
基于Caffe的DeepID2实现(中)
小喵的唠叨话:我们在上一篇博客里面,介绍了Caffe的Data层的编写。有了Data层,下一步则是如何去使用生成好的训练数据。也就是这一篇的内容。
小喵的博客:http://www.miaoerduo.com
博客原文:https://www.miaoerduo.com/2016/07/15/deepid2-2/
二、精髓,DeepID2 Loss层
DeepID2这篇论文关于verification signal的部分,给出了一个用于监督verification的loss。
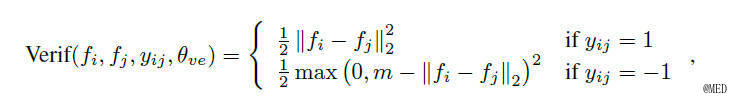
其中,fi和fj是归一化之后的特征。
当fi和fj属于同一个identity的时候,也就是yij=1时,loss是二者的L2距离,约束使得特征更为相近。
当fi和fj不属于同一个identity的时候,即yij=-1,这时的loss表示什么呢?参数m又表示什么?
m在这里是margin的意思,是一个可以自行设置的参数,表示期望的不同identity的feature之间的距离。当两个feature的大于margin时,说明网络已经可以很好的区分这两个特征,因此这是loss为0,当feature间的距离小于margin时,loss则为(m-|fi - fj|)^2,表示还需要两个特征能够更好的区分。因此这个loss函数比较好的反应了我们的需求,也就是DeepID2的算法思想。
这个Loss层实现起来似乎并不麻烦,前馈十分的简单。至于后馈,求导也非常简单。但是Caffe加入新层,需要在caffe.proto文件中,做一些修改,这也是最困扰小喵的地方。
不过有个好消息就是:Caffe官网增加了ContrastiveLossLayer这个层!
和我们的需要是一样的。因此我们不需要自己实现这个层。
喜大普奔之余,小喵也专门看了Caffe的文档,以及这里提到了siamese network,发现这个网络使用ContrastiveLossLayer的方式比较独特,Caffe项目中的examples中有例子,感兴趣可以看看。
ContrastiveLossLayer的输入,也就是bottom有三部分,feature1、feature2、label,feature1和feature2是分别对应的两组feature,而label则表示该对feature是否是属于同一个identity,是的话,则为1,不是则为0。而且该层还提供一个参数margin,也就是论文的公式里面的m。
最终的结论就是,虽然我们不需要自己写Loss层,但是还是必须增加一些额外的层。
主要有2个,用于将特征归一化的NormalizationLayer以及用于将feature层转换成ContrastiveLossLayer的输入的层,不妨命名为ID2SliceLayer。
三、小问题,大智慧之Normalization Layer
这个归一化的层用于将输入的feature map进行归一化。Caffe官网并没有提供相关的层,因此我们必须自己实现(或者从网上找),这里我们还是选择自己来实现,顺便学习一下Caffe加层的技巧。
Normalization层的前馈非常的简单,输入为一个向量x,输出为归一化之后的向量:
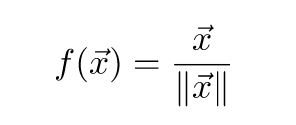
至于后馈,需要求导,计算稍微有点复杂,小喵在推导4遍之后才给出如下表达式:
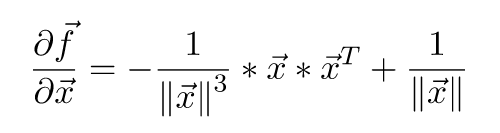
其中x为输入的特征向量,为列向量。这里是将整个feature map看做一个列向量。
知道了前馈后馈的计算规则,那么很容易编写自己的层了,这里小喵建议大家找个Caffe已经有了的内容相近的层,照着改写。比如这个Normalization层,没有任何层的参数,所以照着ReLU类似的层就很好编写。
之后就祭出我们的code:
1 // create by miao 2 // 主要实现了feature的归一化 3 #ifndef CAFFE_NORMALIZATION_LAYER_HPP_ 4 #define CAFFE_NORMALIZATION_LAYER_HPP_ 5 6 #include <vector> 7 8 #include "caffe/blob.hpp" 9 #include "caffe/layer.hpp" 10 #include "caffe/proto/caffe.pb.h" 11 12 #include "caffe/layers/neuron_layer.hpp" 13 14 namespace caffe { 15 16 template <typename Dtype> 17 class NormalizationLayer : public NeuronLayer<Dtype> { 18 public: 19 explicit NormalizationLayer(const LayerParameter& param) 20 : NeuronLayer<Dtype>(param) {} 21 virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom, 22 const vector<Blob<Dtype>*>& top); 23 virtual inline const char* type() const { return "Normalization"; } 24 virtual inline int ExactNumBottomBlobs() const { return 1; } 25 virtual inline int ExactNumTopBlobs() const { return 1; } 26 27 protected: 28 virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, 29 const vector<Blob<Dtype>*>& top); 30 virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom, 31 const vector<Blob<Dtype>*>& top); 32 virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, 33 const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); 34 virtual void Backward_gpu(const vector<Blob<Dtype>*>& top, 35 const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); 36 Blob<Dtype> norm_val_; // 记录每个feature的模 37 }; 38 39 } // namespace caffe 40 41 #endif // CAFFE_NORMALIZATION_LAYER_HPP_
这个层的头文件异常的简单,和ReLU的仅有的区别就是类的名字不一样,而且多了个成员变量norm_val_,用来记录每个feature的模值。
