第一次个人编程作业
| 这个作业属于哪个课程 | 信安1912 |
|---|---|
| 这个作业要求在哪里 | |
| 这个作业的目标 |
1. Github 链接
2. 计算模块接口的设计与实现过程
2.1 实现思路
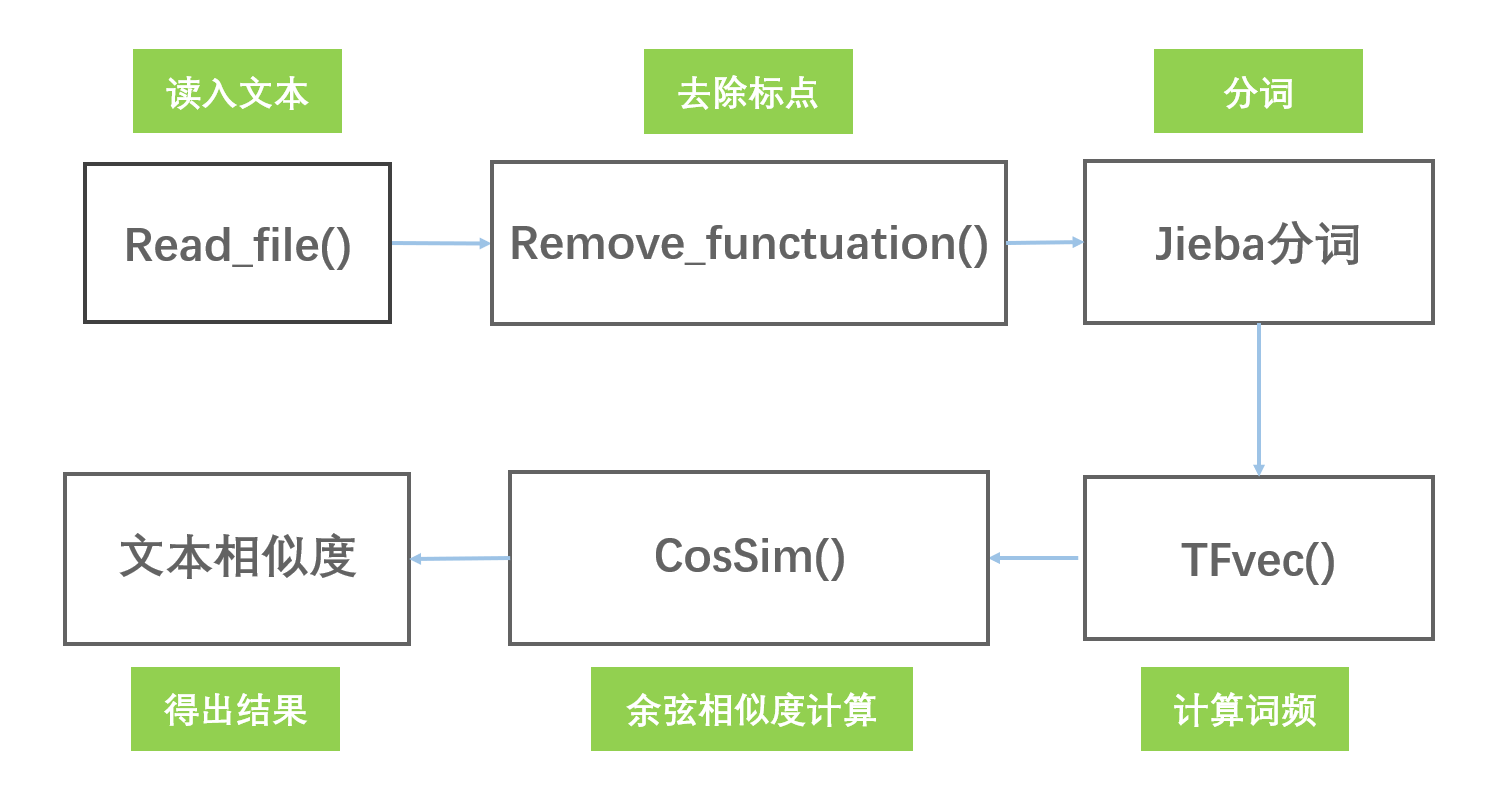
思路:
- 读文档:读入文档。
- 数据清洗:清除标点符号,正则表达式不太会,所以直接用字符简单粗暴,学会之后优化更改。
- 文本分词:jieba库分词。
- 词频计算:计算每个词的频率
- 余弦相似度计算:利用两个词频向量直接计算余弦值。
用到的库:
- jieba分词
- numpy规范矩阵以及余弦值计算
- time计算运行时间
2.2 余弦相似度计算原理:
【举一个例子,来说明余弦计算文本相似度】
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。

