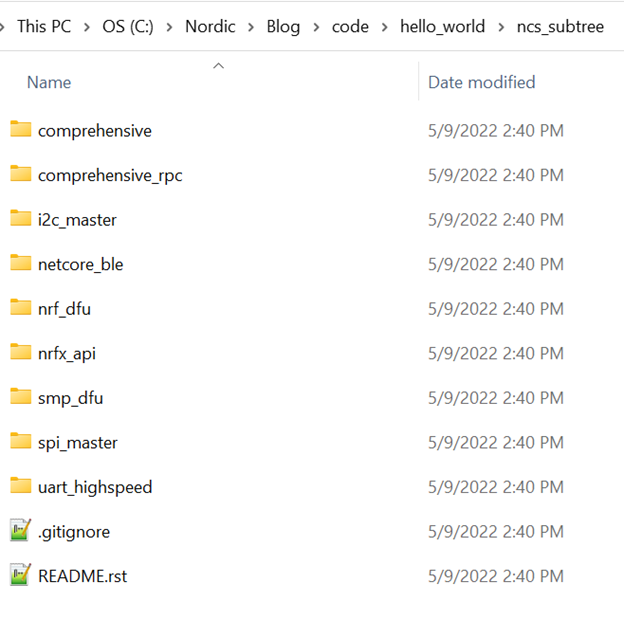
这个时候,我们使用git log看一下日志,有:
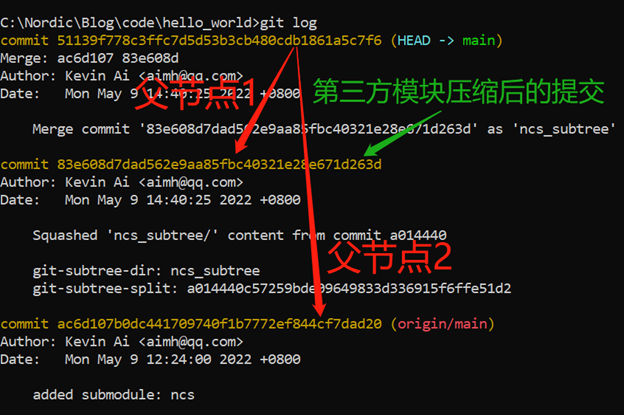
可以看出,ncs_subtree这个模块已经成为hello_world仓库的一部分了。
我们现在把刚才的修改同步到服务器:
git push

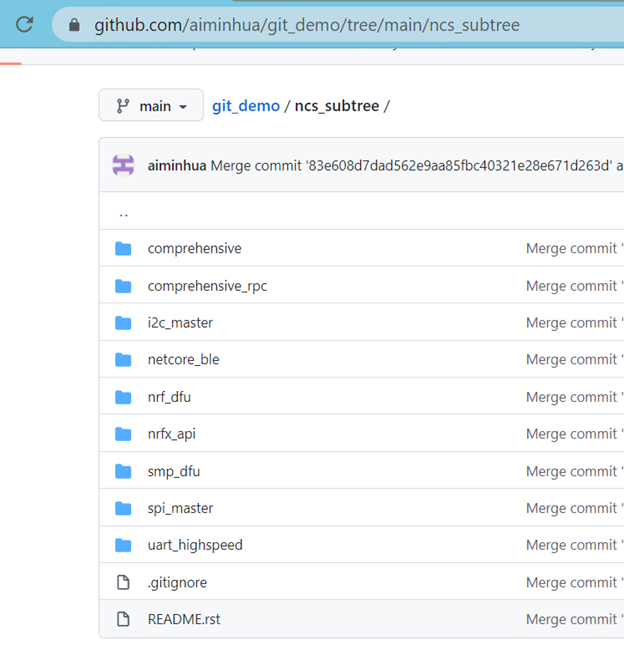
可以看出,git push操作可以把第三方模块代码完整clone到服务器上。
如果第三方模块更新了,我们可以通过git subtree pull拉取最新代码到本地,比如下面命令就可以将本地的ncs_subtree模块跟服务器同步:
git subtree pull --prefix ncs_subtree https://gitee.com/minhua_ai/ncs_samples.git master --squash
4.11 git tag – 发布软件版本
到目前为止,我们的Git仓库演示也就基本结束,我们现在可以着手发布它,也就是给我们当前的main分支head打一个tag,然后push到服务器。Tag就是一个特殊的commit,比如你要发布的版本,比如你要临时测试的版本,这个时候还是用commit ID去引用它,非常不利于阅读和大家交流,而tag相当于给这个commit取了一个好记的名字,利于大家阅读和交流。
给当前HEAD打tag命令为:
git tag -a v1.0.0 -m "git demo release v1.0.0"
然后我们通过git tag去列出目前仓库支持的所有tag,如果上述命令成功了,就会有输出:

然后我们把这个tag推送到服务器:
git push origin v1.0.0
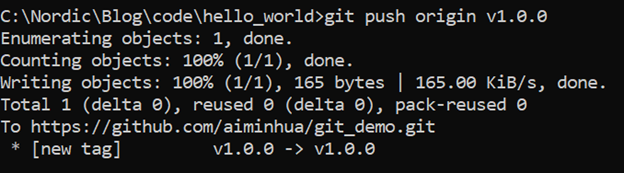
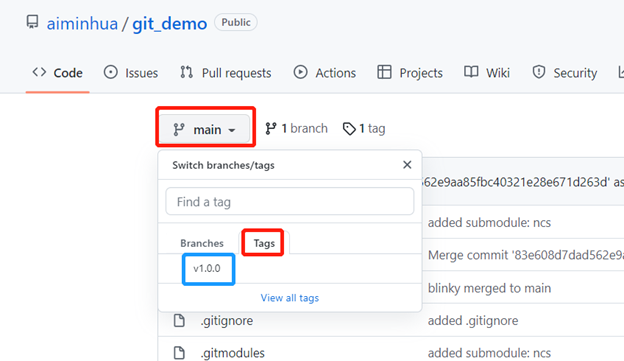
Tag一旦打成功了,你可以查看tag对应的内容:
git checkout v1.0.0
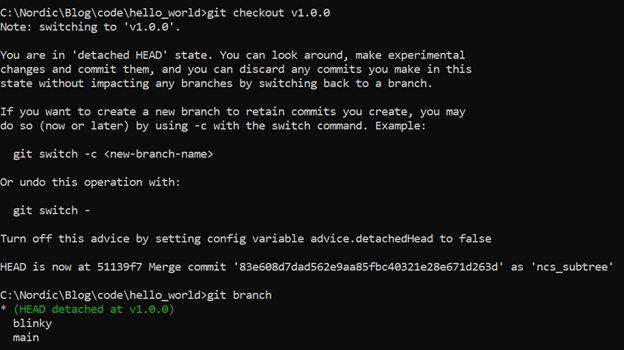
如上面日志提示的一样,你可以查看tag内容,但是你不能修改它。如需修改tag对应的内容,你必须新起一个branch,然后去修改,而不能直接在tag上进行修改。
4.12 将GitHub仓库导入到Gitee – 解决GitHub访问速度慢问题
