lsn
##################
参考:https://blog.csdn.net/GDJ0001/article/details/83510447
##############
LSN称为日志的逻辑序列号(log sequence number),在innodb存储引擎中,lsn占用8个字节。LSN的值会随着日志的写入而逐渐增大。
根据LSN,可以获取到几个有用的信息:
1.数据页的版本信息。
2.写入的日志总量,通过LSN开始号码和结束号码可以计算出写入的日志量。
3.可知道检查点的位置。
实际上还可以获得很多隐式的信息。
LSN不仅存在于redo log中,还存在于数据页中,在每个数据页的头部FILE_HEADER部分,有一个FIL_PAGE_LSN---记录了该数据页最后被修改的日志序列位置。数据页中还存在FIL_PAGE_FILE_FLUSH_LSN(只存在于共享表空间 ,独立表空间中该值为0。该值代表了数据页的文件至少被更新到的位置)。通过数据页中的LSN值和redo log中的LSN值比较,如果页中的LSN值小于redo log中LSN值,则表示数据丢失了一部分,这时候可以通过redo log的记录来恢复到redo log中记录的LSN值时的状态。
redo log的LSN信息可以通过 show engine innodb status 命令来查看。MySQL 5.5版本的show结果中只有3条记录,没有pages flushed up to。
查看redolog刷盘时间:默认日志刷盘频率为1秒
mysql> show global variables like 'innodb_flush_log_at_timeout%'; +-----------------------------+-------+ | Variable_name | Value | +-----------------------------+-------+ | innodb_flush_log_at_timeout | 1 | +-----------------------------+-------+ 1 row in set (0.00 sec) mysql>
查看LSN
mysql> show engine innodb status\G *************************** 1. row *************************** Type: InnoDB Name: Status: ===================================== 2023-04-25 14:52:31 0x7f6abcd3f700 INNODB MONITOR OUTPUT ===================================== Per second averages calculated from the last 38 seconds ----------------- BACKGROUND THREAD ----------------- srv_master_thread loops: 3948 srv_active, 0 srv_shutdown, 1196877 srv_idle srv_master_thread log flush and writes: 1200825 ---------- SEMAPHORES ---------- OS WAIT ARRAY INFO: reservation count 433 OS WAIT ARRAY INFO: signal count 562 RW-shared spins 0, rounds 1152, OS waits 393 RW-excl spins 0, rounds 1160, OS waits 8 RW-sx spins 33, rounds 483, OS waits 5 Spin rounds per wait: 1152.00 RW-shared, 1160.00 RW-excl, 14.64 RW-sx ------------ TRANSACTIONS ------------ Trx id counter 161973 Purge done for trx's n:o < 161973 undo n:o < 0 state: running but idle History list length 1 LIST OF TRANSACTIONS FOR EACH SESSION: ---TRANSACTION 421572652587744, not started 0 lock struct(s), heap size 1136, 0 row lock(s) ---TRANSACTION 421572652589568, not started 0 lock struct(s), heap size 1136, 0 row lock(s) ---TRANSACTION 421572652588656, not started 0 lock struct(s), heap size 1136, 0 row lock(s) ---TRANSACTION 421572652586832, not started 0 lock struct(s), heap size 1136, 0 row lock(s) -------- FILE I/O -------- I/O thread 0 state: waiting for completed aio requests (insert buffer thread) I/O thread 1 state: waiting for completed aio requests (log thread) I/O thread 2 state: waiting for completed aio requests (read thread) I/O thread 3 state: waiting for completed aio requests (read thread) I/O thread 