3. 部分模块
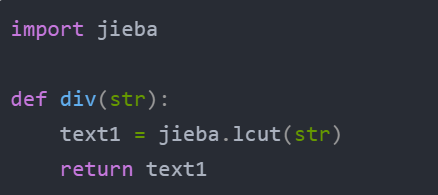
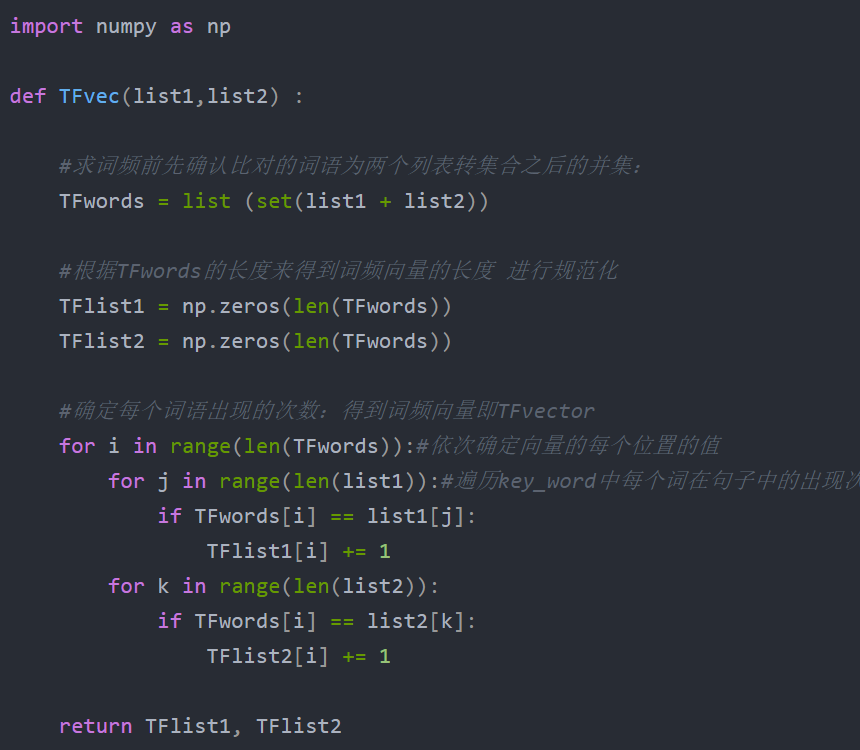

4. 相似度结果





5.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| - Estimate | - 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 1375 | 2350 |
| - Analysis | 需求分析(包括学习新技术) | 30 | 200 |
| - Design Spec | 生成设计文档 | 5 | 15 |
| - Design Review | 设计复审 | 5 | 10 |
| - Coding Standard | 代码规范(为目前的开发制定合适的规范) | 15 | 5 |
| - Design | 具体设计 | 300 | 300 |
| - Coding | 具体编码 | 600 | 1200 |
| - Code Review | 代码复审 | 300 | 500 |
| - Test | 测试 | 120 | 120 |
| Reporting | 报告 | 110 | 165 |
| - Test Repor | 测试报告 | 30 | 60 |
| - Size Measurement | 计算工作量 | 20 | 10 |
| - Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 95 |
| 合计 | 1505 | 2545 |
6.Summary
- 还有很多没来的及做
(做了 没解决) - 说明还有很多进步空间
(精神胜利法) - 几天只睡了几个钟 脑子已经不能思考了
(找借口 没有) - 很久没敲代码了
(不配)很多不会的都是直接在菜鸟教程现学现卖(哪里卖了) - python重温了
(就没学完过) - 实践进步很快 我很喜欢 下次继续
(进步啥了) - 中秋快乐!!!
(手下留情)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号