GitHub有很多非常好的开源代码,但是目前国内访问GitHub有点慢,当这个GitHub仓库比较大的时候,直接使用git clone去下载它,经常会报超时等各种莫名其妙的错误。此时我们可以把这个GitHub仓库导入到Gitee,由Gitee通过云云对接的方式去clone(这个过程其实就是建立仓库的镜像),然后我们再从Gitee服务器把镜像仓库clone下来。下面我们将演示如何把我们刚刚创立的仓库:https://github.com/aiminhua/git_demo导入到gitee。
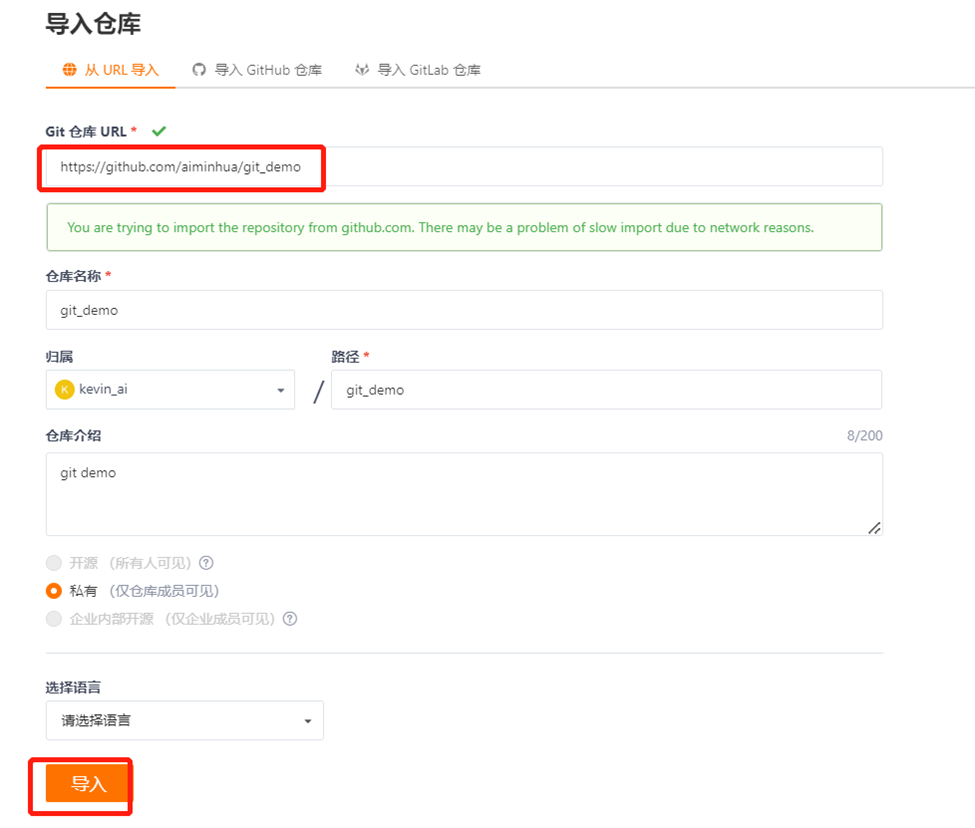
首先确保你有gitee账号,然后登录,选择如下菜单选项:
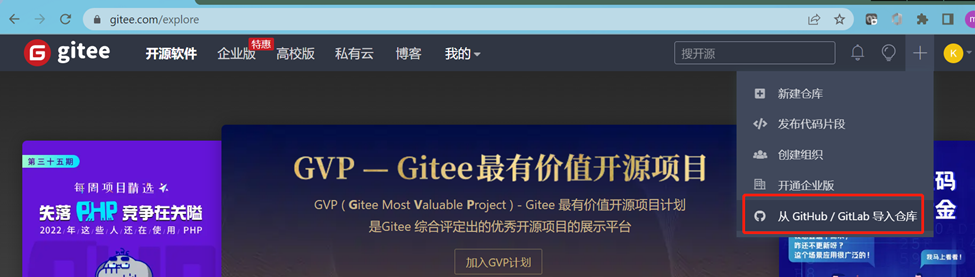
然后输入GitHub仓库地址:https://github.com/aiminhua/git_demo,最后点击"导入"按钮,Gitee就会通过云云通信的方式去抓取GitHub上的仓库,并在Gitee服务器上建立镜像。
成功后我们将看到:
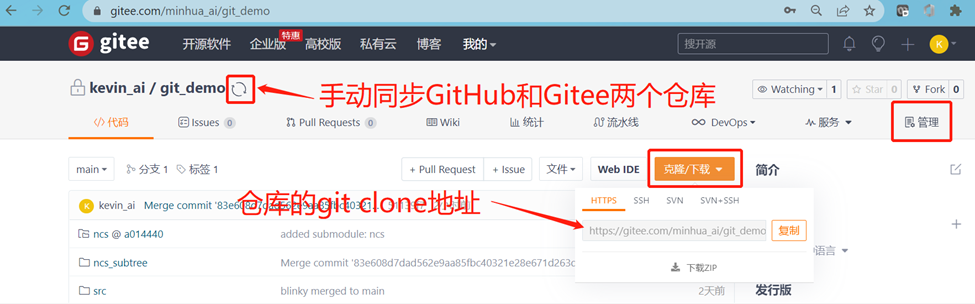
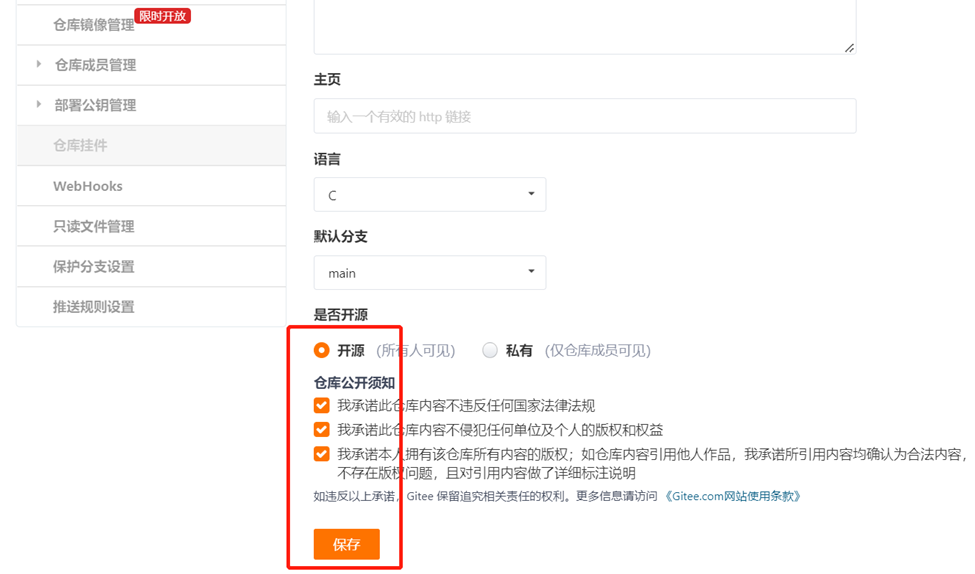
点击"管理"标签页,将仓库设为公开:
然后我们就可以从Gitee克隆这个仓库了。首先新建目录hello_world3,然后把仓库克隆到这个目录:
git clone https://gitee.com/minhua_ai/git_demo.git

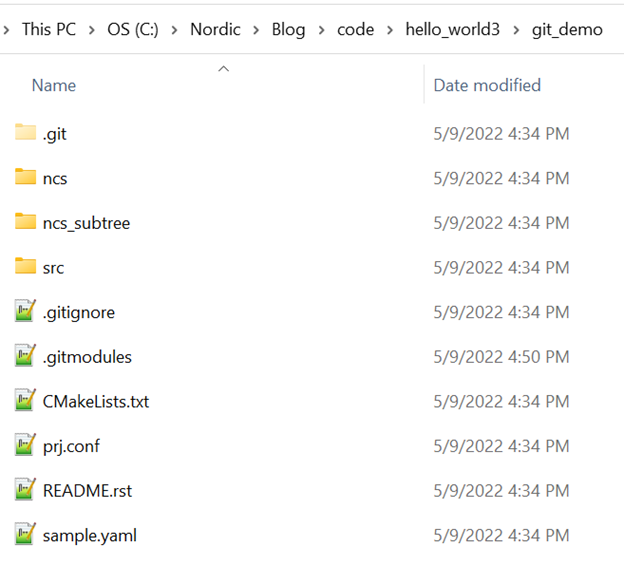
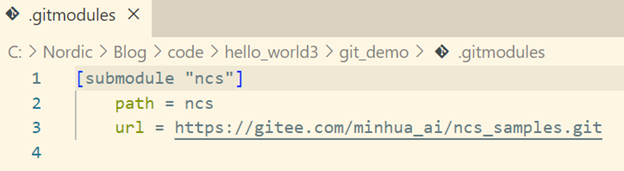
注:这里git clone我们没有使用--recursive参数,目的是为了跳过GitHub访问,因为ncs这个目录其实是一个指向一个GitHub第三方仓库的submodule,不加--recursive参数,我们就不需要去clone这个GitHub的第三方仓库,让大家对Gitee访问速度有个直观的认识。但实际上我们肯定需要加上--recursive参数,这样才能保证整个仓库的完整性,但加上--recursive参数后,问题又来了,submodule又指向了GitHub仓库,访问速度骤然下降甚至有可能失败,怎么办?还是老办法,先把这个第三方的submodule:https://github.com/aiminhua/ncs_samples导入到Gitee,成功后,我们得到它的clone地址:https://gitee.com/minhua_ai/ncs_samples.git。然后我们更改git submodule的配置,使其指向这个镜像,即修改.gitmodules文件:
然后我们输入git submodule update命令:
git submodule update --init

至此整个GitHub仓库就完全导入到Gitee服务器上,并通过Gitee服务器全部下载到本地。