4 state: waiting for completed aio requests (read thread) I/O thread 5 state: waiting for completed aio requests (read thread) I/O thread 6 state: waiting for completed aio requests (read thread) I/O thread 7 state: waiting for completed aio requests (read thread) I/O thread 8 state: waiting for completed aio requests (read thread) I/O thread 9 state: waiting for completed aio requests (read thread) I/O thread 10 state: waiting for completed aio requests (read thread) I/O thread 11 state: waiting for completed aio requests (read thread) I/O thread 12 state: waiting for completed aio requests (read thread) I/O thread 13 state: waiting for completed aio requests (read thread) I/O thread 14 state: waiting for completed aio requests (read thread) I/O thread 15 state: waiting for completed aio requests (read thread) I/O thread 16 state: waiting for completed aio requests (read thread) I/O thread 17 state: waiting for completed aio requests (read thread) I/O thread 18 state: waiting for completed aio requests (write thread) I/O thread 19 state: waiting for completed aio requests (write thread) I/O thread 20 state: waiting for completed aio requests (write thread) I/O thread 21 state: waiting for completed aio requests (write thread) I/O thread 22 state: waiting for completed aio requests (write thread) I/O thread 23 state: waiting for completed aio requests (write thread) I/O thread 24 state: waiting for completed aio requests (write thread) I/O thread 25 state: waiting for completed aio requests (write thread) Pending normal aio reads: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] , aio writes: [0, 0, 0, 0, 0, 0, 0, 0] , ibuf aio reads:, log i/o's:, sync i/o's: Pending flushes (fsync) log: 0; buffer pool: 0 975 OS file reads, 50377 OS file writes, 48353 OS fsyncs 0.00 reads/s, 0 avg bytes/read, 2.53 writes/s, 0.45 fsyncs/s ------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 0, seg size 2, 0 merges merged operations: insert 0, delete mark 0, delete 0 discarded operations: insert 0, delete mark 0, delete 0 Hash table size 276707, node heap has 0 buffer(s) Hash table size 276707, node heap has 1 buffer(s) Hash table size 276707, node heap has 1 buffer(s) Hash table size 276707, node heap has 2 buffer(s) Hash table size 276707, node heap has 1 buffer(s) Hash table size 276707, node heap has 0 buffer(s) Hash table size 276707, node heap has 0 buffer(s) Hash table size 276707, node heap has 0 buffer(s) 3.29 hash searches/s, 27.05 non-hash searches/s --- LOG --- Log sequence number 31792728 Log flushed up to 31792728 Pages flushed up to 31792728 Last checkpoint at 31792719 0 pending log