tidb数据库的适用场景
######################
一、大数据量:
什么叫大数据量?至少有千万行级别的大表,或者数据库schema的占空空间有T级别的数据量,
如果数据量少于500G且qps或并发量小则使用mysql
二、高并发量:
数十万QPS也不再话下
不用再分库分表了,也不再使用中间件了
三、dba运维简单:
因为tidb自动维护数据的强一致性和高可用,解脱了dba
四、实时HTAP场景:
mysql与tidb的区别:
自增id:tidb的自增id只能保证唯一性,不保证自增性和连续性,也不支持在线添加列auto_increment属性
索引区别:tidb的主键索引和唯一索引的存储方式相同,不支持全文索引、空间索引、
字符集支持:仅支持utf8/utf8mb4/ascii/latin1/binary几个字符集
视图:tidb只支持读,不支持insert、update、delete等其他操作
外键:tidb不支持
触发器:tidb不支持
存储过程:tidb不支持
自定义函数:tidb不支持
sql_mode区别:部分选项有差别
ddl区别:不支持将整型改为字符串,不支持同时修改多个字段,不支持有损更改,比如bigint改为int
执行计划:tidb有区别
悲观事务区别:没有gap lock,tidb的ddl语句会打断正在执行的悲观事务,让悲观事务提交失败,而mysql则会阻塞ddl语句,autocommit事务优先采用乐观事务,即使全局采用了悲观事务模型,不支持select xxx from yyy lock in share mode,语句不会报错,但是加锁操作无效。tidb乐观事务的affectted_row值不准,业务千万不要依赖这个做业务逻辑。
加锁处理逻辑
1)是否需要加数据锁?
2)对加锁超时进行什么处理?重试?抛出?
tidb架构:
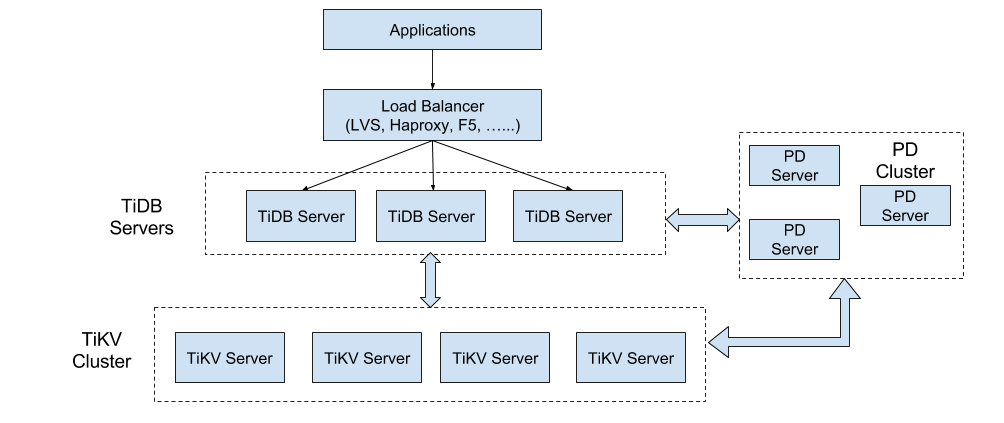
一个 TiDB 集群由不同的模块组成,包括:TiDB 服务器、TiKV 服务器、Placement Driver (PD) 服务器。
TiDB 的架构非常简单,首先是 Load Balancer,可以将用户的 SQL 请求打散,发送到 TiDB Server 中。TiDB Server 是一个无状态的计算层,可以随意扩展,实际的数据存储在分布式 KV 存储 TiKV 中。此外,还有一个 PD 组件来对这些数据进行调度以及规整。 这一套架构最突出的部分是扩容,以扩容作为第一要义。扩容体现在两个方面,
一是存储扩容,传统的单机数据库无法承载的数据量,TiDB 可以将其存储到分布式存储中。
二是计算上,传统数据库单机无法承受较高的 QPS, 通过这种扩容的方式,QPS 可以打散到不同的计算节点上。
TiDB 集群主要分为三个组件:
TiDB Server:请求处理和计算处理(业务请求量大,那就增加tidb节点)
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。
TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server:存储集群元数据、分配全局事务id、对tikv集群调度和负载均衡
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server:多副本存储数据(业务数据量暴增,那就增加tikv节点)
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。
TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
核心特性
水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。
TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 30 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
tidb-server组件目录结构:/home/work/tidb/tidb-4000
[work@10.10.10.10 tidb-4000]$ tree . ├── bin │ └── tidb-server ├── conf │ ├── cluster.conf │ └── tidb.toml ├── log │ ├── tidb.log │ ├── tidb_slow_query.log │ └── tidb_stderr.log ├── scripts │ └── run_tidb.sh └── tmp-storage └── 10000_tidb └── MC4wLjAuMDo0MDAwLzAuMC4wLjA6MTAwODA= └── tmp-storage ├── _dir.lock └── record
#####################

######################

 浙公网安备 33010602011771号
浙公网安备 33010602011771号