这里要特别强调一点:虽然Gitee上的仓库可以一直跟GitHub同步,但从根本上来说,这是两个完全独立的仓库,一旦把GitHub仓库导入到你的Gitee账号下,你就是这个仓库的owner,而不是原来的第三方仓库开发者,你可以认为你自己新建了一个仓库,只不过仓库内容跟GitHub上的第三方仓库内容一模一样而已。
4.13 pull request – 贡献自己的代码
首先说明一下,pull request跟git pull两者完全不搭架,属于两个不同的范畴。Pull request是针对GitHub/Gitee等代码托管平台来说的,在这些代码托管平台,有很多开源的仓库,你会使用他们,使用过程中,你会发现这些开源代码的问题,然后你自己把这些问题给fix了,由于你不是这些开源仓库的开发者,你没法使用git push直接把自己的fix推送到这些开源仓库,这个问题怎么解决?这个就是pull request要做的事情。
Pull request(简写为PR)用于把自己的修改merge到第三方仓库,其步骤如下所示:
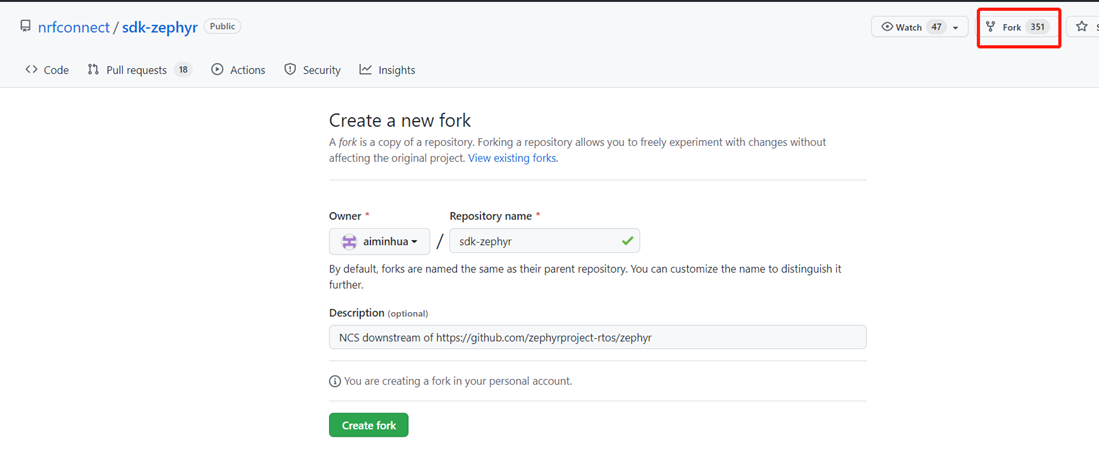
1. 先fork第三方仓库到自己的账号下面,下面是一个把https://github.com/nrfconnect/sdk-zephyr仓库fork到我账号的示例。
Fork成功后,界面如下所示:
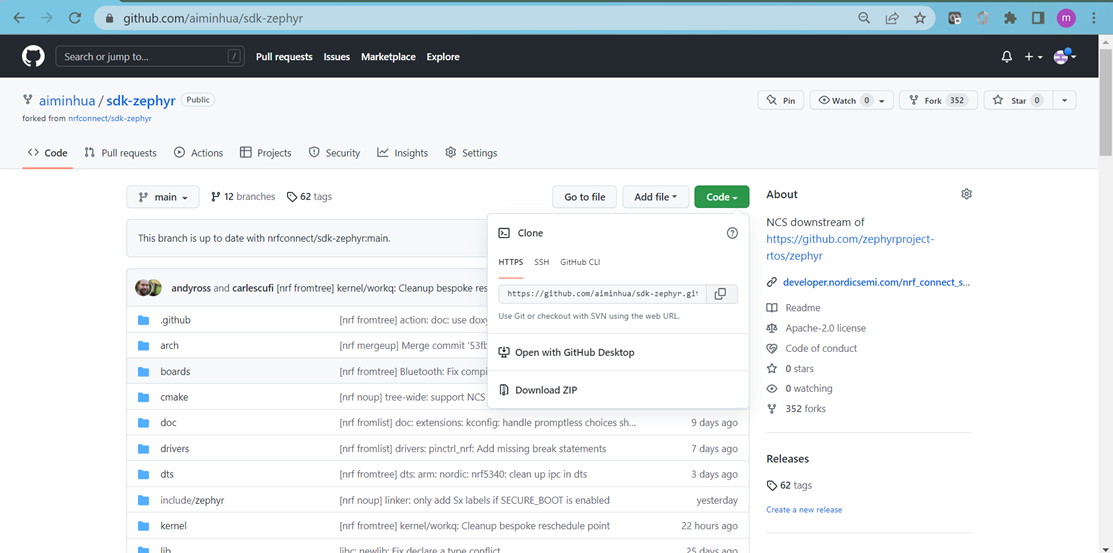
可以看出,sdk-zephyr成了我自己的一个仓库了,既然它现在是我的仓库,我当然可以对他做任何修改了。这种情况下,我们把原始的https://github.com/nrfconnect/sdk-zephyr称为https://github.com/aiminhua/sdk-zephyr(我自己的仓库)的upstream仓库。
2. clone https://github.com/aiminhua/sdk-zephyr对应的仓库
git clone https://github.com/aiminhua/sdk-zephyr.git
clone好之后我们会建一个新分支,然后在这个新分支上进行修改,比如我们新建一个分支:gpiote_pin_fix
git branch gpiote_pin_fix
git checkout gpiote_pin_fix
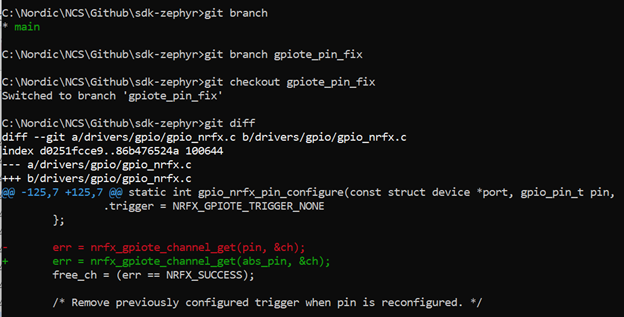
然后修改这个仓库某些文件,比如我们修改gpio_nrfx.c(具体修改见下面日志),并提交相关修改到仓库
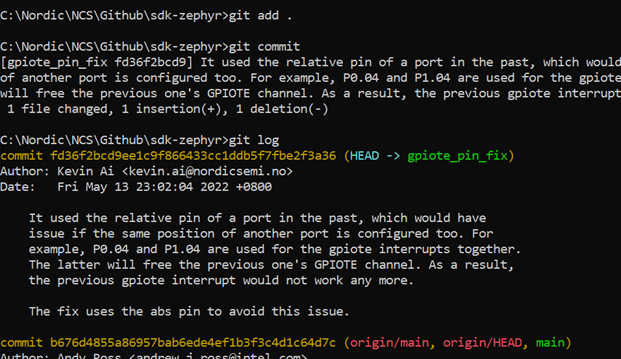
git add .
