

初识爬虫
1.爬虫的概念
(1)爬虫又叫网页蜘蛛,是模拟人操作客户端向服务器发起请求,抓取数据的自动化程序或脚本。
(2)说明:
① 模拟:用爬虫程序伪装出人的行为,避免被服务器识别为爬虫程序;
② 客户端:浏览器、app都可以实现人与服务器之间的交互行为,应用客户端从服务器获取数据;
③ 自动化: 数据量较小可以人工获取,但往往公司里爬取的数据量在百万条、千万条级别,所以要程序自动化获取数据。
2.爬虫分类
(1) 通用爬虫:爬取网页数据,为搜索引擎提供检索服务;
(2) 聚焦爬虫:针对某一领域爬取特定数据的爬虫,聚焦爬虫又分为深度爬虫和增量式爬虫。
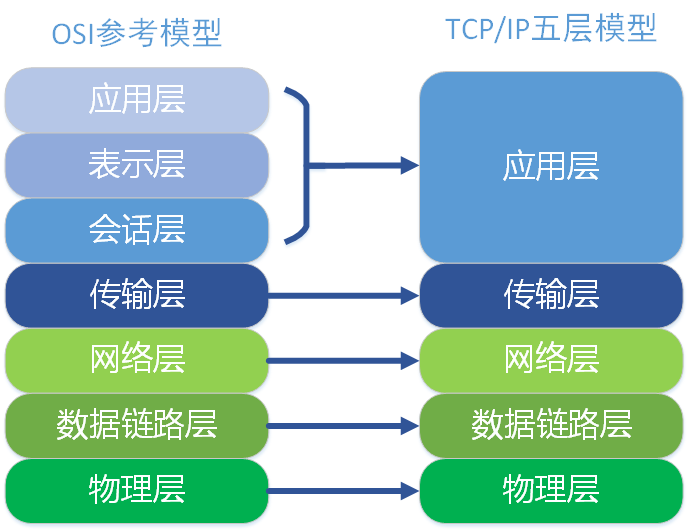
3.网络模型:OSI七层与TCP/IP五层
一、OSI参考模型

二、TCP/IP五层模型
TCP/IP五层协议和OSI的七层协议对应关系如下。
4.网络协议
TCP协议与UDP协议:
(1) 两者都是传输层协议
(2) TCP协议,是一种面向连接的,可靠的,基于字节流的传输层通信协议,其具有以下4个特性:
① 有序性
② 正确性
③ 可靠性
④ 可控性
(3) UDP协议,是用户数据协议,面向无连接的传输层协议,传输不可靠,其具有以下3个特点:
① 无链接,数据可能丢失或损坏
② 报文小,传输速度快
③ 吞吐量大的网络传输,可以在一定程度上承受数据丢失

