C++引用 | 什么是引用
引用
我们知道C语言以指针著名
C++大佬在发明C++的过程中,觉得指针有些难,就发明了引用
引用是什么?
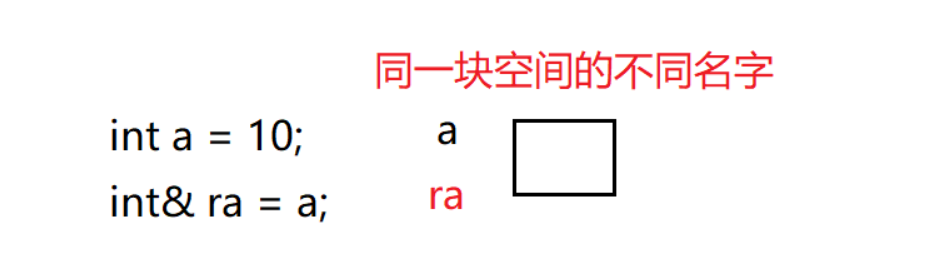
引用并不是定义一个新的变量,而是给一个已存在的变量取一个别名.
编译器不会给引用变量开辟内存空间 , 这个别名 和它引用的的变量(原变量) 共用同一块内存空间
简单来说就是 : 引用变量和原变量的地址相同 就是同一块空间的不同名字
定义方法
类型& 引用变量名(对象名) = 引用实体
int main()
{
int a=10;
int& ra=a;//这就是给a取别名 叫ra
printf("%d\n",a);//输出10
printf("%d\n",ra);// 也是输出10
return 0;
}
可以观察他们的地址:

ra 和 a 的地址是一样的, 也就是说,他们共用一块内存空间,只是叫法不同而已
所以,用变量 或者变量的引用 都会引起内存空间值的变化
引用特性
-
引用必须在定义的时候初始化 (因为是给别的变量起别名,所以别名不会单独存在,首先需要有一个引用对象才可以)
-
一个变量可以有多个引用(一个人可以有多个外号),同样的一块空间也可以有多个名字
-
一个引用一旦引用一个实体,就不能再引用其他实体(也就是说,引用只能在定义的时候初始化,其他时候再赋值 其实就是对引用所指的那块内存空间进行赋值了)(java中的引用可以改变指向,C++不可以)
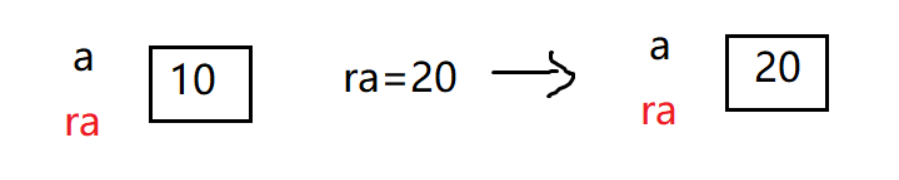
引用的应用场景
1.做参数
-
输出型参数: 参数传进去进行改变,外面可以拿到改变的值(也就是改变外部变量的值) -- 比如交换函数(交换两个变量的值)
void Swap(int& a, int& b) { //利用别名修改内存的值 int tmp = a; a = b; b = tmp; } int main() { int a = 10; int b = -10; cout << "交换前:" << " a= " << a << " b= " << b << endl; Swap(a, b);//传递a和b的值 但是用a和b的引用来接收(也就是给a和b都起别名) cout << "交换后:" << " a= " << a << " b= " << b << endl; return 0; }形参利用引用接收,那么形参就是两个实参的别名, 那么对形参的修改也就会影响到内存空间的值,从而实现对变量的改变
另一个例子: 我们知道链表需要传递二级指针,从而对头指针进行修改, 二级指针 就可以替换成引用
- 形参作为头指针的别名
//写法1: typedef struct SListNode{ int val; struct ListNode* next; }SListNode, *PSListNode; /*后面这里把 SListNode* 类型typedef为 PSListNode*/ //头插 //写法1: void SListPushBack(ListNode*& phead,int val) { //形参为头指针的别名 //形参的改变会影响实参 /** *.... */ } //写法2: //PSListNode 其实就等价于方法1的 ListNode* void SListPushBack(PSListNode& phead,int val) { /****/ } int main() { SListNode* list=NULL;//定义头指针 SListPushBack(list,1); SListPushBack(list,2); SListPushBack(list,3); return 0; } -