git commit -s
注意:这条命令之后会跳出一个文本编辑器让你输入提交消息,提交消息一定要符合第三方仓库的书写要求(第三方仓库一般都会出相关的书写指南,你需要自己去查阅一下),否则检查是过不了的。这里的-s是sign off的意思,主要是版权方面的考量,加上就好了。
此时我们就可以把最新的branch推送到远程仓库了:
git push -u origin gpiote_pin_fix
上面git指令的操作日志如下所示:
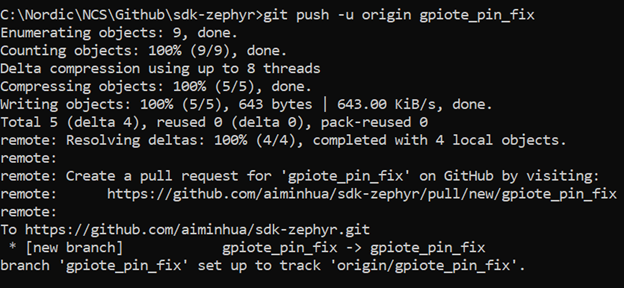
服务器收到新的推送后,自动会提示你要不要创建pull request,你也可以手动选择创建pull request,如下:

创建pull request的界面如下所示:
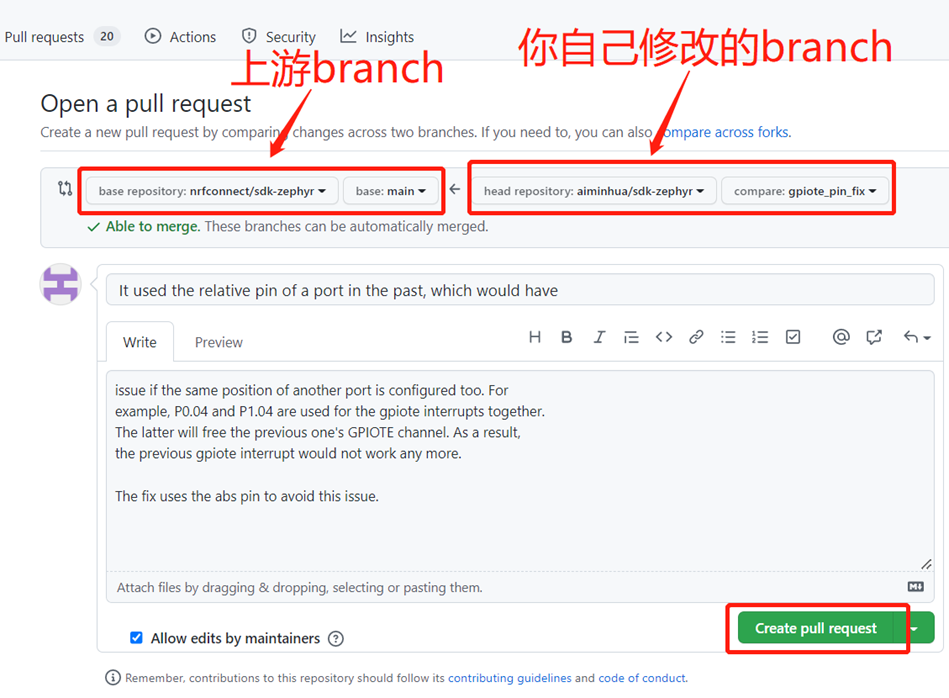
Pull request创建成功后,上游仓库pull requests标签页下会自动包含你刚才创建的pull request,如下:
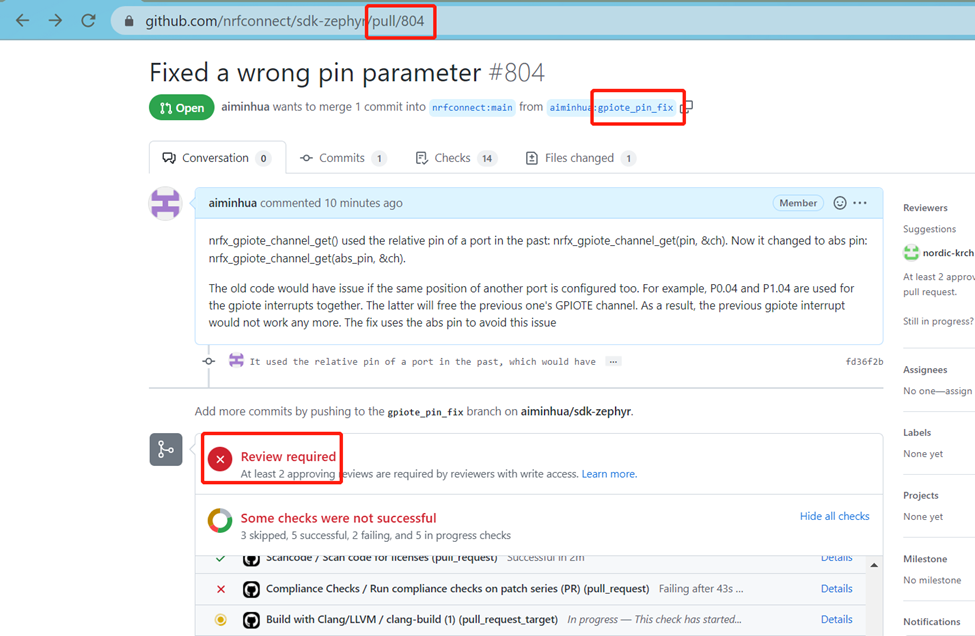
然后等待审核,按照审核意见进行细化修改,直至最后merge成功。
注意:PR创建的时候是在自己的fork下,成功后跑到上游仓库,最终它是属于上游仓库的PR,而不是你自己的PR,寻找PR必须去上游仓库寻找哦。
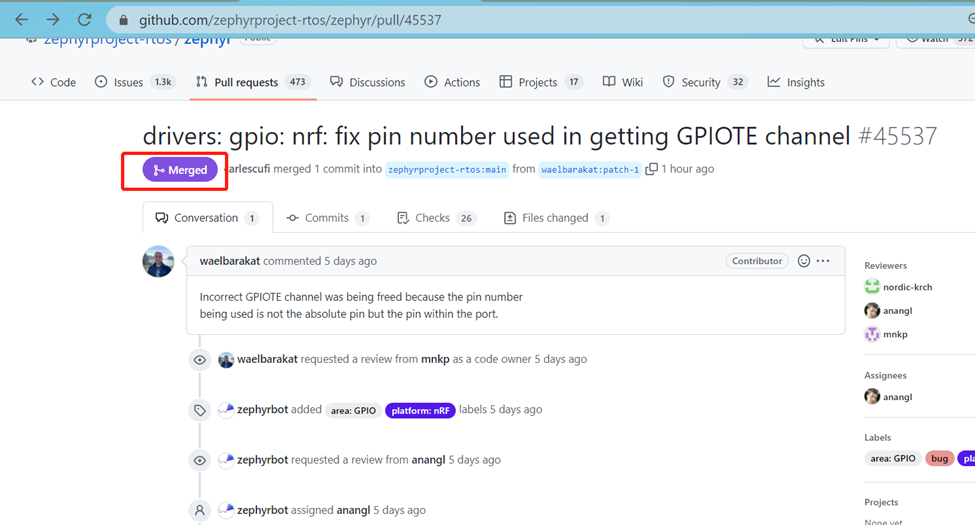
这里面还有一种特殊情况:就是你的upstream仓库还有上一级upstream仓库,这个时候你就要分清此fix是只适用于直接的upstream仓库,还是更上一级的upstream也适用,如果最最上级的upstream也适用的话,你应该把PR开在它那里,比如上面例子,https://github.com/nrfconnect/sdk-zephyr其实也是一个fork,它的upstream是:https://github.com/zephyrproject-rtos/zephyr,而且上面例子的fix是适用最原始仓库的:https://github.com/zephyrproject-rtos/zephyr,这个时候上面的PR应该直接开在https://github.com/zephyrproject-rtos/zephyr这下面,为此我们重复上面的过程(完全再来一次,而且跟上面的PR没有任何关系),最终PR的样子是下面这样的:https://github.com/zephyrproject-rtos/zephyr/pull/45537。
5. 常用Git命令说明
不管是Git软件本身,还是Git官网,都提供了非常详尽的Git命令使用说明,Git工作原理等等有关Git的一切。虽然我这篇博客非常长,但其主要目的还是帮助大家建立Git的常识,熟悉Git的一些基本用法,了解Git的基本工作原理,有了这些基础后,大家再去读Git命令使用说明或者其他Git文章,就容易得多。说到底,Git参考文档还是以Git官方为准,我们只是为大家做了一个桥梁。
Git官方参考文档为:https://git-scm.com/docs,里面列出了Git所有命令及其详尽说明。实际上,大家也不需要去访问网站,Git软件本身就自带说明文档,大家直接查看本地说明文档即可。比如git diff这个命令,我们输入
git diff --help
自动跳出如下手册页面:
里面详细列出了git diff内涵,使用说明,使用注意事项,举例等等,可以说,应有尽有,事无巨细,包罗万象,不过这带来了一个副作用:太详细了反而让读者抓不到精髓,这也是为什么市面上有那么多的Git教程的原因。笔者这篇博客希望能帮助大家理解git的帮助文档,最终达到一个境界:只需看Git官方帮助文档,就能解决碰到的所有Git问题,而无需再去网上搜索第三方的参考资料。
最后推荐一本Git专业书籍:Pro Git,整本书可以从这里获取:https://git-scm.com/book/en/v2。Pro Git是一本非常经典的介绍Git的书,我也是在写作本文的过程中无意发现了这本书,这本书不管是广度还是深度,都是可圈可点的,而且通俗易懂,深入浅出,非常适合Git学习和钻研。
介绍Git常用命令之前,我再次把下面这张Git命令操作区域关系图贴出来,这是一张来自wikipedia的图,非常直观地表达了Git常用命令的操作对象。
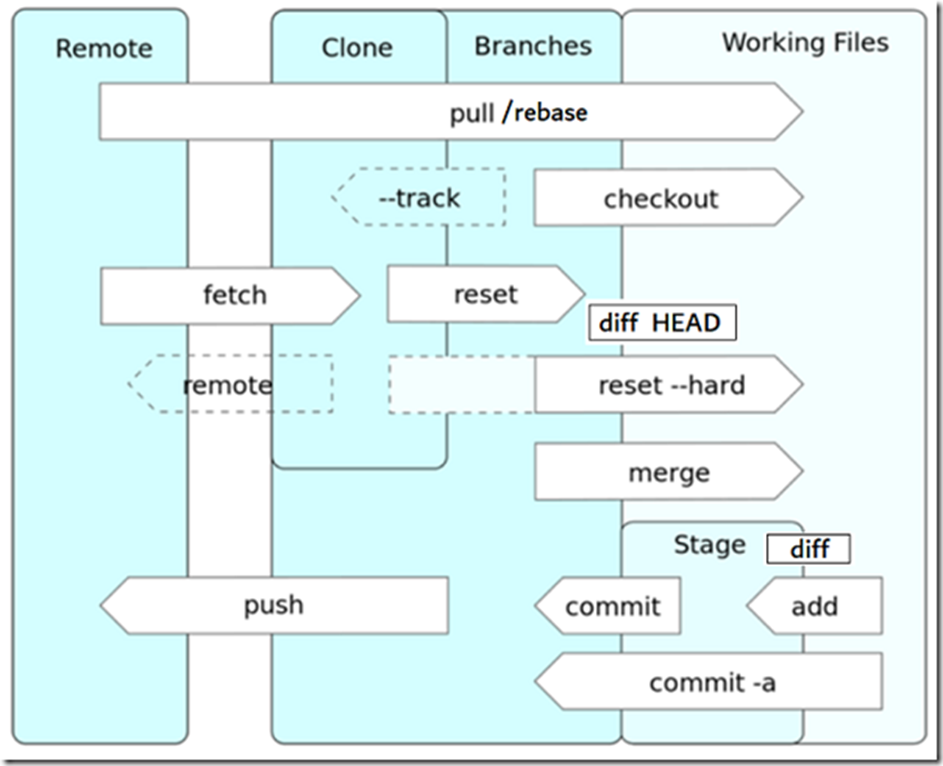
下面都是一些常用Git命令,建议大家都去了解一下。
5.1 git config
git config用于配置git软件的一些参数。
//设置邮箱和用户名(记得换成你自己的邮箱和用户名)
git config --global user.email "aimh@qq.com" git config --global user.name "Kevin Ai"
//默认分支名字改为main
git config --global init.defaultBranch main
//设置http代理或者vpn
git config https.proxy 127.0.0.1:7890 git config http.proxy 127.0.0.1:7890
//取消http代理或者vpn设置
git config --unset http.proxy
git config --unset https.proxy
//把c:/mywork(记得换成你自己的目录哦)设为安全目录
git config --global --add safe.directory c:/mywork
//所有目录都是安全的
git config --global --add safe.directory "*"
//通过浏览器打开git config的帮助页面
git config --help
5.2 git init
git init用来创建仓库。
//在当前目录创建git仓库
git init
//在新目录work/repo(记得换成你自己的目录哦)下创建git仓库
git init work/repo
5.3 git clone
git clone用于将远程仓库克隆到本地。
//克隆https://gitee.com/minhua_ai/ncs_samples.git(记得换成你自己的git服务器地址)仓库到本地
git clone https://gitee.com/minhua_ai/ncs_samples.git
//递归克隆远程仓库https://github.com/aiminhua/git_demo.git(记得换成你自己的git服务器地址),这个远程仓库包含submodule
git clone https://github.com/aiminhua/git_demo.git --recursive
5.4 git add
git add用于把工作目录更新添加到index区(stage区)。
//把工作目录所有修改添加到index
git add .
