
窗口函数的使用
语法
‹窗口函数› over
(partition by ‹用于分组的列名›
order by ‹用于排序的列名›)
‹窗口函数›的位置,可以放以下两种函数:
-
专用窗口函数,比如rank, dense_rank, row_number等
-
聚合函数,如sum. avg, count, max, min等
专用窗口函数
表数据
| RowID | DeptID | PaidYear | PaidAmount |
|---|---|---|---|
| 1 | 10001 | 2022 | 20000 |
| 2 | 10002 | 2022 | 15000 |
| 3 | 20001 | 2022 | 10000 |
| 4 | 20002 | 2022 | 300000 |
| 5 | 20003 | 2022 | 10000 |
| 6 | 30001 | 2022 | 8000 |
| 7 | 10001 | 2021 | 5000 |
| 8 | 10002 | 2021 | 8000 |
| 9 | 20001 | 2021 | 10000 |
| 10 | 20002 | 2021 | 250000 |
| 11 | 20003 | 2021 | 10000 |
| 12 | 30001 | 2021 | 20000 |
建表语句
CREATE TABLE [DeptPaid](
[RowID] [bigint] IDENTITY(1,1) NOT NULL,
[DeptID] [bigint] NOT NULL,
[PaidYear] [nchar](4) NULL,
[PaidAmount] [numeric](18, 2) NULL
) ON [PRIMARY]
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (1, 10001, N'2022', CAST(20000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (2, 10002, N'2022', CAST(15000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (3, 20001, N'2022', CAST(10000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (4, 20002, N'2022', CAST(300000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (5, 20003, N'2022', CAST(10000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (6, 30001, N'2022', CAST(8000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (7, 10001, N'2021', CAST(5000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (8, 10002, N'2021', CAST(8000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (9, 20001, N'2021', CAST(10000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (10, 20002, N'2021', CAST(250000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (11, 20003, N'2021', CAST(10000.00 AS Numeric(18, 2)))
INSERT [DeptPaid] ([RowID], [DeptID], [PaidYear], [PaidAmount]) VALUES (12, 30001, N'2021', CAST(20000.00 AS Numeric(18, 2)))
select *,
rank() over (order by PaidAmount desc) as ranking,
dense_rank() over (order by PaidAmount desc) as dese_rank,
row_number() over (order by PaidAmount desc) as row_num
from DeptPaid where PaidYear='2022'
| RowID | DeptID | PaidYear | PaidAmount | ranking | dese_rank | row_num |
|---|---|---|---|---|---|---|
| 4 | 20002 | 2022 | 300000 | 1 | 1 | 1 |
| 1 | 10001 | 2022 | 20000 | 2 | 2 | 2 |
| 2 | 10002 | 2022 | 15000 | 3 | 3 | 3 |
| 3 | 20001 | 2022 | 10000 | 4 | 4 | 4 |
| 5 | 20003 | 2022 | 10000 | 4 | 4 | 5 |
| 6 | 30001 | 2022 | 8000 | 6 | 5 | 6 |
聚合函数
sqlserver2012以上版本支持
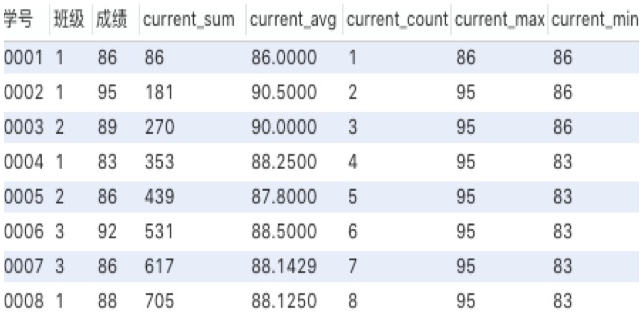
select *,
sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表;
窗口函数的移动平均
sqlserver2012以上版本支持
select *,
avg(成绩) over
(order by 学号 rows 2 preceding) as current_avg
from 班级表;
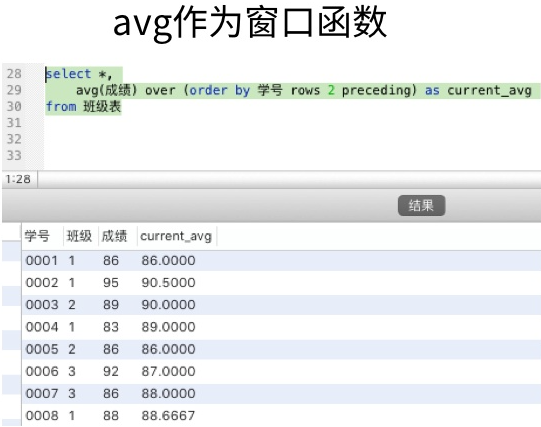
rows和preceding这两个关键字,是“之前~行”的意思,上面的句子中,是之前2行(总计最多3行)。也就是得到的结果是自身记录及前2行的平均。想要计算当前行与前n行(共n+1行)的平均时,只要调整rows…preceding中间的数字即可。
适用于:在公司业绩名单排名中,可以通过移动平均,直观地查看到与相邻名次业绩的平均、求和等统计数据。
使用场景
-
经典top N问题
找出每个部门排名前N的员工进行奖励# topN问题 sql模板 select * from (select *, row_number() over (partition by 要分组的列名 order by 要排序的列名 desc) as ranking from 表名) as a where ranking ‹= N; -
经典排名问题
业务需求“在每组内排名”,比如:每个部门按业绩来排名 -
在每个组里比较的问题
比如查找每个组里大于平均值的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号