
【软工】结对编程作业
<tbody>
<tr>
<td>这个作业属于哪个课程</td>
<td><a href ="https://edu.cnblogs.com/campus/buaa/BUAA_SE_2019_LJ">2019BUAA软件工程</a></td>
</tr>
<tr>
<td>这个作业的要求在哪里</td>
<td><a href ="https://edu.cnblogs.com/campus/buaa/BUAA_SE_2019_LJ/homework/2638">作业要求</a></td>
</tr>
<tr>
<td>我在这个课程的目标是</td>
<td>完成本次作业,同时熟悉结对编程</td>
</tr>
<tr>
<td>这个作业的帮助</td>
<td>熟悉了vs2017的部分操作,同时对结对编程有了比较深刻的理解</td>
</tr>
</tbody>
| 项目 | 内容 |
|---|
一、本次作业项目github地址
二、开发前PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 210 | |
| · Design Spec | · 生成设计文档 | 90 | |
| · Design Review | · 设计复审 (和同事审核设计文档) | 120 | |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | |
| · Design | · 具体设计 | 300 | |
| · Coding | · 具体编码 | 500 | |
| · Code Review | · 代码复审 | 300 | |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 120 | |
| · Size Measurement | · 计算工作量 | 30 | |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | |
| 合计 | 2030 |
三、接口设计
模块之间通过他们的api通信,一个模块不需要知道另外一个模块的内部情况,这就被称为信息隐藏或封装。封装提高了软件的可重用性,因为模块之间不紧密相连,最后封装也降低了构建大型系统的风险,即使整个系统不可用,但是这些模块可能是有用的。
接口设计有六大原则:单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则以及开闭原则。这些原则对接口设计有了很大的约束,本次我们实现的作业没有使用继承,所以里氏替换原则自然不会违背,同时由于设计比较简单,其他的原则也都一一满足了。
藕合度是度量一个代码单元在使用时与其他单元的关系。最理想,最松散的耦合,是一个单元无需其他代码单元特别的配合而可以使用。这里的Loose Coupling实际上和单一职责原则有些类似,主要是为了确保每一个类或方法的作用尽量单一,避免耦合。