//把指定文件main.c(记得换成你自己的指定文件哦)添加到index
git add main.c
//通过浏览器打开git add的帮助页面
git add --help
5.5 git commit
git commit用于把修改提交到仓库。
//把stage内容提交到仓库,自动打开系统编辑器以让你输入提交信息
git commit
//把stage内容提交到仓库,自动打开系统编辑器以让你输入提交信息,并署名该提交
git commit -s
//把stage内容提交到仓库,提交信息为"my first repo"(记得改成你自己的提交信息)
git commit -m "my first repo"
//把working directory里面的修改直接提交到仓库,自动打开系统编辑器以让你输入提交信息
git commit -a
//把working directory里面的修改直接提交到仓库,提交信息为"updated main.c"(记得换成你自己的提交信息)
git commit -a -m "updated main.c"
//commit之后发现还有文件需要修改,修改之后,把本次修改合并在上次commit之中,而不是另起一个新commit,自动打开系统编辑器以让你更新上次的提交信息
git commit --amend
//commit之后发现还有文件需要修改,修改之后,把本次修改合并在上次commit之中,而不是另起一个新commit,并把提交信息更新为"updated main.c again"(记得换成你自己的提交信息)
git commit --amend -m "updated main.c again"
//在CMD输入多行提交信息,使用ctrl+z保存并退出输入界面,使用ctrl+c不保存退出。这个命令用得少,一般直接使用git commit就可以了
git commit -F-
5.6 git diff
git diff用来比较两个对象。
//显示所有未添加至index的变更
git diff
//显示所有已添加到index但还未commit的变更
git diff --cached
//显示与上一个commit的差异
git diff HEAD~1
//显示main分支与blinky分支的不同(记得换成你自己的分支名)
git diff main blinky
//显示master分支与blinky分支的不同(记得换成你自己的分支名)
git diff master blinky
//只显示main分支与blinky分支src目录的不同(记得换成你自己的分支和目录)
git diff main blinky -- src/*
//只显示master分支与blinky分支src目录的不同(记得换成你自己的分支和目录)
git diff master blinky -- src/*
//只统计main分支与blinky分支的文件差异,不比较内容本身差异(记得换成你自己的分支名)
git diff main blinky --stat
//比较HEAD与e6bdd4bfeb1197189e7707df1e52ddb1979cc862(这是一个对象的ID,即hash值,记得换成你自己的)的差异
git diff e6bdd4bfeb1197189e7707df1e52ddb1979cc862
//将更改输出到patch.diff文件(记得换成你的文件名,文件名和扩展名没有强制要求)
git diff > patch.diff
//通过浏览器打开git diff的帮助页面
git diff --help
5.7 git reset
git reset用来把HEAD指针复位到前面的commit。
//把HEAD复位到commit:fb863c(这是一个对象的ID,即hash值,记得换成你自己的)状态
git reset --hard fb863c
//把main分支复位到服务器clone状态
git reset --hard origin/main
//把master分支复位到服务器clone状态
git reset --hard origin/master
//复位index区
git reset
//通过浏览器打开git reset的帮助页面
git reset --help
5.8 git status
git status用于查看当前状态。
//查看working directory哪些文件修改了
git status
//通过浏览器打开git status的帮助页面
git status --help
5.9 git rm
git rm用于删除工作目录或者index区的文件。
//同时删除index和working tree里面的README.rst文件(记得换成你自己的文件)
git rm README.rst
//只删除index里面的README.rst,保留working tree里面的README.rst(记得换成你自己的文件)
git rm --cached README.rst
如果只删除working tree里面的文件,或者还没有添加到index里面的文件,请直接使用操作系统的删除命令
5.10 git log
git log显示提交历史。
//显示提交历史
git log
//显示提交历史,并统计文件修改情况
git log --stat
//显示src/main.c的提交历史(记得换成你自己的文件)
git log src/main.c
//显示src/main.c的内容修改历史—diff形式 (记得换成你自己的文件)
git log -p src/main.c
//搜索所有提交历史信息中包含"blinky"关键字的提交(记得换成你自己的关键字)
git log --grep blinky
5.11 git show
git show用于显示对象信息。
//显示e56e8a(这是一个对象的ID,即hash值,记得换成你自己的)的信息
git show e56e8a
//显示tag v1.0.0的信息(记得换成你自己的tag名称)
git show v1.0.0
//显示tag v1.0.0的名字信息(记得换成你自己的tag名称)
git show --name-only v1.0.0
//显示提交e56e8a(这是一个对象的ID,即hash值,记得换成你自己的)包含的src/main.c内容(记得换成你自己的文件)
git show e56e8a:src/main.c
5.12 git tag
git tag用于创建,列出,删除与验证tag对象。
//列出目前仓库包含的tag
git tag
//给commit e56e8a(这是一个对象的ID,即hash值,记得换成你自己的)打轻量级的tag,tag名称为v0.1(记得换成你自己的名称)
git tag v0.1 e56e8a
//给HEAD打有注解的tag,tag名称为v1.0.0(记得换成你自己的名称)
git tag -a v1.0.0 -m "git demo release v1.0.0"
//删掉tag v0.1(记得换成你自己的tag)
git tag -d v0.1
5.13 git branch
git branch用于列出,创建和删除分支。
//列出所有本地分支
git branch
//列出所有远程分支(确切说是远程跟踪分支)
git branch -r
//同时列出本地和远程分支
git branch -a
//创建一个新分支:feature(记得换成你自己的分支名)
git branch feature
//删除分支:feature(记得换成你自己的分支名)
git branch -d feature
//修改分支feature名字为dev(记得换成你自己的分支名)
git branch -m feature dev
//基于commit e56e8a(这是一个对象的ID,即hash值,记得换成你自己的)建立分支:feature(记得换成你自己的分支名)
git branch feature e56e8a
//设置当前分支跟踪origin/blinky,即origin/blinky成为它的upstream(记得换成你自己的分支名)
git branch --set-upstream-to origin/blinky
//删除远程分支blinky在本地的clone(记得换成你自己的分支名)
git branch -dr origin/blinky
5.14 git checkout
git checkout用于切换分支或者恢复工作目录内容。
//切换到blinky分支(记得换成你自己的分支名)
git checkout blinky
//切换到tag: v1.0.0(记得换成你自己的tag)
git checkout v1.0.0
//切换到commit e56e8a(这是一个对象的ID,即hash值,记得换成你自己的)
git checkout e56e8a
//创建分支blinky并切换到此分支(记得换成你自己的分支名)
git checkout -b blinky
//把index区的内容覆盖working tree
git checkout .
//把index区的src/main.c覆盖working tree里面的src/main.c(记得换成你自己的文件)
git checkout -- src/main.c
5.15 git merge
git merge用于合并开发历史。
//将远程跟踪分支origin/main合并到当前分支
git merge origin/main
//将远程跟踪分支origin/ master合并到当前分支
git merge origin/master
//将blinky分支合并到当前分支(记得换成你自己的分支名)
git merge blinky
//手动解决冲突后,继续刚才有冲突的merge,完成merge过程
git merge --continue
//中止刚才有冲突的merge
git merge --abort
5.16 git rebase
git rebase用于将当前分支分叉后的所有commit重新提交在新分支的末端。
//将当前分支分叉后的所有commit重新提交在main分支的末端
git rebase main
//将当前分支分叉后的所有commit重新提交在master分支的末端
git rebase master
//手动解决冲突后继续rebase操作以完成整个操作
git rebase --continue
//跳过本commit继续rebase过程
git rebase --skip
//中止rebase过程
git rebase --abort
5.17 git remote
git remote用于管理远程跟踪仓库。
//查看当前所有远程跟踪仓库
git remote -v
//显示远程仓库origin的信息
git remote show origin
//将https://github.com/aiminhua/git_demo.git(记得换成自己的git服务器地址)设为远程跟踪仓库,并命名为origin
git remote add origin https://github.com/aiminhua/git_demo.git
//删除远程跟踪仓库origin
git remote remove origin
5.18 git push
git push将本地内容推送到远程服务器。
//将当前分支推送到远程origin仓库的main分支
git push -u origin main
//将当前分支推送到远程origin仓库的master分支
git push -u origin master
//将当前分支推送到远程origin仓库的blinky分支(记得换成你自己的分支名)
git push -u origin blinky
//推送tag:v1.0.0到远程服务器(记得换成你自己的tag)
git push origin v1.0.0
//推送所有跟踪分支到远程服务器
git push
//删除远程服务器的blinky分支(记得换成你自己的分支名)
git push origin --delete blinky
5.19 git fetch
git fetch用于下载远程仓库更新到本地。
//下载origin仓库的更新到本地clone区
git fetch origin
//下载所有关联的远程仓库
git fetch
//下载远程仓库的pull request#2518(记得换成你自己的pull request编号)到本地分支:smp_ota(记得换成你自己的分支名)。
git fetch origin pull/2518/head:smp_ota
5.20 git pull
git pull用于集成远程分支更新到本地分支,是git fetch和git rebase/merge的合体。
//将当前分支rebase到远程跟踪分支origin/main
git pull --rebase origin main
//将当前分支rebase到远程跟踪分支origin/ master
git pull --rebase origin master
//将远程origin/main分支merge到当前分支
git pull origin main
//将远程origin/master分支merge到当前分支
git pull origin master
//取所有远程分支,并将当前分支的upstream分支merge过来
git pull
//下载远程仓库的pull request#2518(记得换成你自己的pull request编号)到本地分支:smp_ota(记得换成你自己的分支名)
git pull origin pull/2518/head:smp_ota
//通过浏览器打开git pull的帮助页面
git pull --help
5.21 git revert
git revert用于覆盖最近几次的提交,即把历史中的一次提交重新在分支顶端提交一次。
//把前一次提交再重新提交一次,相当于前一次提交覆盖了当前提交
git revert HEAD~1
//把commit:fb863c(这是一个对象的ID,即hash值,记得换成你自己的)重新提交在分支最顶端
git revert fb863c
