
Java学习笔记---字符串
字符串操作是计算机程序设计中最常见的行为。
- 字符串操作是
- 不可变String
- 重载“+”与StringBuilder
- 无意识的递归
- String上的操作
- 格式化输出
- 正则表达式
- 扫描输入
- StringTokenizer
1.不可变String
String对象是不可变的,String类中每一个看起来会修改String值的方法,实际上都是创建了一个全新的String对象,以包含修改后的字符串内容。而最初的String对象则丝毫未动。
 在这个例子中,把q传给upcase()方法时,实际传递的是引用的一个拷贝。
在这个例子中,把q传给upcase()方法时,实际传递的是引用的一个拷贝。
其实,每当把String对象作为方法的参数时,都会复制一份引用,而该引用所指的对象其实一直待在单一的物理位置上,从未动过。
upcase()方法,传入其中的引用有了名字s,只有在upcase()运行的时候,局部引用s才存在。一旦upcase()运行结束,s就消失了。当然了,upcase()的返回值,其实只是最终结果的引用。这足以说明,upcase()返回的引用已经指向了一个新的对象,而原本的q则还在原地。
String这种行为正是编程所需要的。例如:

在这里,不希望upcase()改变其参数。对于一个方法而言,参数是为该方法提供信息的,而不是想让该方法改变自己的。
2.重载“+”与StringBuilder
String对象不可变,所以可以给一个String对象加任意多的别名。因为String对象具有只读特性,指向它的任何引用都不可能改变它的值,因此,也就不会对其他的引用有什么影响。
不可变性会带来一定的效率问题。为String对象重载的“+”操作符就是一个例子。重载的意思是,一个操作符在应用于特定的类时,被赋予了特殊的意义(用于String的“+”与“+=”是Java中仅有的两个重载过的操作符,而Java并不允许程序员重载任何操作符。)
操作符“+”可以用来连接String:
 猜想工作过程:String可能有一个append()方法,它会生成一个新的String对象,以包含“abc”与mango连接后的字符串。然后,该对象再与“def”相连,生成另一个新的String对象,以此类推。
猜想工作过程:String可能有一个append()方法,它会生成一个新的String对象,以包含“abc”与mango连接后的字符串。然后,该对象再与“def”相连,生成另一个新的String对象,以此类推。
这种工作方式当然也行的通,但是为了生成最终的String,此方式会产生一大堆需要垃圾回收的中间对象。其性能相当糟糕。
使用javap来反编译以上代码。命令:
 这里-c标志表示生成JVM字节码,内容如下:
这里-c标志表示生成JVM字节码,内容如下:
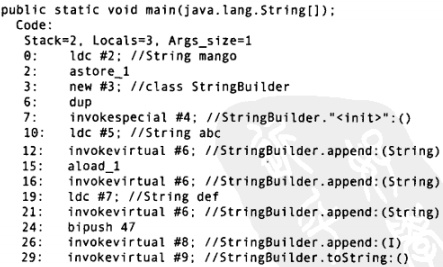
 编译器自动引入了java.lang.StringBuilder类,虽然源代码中并没有使用,但编译器自动应用了,因为它更高效。
编译器自动引入了java.lang.StringBuilder类,虽然源代码中并没有使用,但编译器自动应用了,因为它更高效。
在这个例子中,编译器创建了一个StringBuilder对象,用以构造最终的String,并为每个字符串调用一次StringBuilder的app()方法,总计四次。最后调用toString()生成结果,并存为s。
也许会觉得可以随意使用String对象,反正编译器会为你自动地优化性能。在这之前,我们先了解一下编译器会为我们优化到什么程度。下面使用两种方式来生成String:1).使用了多个String对象;2).在代码中使用StringBuilder。
 运行javap -c WitherStringBuilder反编译上面代码,可以看到两个方法对应的字节码。首先是implicit()方法:
运行javap -c WitherStringBuilder反编译上面代码,可以看到两个方法对应的字节码。首先是implicit()方法:
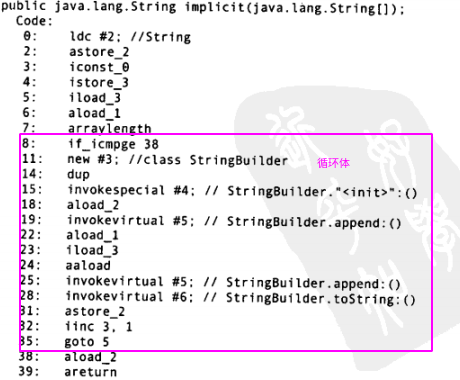 从第8行到第35行构成了一个循环体。第8行:对栈中的操作数进行“大于或等于的整数比较运算”,循环结束时跳到第38行。
从第8行到第35行构成了一个循环体。第8行:对栈中的操作数进行“大于或等于的整数比较运算”,循环结束时跳到第38行。
第35行:返回循环体的起始点(第5行)。重点是:StringBuilder是在循环之内构造的,这意味着每经过循环一次,就会创建一个新的StringBuilder对象。