在我们的作业中,最核心的模块是core,内部有一个实例化的储存图主要信息的private对象graph,所以外部无法调用,这很好的实现了封装。同时,计算模块(core)和图模块(graph)是分开的,所以彼此不会干扰,各司其职,耦合度自然满足条件。
四、计算模块接口的设计与实现
我们的计算模块是Core,同时储存图信息以及和图相关的运算与运算结果都存储在graph中,graph是在实例化Core对象时自动实例化的一个对象,其存储在Core 中。由于get_chain_char和get_chain_word的内部实现其实很相似,仅仅是边的权值不同,所以我们也在Core内部抽象出一个公共接口,这样外部在调用get_chain_word和get_chain_char的时候只需要调用这个公共接口就好了。具体的流程图如下:

算法大致思路:首先对问题进行建模:该问题可以抽象为在一个有向图中求最长路径的问题:每个单词的首尾字母分别为有向图中的节点,然后一个单词就抽象为一条边,最长链即为最长路径。
- 第一步是对输入的异常进行检测,如果输入的单词不合法或者指定的头尾不合法则报错。
- 第二步是对输入的单词进行建图。这里有两种模式,如果是调用get_chain_word则权值是1,否则权值为单词的长度。同时,对于自环的情况我们单独处理的,相当于后面拓扑排序的时候直接跳过了自环。
- 第三步是进行拓扑排序。此步骤的目的是判断是否有环以及为后面的算法做准备
- 第四步是根据上一步的排序结果选择不同的算法。如果有环则进行暴力搜索,如果没环则根据排序结果从尾到头做一次dp即可。
独到之处:
- 节省空间。每条边只存了一个权值,即1或其单词长度。在一开始建图的时候就会加判断,节省了空间。
- 代码复用。不管有环还是无环都会先调用拓扑排序的算法,该算法即进行了排序也可以判断是否有环。同时,我们的内部接口实现也做到了代码复用与减少代码之间的耦合。
- 实现简洁。拓扑排序时我们采用的是经典的dfs的写法,没有采用入度和出度的写法,实现方式更简洁,效率也不错,同时代码看上去也很简单。
五、UML图
由于vs2017可以自动导出类图,我们最终生成的类图如下:

六、计算模块接口部分的性能改进
【引自小伙伴的博客】
这一部分中我们花费了约3-4小时。我们主要针对有环情况的算法进行改进。
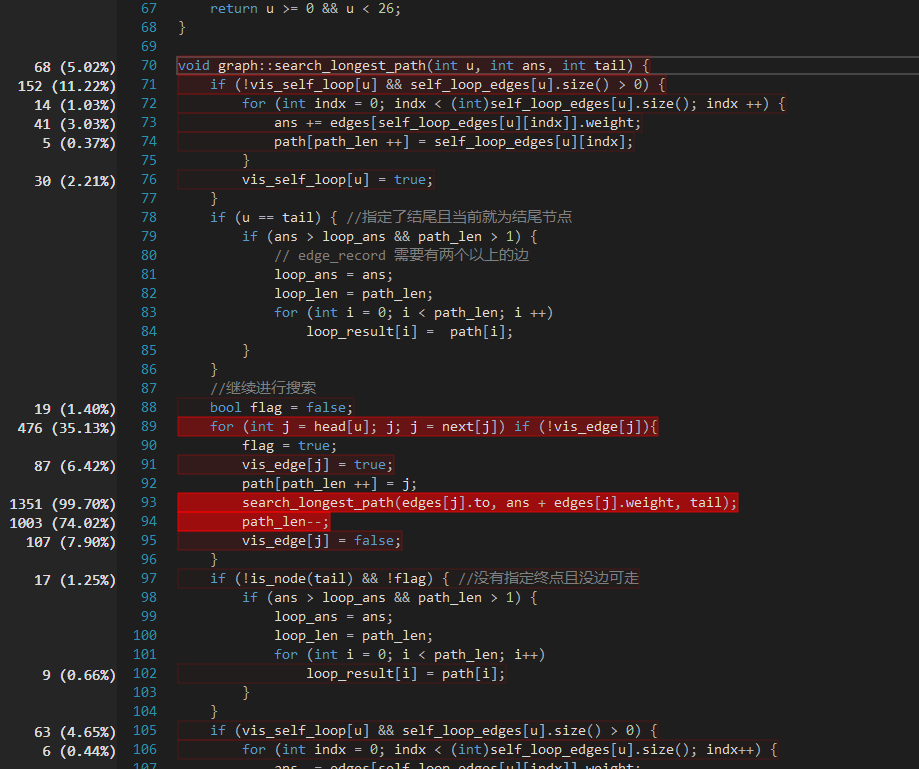
由于在一个有向有环图中寻找最长的路径是一个NP问题,从算法本身的角度来看无论如何都逃不开NP这个坑,因此我们使用了普通的DFS来进行。我们优化的地方在于将算法中访存的消耗尽可能降低。起初我们使用了vector作为路径存储的数据结构,在经过一次性能分析后我们发现递归部分中退栈操作很多,因此我们将vector改为一维数组,将原先的pop_back变成栈顶指针的--操作,从而降低了时间消耗。