5.22 git restore
git restore用于恢复工作目录或者index区里面的文件。
//将index中的src/main.c内容恢复到工作区的src/main.c(记得换成你自己的文件)
git restore src/main.c
//恢复index中的README.rst至HEAD状态(记得换成你自己的文件)
git restore --staged README.rst
//将tag:v1.0.0(记得换成你自己的tag)中的src/main.c内容恢复到工作区的src/main.c(记得换成你自己的文件)
git restore --source=v1.0.0 src/main.c
5.23 git reflog
git reflog用于管理引用日志信息,包括多个子命令,默认git reflog等价于git reflog show。
//显示HEAD的所有更新操作日志,包括那些删除了或者不可达的commit
git reflog
//显示main分支的所有更新操作日志,包括那些删除了或者不可达的commit
git reflog main
//显示master分支的所有更新操作日志,包括那些删除了或者不可达的commit
git reflog master
5.24 git stash
git stash用于将working tree的修改暂时压栈。
//将working tree里面的修改压入stash栈
git stash
//将stash栈中的内容弹出到工作区
git stash pop
//显示stash栈里面的内容
git stash show
5.25 git submodule
git submodule用于初始化,更新和查看submodule。
//把https://github.com/aiminhua/ncs_samples.git(记得换成自己的git服务器地址)添加为本仓库的子模块并放在ncs(记得换成自己的目录)目录下
git submodule add https://github.com/aiminhua/ncs_samples.git ncs
//从服务器下载submodule的更新,如果没有初始化,则对其先进行初始化
git submodule update --init
//反初始化ncs(记得换成自己的目录)这个submodule
git submodule deinit ncs
//通过浏览器打开git submodule的帮助页面
git submodule --help
5.26 git subtree
git subtree用于包含第三方库到主工程中,这个第三方库的历史记录成了主工程的一部分。
//包含https://gitee.com/minhua_ai/ncs_samples.git(记得换成自己的git服务器地址)为当前仓库下的一个子库,所有代码放在ncs(记得换成自己的目录)目录下,--squash表示只把最后一条提交记录加在主库的历史记录中
git subtree add --prefix ncs https://gitee.com/minhua_ai/ncs_samples.git master --squash
//更新这个subtree子库,参数说明同上
git subtree pull --prefix ncs https://gitee.com/minhua_ai/ncs_samples.git master --squash
//通过浏览器打开git subtree的帮助页面
git subtree --help
5.27 git cherry-pick
git cherry-pick用于merge指定的commit到当前分支。
//将提交b03a94fa9245abf41538028450a9c675067d6e4f(这是一个对象的ID,即hash值,记得换成你自己的)的修改merge到当前分支
git cherry-pick b03a94fa9245abf41538028450a9c675067d6e4f
5.28 git grep
git grep用于使用正则表达式搜索整个仓库。
//在工作目录中搜索包含"blinky"关键字的文件(记得换成自己的关键字)
git grep "blinky"
//通过浏览器打开git grep的帮助页面
git grep --help
5.29 git apply
git apply用于把补丁(diff文件)应用在当前工作目录,该工作目录可以不关联一个git仓库。
//把patch.diff(记得换成你自己的文件)文件应用在当前目录及子目录,当前目录以外的忽略。注:diff文件的生成请见git diff命令说明
git apply patch.diff
//通过浏览器打开git apply的帮助页面
git apply --help
5.30 git cat-file
git cat-file用于查看仓库对象的内容。
//查看fb863cc95ca4a80fe64e51addd1db6a3910ee69e(这是一个对象的ID,即hash值,记得换成你自己的)这个对象的内容
git cat-file -p fb863cc95ca4a80fe64e51addd1db6a3910ee69e
5.31 git ls-files
git ls-files用于查看index或者工作目录中的文件。
//列出index中的所有文件
git ls-files -s
//列出工作目录中的所有文件
git ls-files
5.32 git merge-file
git merge-file只merge一个文件,这个文件可以不关联git仓库。
//把other.c文件相对于base.c文件的diff输出到current.c文件(记得换成你自己的文件)
git merge-file current.c base.c other.c
//通过浏览器打开git merge-file的帮助页面
git merge-file --help
5.33 git gc
git gc用于清理git仓库不需要的文件以及对Git仓库进行压缩优化,一般不需要你自己去跑这条指令,系统自动会去做git gc操作。
git gc
6. Git重要术语列表
下面是Git重要术语列表,他们都直接摘自Git官网,原文链接为:https://git-scm.com/docs/gitglossary#def_parent。
branch
A "branch" is a line of development. The most recent commit on a branch is referred to as the tip of that branch. The tip of the branch is referenced by a branch head, which moves forward as additional development is done on the branch. A single Git repository can track an arbitrary number of branches, but your working tree is associated with just one of them (the "current" or "checked out" branch), and HEAD points to that branch.
checkout
The action of updating all or part of the working tree with a tree object or blob from the object database, and updating the index and HEAD if the whole working tree has been pointed at a new branch.
cherry-picking
In SCM jargon, "cherry pick" means to choose a subset of changes out of a series of changes (typically commits) and record them as a new series of changes on top of a different codebase. In Git, this is performed by the "git cherry-pick" command to extract the change introduced by an existing commit and to record it based on the tip of the current branch as a new commit.
commit
As a noun: A single point in the Git history; the entire history of a project is represented as a set of interrelated commits. The word "commit" is often used by Git in the same places other revision control systems use the words "revision" or "version". Also used as a short hand for commit object.
As a verb: The action of storing a new snapshot of the project's state in the Git history, by creating a new commit representing the current state of the index and advancing HEAD to point at the new commit.
core Git
Fundamental data structures and utilities of Git. Exposes only limited source code management tools.
detached HEAD
Normally the HEAD stores the name of a branch, and commands that operate on the history HEAD represents operate on the history leading to the tip of the branch the HEAD points at. However, Git also allows you to check out an arbitrary commit that isn't necessarily the tip of any particular branch. The HEAD in such a state is called "detached".
Note that commands that operate on the history of the current branch (e.g. git commit to build a new history on top of it) still work while the HEAD is detached. They update the HEAD to point at the tip of the updated history without affecting any branch. Commands that update or inquire information about the current branch (e.g. git branch --set-upstream-to that sets what remote-tracking branch the current branch integrates with) obviously do not work, as there is no (real) current branch to ask about in this state.
fast-forward
A fast-forward is a special type of merge where you have a revision and you are "merging" another branch's changes that happen to be a descendant of what you have. In such a case, you do not make a new merge commit but instead just update your branch to point at the same revision as the branch you are merging. This will happen frequently on a remote-tracking branch of a remote repository.
fetch
Fetching a branch means to get the branch's head ref from a remote repository, to find out which objects are missing from the local object database, and to get them, too. See also git-fetch[1].
hash
In Git's context, synonym for object name.
head
A named reference to the commit at the tip of a branch. Heads are stored in a file in $GIT_DIR/refs/heads/ directory, except when using packed refs. (See git-pack-refs[1].)