flushes, 0 pending chkp writes 47040 log i/o's done, 0.18 log i/o's/second ---------------------- BUFFER POOL AND MEMORY ---------------------- Total large memory allocated 1107296256 Dictionary memory allocated 498833 Buffer pool size 65536 Free buffers 64577 Database pages 954 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 730, created 224, written 2671 0.00 reads/s, 0.00 creates/s, 0.00 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 954, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---------------------- INDIVIDUAL BUFFER POOL INFO ---------------------- ---BUFFER POOL 0 Buffer pool size 8192 Free buffers 7990 Database pages 201 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 136, created 65, written 1075 0.00 reads/s, 0.00 creates/s, 0.00 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 201, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 1 Buffer pool size 8192 Free buffers 8138 Database pages 53 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 43, created 10, written 38 0.00 reads/s, 0.00 creates/s, 0.00 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 53, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 2 Buffer pool size 8192 Free buffers 8149 Database pages 42 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 42, created 0, written 1 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 42, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 3 Buffer pool size 8192 Free buffers 8081 Database pages 111 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 111, created 0, written 443 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 111, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 4 Buffer pool size 8192 Free buffers 8032 Database pages 159 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 122, created 37, written 199 0.00 reads/s, 0.00 creates/s, 0.00 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 159, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 5 Buffer pool size 8192 Free buffers 8006 Database pages 185 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 121, created 64, written 365 0.00 reads/s, 0.00 creates/s, 0.00 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 185, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 6 Buffer pool size 8192 Free buffers 8066 Database pages 126 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 88, created 38, written 349 0.00 reads/s, 0.00 creates/s, 0.00 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 126, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] ---BUFFER POOL 7 Buffer pool size 8192 Free buffers 8115 Database pages 77 Old