大对象传参,提高效率
因为值传递形参会拷贝一份实参,而引用传参并不会开辟空间
只是起一个别名,所以提高效率
测试:
//大型参数传参 #include <time.h> struct A { int a[10000]; }; void TestFunc1(A a) {} void TestFunc2(A& a) {} void TestRefAndValue() { A a; // 以值作为函数参数 size_t begin1 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc1(a);//每次传参拷贝40000个字节 size_t end1 = clock(); // 以引用作为函数参数 size_t begin2 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc2(a); size_t end2 = clock(); // 分别计算两个函数运行结束后的时间 cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; } /* 输出 */ // 8 --值传参耗时(ms) // 0 --引用传参耗时(ms) 可以看出 消耗是有差别的 引用传参 基本无消耗,而值传参是有一定消耗的
2.做返回值
回顾一下传值返回
只要是传值返回,不管函数中的变量是在静态区还是在栈区(因为他不能智能去识别)
都是会生成一个对象的拷贝,作为函数调用的返回值
/** 传值返回 **/
int test1()
{
int n=0;
n++;
return n;
}
//上面返回n的时候 其实是先把n放到寄存器中
// 然后利用寄存器把 值给带出来
// 此时函数已经销毁
/**
如果要返回的对象不是int类型 是很大的对象
那么就不会放在寄存器中,因为寄存器的容量很小 一般是4-8字节
此时就会在main函数的栈帧中提前开辟好一块临时空间保存返回值
*/
/* 如果要返回的值 保存在静态区 */
int test2()
{
//此时n为静态变量 保存在静态区
//函数调用完成 不被销毁
// 此时返回的时候 也会创建临时空间去保存返回值
// 因为编译器只会看 你是传值返回 就回去利用临时变量
// 去保存返回值
static n = 0;
n++;
return n;
}
int main()
{
int ret=test1();//接收寄存器中的值
return 0;
}
-
传引用返回
传引用返回的语法含义就是 返回 返回对象的别名
int& func() { int n=0; n++; return n; } //上面的函数 返回的是n的别名 (编译器给n的内存空间起了一个别名 并返回这个别名) int main() { //给编译器返回的别名又起了一个别名叫ret // 其实就是func中n的别名 int& ret=func(); //此时ret和上面func函数中的n表示的是同一块内存空间 printf("%d\n",ret);//第一次调用 printf("%d\n",ret);//第二次调用 return 0; } //输出 // --> 1 // --> 5187647其实ret的结果是未定义的,(函数调用完成之后ret那块空间已经不属于我们了) 如果栈帧结束的时候,系统会清理栈帧置成随机值,那么ret 的结果就是随机值. 在VS下,这一次函数调用完并不会接着清理栈帧空间, 下一次调用函数才会清理栈帧重置为另一个函数的栈帧. 原来栈帧的内容被覆盖了,所以第一次调用printf 结果是 1
