KMP学习笔记
最近在搞这个东西,不知道为啥,看一遍sb一遍。终于在今天下午从宿舍里猛的一起,狂奔到机房中,还在懵逼状态下的我终于搞懂了这个算法。纵观全网,kmp虽然是个很老很经典的算法,博客关于它的讲解也不少,我就把我的理解写一遍,希望对大家有所帮助。
首先kmp这个东西是干啥使的呢?比如你在打亡者农药,你方后羿无脑站前排输出,阿珂切tank,安琪拉大招刷野怪,吕布跳下去就g了,你项羽满血冲进去满血冲出来,你是不是这个时候特别想骂一句**呢?对,就是这个**,这种脏话过滤器就是用了kmp算法。下面就开始正式写这个算法。
P3375 【模板】KMP字符串匹配
这是个模板题。
首先理解这个算法的流程。我们普通的暴力算法是有一个文本串s1,一个模式串s2,长度分别是len1,len2。开始就是把文本串for一遍,如果s1[i]==s2[t],i++,t++,否则t=0,即当前文本串停止下一位的进行,而模式串从头上开始匹配对不对。这种方法实在是太慢了。而kmp这个算法的流程是,比如ababc,abc,开始的两位相等,而第三位a!=c,如果这是暴力算法,你的模式串将会从头开始匹配,而kmp则不然,他只需要再匹配一个c就好了,因为他记录了c前面的ab,与他正好是公共序列,所以时间复杂度的优势就体现了出来。
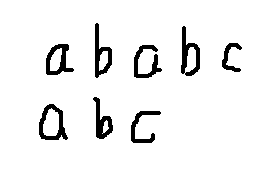
如上图的文本串和模式串,一开始a与a相等,b与b相等,但是到了第三位,a与c不相等,根据next数组,当我们失配时,我们就可以向后移动next个单位,就像上图,当你失配后,直接移动next个单位,开始匹配。
for(int i=0; i<len1; i++) { while(k&&a1[i]!=a2[k])k=kmp[k]; k+=a1[i]==a2[k]?1:0; if(k==len2)printf("%d\n",i-len2+2); }
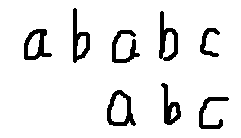
如上图。现在可能会问,那怎么处理next数组呢?
处理next数组也不难,我们只需要自己匹配自己就好了。那为啥呢,我们自己匹配自己,记录我们的模式串前缀的多少。
for(int i=1; i<len2; i++) { while(k&&a2[i]!=a2[k])k=kmp[k]; kmp[i+1]=(a2[i]==a2[k])?++k:0; }
以上就是这个算法,虽然是MP
#include<iostream> #include<cmath> #include<cstdio> #include<cstring> using namespace std; char a1[1000001],a2[1000001]; int kmp[2000000]; int main() { cin >> a1; cin >> a2; int len1=strlen(a1),len2=strlen(a2); int k=0; for(int i=1; i<len2; i++) { while(k&&a2[i]!=a2[k])k=kmp[k]; kmp[i+1]=(a2[i]==a2[k])?++k:0; } k=0; for(int i=0; i<len1; i++) { while(k&&a1[i]!=a2[k])k=kmp[k]; k+=a1[i]==a2[k]?1:0; if(k==len2)printf("%d\n",i-len2+2); } for(int i=1; i<=len2; i++) cout<<kmp[i]<<' '; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号