database pages 0 Modified db pages 0 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 67, created 10, written 201 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 77, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] -------------- ROW OPERATIONS -------------- 0 queries inside InnoDB, 0 queries in queue 0 read views open inside InnoDB Process ID=3274, Main thread ID=140096114005760, state: sleeping Number of rows inserted 25539, updated 284, deleted 198, read 85251 0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s ---------------------------- END OF INNODB MONITOR OUTPUT ============================ 1 row in set (0.00 sec) mysql>
其中:
- log sequence number就是当前的redo log(in buffer)中的lsn;
- log flushed up to是刷到redo log file on disk中的lsn;
- pages flushed up to是已经刷到磁盘数据页上的LSN;
- last checkpoint at是上一次检查点所在位置的LSN。
innodb从执行修改语句开始:
(1).首先修改内存中的数据页,并在数据页中记录LSN,暂且称之为data_in_buffer_lsn;
(2).并且在修改数据页的同时(几乎是同时)向redo log in buffer中写入redo log,并记录下对应的LSN,暂且称之为redo_log_in_buffer_lsn;
(3).写完buffer中的日志后,当触发了日志刷盘的几种规则时,会向redo log file on disk刷入重做日志,并在该文件中记下对应的LSN,暂且称之为redo_log_on_disk_lsn;
(4).数据页不可能永远只停留在内存中,在某些情况下,会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
(5).要记录checkpoint所在位置很快,只需简单的设置一个标志即可,但是刷数据页并不一定很快,例如这一次checkpoint要刷入的数据页非常多。也就是说要刷入所有的数据页需要一定的时间来完成,中途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
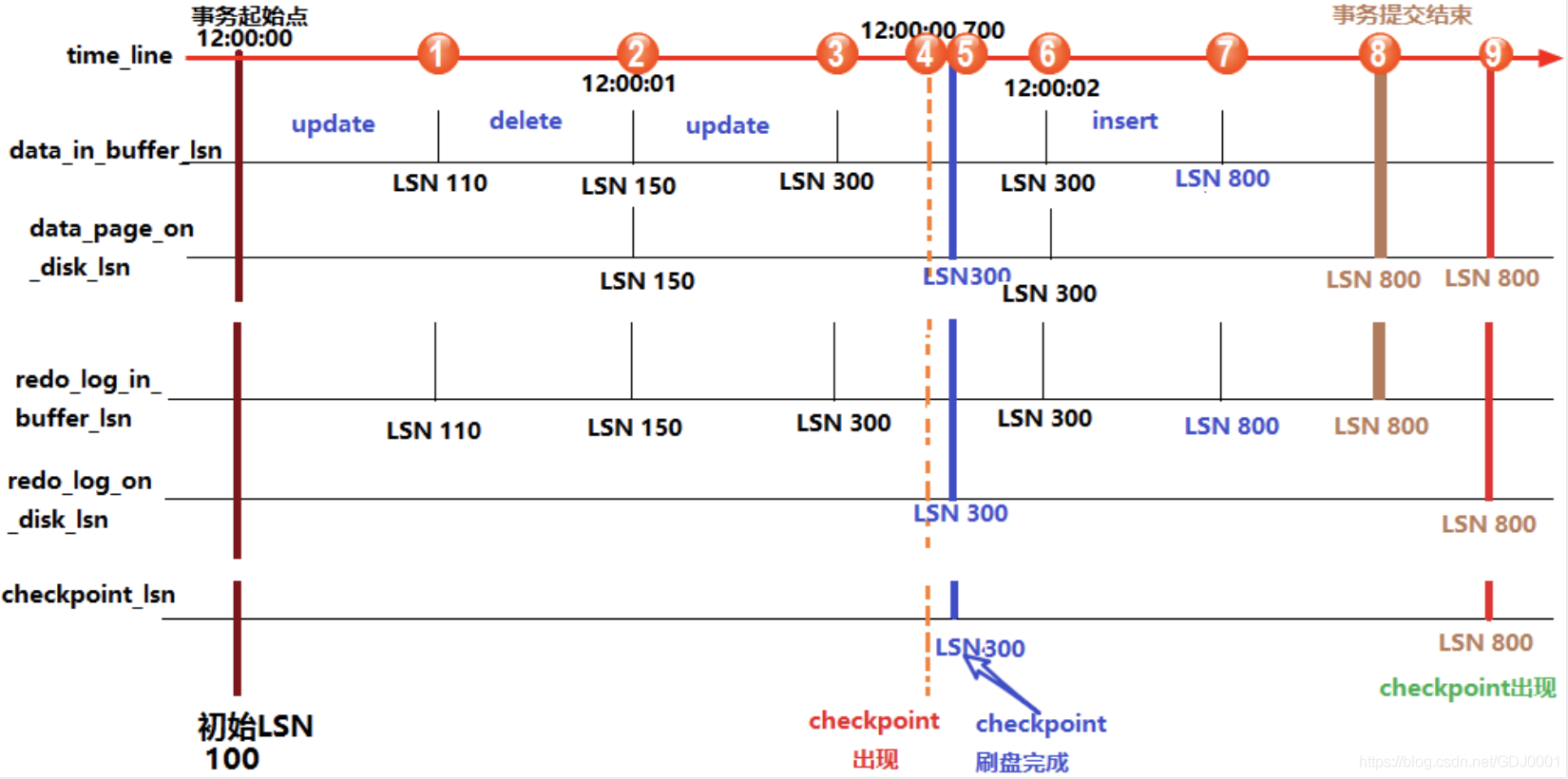
上图中,从上到下的横线分别代表:时间轴、buffer中数据页中记录的LSN(data_in_buffer_lsn)、磁盘中数据页中记录的LSN(data_page_on_disk_lsn)、buffer中重做日志记录的LSN(redo_log_in_buffer_lsn)、磁盘中重做日志文件中记录的LSN(redo_log_on_disk_lsn)以及检查点记录的LSN(checkpoint_lsn)。
假设在最初时(12:0:00)所有的日志页和数据页都完成了刷盘,也记录好了检查点的LSN,这时它们的LSN都是完全一致的。
假设此时开启了一个事务,并立刻执行了一个update操作,执行完成后,buffer中的数据页和redo log都记录好了更新后的LSN值,假设为110。这时候如果执行 show engine innodb status 查看各LSN的值,即图中①处的位置状态,结果会是:
log sequence number(110) > log flushed up to(100) = pages flushed up to = last checkpoint at
之后又执行了一个delete语句,LSN增长到150。等到12:00:01时,触发redo log刷盘的规则(其中有一个规则是 innodb_flush_log_at_timeout 控制的默认日志刷盘频率为1秒),这时redo log file on disk中的LSN会更新到和redo log in buffer的LSN一样,所以都等于150,这时 show engine innodb status ,即图中②的位置,结果将会是:
log sequence number(150) = log flushed up to > pages flushed up to(100) = last checkpoint at
再之后,执行了一个update语句,缓存中的LSN将增长到300,即图中③的位置。
假设随后检查点出现,即图中④的位置,正如前面所说,检查点会触发数据页和日志页刷盘,但需要一定的时间来完成,所以在数据页刷盘还未完成时,检查点的LSN还是上一次检查点的LSN,但此时磁盘上数据页和日志页的LSN已经增长了,即:
log sequence number > log flushed up to 和 pages flushed up to > last checkpoint at
但是log flushed up to和pages flushed up to的大小无法确定,因为日志刷盘可能快于数据刷盘,也可能等于,还可能是慢于。但是checkpoint机制有保护数据刷盘速度是慢于日志刷盘的:当数据刷盘速度超过日志刷盘时,将会暂时停止数据刷盘,等待日志刷盘进度超过数据刷盘。
等到数据页和日志页刷盘完毕,即到了位置⑤的时候,所有的LSN都等于300。