下图为有环情况下消耗CPU最多的函数,即DFS的主函数
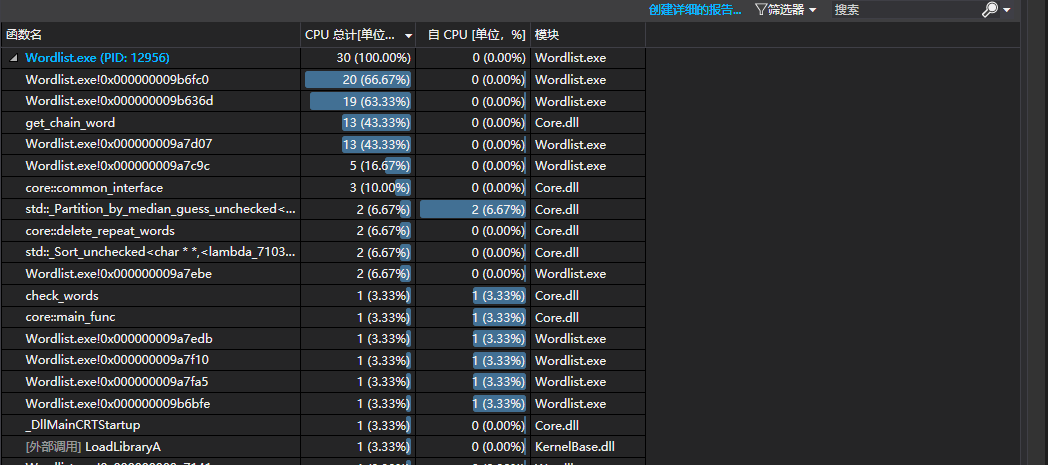
我们使用一个9000余词的文件对于无环情况进行了测试,结果发现算法在无环情况下表现良好,get_chain_word/char中消耗最多的部分实际上是接口中进行malloc的部分。
七、Design by Contract, Code Contract
Design by Contract, 即契约编程:我们在声明一个函数/方法的时候,对函数的输入和输出所具备的性质是有所期望和规定的。有时候这种性质会被我们明确的写出来,有时候会被我们忽略掉。这些期望和规定就是Contract。
其好处是责任的细化。每个程序猿都只需要处理自己的契约范围负责。同时,有责任的时候也能很快的定位到个人。
在我们的作业中,由于我们是两个人共同开发和debug的,所以有些地方并没有很严格的按照这个要求来做。
八、计算模块部分单元测试展示
【引自小伙伴的博客】
单元测试范例
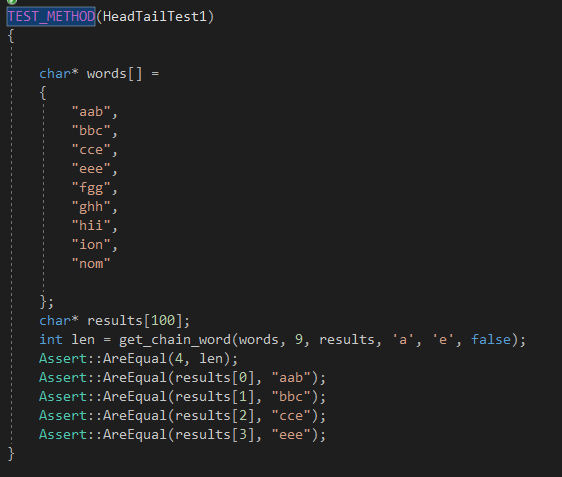
单元测试部分我们分别对无环和有环以及各种异常情况进行了测试,共构造了19个单元测试。
构造测试的思路大体上是尽可能覆盖各个分支。由于char和word两个接口在具体运行时仅仅是初始化权值不同,因此测试中我们更注重于各种特殊情况的测试,如开头和结尾的自环等。
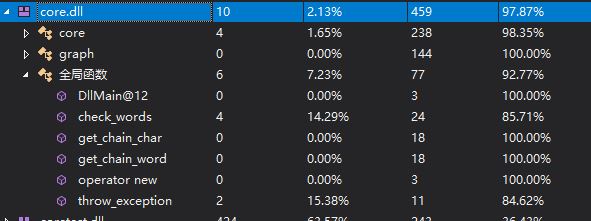
单元测试的分支覆盖率为97%,其中包含了各种异常测试的覆盖。
九、计算模块部分异常处理说明
异常一 输入的头或尾不是字母
在输入的头或尾不是字母的情况下会抛出异常,以下为测试样例:
void invalid_head()
{
char* words[] =
{
"aba",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 1, 0, false);
}
TEST_METHOD(WordsException9)
{
Assert::ExpectException<std::invalid_argument>([&] {exception_test::invalid_head(); });
try
{
exception_test::invalid_head();
}
catch (const std::exception& e)
{
Assert::AreEqual("Core: invalid head or tail", e.what());
}
}
异常二 有环但没有指定-r参数
在检测到图中有环但是输入的参数中没有-r参数,会抛出异常:
void has_loop()
{
char* words[] =
{
"aba",
"aca",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 0, false);