再来看explicit()方法对应的字节码:
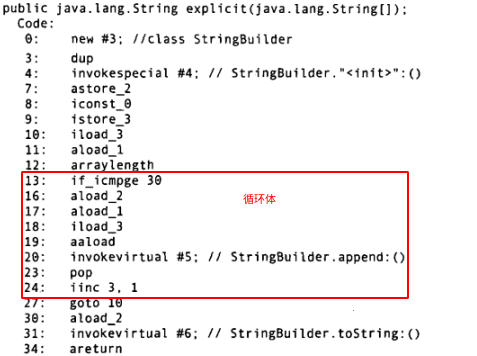 可以看到,步进循环体的代码更简单、更简短,而且它只生成一个StringBuilder对象。显式地创建StringBuilder还允许预先为其指定大小。
可以看到,步进循环体的代码更简单、更简短,而且它只生成一个StringBuilder对象。显式地创建StringBuilder还允许预先为其指定大小。
如果已经知道最终的字符串大概有多长,那预先指定StringBuilder的大小可以避免多次重新分配缓存。
因此,当你为一个类编写toString()方法时,如果字符串操作比较简单,那就可以信赖编译器,它会为你合理地构造最终的字符串结果。但是,如果要在toString()方法中使用循环,那么最好自己创建一个StringBuilder对象,用它来构造最终的结果。参考以下示例:
 最终的结果是用append()语句一点点拼接起来的。
最终的结果是用append()语句一点点拼接起来的。
若想走捷径,例如append(a+ ":" + c),那么编译器就会调入陷阱,从而为你另外创建一个StringBuilder对象处理括号内的字符串操作。
如果拿不准该用哪种方式,随时使用javap来分析你的程序。
StringBuilder提供了丰富而全面的方法,包括insert(),repleace(),substring()甚至reverse(),但是最常用的还是append()和toString()。还有delete()方法,上面的例子用它删除最后一个逗号与空格,以便添加右括号。
需要注意:StringBuilder是Java SE5引入的,在这之前Java用的是StringBuffer。后者是线程安全的,因此开销也会大些,所以在Java SE5/6中,字符串的操作应该会更快一点:
总结:
若需要循环拼接字符串,最好的方法是使用StringBuilder对象,使用方法append()逐个将字符串进行拼接,最后使用方法toString()方法将其保存为一个字符串。
若是简单的字符串拼接,可以使用“+”号,编译器会合理地构造最终的字符串结果。
3.无意识的递归
Java中的每个类从根本上都是继承Object,标准容器自然也不例外。因此容器类都有toString()方法,并且覆写了该方法,使得它生成的String结果能够表达容器自身,以及容器所包含的对象。例如ArrayList.toString(),它会遍历ArrayList中包含的所有对象,调用每个元素上的toString()方法:
 如果希望toString()方法打印出对象的内存地址,可以考虑使用this关键字:
如果希望toString()方法打印出对象的内存地址,可以考虑使用this关键字:
 当你创建了InfiniteRecursion对象,并将其打印出来的时候,会得到一串非常长的异常。
当你创建了InfiniteRecursion对象,并将其打印出来的时候,会得到一串非常长的异常。
如果将该InfiniteRecursion对象存入一个ArrayList,然后打印该ArrayList,你也会同样的异常。其实,当如下代码运行时:
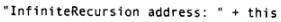 这里发生了自动类型转换,由InfiniteRecursion类型转换成String类型。因为编译器看到一个String对象后面跟着一个“+”,而再后面的对象不是String,于是编译器试着将this转换成一个String。如何转换:正是通过调用this上的toString()方法,于是就发生了递归调用。
这里发生了自动类型转换,由InfiniteRecursion类型转换成String类型。因为编译器看到一个String对象后面跟着一个“+”,而再后面的对象不是String,于是编译器试着将this转换成一个String。如何转换:正是通过调用this上的toString()方法,于是就发生了递归调用。
若真想打印出对象的内存地址,应该调用Object.toString()方法,这才是负责此任务的方法。所以,不该使用this,而是应该调用:super.toString()方法。
总结:
不要在toString()方法中调用对象本身的toString()方法,若使用this会很容易碰到这个问题,得使用super.this就可以避免这个问题。
4.String上的操作
以下是String对象具备一些基本方法。重载的方法归纳在同一行中:


可以总结:
当需要改变字符串的内容时,String类的方法都会返回一个新的String对象。
同时,若内容没有发生改变,String的方法只是返回指向元对象的引用而已。这可以节约存储空间以及避免额外的开销。
5.格式化输出
Java SE5推出了C语言风格的格式化输出功能,不仅使得控制输出的代码更加简单,同时也给与Java开发者对于输出格式与排列更强大的控制能力。
printf():
C语言中的printf()不能像Java那样连接字符串,它使用一个简单的格式化字符串,加上要插入的值,然后将其格式化输出。
printf()使用特殊的占位符来表示数据将来的位置,而且还将插入格式化字符串的参数,以逗号隔开,排成一排:
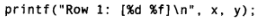 这一行代码在运行的时,首先将x的值插入到%d的位置,然后将y的值插入到%f的位置。这些占位符称作格式修饰符,不但说明了插入数据的位置,还说明了插入什么类型的变量,以及如何对其格式化。
这一行代码在运行的时,首先将x的值插入到%d的位置,然后将y的值插入到%f的位置。这些占位符称作格式修饰符,不但说明了插入数据的位置,还说明了插入什么类型的变量,以及如何对其格式化。
System.out.format():
Java SE5引入的format方法可用于PrintStream或PrintWriter对象,其中也包括System.out对象。format()方法模仿自C的printf()。也可以使用printf()方法:
 可以看到,format()与printf()是等价的,它们只需要一个简单的格式化字符串,加上一串参数即可,每个参数对应一个格式修饰符。
可以看到,format()与printf()是等价的,它们只需要一个简单的格式化字符串,加上一串参数即可,每个参数对应一个格式修饰符。
Formatter类:
在Java中,所有新的格式化功能都能由java.util.Formatter类处理。可以将Formatter看作一个翻译器,它将你的格式化字符串与数据翻译成需要的结果。当你创建一个Formatter对象的时候,需要向其构造器传递一些消息,告诉它最终的结果将向哪里输出:
 所有的tommy都将输出到System.out,而所有的terry则都输出到System.out的一个别名中。
所有的tommy都将输出到System.out,而所有的terry则都输出到System.out的一个别名中。
Formatter的构造器经过重载可以接受多种输出目的地,不过最常用的还是PrintStream、OutputStream和File。
Formatter功能就是将字符串与数据翻译成需要的结果,然后输出到某个地方,这个地方一般是PrintStream、OutputStream和File。
格式化说明符:
在插入数据时,若要控制空格与对齐,需要更精细复杂的格式修饰符。以下是其抽象的语法:
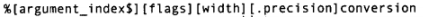
最常用的应用是控制一个域的最小尺寸,这可以通过指定width来实现。Formatter对象通过在必要时添加空格,来确保一个域至少达到某个长度。在默认情况下,数据是右对齐,不过可以通过使用“-”标志来改变对其方向。
与width相对的是precision,它用来指明最大尺寸。width可以应用于各种类型的数据转换,并且其行为方式都一样。precision则不一样,不是所有类型的数据都能使用precision,而且,应用于不同类型的数据转换时,precision的意义也不同:
在将precision应用于String时,它表示打印String时输出字符的最大数量。
将precision应用于浮点数时,表示小数部分要显示出来的位数(默认是6位小数),如果小数位数太多则舍入,太少则在尾部补零。
由于整数没有小数部分,所以precision无法应用于整数。
下面的程序应用格式修饰符来打印一个购物收据:


通过相当简洁的语法,Formatter提供了对空格与对齐的强大控制能力。
Formatter转换:
下面的表格包含了最常用的类型转换:
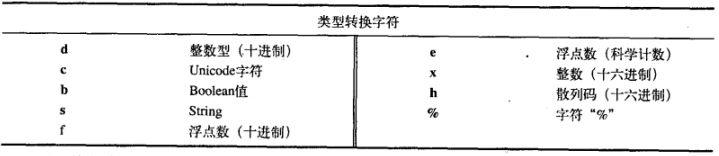
下面的程序演示了这些转换是如何工作的:


 被注释的代码表示,针对相应类型的变量,这些转换是无效的。
被注释的代码表示,针对相应类型的变量,这些转换是无效的。
程序中的每个变量都用到了b转换。虽然它对各种类型是合法的,但其行为取不一定与你想象的一致。对于boolean基本类型和Boolean对象,其转换结果是对应的true或false。但是对其他类型的参数,只要该参数不是null,那转换的结果永远都是true。即使是数字0,转换结果依然是true,但这在c语言中是false。所以将b应用于非布尔值类型的对象时应格外小心。
前面的章节已经说过:不能将int,String等基本类型赋值给boolean型对象,它们之间不能实现转换。
String.format():
Java SE5也参考了C中的sprintf()方法,已生成格式化的String对象。String.format()是一个static方法,它接受与Formatter.format()方法一样的参数,但返回一个String对象。当只需要使用forma()方法一次的时候,String.format()用起来很方便。例如:
 其实在String.format()内部,它也是创建一个Formatter对象,然后将你传入的参数转给该Formatter。不过,与其自己做这些事,不如使用便捷的String.format()方法,何况这样的代码更清晰。
其实在String.format()内部,它也是创建一个Formatter对象,然后将你传入的参数转给该Formatter。不过,与其自己做这些事,不如使用便捷的String.format()方法,何况这样的代码更清晰。
一个十六进制转储(dump)工具:
在处理二进制文件时,经常希望以十六进制的格式看看其内容。下面的小工具使用了String.format()方法,以可读的十六进制格式将字节数组打印出来:

 为了打开及读入二进制文件,用到了另一个工具net.mindview.util.BinaryFile。这里的read()方法将整个文件以byte数组的形式返回。
为了打开及读入二进制文件,用到了另一个工具net.mindview.util.BinaryFile。这里的read()方法将整个文件以byte数组的形式返回。
6.正则表达式
很久以前,正则表达式就已经整合到标准Unix工具集之中,而在Java中,字符串操作还主要集中于String,StringBuffer和StringTokenizer类。与正则表达式相比较,它们只能提供相当简单的功能。
正则表达式是一种非常强大的文本处理工具,使用正则表达式可以以编程的方式,构造复杂的文本模式,并对输入的字符串进行搜索。一旦找到了匹配这些模式的部分,就能随心所欲地对它们进行处理。
正则表达式处理的问题:匹配,选择,编辑以及验证。
基础:
一般来说,正则表达式就是以某种方式来描述字符串,例如:要找一个数字,它可能有一个负号在最前面,那么就写一个负号加上一个问号,就像这样: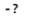
要描述一个整数,可以说它有一位或多位阿拉伯数字,在正则表达式中,用\d表示一位数字。
在其他语言中,\\表示要插入一个普通的反斜杠,而在Java中,\\表示插入一个正则表达式的反斜杠,所以其后面的字符具有特殊的意义。例如:\\d表示一位数字。若要插入一个普通的反斜杠,应该写成:\\\\。不过,换行和制表符之类的东西只需使用单反斜杠:\n\t。
要表示“一个或多个之前的表达式”,应该使用+。所以,若要表示“可能有一个负号,后面跟着一位或多位数字”,可以这样:-?\\d+。
应用正则表达式最简单的途径就是利用String类内建的功能。例如:可以检查一个String是否匹配如上所述的正则表达式。
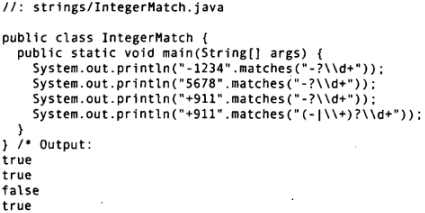 String内建的功能:str.matches()
String内建的功能:str.matches()
前两个字符串满足对应的正则表达式,匹配成功。第三个字符串开头有一个+,它也是合法的整数,但与对应的正则表达式却不匹配。
在正则表达式中,括号有着将表达式分组的效果,而竖线|则表示或操作。也就是:(-|\\+)?;表示负号或加号。这里因为+在正则表达式中有特殊的意义,所以必须用\\将其转义,使之成为表达式中的一个普通字符。
String类还自带了一个非常有用的正则表达式工具--split()方法,其功能是“将字符串从正则表达式匹配的地方切开。”
 String自带的另一个正则表达式工具:split()
String自带的另一个正则表达式工具:split()

第一个语句使用普通的字符作为正则表达式,其中并不包含任何特殊的字符。因此第一个split()只是按照空格来划分字符串。
第二个和第三个split()都用到了\W,它的意思是非单词字符(如果W小写,\w,则表示一个单词字符)。第二个例子将标点字符删除了;(因为标点符号是非单词字符)
第三个split()表示“字母n后面跟着一个或多个非单词字符”;
可以看到,在原始字符串中,与正则表达式匹配的部分,在最终的结果中都不存在了。因为split()功能是将字符串从匹配的地方切开。
String.split()还有一个重载的版本,它允许你限制字符串分割的次数。
String类自带的最后一个正则表达式工具是“替换”。可以只替换正则表达式第一个匹配的子串,或是替换所有匹配的地方。
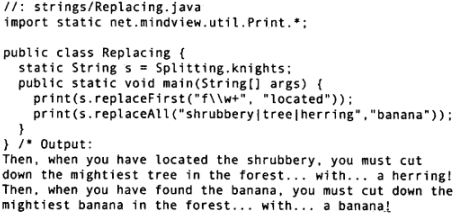 String自带的正则表达式工具:replaceFirst()和replaceAll();
String自带的正则表达式工具:replaceFirst()和replaceAll();
第一个表达式匹配的是,以字母f开头,后面跟着一个或多个字母(这里w是小写),并且只替换掉第一个匹配的部分,所以found被替换成located。
第二个表达式要匹配的是三个单词中的任意一个,因为它们以竖线分隔表示“或”,并且替换所有匹配的部分。
总结:
1.String类内建的三个正则表达式工具:
str.matches(regex);返回true或false,表示str是否与regex相匹配;
str.split(regex);返回字符数组,将字符串从正则表达式匹配的地方切开,相匹配的部分全部都被切割掉了;
str.replaceAll(regex,str1)和str.replaceFirst();返回字符串,在str中与regex相匹配的部分用str1进行替换。
2.几个简单的正则表达式:
\\:在正则表达式子中表示一个反斜杠
\\d:表示一个数字;
\\W:表示一个非字符;
\\w:小写w,表示一个字符
?:表示可能有一个?前面的内容;
+:表示多个;比如\\W+,表示多个非字符;\\d+表示多个数字;
创建正则表达式:
首先从正则表达式可能存在的构造集中选取一个很有用的子集:

然后是字符类,学会使用字符类之后,正则表达式的威力才真正显现出来。

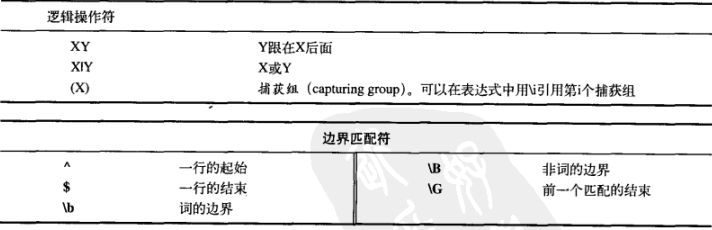
接下来是逻辑操作符和便捷匹配符:
下面是一个演示:

 我们的目的是编写尽量能够完成任务的、最简单以及最必要的正则表达式。
我们的目的是编写尽量能够完成任务的、最简单以及最必要的正则表达式。
量词:
量词描述了一个模式吸收输入文本的方式:
贪婪型:量词总是贪婪的,除非有其他的选项被设置。贪婪表达式会为所有可能的模式发现尽可能多的匹配。导致此问题的一个典型理由就是假定我们的模式仅能匹配第一个可能的字符组,如果它是贪婪的,那么它就会继续往下匹配。
勉强型:用问号来指定,这个量词匹配满足模式所需的最少字符数。因此也称作懒惰的、最少匹配的、非贪婪的、或不贪婪的。
占有型:目前,这种类型的量词只在Java中才可用,也更高级。当正则表达式被应用于字符串时,它会产生相当多的状态,以便在匹配失败时可以回溯。而“占有的”量词并不保存这些中间状态,因此它们可以防止回溯。它们常常用于防止正则表达式失控,因此可以使正则表达式执行起来更有效。
 表达式X通常必须用圆括号括起来,以便它能够按照我们期望的效果去执行。例如:abc+,表示的是ab后面跟一个或多个c;
表达式X通常必须用圆括号括起来,以便它能够按照我们期望的效果去执行。例如:abc+,表示的是ab后面跟一个或多个c;
而(abc)+则表示匹配一个或多个“abc”。
CharSequence:
接口CharSequence从CharBuffer、String、StringBuffer、StringBuilder类之中抽象出了字符序列的一般化定义:
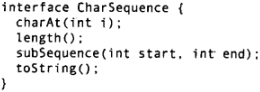 因此,这些类都实现了该接口。多数正则表达式都接受CharSequence类型的参数。
因此,这些类都实现了该接口。多数正则表达式都接受CharSequence类型的参数。
Pattern和Matcher:
比起功能有限的String类,更希望构造功能强大的正则表达式对象。只需要导入java.util.regex包,然后用static Pattern.compile()方法编译你的正则表达式即可。它会根据你的String类型的正则表达式生成一个Pattern对象。接下来,把你想要索引的字符串传入Pattern对象的matcher()方法。matcher()方法会生成一个Matcher对象,它有很多功能可用。例如:它的replaceAll()方法能将所有匹配的部分都替换成你传入的参数。
下面例子演示能否匹配一个输入字符串。第一个控制台参数是将要用来搜索匹配的输入字符串,后面的一个或多个参数都是正则表达式,它们将用来在输入的第一个字符串中查找匹配。在Unix/Linux上,命令行中的正则表达式必须用引号括起。
 Pattern对象表示编译后的正则表达式。
Pattern对象表示编译后的正则表达式。
该例子可以看到,使用已编译的Pattern对象上的matcher()方法,加上一个输入字符串,从而共同构建一个Matcher对象。同时,Pattern类还提供了static方法:
 该方法用以检查regex是否匹配整个CharSequence类型的input类型。
该方法用以检查regex是否匹配整个CharSequence类型的input类型。
编译后的Pattern对象还提供了split()方法,它从匹配了regex的地方分割输入字符串,返回分割后的子字符串String数组。
通过调用Pattern.matcher()方法,并传入一个字符串参数,我们得到一个Matcher对象。使用Matcher上的方法,将能够判断各种不同类型的匹配是否成功:
 其中的matches()方法用来判断整个输入字符串是否匹配正则表达式模式,而lookingAt()则用来判断该字符串的起始部分是否能够匹配模式。
其中的matches()方法用来判断整个输入字符串是否匹配正则表达式模式,而lookingAt()则用来判断该字符串的起始部分是否能够匹配模式。
find():
Matcher.find()方法可用来在CharSequence中查找多个匹配。例如:
 模式\\w+将字符串划分为单词。find()像迭代器那样前向遍历输入字符串。而第二个find()能接收一个整数作为参数,该整数表示字符串中字符的位置,并以其作为搜索的起点。
模式\\w+将字符串划分为单词。find()像迭代器那样前向遍历输入字符串。而第二个find()能接收一个整数作为参数,该整数表示字符串中字符的位置,并以其作为搜索的起点。
从结果可以看出,后一个版本的find()方法能根据其参数的值,不断重新设定搜索的起始位置。
组:
组是用括号划分的正则表达式,可以根据组的编号来引用某个组。组号为0表示整个表达式,组号1表示被第一对括号括起来的组,依次类推。因此,A(B(C))D中有三个组:组0是ABCD;组1是BC;组2是C。
Matcher对象提供了一系列方法,用以获取与组相关的信息:
public int groupCount()返回该匹配器的模式中的分组数目(第0组不包括在内)。
public String group()返回前一次匹配操作的第0组(整个匹配)。
public String group(int i)返回在前一次匹配操作期间指定的组号,如果匹配成功,但是指定的组没有匹配输入字符串的任何部分,则将会返回null。
public int start(int group)返回前一次匹配操作中寻找到的组的起始索引。
public int end(int group)返回在前一次匹配操作中寻找到的最后一个字符索引加一的值。
下面是正则表达式组的例子:
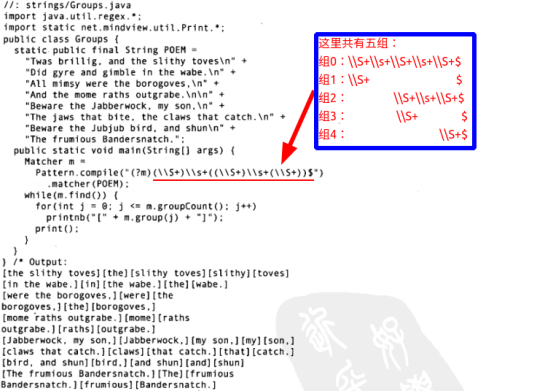
这个正则表达式有许多圆括号分组,由任意数目的非空格字符(\S+)及随后的任意数目的空格字符(\s+)所组成。目的是捕获每行的最后3个词,每行最后以$结束。
在正常情况下是将$与整个输入序列的末端相匹配。我们需要显式地告知正则表达式注意输入序列中的换行符。这可以由序列开头的模式标记(?m)来完成。
start()与end():
在匹配操作成功之后,start()返回先前匹配的起始位置的索引,而end()返回所匹配的最后字符的索引加一的值。
匹配操作失败之后(或先于一个正在进行的匹配操作去尝试)调用start()或end()将会产生IllegalStateException。
下面示例展示了matches()和lookingAt()的用法:

 find()可以在输入的任意位置定位正则表达式,而lookingAt()和matches()只有在正则表达式与输入的最开始处就开始匹配时才会成功。
find()可以在输入的任意位置定位正则表达式,而lookingAt()和matches()只有在正则表达式与输入的最开始处就开始匹配时才会成功。
matches()只有在整个输入都匹配正则表达式时才会成功,而lookingAt()只要输入的第一部分匹配就会成功。
Pattern标记:
Pattern类的compile()方法还有另外一个版本,接受一个标记参数,以调整匹配的行为:


在这些标记中,Pattern.CASE_INSENSITIVE、Pattern.MULTILINE以及Pattern.COMMENTS针对声明或文档特别有用。可以直接在正则表达式中使用其中的大多数标记,只需将上表中括号括起来的字符插入到正则表达式中,希望它起作用的位置即可。
还可以通过“或”(|)操作符组合多个标记的功能:
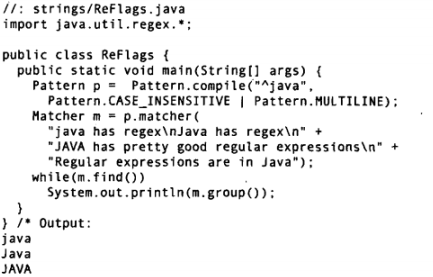 在这个例子中,创建了一个模式,它将匹配所有以“java”、“Java”和“JAVA”等开头的行,并且是在设置了多行标记的状态下,对每一个行(从字符序列的第一个字符开始,至每一个行终结符)都进行了匹配。group()只返回已匹配的部分。
在这个例子中,创建了一个模式,它将匹配所有以“java”、“Java”和“JAVA”等开头的行,并且是在设置了多行标记的状态下,对每一个行(从字符序列的第一个字符开始,至每一个行终结符)都进行了匹配。group()只返回已匹配的部分。
split():
split()方法将输入字符串断开成字符串对象数组,断开边界由下列正则表达式确定:
String[] split(CharSequence input)
String[] split(Charsequence input, int limit)
这是一个快速而方便的方法,可以按照通用边界断开输入文本:

 第二种形式的split()方法可以限制将输入分割成字符串的数量。
第二种形式的split()方法可以限制将输入分割成字符串的数量。
替换操作:
正则表达式特别便于替换文本,它提供了很多方法:
replaceFirst(String replacement)以参数字符串replacement替换掉第一个匹配成功的部分。
replaceAll(String replacement)以参数字符串replacement替换所有匹配成功的部分。
appendReplacement(StringBuffer sbuf, String replacement)执行渐进式的替换,不像replaceFirst()和replaceAll()那样只替换第一个匹配或全部匹配。这个方法允许调用其他方法来生成或处理replacement(replaceFirst()和replaceAll()则只能使用一个固定的字符串),使得能够以编程的方式将目标分割成组,从而具备更强大的替换功能。
appendTail(StringBuffer sbuf)在执行了一次或多次appendReplacement()之后,调用此方法可以将输入字符串余下的部分复制到sbuf中。
下面程序演示了如何使用这些替换方法。开头部分注释掉的文本,就是正则表达式要处理的输入字符串。

 此处使用了TextFile类打开并读入文件。
此处使用了TextFile类打开并读入文件。
static read()方法读入整个文件,将其内容作为String对象返回。
mInput用以匹配在/*!和!*/之间的所有文字。
接下来,将存在两个或两个以上空格的地方缩减为一个空格,并且删除每行开头部分的所有空格。(为了使每一行都达到这个效果,而不仅仅只是删除文本开头部分的空格,这里特意打开了多行状态)。这两个替换操作所使用的replaceAll()是String对象自带的方法,在这里,使用此方法更方便。(因为只使用了一次replaceAll(),与其便以为Pattern,不如直接使用String的replaceAll()方法,而且开销也更小些)
replaceFirst()只对找到的第一个匹配进行替换。此外,replaceFirst()和replaceAll()方法用来替换的只是普通的字符串。
在这个例子中,先构造了sbuf用来保存最终结果,然后用group()选择一个组,并对其进行处理,将正则表达式找到的元音字母转换成大写字母。
一般情况下,应该遍历执行所有的替换操作,然后再调用appendTail()方法,但是,如果你想模拟replaceFirst()的行为,那就只需执行一次替换,然后调用appendTail()方法,将剩余未处理的部分存入sbuf即可。
同时,appendReplaceMent()方法还允许你通过$g直接找到匹配的某个组,这里的g就是组号。然而,它只能应付一些简单的处理,无法实现类似前面这个例子中的功能。
reset():
通过reset()方法,可以将现有的Matcher对象应用于一个新的字符序列:
 使用不带参数的reset()方法,可以将Matcher对象重新设置到当前字符序列的起始位置。
使用不带参数的reset()方法,可以将Matcher对象重新设置到当前字符序列的起始位置。
正则表达式与Java I/O:
前面的例子都是将正则表达式应用于静态的字符串。下面的例子将演示如何将正则表达式应用在一个文件中进行搜索匹配操作。JGrep.java的灵感源自于Unix上的grep。它有两个参数:文件名以及要匹配的正则表达式。输出的是有匹配的部分以及匹配部分在行中的位置。
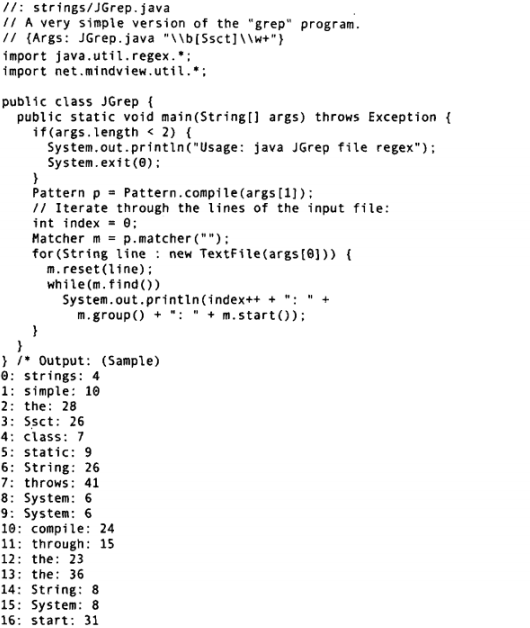 通过net.mindview.util.Text对象将文件打开,读入所有的行后,并存储在一个ArrayList中。
通过net.mindview.util.Text对象将文件打开,读入所有的行后,并存储在一个ArrayList中。
可以用循环来迭代遍历TextFile对象中的所有行。虽然也可以在for循环内部创建新的Matcher对象,但是,在循环外创建一个空的Matcher对象,然后用reset()方法每次为Matcher加载一行输入,这种处理会有一定的性能优化。最后用find()搜索结果。
7.扫描输入
到目前为止,从文件或标准输入读取数据还是一件相当痛苦的事情。一般的解决之道就是读入一行文本,对其进行分词,然后使用Integer、Double等类的各种解析方法来解析数据:
 input元素使用的类来自java.io,StringReader将String转化为可读的流对象,然后用这个对象来构造BufferReader对象,因为要使用BufferReader的readLine()方法。
input元素使用的类来自java.io,StringReader将String转化为可读的流对象,然后用这个对象来构造BufferReader对象,因为要使用BufferReader的readLine()方法。
最终可以使用input对象一次读取一行文本,就像是从控制台读入标准输入一样。
readLine()方法将一行输入转为String对象。如果每一行数据正好对应一个输入值,那这个方法也还可行。但是,如果两个输入值在同一行,事情就不好办了,必须分解这个行,才能分别翻译所需的输入值。
在这个例子中,分解的操作发生在创建numArray时,不过要注意,split()方法是在J2SE1.4中的方法,所以在这之前,还必须做些别的准备。
Java SE5新增了Scanner类,它可以大大减轻扫描输入的工作负担:
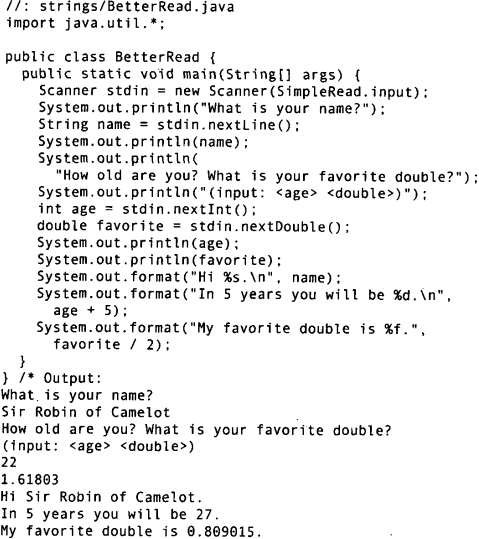
Scanner的构造器可以接受任何类型的输入对象,包括File对象、InputStream、String或者像磁力中的Readable对象。Readable是Java SE5中新加入的一个接口,标识“具有read()方法的某种东西”。前一个例子中的BufferedReader也归于这一类。
有了Scanner,所有的输入、分词以及翻译的操作都隐藏在不同类型的next方法中。普通的next()方法返回下一个String。所有的基本类型都有对应的next方法,包括BigDecimal和BigInteger。
所有的next方法,只有在找到一个完整的分词之后才会返回。
Scanner还有相应的hasNext()方法,用以判断下一个输入分词是否所需的类型。
在前面的两个例子中,BetterRead.java没有针对IOException添加try区块。因为,Scanner有一个假设,在输入结束时会抛出IOException,所以Scanner会把IOException吞掉。不过,通过ioException()方法,可以找到最近发生的异常,因此,可以在必要时检查它。
Scanner定界符:
默认情况下,Scanner根据空白字符对输入进行分词,但是可以用正则表达式指定自己所需的定界符:

这个例子使用逗号(包括逗号前后任意的空白字符)作为定界符,同样的技术也可以用来读取逗号分隔的文件。可以用useDelimiter()来设置定界符,同时,还有一个delimiter()方法,用来返回当前正在作为定界符使用的Pattern对象。
用正则表达式扫描:
除了能够扫描基本类型之外,还可以使用自定义的正则表达式进行扫描,这在扫描复杂数据的时候非常有用。下面例子将扫描一个防火墙日志文件中记录的威胁数据:
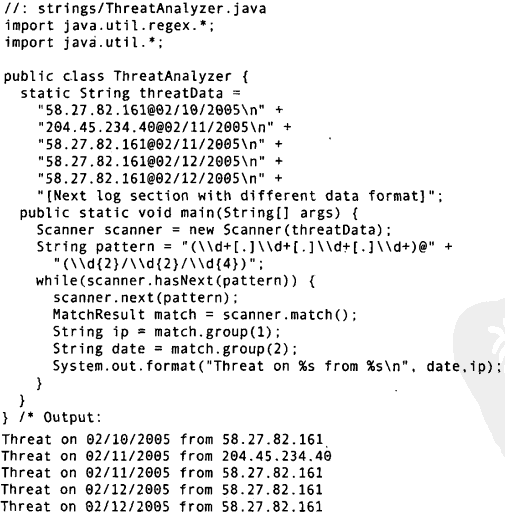
当next()方法配合指定的正则表达式使用时,将找到下一个匹配该模式的输入部分,调用match()方法就可以获得匹配的结果。如上所示,它的工作方式与之前看到正则表达式匹配相似。在配合正则表达式使用扫描时,有一点需要注意:它仅仅针对下一个输入分词进行匹配,如果你的正则表达式中有定界符,那永远不可能匹配成功。
8.StringTokenizer
在Java引入正则表达式(J2SE1.4)和Scanner类(Java SE5)之前,分割字符串的唯一方法是使用StringTokenizer来分词。不过,现在有了正则表达式和Scanner,可以使用更加简单、更加简洁的方式来完成同样的工作了。
下面例子将StringTokenizer与另两种技术做了一个比较:

使用正则表达式或Scanner对象,能够以更加复杂的模式来分割一个字符串,而这对于StringTokenizer来说就很困难了。基本上,我们可以放心的说,StringTokenizer已经可以废弃不用了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号