随着时间的推移到了12:00:02,即图中位置⑥,又触发了日志刷盘的规则,但此时buffer中的日志LSN和磁盘中的日志LSN是一致的,所以不执行日志刷盘,即此时 show engine innodb status 时各种lsn都相等。
随后执行了一个insert语句,假设buffer中的LSN增长到了800,即图中位置⑦。此时各种LSN的大小和位置①时一样。
随后执行了提交动作,即位置⑧。默认情况下,提交动作会触发日志刷盘,但不会触发数据刷盘,所以 show engine innodb status 的结果是:
log sequence number = log flushed up to > pages flushed up to = last checkpoint at
最后随着时间的推移,检查点再次出现,即图中位置⑨。但是这次检查点不会触发日志刷盘,因为日志的LSN在检查点出现之前已经同步了。假设这次数据刷盘速度极快,快到一瞬间内完成而无法捕捉到状态的变化,这时 show engine innodb status 的结果将是各种LSN相等。
一、简介
思考一下这个场景:如果重做日志可以无限地增大,同时缓冲池也足够大,那么是不需要将缓冲池中页的新版本刷新回磁盘。因为当发生宕机时,完全可以通过重做日志来恢复整个数据库系统中的数据到宕机发生的时刻。
但是这需要两个前提条件:1、缓冲池可以缓存数据库中所有的数据;2、重做日志可以无限增大
因此Checkpoint(检查点)技术就诞生了,目的是解决以下几个问题:1、缩短数据库的恢复时间;2、缓冲池不够用时,将脏页刷新到磁盘;3、重做日志不可用时,刷新脏页。
-
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。数据库只需对Checkpoint后的重做日志进行恢复,这样就大大缩短了恢复的时间。
-
当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
-
当重做日志出现不可用时,因为当前事务数据库系统对重做日志的设计都是循环使用的,并不是让其无限增大的,重做日志可以被重用的部分是指这些重做日志已经不再需要,当数据库发生宕机时,数据库恢复操作不需要这部分的重做日志,因此这部分就可以被覆盖重用。如果重做日志还需要使用,那么必须强制Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
对于InnoDB存储引擎而言,是通过LSN(Log Sequence Number)来标记版本的。
LSN是8字节的数字,每个页有LSN,重做日志中也有LSN,Checkpoint也有LSN。可以通过命令SHOW ENGINE INNODB STATUS来观察:
|
1
2
3
4
5
6
7
8
9
10
|
mysql> show engine innodb status \G---LOG---Log sequence number 34778380870Log flushed up to 34778380870Last checkpoint at 347783808700 pending log writes, 0 pending chkp writes54020151 log i/o's done, 0.92 log i/o's/second |
Checkpoint发生的时间、条件及脏页的选择等都非常复杂。而Checkpoint所做的事情无外乎是将缓冲池中的脏页刷回到磁盘,不同之处在于每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发Checkpoint。
二、Checkpoint分类
在InnoDB存储引擎内部,有两种Checkpoint,分别为:Sharp Checkpoint、Fuzzy Checkpoint
Sharp Checkpoint 发生在数据库关闭时将所有的脏页都刷新回磁盘,这是默认的工作方式,即参数innodb_fast_shutdown=1。但是若数据库在运行时也使用Sharp Checkpoint,那么数据库的可用性就会受到很大的影响。故在InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页,而不是刷新所有的脏页回磁盘。
Fuzzy Checkpoint:1、Master Thread Checkpoint;2、FLUSH_LRU_LIST Checkpoint;3、Async/Sync Flush Checkpoint;4、Dirty Page too much Checkpoint
1、Master Thread Checkpoint
以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,此时InnoDB存储引擎可以进行其他的操作,用户查询线程不会阻塞。
2、FLUSH_LRU_LIST Checkpoint
因为InnoDB存储引擎需要保证LRU列表中需要有差不多100个空闲页可供使用。在InnoDB1.1.x版本之前,需要检查LRU列表中是否有足够的可用空间操作发生在用户查询线程中,显然这会阻塞用户的查询操作。倘若没有100个可用空闲页,那么InnoDB存储引擎会将LRU列表尾端的页移除。如果这些页中有脏页,那么需要进行Checkpoint,而这些页是来自LRU列表的,因此称为FLUSH_LRU_LIST Checkpoint。
而从MySQL 5.6版本,也就是InnoDB1.2.x版本开始,这个检查被放在了一个单独的Page Cleaner线程中进行,并且用户可以通过参数innodb_lru_scan_depth控制LRU列表中可用页的数量,该值默认为1024,如:
|
1
2
3
4
5
6
|
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_lru_scan_depth';+-----------------------+-------+| Variable_name | Value |+-----------------------+-------+| innodb_lru_scan_depth | 1024 |+-----------------------+-------+ |
