
[LIME] [SHAP] 如何解释机器学习模型
5.14更新
LIME
- 动机:在全局中独立变量对结果的影响可能非常复杂,难以直观得到关系
- 如果专注于一个局部,可以把他们的关系近似为线性模型
- 提出 Local Interpretable Model-Agnostic Explanations,在一组可解释的表示上确定一个可解释的模型,使这个模型在局部与分类器一致

- 可解释的数据表示 Interpretable Data Representations
- 无论模型得到的输入是什么,需要提取一组人类可理解的数据表示。如:文本分类中表示word是否存在的one-hot二元向量;图像分类中表示图像中的一块连续区域是否存在的二元向量。用表示待解释样本的原始表示,表示可理解的表示。
- 精确度-可解释性的取舍 Fidility-Interpretability Trade-off
- 对于一个可解释的模型,表示一组潜在的可解释模型,包括线性模型、决策树等。的定义域是,也就是表示一组可解释元素的存在与否。由于不是所有都足够简单,定义为模型的复杂性(与可解释性相对)。如:决策树的则为树的深度;线性模型的为非零权重数。
- 对于一个模型,在分类任务中,表示属于特定类别的概率,进一步用作为样本z接近x的接近程度,作为x的邻域。表示在定义的邻域中,与的距离(不相似度)。则,在精确度-可解释性的取舍中,LIME的目标是:

SHAP
Shapley值是一个来自合作博弈论(cooperative game theory)的方法,由Shapley在1953年创造的Shapley值是一种根据玩家对总支出的贡献来为玩家分配支出的方法,玩家在联盟中合作并从这种合作中获得一定的收益。用Shapley值去解释机器学习的预测的话,其中“总支出”就是数据集单个实例的模型预测值,“玩家”是实例的特征值,“收益”是该实例的实际预测减去所有实例的平均预测。
SHAP作者发现现有的6个可解释方法实际可以解释为同一种模型。
对于简单的模型来说,最好的解释就是模型本身,同时满足可解释性和完备性。对于复杂的模型(如集成方法或深度网络),原始模型它不容易理解。我们必须使用一种更简单的解释模型explanation model,定义为原始模型的任何可解释的近似。用f表示原始模型,g表示解释模型。
SHAP将Shapley值解释表示为一种加性特征归因方法(additive feature attribution method),将模型的预测值解释为二元变量的线性函数:
其中,是简化输入的特征数,
LIME就是直接在局部应用上式提供可解释性,把简化的输入作为可解释的输入,用把表示可解释输入的二元向量映射到原始输入空间。在局部上,使时
DeepLIFT对神经网络每个神经元的激活程度与参考值比较,分配贡献分数,从而反推输入对结果的贡献。
对每个输入,归因为一个值,表示这个输入的效果被设为参考值reference value。映射把二元的特征转换为原始输入,其中1表示输入不变,0表示输入取参考值。参考值可以是人工指定的对这个特征无背景信息的值,
其中是模型输出,,,表示输入的参考值。
使,DeepLIFT就满足了加性特征归因方法的定义。
传统的Shapley值估计:现有三个方法利用博弈论来计算模型解释,包括Shapley regression values、Shapley sampling values、和Quantitative Input Influence。这里不展开讲了。
加性特征归因方法是满足以下三个条件的唯一解决方案:
- 局部精度 Local Accuracy:对特定输入近似原始模型时,局部精度要求解释模型至少和对简化的输入输出匹配:
- 缺失性 Missingness:如果简化的输入表示特征是否存在,缺失性要求输入中缺失的特征对结果没有影响:
- 一致性 Consistency:一致性要求如果模型发生变化,简化输入的贡献应当增加或不变,与其他输入无关:


定理1来自于合作博弈论的组合结果,表示Shapley值。Young (1985)证明了Shapley值是唯一满足局部精度、一致性和一个冗余属性的值。还需要满足缺失性才能证明Shapley值满足加性特征归因方法。
本文提出一种统一的方法来改进现有方法,防止破坏局部精度和一致性。
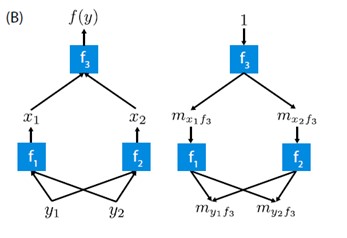
- 本文提出SHAP值作为特征重要性的统一指标。原始模型的条件期望函数的Shapley值满足定理1,其中,是中非零值的下标集合。如图

- SHAP值解释了怎样从没有任何特征信息时的基础值获得当前输出。
- 当模型是非线性或输入特征不独立时,添加特征的顺序就很重要,SHAP值为所有可能的顺序取平均。
- SHAP值使用条件期望来定义简化输入。定义中隐含了一个简化输入映射,其中不包含中缺失的值。由于大多数模型不能处理缺失输入,我们把近似为。SHAP值的定义设计为近似前面讲的6种方法。
- SHAP值的计算非常困难,本文提出两种模型无关的近似方法:
- Shapley sampling values (现有)、Kernel SHAP (新)
- 还描述了四种针对不同模型的近似方法:
- Linear SHAP、Low-Order SHAP(现有)、Max SHAP、Deep SHAP(新)
- 其中,特征独立性和模型线性度是可选假设。表示不在中的特征集合