1 // create by miao 2 #include <vector> 3 #include <cmath> 4 #include "caffe/layers/normalization_layer.hpp" 5 #include "caffe/util/math_functions.hpp" 6 7 namespace caffe { 8 9 template <typename Dtype> 10 void NormalizationLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom, 11 const vector<Blob<Dtype>*>& top) { 12 NeuronLayer<Dtype>::LayerSetUp(bottom, top); 13 CHECK_NE(top[0], bottom[0]) << this->type() << " Layer does not " 14 "allow in-place computation."; 15 norm_val_.Reshape(bottom[0]->shape(0), 1, 1, 1); // 申请norm的内存 16 } 17 18 19 template <typename Dtype> 20 void NormalizationLayer<Dtype>::Forward_cpu( 21 const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { 22 23 Dtype *norm_val_cpu_data = norm_val_.mutable_cpu_data(); 24 for (int n = 0; n < bottom[0]->shape(0); ++ n) { 25 // 计算每个c * h * w的区域的模 26 norm_val_cpu_data[n] = std::sqrt(static_cast<float>( 27 caffe_cpu_dot<Dtype>( 28 bottom[0]->count(1), 29 bottom[0]->cpu_data() + bottom[0]->offset(n), 30 bottom[0]->cpu_data() + bottom[0]->offset(n) 31 ) 32 )); 33 // 将每个bottom归一化,输出到top 34 caffe_cpu_scale<Dtype>( 35 top[0]->count(1), 36 1. / norm_val_cpu_data[n], 37 bottom[0]->cpu_data() + bottom[0]->offset(n), 38 top[0]->mutable_cpu_data() + top[0]->offset(n) 39 ); 40 } 41 } 42 43 template <typename Dtype> 44 void NormalizationLayer<Dtype>::Backward_cpu( 45 const vector<Blob<Dtype>*>& top, 46 const vector<bool>& propagate_down, 47 const vector<Blob<Dtype>*>& bottom) { 48 49 const Dtype *norm_val_cpu_data = norm_val_.cpu_data(); 50 const Dtype *top_diff = top[0]->cpu_diff(); 51 Dtype *bottom_diff = bottom[0]->mutable_cpu_diff(); 52 const Dtype *bottom_data = bottom[0]->cpu_data(); 53 54 caffe_copy(top[0]->count(), top_diff, bottom_diff); 55 56 for (int n = 0; n < top[0]->shape(0); ++ n) { 57 Dtype a = - 1./(norm_val_cpu_data[n] * norm_val_cpu_data[n] * norm_val_cpu_data[n]) * caffe_cpu_dot<Dtype>( 58 top[0]->count(1), 59 top_diff + top[0]->offset(n), 60 bottom_data + bottom[0]->offset(n) 61 ); 62 Dtype b = 1. / norm_val_cpu_data[n]; 63 caffe_cpu_axpby<Dtype>( 64 top[0]->count(1), 65 a, 66 bottom_data + bottom[0]->offset(n), 67 b, 68 bottom_diff + top[0]->offset(n) 69 ); 70 } 71 } 72 #ifdef CPU_ONLY 73 STUB_GPU(NormalizationLayer); 74 #endif 75 76 INSTANTIATE_CLASS(NormalizationLayer); 77 REGISTER_LAYER_CLASS(Normalization); 78 79 } // namespace caffe
最后就是GPU部分的代码,如果不在乎性能的话,直接在CUDA的前后馈里面调用CPU版的前后馈就行。当然如果了解CUDA的话,完全可以写一份GPU版的代码。小喵这里就偷懒了一下。。。
1 // create by miao 2 #include <vector> 3 #include <cmath> 4 #include "caffe/layers/normalization_layer.hpp" 5 #include "caffe/util/math_functions.hpp" 6 7 namespace caffe { 8 9 template <typename Dtype> 10 void NormalizationLayer<Dtype>::Forward_gpu( 11 const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { 12 this->Forward_cpu(bottom, top); 13 } 14 15 template <typename Dtype> 16 void NormalizationLayer<Dtype>::Backward_gpu( 17 const vector<Blob<Dtype>*>& top, 18 const vector<bool>& propagate_down, 19 const vector<Blob<Dtype>*>& bottom) { 20 this->Backward_cpu(top, propagate_down, bottom); 21 } 22 INSTANTIATE_LAYER_GPU_FUNCS(NormalizationLayer); 23 } // namespace caffe
这样,我们就写完了Normalization层的所有代码。
对于比较老版本的Caffe,还需要修改/caffe_root/src/caffe/caffe.proto文件。而新版的Caffe只要在新增参数的情况下才需要修改。我们的这个Normalization层并没有用到新的参数,因此并不需要修改caffe.proto文件。
至于新版的Caffe为什么这么智能,原因其实就在这两行代码:
INSTANTIATE_CLASS(NormalizationLayer); REGISTER_LAYER_CLASS(Normalization);
宏INSTANTIATE_CLASS在/caffe_root/include/caffe/common.hpp中定义。
宏REGISTER_LAYER_CLASS在/caffe_root/include/caffe/layer_factory.hpp中定义。
感兴趣可以自行查阅。
转载请注明出处~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号