HEAD
The current branch. In more detail: Your working tree is normally derived from the state of the tree referred to by HEAD. HEAD is a reference to one of the heads in your repository, except when using a detached HEAD, in which case it directly references an arbitrary commit.
head ref
A synonym for head.
index
A collection of files with stat information, whose contents are stored as objects. The index is a stored version of your working tree. Truth be told, it can also contain a second, and even a third version of a working tree, which are used when merging.
index entry
The information regarding a particular file, stored in the index. An index entry can be unmerged, if a merge was started, but not yet finished (i.e. if the index contains multiple versions of that file).
master
The default development branch. Whenever you create a Git repository, a branch named "master" is created, and becomes the active branch. In most cases, this contains the local development, though that is purely by convention and is not required.
merge
As a verb: To bring the contents of another branch (possibly from an external repository) into the current branch. In the case where the merged-in branch is from a different repository, this is done by first fetching the remote branch and then merging the result into the current branch. This combination of fetch and merge operations is called a pull. Merging is performed by an automatic process that identifies changes made since the branches diverged, and then applies all those changes together. In cases where changes conflict, manual intervention may be required to complete the merge.
As a noun: unless it is a fast-forward, a successful merge results in the creation of a new commit representing the result of the merge, and having as parents the tips of the merged branches. This commit is referred to as a "merge commit", or sometimes just a "merge".
object
The unit of storage in Git. It is uniquely identified by the SHA-1 of its contents. Consequently, an object cannot be changed.
object database
Stores a set of "objects", and an individual object is identified by its object name. The objects usually live in $GIT_DIR/objects/.
object identifier
Synonym for object name.
object name
The unique identifier of an object. The object name is usually represented by a 40 character hexadecimal string. Also colloquially called SHA-1.
object type
One of the identifiers "commit", "tree", "tag" or "blob" describing the type of an object.
index
A collection of files with stat information, whose contents are stored as objects. The index is a stored version of your working tree. Truth be told, it can also contain a second, and even a third version of a working tree, which are used when merging.
index entry
The information regarding a particular file, stored in the index. An index entry can be unmerged, if a merge was started, but not yet finished (i.e. if the index contains multiple versions of that file).
master
The default development branch. Whenever you create a Git repository, a branch named "master" is created, and becomes the active branch. In most cases, this contains the local development, though that is purely by convention and is not required.
merge
As a verb: To bring the contents of another branch (possibly from an external repository) into the current branch. In the case where the merged-in branch is from a different repository, this is done by first fetching the remote branch and then merging the result into the current branch. This combination of fetch and merge operations is called a pull. Merging is performed by an automatic process that identifies changes made since the branches diverged, and then applies all those changes together. In cases where changes conflict, manual intervention may be required to complete the merge.
As a noun: unless it is a fast-forward, a successful merge results in the creation of a new commit representing the result of the merge, and having as parents the tips of the merged branches. This commit is referred to as a "merge commit", or sometimes just a "merge".
object
The unit of storage in Git. It is uniquely identified by the SHA-1 of its contents. Consequently, an object cannot be changed.
object database
Stores a set of "objects", and an individual object is identified by its object name. The objects usually live in $GIT_DIR/objects/.
object identifier
Synonym for object name.
object name
The unique identifier of an object. The object name is usually represented by a 40 character hexadecimal string. Also colloquially called SHA-1.
object type
One of the identifiers "commit", "tree", "tag" or "blob" describing the type of an object.
octopus
To merge more than two branches.
origin
The default upstream repository. Most projects have at least one upstream project which they track. By default origin is used for that purpose. New upstream updates will be fetched into remote-tracking branches named origin/name-of-upstream-branch, which you can see using git branch -r.
overlay
Only update and add files to the working directory, but don't delete them, similar to how cp -R would update the contents in the destination directory. This is the default mode in a checkout when checking out files from the index or a tree-ish. In contrast, no-overlay mode also deletes tracked files not present in the source, similar to rsync --delete.
pack
A set of objects which have been compressed into one file (to save space or to transmit them efficiently).
pack index
The list of identifiers, and other information, of the objects in a pack, to assist in efficiently accessing the contents of a pack.
plumbing
Cute name for core Git.
porcelain
Cute name for programs and program suites depending on core Git, presenting a high level access to core Git. Porcelains expose more of a SCM interface than the plumbing.
pull
Pulling a branch means to fetch it and merge it. See also git-pull[1].
push
Pushing a branch means to get the branch's head ref from a remote repository, find out if it is an ancestor to the branch's local head ref, and in that case, putting all objects, which are reachable from the local head ref, and which are missing from the remote repository, into the remote object database, and updating the remote head ref. If the remote head is not an ancestor to the local head, the push fails.
rebase
To reapply a series of changes from a branch to a different base, and reset the head of that branch to the result.
ref
A name that begins with refs/ (e.g. refs/heads/master) that points to an object name or another ref (the latter is called a symbolic ref). For convenience, a ref can sometimes be abbreviated when used as an argument to a Git command; see gitrevisions[7] for details. Refs are stored in the repository.
The ref namespace is hierarchical. Different subhierarchies are used for different purposes (e.g. the refs/heads/ hierarchy is used to represent local branches).
There are a few special-purpose refs that do not begin with refs/. The most notable example is HEAD.
reflog
A reflog shows the local "history" of a ref. In other words, it can tell you what the 3rd last revision in this repository was, and what was the current state in this repository, yesterday 9:14pm. See git-reflog[1] for details.
refspec
A "refspec" is used by fetch and push to describe the mapping between remote ref and local ref.
remote repository
A repository which is used to track the same project but resides somewhere else. To communicate with remotes, see fetch or push.
remote-tracking branch
A ref that is used to follow changes from another repository. It typically looks like refs/remotes/foo/bar (indicating that it tracks a branch named bar in a remote named foo), and matches the right-hand-side of a configured fetch refspec. A remote-tracking branch should not contain direct modifications or have local commits made to it.
repository
A collection of refs together with an object database containing all objects which are reachable from the refs, possibly accompanied by meta data from one or more porcelains. A repository can share an object database with other repositories via alternates mechanism.
resolve
The action of fixing up manually what a failed automatic merge left behind.
revision
Synonym for commit (the noun).
SCM
Source code management (tool).
SHA-1
"Secure Hash Algorithm 1"; a cryptographic hash function. In the context of Git used as a synonym for object name.
shallow repository
A shallow repository has an incomplete history some of whose commits have parents cauterized away (in other words, Git is told to pretend that these commits do not have the parents, even though they are recorded in the commit object). This is sometimes useful when you are interested only in the recent history of a project even though the real history recorded in the upstream is much larger. A shallow repository is created by giving the --depth option to git-clone[1], and its history can be later deepened with git-fetch[1].
stash entry
An object used to temporarily store the contents of a dirty working directory and the index for future reuse.
submodule
A repository that holds the history of a separate project inside another repository (the latter of which is called superproject).
superproject
A repository that references repositories of other projects in its working tree as submodules. The superproject knows about the names of (but does not hold copies of) commit objects of the contained submodules.
tag
A ref under refs/tags/ namespace that points to an object of an arbitrary type (typically a tag points to either a tag or a commit object). In contrast to a head, a tag is not updated by the commit command. A Git tag has nothing to do with a Lisp tag (which would be called an object type in Git's context). A tag is most typically used to mark a particular point in the commit ancestry chain.
tag object
An object containing a ref pointing to another object, which can contain a message just like a commit object. It can also contain a (PGP) signature, in which case it is called a "signed tag object".
tree
Either a working tree, or a tree object together with the dependent blob and tree objects (i.e. a stored representation of a working tree).
tree object
An object containing a list of file names and modes along with refs to the associated blob and/or tree objects. A tree is equivalent to a directory.
unmerged index
An index which contains unmerged index entries.
unreachable object
An object which is not reachable from a branch, tag, or any other reference.
upstream branch
The default branch that is merged into the branch in question (or the branch in question is rebased onto). It is configured via branch.<name>.remote and branch.<name>.merge. If the upstream branch of A is origin/B sometimes we say "A is tracking origin/B".
working tree
The tree of actual checked out files. The working tree normally contains the contents of the HEAD commit's tree, plus any local changes that you have made but not yet committed.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号