模型无关方法
在近似条件期望时假设特征相互独立,则SHAP值可以直接用Shapley sampling values或Quantitative Input Influence方法得到。本文还提出了计算量更少的近似方法。
Kernel SHAP (Linear LIME + Shapley values)
线性的LIME是加性特征归因方法,由于LIME的参数选择是启发式的,不能保证结果是满足之前三个条件的唯一解Shapley values。

当或时,,为了使,在优化过程中要消除两个变量避免无限权重。
假设是线性的,是平方误差,LIME的优化目标仍然可以用线性回归求解,因此Shapley值可以通过加权线性回归计算。
Kernel SHAP通过提高模型无关的采样效率加快了SHAP值计算,如果对模型类型增加限制,可以提出更快的近似方法。
Linear SHAP
对于线性模型,如果假设特征独立,SHAP值可以直接从模型的权重参数直接近似得到。

Low-Order SHAP
Kernel SHAP的线性回归计算复杂度为,如果能对条件期望取近似,对于较小的比较高效。
Max SHAP
通过对Shapley值进行变换,我们可以计算每个输入增加其他输入最大值的概率。在有序的输入上可以把时间复杂度从提高到。
没看懂
Deep SHAP (DeepLIFT + Shapley values)
为了引入外部信息,如果把DeepLIFT的参考值解释为,则DeepLIFT会假设输入特征独立且深度模型为线性,从而近似SHAP值。
DeepLIFT用的线性合成规则等效于把神经网络中的非线性部分线性化。反向传播的规则直观定义了每个元素如何线性化,但是是通过启发式方法选择的。由于DeepLIFT是满足局部精度和缺失性的加性特征归因方法,可知Shapley值是唯一满足一致性的归因值。采用DeepLIFT作为SHAP值的近似成分,即可得到Deep SHAP。
Deep SHAP把网络中各个小组件的SHAP值组合为整个网络的SHAP值。

实验

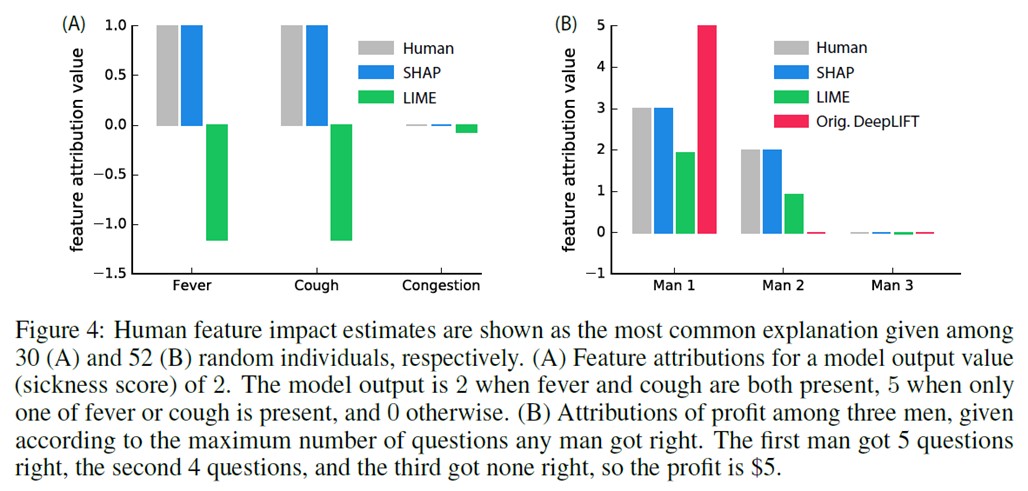

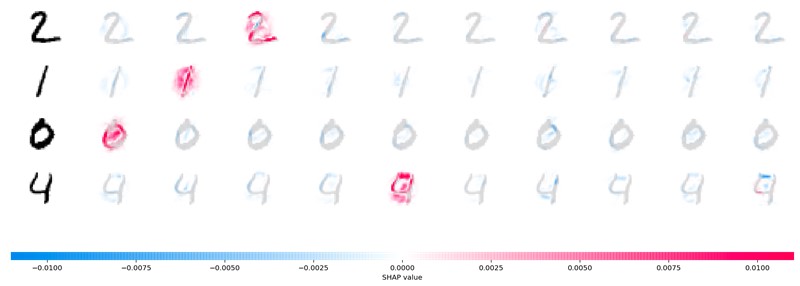

原始内容

常用方法:
特征重要性:模型预测多大程度依赖一个特征


部份相关图(partial dependence plots):一个特征如何影响模型输出

固定其他特征改变单个特征的值,查看对结果的影响
Lime:哪些变量导致了预测
LIME: Local Interpretable Model-Agnostic Explanations
target和独立变量之间的关系在全局中可能非常复杂,难以直观得到他们之间的关系,如图,绿星是一个待解释的实例:

如果放大到非常局部(local)的层级,我们可以把这种关系近似为线性模型。
LIME的工作流程:
- 采样原始数据中接近待解释实例的样本
- 计算样本和待解释实例的距离
- 用原始模型预测这些样本
- 用这些样本训练一个简单的线性模型
- 这个线性模型用第二步得到的相似性作为权重,确保最接近原始实例的样本的误差更重要
例:判断是否会信用卡违约

橙色表示特征贡献倾向违约,蓝色表示特征贡献倾向不违约。global模型预测结果为0.072,local模型预测结果为0.066。本例中global和local模型较类似。
对预测“不违约”的贡献最大的特征是上一个月的还款状态(PAY_0=1),表示上一个月的还款及时完成,PAY_2、PAY_3类似。说明如果上个月的还款按时完成,用户更可能在下一个月不违约。
LIMIT_BAL的贡献也倾向“不违约”。更高的LIMIT_BAL表示使用的额度很少,下个月的账单也可能很少,更不可能违约。
通过分析预测错误的样本可以更好的发现是什么特征导致了预测错误。

本例被错误分类为不违约,可能因为之前的账单都按时完成了,影响了预测结构。
根据以上的例子,LIME的总体思路看起来合理,但容易收到一些潜在缺陷影响。
- 局部线性行为。LIME假设对于实例周围的一小部分有效,但对于更复杂的数据集,随着局部范围增大,假设可能不成立。因此,局部可解释模型可能无法解释全局线性模型的行为。
- 特征数量。特征数量应道同时满足模型的复杂性和解释的简单性。python库提供以下选项:forward_selection, lasso_path, none, auto。
- LIME不支持没有概率分数的模型。
- LIME不能汇总特征的解释,要一个个实例去分析。
- 相似度分数。LIME在每个特征有不同值范围的高维空间中计算相似度较复杂。
- 邻居的定义。LIME需要定义局部的范围来找到邻居,没有确定邻域的最佳方法。
- 模型解释的一致性。由于采样偏差,相似性计算和邻域定义,LIME的解释缺乏一致性。
LIME提供了非常简单易懂的解释,是分析每个功能的快速方法。 LIME也可以用于文本和图像数据,与其他可解释的技术(例如SHAP)相比,LIME的执行时间更少。
Shap:哪些变量导致了预测
最常用的模型解释工具SHAP: SHapley Additive exPlanations
引入合作博弈论cooperative game theory和局部解释local explanations的概念来获得夏普利值shapley value。在合作博弈论的启发下SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。
假设第个样本为,第个样本的第个特征为,模型对该样本的预测值为,整个模型的基线(通常是所有样本的目标变量的均值)为,那么SHAP value服从以下等式:
其中为SHAP值。就是第个样本中第1个特征对最终预测值的贡献值。每个特征的SHAP值表示以该特征为条件时预期模型预测的变化。 对于每个功能,SHAP值说明了贡献,以说明实例的平均模型预测与实际预测之间的差异。 当,说明该特征提升了预测值,反之,说明该特征使得贡献降低。
传统的feature importance只告诉哪个特征重要,但我们并不清楚该特征是怎样影响预测结果的。SHAP value最大的优势是SHAP能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。
在给定age,gender和limit balance作为独立特征的情况下,预测该实例信用卡违约的可能性。计算age特征的SHAP value的步骤为:
- 对每个实例,gender和limit balance保持不变,age从分布中随机采样来替换;
- 模型预测该实例违约的概率;
- 所有实例的平均预测值和这个实例之间的差异仅在于随机采样的age无关的特征;
- 对于gender和limit balance重复以上步骤;
- age的SHAP value是所有可能组合的边缘分布的加权平均。

这个图展示了与平均预测结果相比每个特征在哪个方向起作用。右侧y轴表示相应的特征值,每个点表示数据中的一个实例。
- PAY_0表示上个月的还款状态,PAY_0值越高(红色),信用卡违约的可能性就比平均趋势高;
- LIMIT_BAL表示额度限制,值越低(蓝色)越可能导致违约。
单个实例:

上图展示了每个特征都各自有其贡献,将模型的预测结果从基础值(base value)推动到最终的取值(model output);将预测推高的特征用红色表示,将预测推低的特征用蓝色表示。
该实例被预测为不违约的主要贡献者是PAY_0=0,表示上个月按时还款会增加该实例被预测为不违约的几率。
缺点:
- 耗时:随着特征的增加,特征可能组合的数量呈指数增长,增加了SHAP的计算时间;
- 可能的特征组合的选择顺序:通常目标与独立特征非线性相关,且独立特征之间也有一定相关性,这种情况下组合特征的选择顺序很重要,并影响SHAP value;
- SHAP不返回模型,无法模拟研究某个特征值增加如何影响输出;
- 独立特征之间的相关性导致从特征的边缘分布采样时,可能生成现实生活中不可能的实例。