3、Async/Sync Flush Checkpoint
指的是重做日志文件不可用的情况,这时需要强制将一些页刷新回磁盘,而此时脏页是从脏页列表中选取的。若将已经写入到重做日志的LSN记为redo_lsn,将已经刷新回磁盘最新页的LSN记为checkpoint_lsn,则可定义:
checkpoint_age = redo_lsn - checkpoint_lsn
再定义以下的变量:
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
若每个重做日志文件的大小为1GB,并且定义了两个重做日志文件,则重做日志文件的总大小为2GB。那么async_water_mark=1.5GB,sync_water_mark=1.8GB。则:
当checkpoint_age<async_water_mark时,不需要刷新任何脏页到磁盘;
当async_water_mark<checkpoint_age<sync_water_mark时触发Async Flush,从Flush列表中刷新足够的脏页回磁盘,使得刷新后满足checkpoint_age<async_water_mark;
checkpoint_age>sync_water_mark这种情况一般很少发生,除非设置的重做日志文件太小,并且在进行类似LOAD DATA的BULK INSERT操作。此时触发Sync Flush操作,从Flush列表中刷新足够的脏页回磁盘,使得刷新后满足checkpoint_age<async_water_mark。
可见,Async/Sync Flush Checkpoint是为了保证重做日志的循环使用的可用性。在InnoDB 1.2.x版本之前,Async Flush Checkpoint会阻塞发现问题的用户查询线程,而Sync Flush Checkpoint会阻塞所有的用户查询线程,并且等待脏页刷新完成。从InnoDB 1.2.x版本开始——也就是MySQL 5.6版本,这部分的刷新操作同样放入到了单独的Page Cleaner Thread中,故不会阻塞用户查询线程。
MySQL官方版本并不能查看刷新页是从Flush列表中还是从LRU列表中进行Checkpoint的,也不知道因为重做日志而产生的Async/Sync Flush的次数。但是InnoSQL版本提供了方法,可以通过命令SHOW ENGINE INNODB STATUS来观察,如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
mysql> show engine innodb status \GBUFFER POOL AND MEMORY----------------------Total memory allocated 2058485760; in additional pool allocated 0Dictionary memory allocated 913470Buffer pool size 122879Free buffers 79668Database pages 41957Old database pages 15468Modified db pages 0Pending reads 0Pending writes: LRU 0, flush list 0, single page 0Pages made young 15032929, not young 00.00 youngs/s, 0.00 non-youngs/sPages read 15075936, created 366872, written 366564230.00 reads/s, 0.00 creates/s, 0.90 writes/sBuffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/sLRU len: 41957, unzip_LRU len: 0I/O sum[39]:cur[0], unzip sum[0]:cur[0] |
4、Dirty Page too much
即脏页的数量太多,导致InnoDB存储引擎强制进行Checkpoint。其目的总的来说还是为了保证缓冲池中有足够可用的页。其可由参数innodb_max_dirty_pages_pct控制:
|
1
2
3
4
5
6
|
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_max_dirty_pages_pct' ;+----------------------------+-------+| Variable_name | Value |+----------------------------+-------+| innodb_max_dirty_pages_pct | 75 |+----------------------------+-------+ |
innodb_max_dirty_pages_pct值为75表示,当缓冲池中脏页的数量占据75%时,强制进行Checkpoint,刷新一部分的脏页到磁盘。在InnoDB 1.0.x版本之前,该参数默认值为90,之后的版本都为75。
三、Checkpoint机制
在Innodb事务日志中,采用了Fuzzy Checkpoint,Innodb每次取最老的modified page(last checkpoint)对应的LSN,再将此脏页的LSN作为Checkpoint点记录到日志文件,意思就是“此LSN之前的LSN对应的日志和数据都已经flush到redo log
当mysql crash的时候,Innodb扫描redo log,从last checkpoint开始apply redo log到buffer pool,直到last checkpoint对应的LSN等于Log flushed up to对应的LSN,则恢复完成
那么具体是怎么恢复的呢?