}
TEST_METHOD(WordsException8)
{
Assert::ExpectException<std::invalid_argument>([&] {exception_test::has_loop(); });
try
{
exception_test::has_loop();
}
catch (const std::exception& e)
{
Assert::AreEqual("Core: loop deteced in words, you need to use -r to parse.", e.what());
}
}
异常三 输入的words数组中有空串
如果输入的words数组中某个字符串为空的话也会抛出异常,测试样例如下:
void empty_string()
{
char* words[] =
{
"",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 0, false);
}
TEST_METHOD(WordsException6)
{
Assert::ExpectException<std::invalid_argument>([&] {exception_test::empty_string(); });
try
{
exception_test::empty_string();
}
catch (const std::exception& e)
{
Assert::AreEqual("Core: empty string in words", e.what());
}
}
异常四 输入的串中有无效字符
如果输入的字符串中有无效字符,则会抛出该异常:
void invalid_char_test()
{
char* words[] =
{
"a12345",
"avdc",
"fewt"
};
char* results[100];
int len = gen_chain_word(words, 3, results, 0, 0, true);
}
TEST_METHOD(WordsException5)
{
Assert::ExpectException<std::invalid_argument>([&] {exception_test::invalid_char_test(); });
try
{
exception_test::invalid_char_test();
}
catch (const std::exception& e)
{
Assert::AreEqual("Core: invalid char in words", e.what());
}
}
异常五 没有足够单词
如果输入的words数组的长度len <= 1则同样会抛出异常,因为链的长度要求必须大于1,所以如果单词个数为负数或01的情况也会抛出异常,测试样例如下:
void not_enough_words()
{
char* words[] =
{
"a"
};
char* results[100];
int len = gen_chain_word(words, 1, results, 0, 0, true);
}
TEST_METHOD(WordsException7)
{
Assert::ExpectException<std::invalid_argument>([&] {exception_test::not_enough_words(); });
try
{
exception_test::not_enough_words();
}
catch (const std::exception& e)
{
Assert::AreEqual("Core: not enough words", e.what());
}
}
十、命令行模块
【引自小伙伴的博客】
界面主要分为两大部分:命令行参数读取解析及文件读取。
在命令行参数解析部分,由于目前已有很多的开源库可供使用,本着不重复造轮子的原则我们使用了一个较为轻量的头文件库cxxopts来处理命令行参数。这个库可以自动将各个参数的值读出并对不合法的情况抛出异常。但由于其涉及的不合法情况较为朴素,我对一些相对复杂的不合法输入进行了处理,例如同时输入-w和-c、或输入了两个-w的情况。
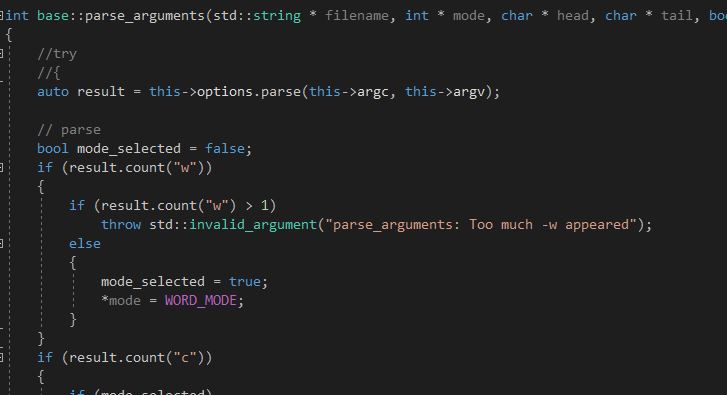
最终我将命令行参数读取和分析封装在base类的parse_arguments函数中,函数通过参数将读取到的值返回。
在文件读取部分,我设计的思路是按字符从文件头开始向后扫描,并在出现特殊字符的位置断开,从而将文件中的合法单词分隔出来。
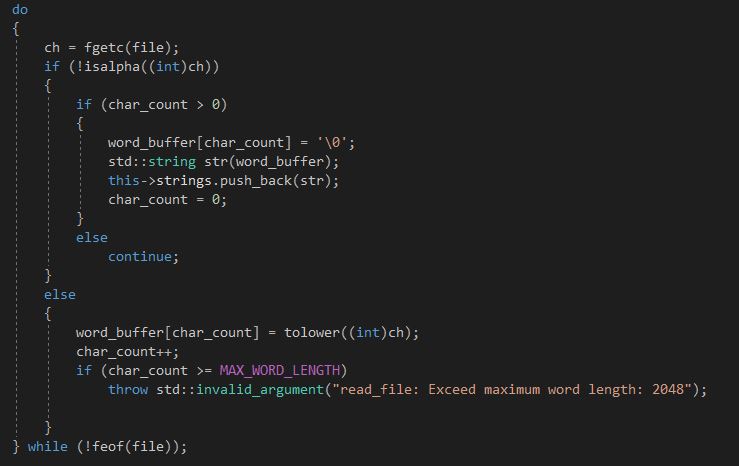
注意到在读文件过程中我对单词的长度也做了约束,如读到长度过长的单词则会抛出异常。最终将以上单词保存在base类成员中的数组内即可。
十一、命令行与计算模块的对接
【引自小伙伴的博客】
dll模块对接方面我使用了Base模块显式调用Dll的方法(即仅借助dll文件,不借助lib文件)。通过windows.h中的LoadLibrary和GetProcAddress实现。最终将调用的过程与开头读文件、解析参数等过程结合,形成完整的运行程序。
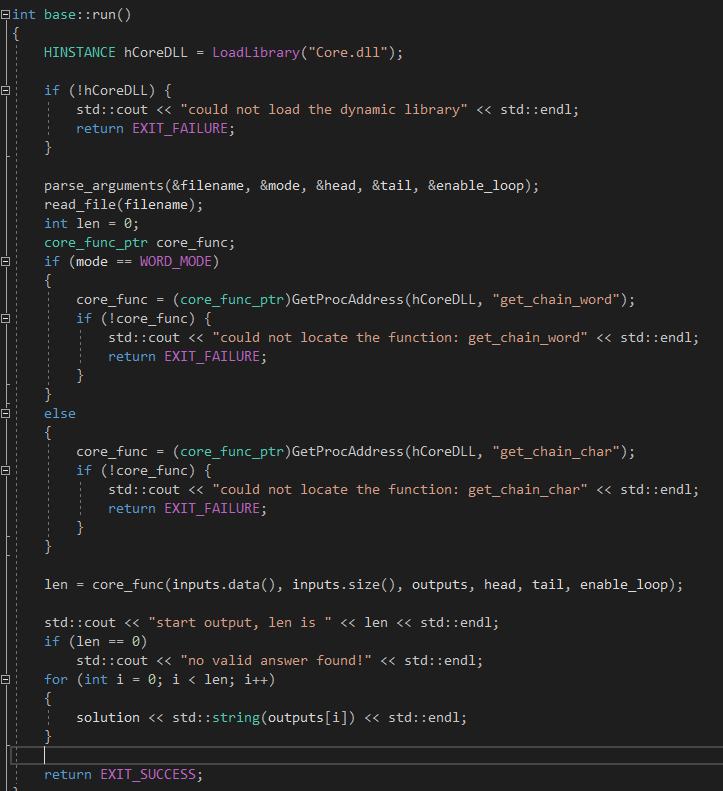
十二、结对过程
由于我们两人大多数时间都是在线上用teamviewer交流,加上前两次线下讨论模块设计的时候忘了拍照片,所以我们提供我们线上交流的截图。
我们结对的过程其实还是蛮顺利的。一开始我们在大概设计好模块之后便各司其职,我负责处理计算部分,另一个小伙伴写完了输入和异常。最后的dll生成和单元测试由于我不是很熟悉,所以我们是连上teamviewer,然后小伙伴来操作,我提供一些帮助。所以整个过程其实蛮愉快的。就是我们开始的时间有点晚了以及中间有些事情耽搁导致进度有点偏慢。不过这次结对编程确实是一次很棒的经历,收获颇丰。
