从零开始搭建前端数据监控系统(二)-前端性能监控方案调研
1. 业界案例
目前前端性能监控系统大致为分两类:以GA为代表的代码监控和以webpagetest为代表的工具监控。
代码监控依托于js代码并部署到需监控的页面,手动计算时间差或者使用浏览器的的API进行数据统计。
影响代码监控数据的因素有以下几种:
- 浏览器渲染机制;
- 浏览器对API的实现程度,比如performance API;
工具监控不用将统计代码部署到页面中,一般依托于虚拟机。以webpageTest为例,输入需统计的url并且选择运行次url的浏览器版本,webpageTest后台虚拟机对url进行请求分析后便可以给出各种性能指标,比如瀑布流、静态文件数量、首屏渲染时间等等。
代码监控和工具监控的对比如下表:

根据目前业务需求以及成本预算,最终决定采用代码监控方案。以下分别介绍代码监控各方面的实现细节。
2. 前端性能监控指标
前端性能统计的数据大致有以下几个:
- 白屏时间:从打开网站到有内容渲染出来的时间节点;
- 首屏时间:首屏内容渲染完毕的时间节点;
- 用户可操作时间节点:domready触发节点;
- 总下载时间:window.onload的触发节点。
下面介绍几种以上几个数据的统计方案。
2.1 常规统计方案
使用注入代码监控的方式统计以上指标,在没有一些浏览器新API(如下文将提到的timing API)的支持下,得到的数据大都是估值,虽然不准确,但也有一定的参考价值。
2.1.1 白屏时间
白屏时间节点指的是从用户进入网站(输入url、刷新、跳转等方式)的时刻开始计算,一直到页面有内容展示出来的时间节点。这个过程包括dns查询、建立tcp连接、发送首个http请求(如果使用https还要介入TLS的验证时间)、返回html文档、html文档head解析完毕。
使用注入代码监控无法获取解析html文档之前的时间信息,目前普遍使用的白屏时间统计方案是在html文档的head中所有的静态资源以及内嵌脚本/样式之前记录一个时间点,在head最底部记录另一个时间点,两者的差值作为白屏时间。如下:
<html>
<head>
<meta charset="UTF-8"/>
<!--这里还有一大串meta信息-->
<script>
var start_time = new Date();//统计起点,实际为html开始解析的时间节点
</script>
<link href='a.css'></link>
<script src='a.js'></script>
<script>
var end_time = new Date();//统计起点,实际为html开始解析的时间节点
</script>
</head>
<body>
</body>
</html>
上述代码中的end_time和start_time的差值一般作为白屏时间的估值,但理论上来讲,这个差值只是浏览器解析html文档head的时间,并非准确的白屏时间。
2.1.2 首屏时间
首屏时间的统计比较复杂,目前应用比较广的方案是将首屏的图片、iframe等资源添加onload事件,获取最慢的一个。
这种方案比较适合首屏元素数量固定的页面,比如移动端首屏不论屏幕大小都展示相同数量的内容,响应式得改变内容的字体、尺寸等。但是对于首屏元素不固定的页面,这种方案并不适用,最典型的就是PC端页面,不同屏幕尺寸下展示的首屏内容不同。上述方案便不适用于此场景。
2.1.3 可操作时间
用户可操作的时间节点即dom ready触发的时间,使用jquery可以通过$(document).ready()获取此数据,如果不使用jQuery可以参考这里通过原生方法实现dom ready。
2.1.4 总下载时间
总下载时间即window.onload触发的时间节点。
目前大多数web产品都有异步加载的内容,比如图片的lazyload等。如果总下载时间需要统计到这些数据,可以借鉴AOP的理念,在请求异步内容之前和之后分别打点,最后计算差值。不过通常来讲,我们说的总下载时间并不包括异步加载的内容。
2.2 使用window.performance API
window.performance 是W3C性能小组引入的新的API,目前IE9以上的浏览器都支持。一个performance对象的完整结构如下图所示:

memory字段代表JavaScript对内存的占用。
navigation字段统计的是一些网页导航相关的数据:
redirectCount:重定向的数量(只读),但是这个接口有同源策略限制,即仅能检测同源的重定向;- type 返回值应该是0,1,2 中的一个。分别对应三个枚举值:
- 0 : TYPE_NAVIGATE (用户通过常规导航方式访问页面,比如点一个链接,或者一般的get方式)
- 1 : TYPE_RELOAD (用户通过刷新,包括JS调用刷新接口等方式访问页面)
- 2 : TYPE_BACK_FORWARD (用户通过后退按钮访问本页面)
最重要的是timing字段的统计数据,它包含了网络、解析等一系列的时间数据。
2.2.1 timing API
timing的整体结构如下图所示:
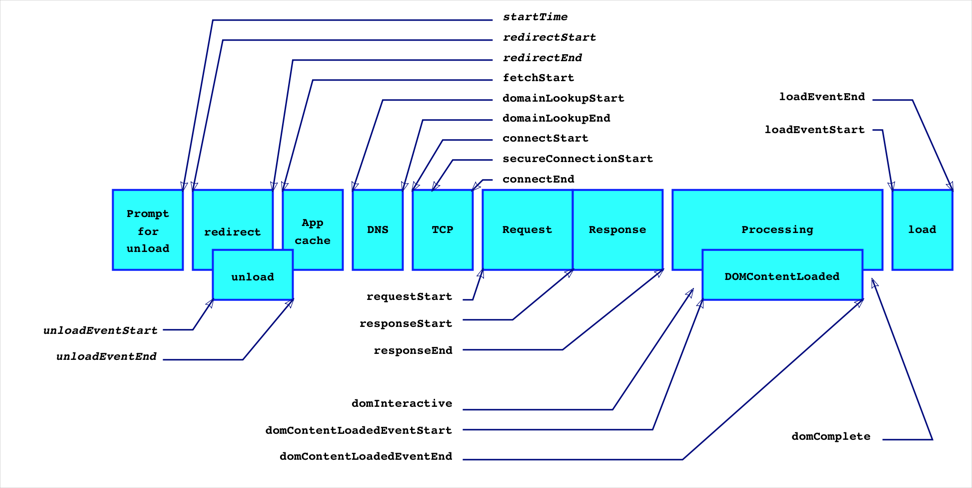
各字段的含义如下:
startTime:有些浏览器实现为navigationStart,代表浏览器开始unload前一个页面文档的开始时间节点。比如我们当前正在浏览baidu.com,在地址栏输入google.com并回车,浏览器的执行动作依次为:unload当前文档(即baidu.com)->请求下一文档(即google.com)。navigationStart的值便是触发unload当前文档的时间节点。
如果当前文档为空,则navigationStart的值等于fetchStart。
redirectStart和redirectEnd:如果页面是由redirect而来,则redirectStart和redirectEnd分别代表redirect开始和结束的时间节点;unloadEventStart和unloadEventEnd:如果前一个文档和请求的文档是同一个域的,则unloadEventStart和unloadEventEnd分别代表浏览器unload前一个文档的开始和结束时间节点。否则两者都等于0;fetchStart是指在浏览器发起任何请求之前的时间值。在fetchStart和domainLookupStart之间,浏览器会检查当前文档的缓存;domainLookupStart和domainLookupEnd分别代表DNS查询的开始和结束时间节点。如果浏览器没有进行DNS查询(比如使用了cache),则两者的值都等于fetchStart;connectStart和connectEnd分别代表TCP建立连接和连接成功的时间节点。如果浏览器没有进行TCP连接(比如使用持久化连接webscoket),则两者都等于domainLookupEnd;secureConnectionStart:可选。如果页面使用HTTPS,它的值是安全连接握手之前的时刻。如果该属性不可用,则返回undefined。如果该属性可用,但没有使用HTTPS,则返回0;requestStart代表浏览器发起请求的时间节点,请求的方式可以是请求服务器、缓存、本地资源等;responseStart和responseEnd分别代表浏览器收到从服务器端(或缓存、本地资源)响应回的第一个字节和最后一个字节数据的时刻;domLoading代表浏览器开始解析html文档的时间节点。我们知道IE浏览器下的document有readyState属性,domLoading的值就等于readyState改变为loading的时间节点;domInteractive代表浏览器解析html文档的状态为interactive时的时间节点。domInteractive并非DOMReady,它早于DOMReady触发,代表html文档解析完毕(即dom tree创建完成)但是内嵌资源(比如外链css、js等)还未加载的时间点;domContentLoadedEventStart:代表DOMContentLoaded事件触发的时间节点:
页面文档完全加载并解析完毕之后,会触发DOMContentLoaded事件,HTML文档不会等待样式文件,图片文件,子框架页面的加载(load事件可以用来检测HTML页面是否完全加载完毕(fully-loaded))。
domContentLoadedEventEnd:代表DOMContentLoaded事件完成的时间节点,此刻用户可以对页面进行操作,也就是jQuery中的domready时间;domComplete:html文档完全解析完毕的时间节点;loadEventStart和loadEventEnd分别代表onload事件触发和结束的时间节点
2.2.2 计算性能指标
可以使用Navigation.timing 统计到的时间数据来计算一些页面性能指标,比如DNS查询耗时、白屏时间、domready等等。如下:
- DNS查询耗时 = domainLookupEnd - domainLookupStart
- TCP链接耗时 = connectEnd - connectStart
- request请求耗时 = responseEnd - responseStart
- 解析dom树耗时 = domComplete - domInteractive
- 白屏时间 = domloadng - fetchStart
- domready时间 = domContentLoadedEventEnd - fetchStart
- onload时间 = loadEventEnd - fetchStart
2.2.3 Resource timing API
Resource timing API是用来统计静态资源相关的时间信息,详细的内容请参考W3C Resource timing 。这里我们只介绍performance.getEntries方法,它可以获取页面中每个静态资源的请求,如下:

可以看到performance.getEntries返回一个数组,数组的每个元素代表对应的静态资源的信息,比如上图展示的第一个元素对应的资源类型initiatorType是图片img,请求花费的时间就是duration的值。
关于Resource timing API的使用场景,感兴趣的同学可以深入研究。
2.3 参考资料
- Facebook测速方案;
- Measuring Page Load Speed with Navigation Timing;
- 前端数据之美 -- 基础篇;
- 7 天打造前端性能监控系统;
- phantomjs ;
- 前端相关数据监控;
- 研究首屏时间?你先要知道这几点细节
3. JavaScript代码异常监控
JavaScript异常一般有两方面:语法错误和运行时错误。两种错误的捕获和处理方式不同,从而影响具体的方案选型。通常来说,处理JS异常的方案有两种:try...catch捕获 和 window.onerror捕获。以下就两种方案分别分析各自的优劣。
虽然语法错误本应该在开发构建阶段使用测试工具避免,但难免会有马失前蹄部署到线上的时候。
3.1 try...catch捕获
这种方案要求开发人员在编写代码的时候,在预估有异常发生的代码段使用try...catch,在发生异常时将异常信息发送给接口:
try{
//可能发生异常的代码段
}catch(e){
//将异常信息发送服务端
}
try...catch的优点是可以细化到每个代码块,并且可以自定义错误信息以便统计。
具体到上文提到的两种js异常,try...catch无法捕获语法错误,当遇到语法错误时,浏览器仍然会抛出错误Uncaught SyntaxError,但是不会被捕获,不会走进catch的代码块内。
另外,如果try代码块中有回调函数也不会被捕获,比如:
try{
var btn = $('#btn');
btn.on('click',function(){
//throw error
});
}catch(e){}
上述代码中btn的监听函数里抛出的异常无法被外层的catch捕获到,必须额外套一层:
try{
var btn = $('#btn');
btn.on('click',function(){
try{
//throw error
}catch(e){}
});
}catch(e){}
综上所述,try...catch方案的部署非常复杂,如果人工部署除了要求巨量的工作量,还跟开发人员的能力和经验有关。如果依赖编译工具部署(比如fis),那每个代码块都套一层try...catch也是非常难看的并且容易引发一些不可预估的问题。
3.2 window.onerror捕获
这种方式不需要开发人员在代码中书写大量的try...catch,通过给window添加onerror监听,在js发生异常的时候便可以捕获到错误信息,语法异常和运行异常均可被捕获到。但是window.onerror这个监听必须放在所有js文件之前才可以保证能够捕获到所有的异常信息。
window.onerror事件的详细信息参考这里。
/**
* @param {String} errorMessage 错误信息
* @param {String} scriptURL 出错文件的URL
* @param {Long} lineNumber 出错代码的行号
* @param {Long} columnNumber 出错代码的列号
* @param {Object} errorObj 错误信息Object
*/
window.onerror = function(errorMessage, scriptURL, lineNumber,columnNumber,errorObj) {
// code..
}
onerror的实现方式各浏览器略有差异,但是前三个参数都是相同的,某些低版本浏览器没有后两个参数。
最后一个参数errorObj各浏览器实现的程度不一致,具体可参考这里。
下图是被onerror捕获到的一个异常的具体信息:

综上所述,window.onerror方案的优点是减少了开发人员的工作量,部署方便,并且可以捕获语法错误和运行错误。缺点是错误信息不能自定义,并且errorObj每种浏览器的实现有略微差异,导致需统计的信息有局限性。
3.3 跨域JS文件异常的捕获
为了提高web性能,目前大部分web产品架构中都有CDN这一环,将资源部署到不同的域名上,充分利用浏览器的并发请求机制。那么在跨域JS文件中发生异常的时候,onerror监听会捕获到什么信息呢?请看下图:

只有一个稍微有价值的信息Script error,其他什么信息都没有,为什么会这样呢?
我们都知道浏览器有同源资源限制,常规状态下是无法进行跨域请求的。而script、img、iframe标签的src属性是没有这种限制的,这也是很多跨域方案的基础。但是即使script标签可以请求到异域的js文件,此文件中的信息也并不能暴露到当前域内,这也是浏览器的安全措施所致。
那么有没有办法获取到异域资源的异常信息呢?
其实很简单,目前可以说基本上所有的web产品对于js/css/image等静态资源都在服务端设置了Access-Control-Allow-Origin: *的响应头,也就是允许跨域请求。在这个环境下,只要我们在请求跨域资源的script标签上添加一个crossorigin属性即可:
<script src="http://static.toutiao.com/test.js" crossorigin></script>
这样的话,异域的test.js文件中发生异常时便可以被当前域的onerror监听捕获到详细的异常信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号