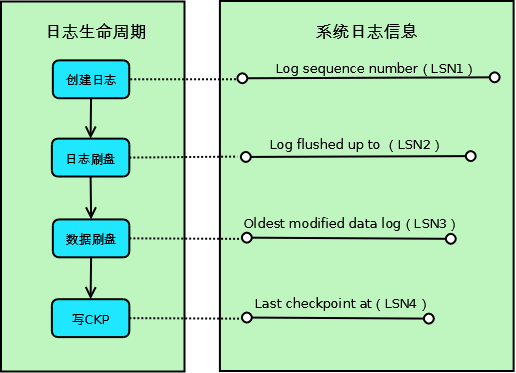
如上图所示,Innodb的一条事务日志共经历4个阶段:
-
创建阶段:事务创建一条日志;
-
日志刷盘:日志写入到磁盘上的日志文件;
-
数据刷盘:日志对应的脏页数据写入到磁盘上的数据文件;
-
写CKP:日志被当作Checkpoint写入日志文件;
对应这4个阶段,系统记录了4个日志相关的信息,用于其它各种处理使用:
-
Log sequence number(LSN1):当前系统LSN最大值,新的事务日志LSN将在此基础上生成(LSN1+新日志的大小);
-
Log flushed up to(LSN2):当前已经写入日志文件的LSN;
-
Oldest modified data log(LSN3):当前最旧的脏页数据对应的LSN,写Checkpoint的时候直接将此LSN写入到日志文件;
-
Last checkpoint at(LSN4):当前已经写入Checkpoint的LSN;
对于系统来说,以上4个LSN是递减的,即: LSN1>=LSN2>=LSN3>=LSN4.
具体的样例如下(使用show innodb status \G命令查看,Oldest modified data log没有显示):
|
1
2
3
4
5
6
7
|
LOG---Log sequence number 34822137537Log flushed up to 34822137537Last checkpoint at 348221330280 pending log writes, 0 pending chkp writes54189288 log i/o's done, 3.00 log i/o's/second |
四、日志保护机制
mysql crash的时候,Innodb有日志刷盘机制,可以通过innodb_flush_log_at_trx_commit参数进行控制,这里说的是如何防止日志覆盖导致日志丢失
Innodb的checkpoint和redo log有哪些紧密关系?有几上名词需要解释一下:

-
Ckp age(动态移动): 最老的dirty page还没有flush到数据文件,即没有做last checkpoint的范围
-
Buf age(动态移动): modified page information没有写到log中,但已在log buffer
-
Buf async(固定点): 日志空间大小的7/8,当buf age移动到Buf async点时,强制把没有写到log中的modified page information开始写入到log中,不阻塞事务
-
Buf sync(固定点): 日志空间大小的15/16,当写入很大的,buf age移动非常快,一下子到buf sync的点,阻塞事务,强制把modified page information开始写入到log中。如果不阻塞事务,未做last checkpoint的redo log存在覆盖危险
-
Ckp async(固定点): 日志空间大小的31/32,当ckp age到达ckp async,强制做last checkpoint,不阻塞事务
-
Ckp sync(固定点):日志空间大小,当ckp age到达ckp sync,强制做last checkpoint,阻塞事务,存在redo log覆盖的危险
接下分析4种情况
-
如果buf age在buf async和buf sync之间
-
如果buf age在buf sync之后(当然这种情况是不存在,mysql有保护机制)
-
如果ckp age在ckp async和ckp sync之间(这种情况是不存在)
-
如果ckp age在ckp sync之后(这种情况是不存在)
第一种情况:

当写入量巨大时,buf age移动到buf async和buf sync之间,触发写出到log中,mysql把尽量多的log写出,如果写入量减慢,buf age又移回到“图一”状态。如果写入量大于flush log的速度,buf age最终会和buf sync重叠,这时所有的事务都被阻塞,强制将2*(Buf age-Buf async)的脏页刷盘,这时IO会比较繁忙。
第二种情况:

当然这种情况是不可能出现,因为如果出现,redo log存在覆盖的可能,数据就会丢失。buf age会越过log size,buf age的大小可能就超过log size,如果要刷buf age,那么整个log size都不够容纳所有的buf age。
第三种和第四种情况不存在分析:
ckp age始终位于buf age的后面(左边),因为ckp age是last checkpoint点,总是追赶buf age(将尽可能多的modified page flush到磁盘),所以buf age肯定是先到达到buf sync。
ckp async及ckp sync存在意义?
mysql中page cache也存在high water及low water,当dirty page触到low water时,os是开始flush dirty page到磁盘,到high water时,会阻塞一切动作,os会疯狂的flush dirty page,磁盘会很忙,存在IO Storm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号