而第二次就是随机值 了(第二次清理了栈帧)
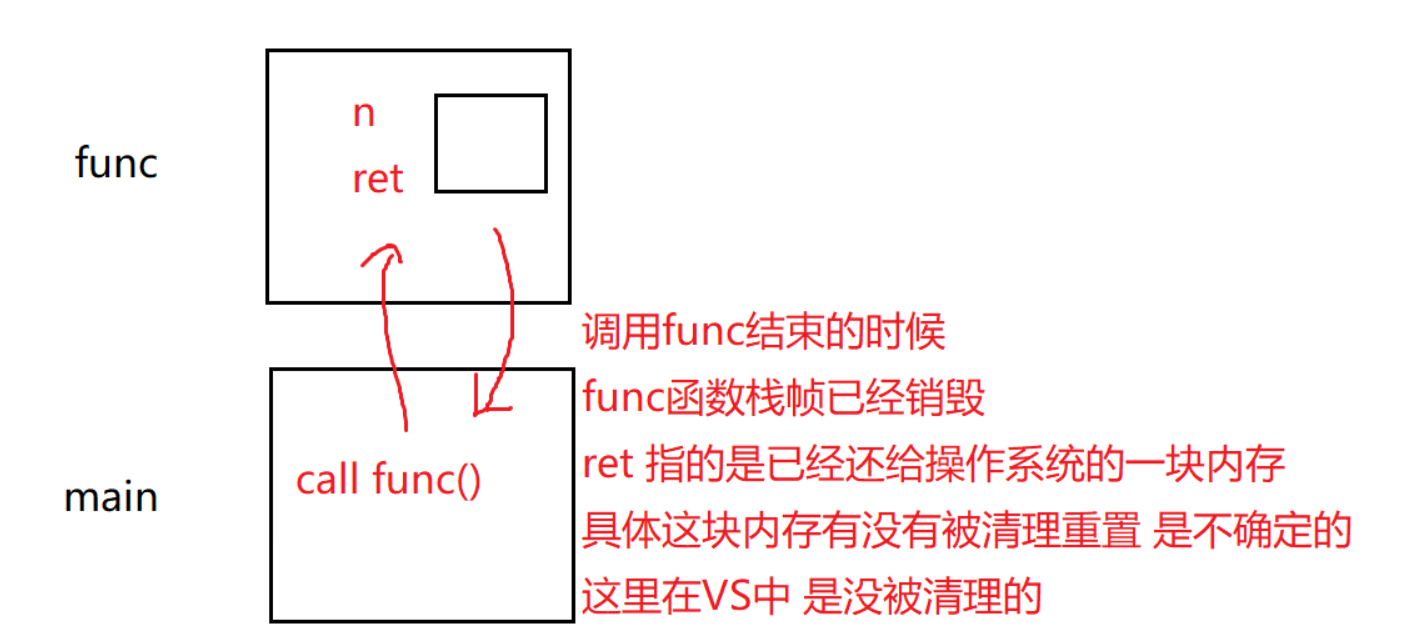
所以上面这种情况使用引用返回是不对的 , 结果是没有保障的!
另一个例子
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main6()
{
int& ret = Add(1, 2);
Add(3, 4);
Add(9, 4);
cout << "Add(1,2) is : " << ret << endl;
return 0;
}
//输出
//-->13
//会发现,ret的值总是最后一次调用Add()的结果
// 这是因为 ret就是 Add()内部的c的引用,也就是每一次ret的值与那块内存的值有关
// 每一次调用Add() 编译器把每一次c的位置都设置在那里(取决于编译器的特性)
// 所以每一次c的值都会改变 所以ret是最后一次调用Add()之后的值
如果除了函数作用域,返回对象就销毁了.那么一定不能用引用返回,一定要用传值返回
引用的正确使用情况:
int& func()
{
static int n = 0;
n++;
return n;
}
//n出了函数作用域 不会被销毁
// 可以使用引用返回
3.引用返回的有意义场景
在顺序表中,如果要修改某个位置的元素
我们通常是传入修改的位置,还有修改成的元素
void SeqListModify(SeqList& s,int pos, int val)
但是可以利用引用做返回值实现更方便的修改方法
//如图 传入pos(位置)
// 返回pos位置处元素的引用(别名)
int& SeqlistAt(SeqList& slist, int pos)
{
assert(pos >= 0 && pos < slist.size);
return slist.a[pos];
}
//在main函数中 可以直接进行修改也可以打印
int main()
{
SeqList st;
SeqListInit(st);
SeqListPushBack(st, 1);
SeqListPushBack(st, 2);
SeqListPushBack(st, 3);
//可以利用SeqListAt函数直接输出
for (int i=0;i<st.size;i++)
{
cout << SeqlistAt(st,i) << " ";
}
cout << endl;
//直接拿到0位置元素进行修改即可
SeqlistAt(st, 0) = 10;
for (int i = 0; i < st.size; i++)
{
cout << SeqlistAt(st, i) << " ";
}
return 0;
}
此时返回的是 返回对象的引用,所以不会进行拷贝,也提升了效率
引用总结
- 做参数
1. 输出型参数 2. 大对象传参,提高效率
- 2. 做返回值
1. 做输出型返回对象,调用者可以修改返回对象 2. 减少拷贝,提高效率
前提:出了函数作用域,返回对象不会被销毁的时候才能做引用返回
常引用
引用是给一个变量取别名
-
一个int类型变量的别名,类型也是int类型
但是如果是一个const int类型变量的别名, 类型也应该是const int类型(权限的平移)
-
一个const int类型的变量 或者是一个常量 是不可以修改的 ,如果他的别名用int& 来接收