十三、结对编程的优缺点
结对编程最大的优点在于,同一份代码经过两个人的复审之后代码的质量会有很大提升。同时,两人在写代码的过程中不断交流思路,代码的架构也会更加丰富。
缺点在于如果两个配合不好的话可能造成1 + 1 < 2的后果,主要原因是问题过于简单导致浪费时间以及问题过于难导致聚在一起讨论也是浪费时间。
<tbody>
<tr>
<td>庹东成</td>
<td>(1)对计算模块比较熟。 (2)对问题能够提出自己的看法并实践 (3)对待小伙伴很友善</td>
<td>对vs2017不太熟,导致后面生成dll和测试的时候进展缓慢 </td>
</tr>
<tr>
<td>周博闻</td>
<td>(1)对vs2017很熟,以及操作熟练 (2)认真仔细,能够想到很多易忽略的点 (3)对待小伙伴很友善</td>
<td>对于题目要求有些地方不是很了解 </td>
</tr>
</tbody>
| 成员 | 优点 | 缺点 |
|---|
十四、PSP表格回填
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 210 | 400 |
| · Design Spec | · 生成设计文档 | 90 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 120 | 90 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 300 | 180 |
| · Coding | · 具体编码 | 500 | 720 |
| · Code Review | · 代码复审 | 300 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 300 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 120 | 150 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 2030 | 2250 |
我们与16101061、16061118组互换了Core.dll进行测试。
我们的dll文件可以在对方的界面模块下运行:
但对方的Core模块并不能被我们的base模块调用。询问得知对方的Core以C#实现,当我使用dumpbin查看其中导出的函数时并不能查看到任何信息。
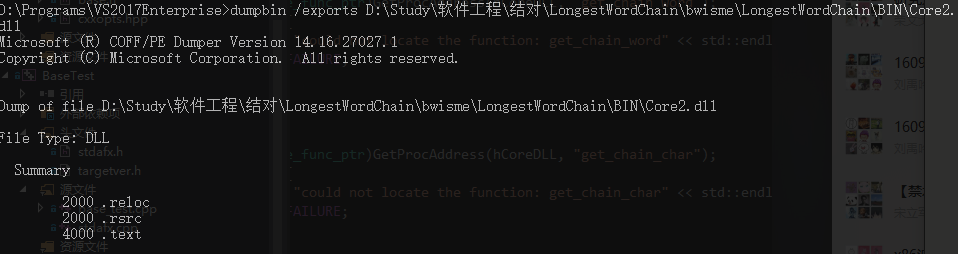
在上网查阅了一些资料后我了解到C++调用C#需要将dll转换为C#的类组件,貌似并没有类似于c++这样直接调用的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号