[k8s]zookeeper集群在k8s的搭建(statefulset模式)-pod的调度
之前一直docker-compose跑zk集群,现在把它挪到k8s集群里.
docker-compose跑zk集群
zk集群in k8s部署
参考:
https://github.com/kubernetes/contrib/blob/master/statefulsets/zookeeper/zookeeper.yaml
https://kubernetes.io/docs/tutorials/stateful-application/zookeeper/
我修改了下默认的yaml
1.zk.yaml的存储,存储指向了我自己的nfs-backend
2.修改了image,拉倒了dockerhub
[root@m1 ~]# cat zookeeper.yaml
---
apiVersion: v1
kind: Service
metadata:
name: zk-svc
labels:
app: zk-svc
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: ConfigMap
metadata:
name: zk-cm
data:
jvm.heap: "1G"
tick: "2000"
init: "10"
sync: "5"
client.cnxns: "60"
snap.retain: "3"
purge.interval: "0"
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
minAvailable: 2
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: zk
spec:
serviceName: zk-svc
replicas: 3
template:
metadata:
labels:
app: zk
spec:
#affinity:
# podAntiAffinity:
# #requiredDuringSchedulingIgnoredDuringExecution:
# preferredDuringSchedulingIgnoredDuringExecution:
# cpu: "500m"
# - labelSelector:
# matchExpressions:
# - key: "app"
# operator: In
# values:
# - zk
# topologyKey: "kubernetes.io/hostname"
containers:
- name: k8szk
imagePullPolicy: Always
image: lanny/gcr.io_google_samples_k8szk:v3
resources:
requests:
memory: "2Gi"
cpu: "500m"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
env:
- name : ZK_REPLICAS
value: "3"
- name : ZK_HEAP_SIZE
valueFrom:
configMapKeyRef:
name: zk-cm
key: jvm.heap
- name : ZK_TICK_TIME
valueFrom:
configMapKeyRef:
name: zk-cm
key: tick
- name : ZK_INIT_LIMIT
valueFrom:
configMapKeyRef:
name: zk-cm
key: init
- name : ZK_SYNC_LIMIT
valueFrom:
configMapKeyRef:
name: zk-cm
key: tick
- name : ZK_MAX_CLIENT_CNXNS
valueFrom:
configMapKeyRef:
name: zk-cm
key: client.cnxns
- name: ZK_SNAP_RETAIN_COUNT
valueFrom:
configMapKeyRef:
name: zk-cm
key: snap.retain
- name: ZK_PURGE_INTERVAL
valueFrom:
configMapKeyRef:
name: zk-cm
key: purge.interval
- name: ZK_CLIENT_PORT
value: "2181"
- name: ZK_SERVER_PORT
value: "2888"
- name: ZK_ELECTION_PORT
value: "3888"
command:
- sh
- -c
- zkGenConfig.sh && zkServer.sh start-foreground
readinessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
securityContext:
runAsUser: 1000
fsGroup: 1000
volumeClaimTemplates:
- metadata:
name: datadir
annotations:
#volume.alpha.kubernetes.io/storage-class: "managed-nfs-storage" #不同版本这里引用的alpha/beta不同注意
volume.beta.kubernetes.io/storage-class: "managed-nfs-storage"
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
遇到的问题: zk-3一直pending
第三台老pending(我只有2个node节点)
$ kubectl get po --all-namespaces
cNAMESPACE NAME READY STATUS RESTARTS AGE IP NODE LABELS
default zk-0 1/1 Running 0 11m 10.2.30.5 n2.ma.com app=zk,controller-revision-hash=zk-1636685058
default zk-1 1/1 Running 0 10m 10.2.54.3 n1.ma.com app=zk,controller-revision-hash=zk-1636685058
default zk-2 0/1 Pending 0 10m <none> <none> app=zk,controller-revision-hash=zk-1636685058
zk-3一直pending解决(调度策略)
zk的yaml的默认调度策略是这样的(每个物理节点对应一个zk节点,所以第三台zk节点一直pending)
kubectl describe po zk-2
...
No nodes are available that match all of the following predicates:: MatchInterPodAffinity (2).
细看了下zk的yaml他的调度策略是这样的,每节点一个zk节点,而我只有2个node,因此暂时先把它注释掉
#affinity:
# podAntiAffinity:
# #requiredDuringSchedulingIgnoredDuringExecution:
# preferredDuringSchedulingIgnoredDuringExecution:
# cpu: "500m"
# - labelSelector:
# matchExpressions:
# - key: "app"
# operator: In
# values:
# - zk
# topologyKey: "kubernetes.io/hostname"
节点亲和调度 pod亲和调度

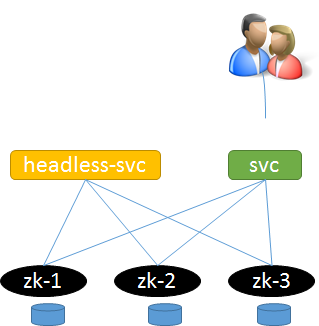
集群内如何访问headless服务?
思路: 可以新建一个非headless的svc.用于针对用户访问.