相当于他的别名的类型就是 int类型 ,显然通过别名可以修改 内存空间的值 , 但是这块空间本来就是不可以修改的! 所以会报错 (权限放大不可以)
-
但是一个int类型的变量 别名可以是 const int类型 (权限的缩小是可以的)
/**
* 常引用
*/
int main7()
{
const int a = 10;
//int& ra = a;会报错,给一个常变量起别名,必须加const
//给这个变量起一个别名,这个别名的类型和原类型必须相同
// 否则就是(权限的放大)
// int& ra = 100;//也是权限的放大
const int& ra = a;//正确(权限的平移)
cout << a << endl;
cout << ra << endl;
//权限的缩小
int b = 20;
const int& rb = b;
//这时候 可以利用b对该内存的值进行修改
// 但是不可以利用rb进行修改, 该别名的权限是只读(权限缩小了)
cout << &b << endl;
cout << &rb << endl;
/* 另一个例子 */
int aa = 10;
double bb = 20;
//int& raa = b;//b是一个double类型,赋值的时候需要隐式类型转换,此时会把b的值拿出来 创建一个临时变量,因为不会对原变量进行转换,所以只是把原变量的值拿出来转化后放入临时变量,临时变量再赋给raa .临时变量具有常性,所以 应该赋值给一个const
const int& raa = bb;
cout << raa << endl;
return 0;
注意: 所有的隐式转换/算术提升/强转,都会产生一个临时变量 , 而不是对原变量进行修改
如果使用引用传参,并且函数内不改变实参的值,那么尽量使用const引用传参
就像指针中 使用const修饰的指针那样(一个效果)
引用和指针的区别
-
使用场景以及语法特性方面
一般来说 指针能完成的事情,用引用都可替代
除了一种情况: 链表的链式访问的地方,必须用指针
因为引用一旦引用一个对象 就不能引用其他对象了(不能变指向), 并且引用定义的时候必须初始化
-
底层原理
从语法的角度来看,引用并没有开辟空间,而指针会开辟 4 / 8 个字节
但是在底层并不是这样的
我们通过观察汇编语言来了解一下:
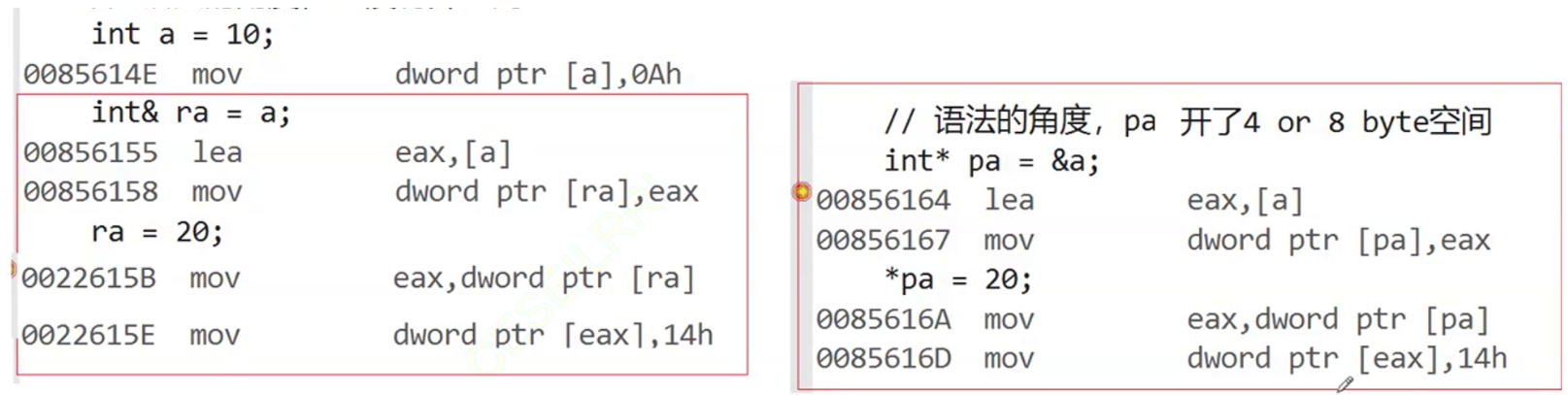
发现用引用 和 用指针 他们的汇编语言是一样的, 都是
- 把a的地址取出来放到eax寄存器
- 把eax中的内容放到 pa所在内存里(pa中存放a的地址)
- 把pa内存空间里的内容(a的地址) 放到eax里面
- 对eax里面的内容(a的地址)解引用 , 把14h(即十进制的10) 写进去( 也就是对a进行了赋值)
显然,引用的底层 就是指针实现的 , 也就是说 ,引用也会开辟空间
开辟空间的大小是4/8字节(地址的大小)
总结(指针的引用的区别)
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型
实体 - 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占
4个字节) - 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
本文作者:夏季微凉"
本文链接:https://www.cnblogs.com/iiianKor/p/17982033
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通