Cracking Digital VLSI Verification Interview 第六章
欢迎关注个人公众号摸鱼范式,后台回复pdf获得全文的pdf文件

Verification Methodologies
UVM (Universal Verification Methodology)
[258] UVM的优点有哪些?
UVM是一种标准验证方法,已被收录为IEEE 1800.12标准。 UVM包括在设计测试平台和测试用例方面定义的方法,并且还附带有一个类库,可帮助轻松轻松地构建有效的受约束的随机测试平台。该方法的一些优点和重点包括:
- 模块化和可重用性:该方法被设计为模块化组件(Driver, Sequencer, Agents, Env等),这使跨模块级别的组件重用为多单元或芯片级验证以及跨项目。
- 将测试与测试平台分开:stimulus/sequencers方面的测试与实际的测试平台层次保持分开,因此可以在不同的模块或项目之间重复使用激励。
- 独立于模拟器:所有模拟器都支持基类库和方法,因此不依赖于任何特定的模拟器。
- Sequence方法可以很好地控制刺激的产生:有几种开发序列的方法:randomization, layered sequences, virtual sequences等。这提供了良好的控制和丰富的激励生成能力。
- Config机制简化了具有深层次结构的对象的配置:Config机制有助于基于使用它的验证环境轻松地配置不同的测试台组件,而无需担心测试台层次结构中任何组件的深度。
- 工厂机制可轻松简化组件的修改:使用工厂创建每个组件可以使它们在不同的测试或环境中被覆盖,而无需更改基础代码库。
[259] UVM的缺点有哪些?
显然,随着UVM方法在验证行业中的采用越来越广泛,UVM的优点会盖过缺点。
- 对于任何不熟悉该方法的人,要了解所有细节的学习曲线就非常陡峭。
- 方法论仍在发展中,并且有很多开销,有时可能会导致仿真缓慢或出现一些错误。
[260] 事务级建模的概念是什么?
事务级别建模(TLM,Transaction level Modelling)是一种在较高抽象级别上对任何系统或设计进行建模的方法。 在TLM中,使用事务对不同模块之间的通信进行建模,从而抽象出所有底层实现细节。 这是验证方法中用于提高模块化和重用性的主要概念之一。 即使DUT的实际接口由信号级别的活动表示,但大多数验证任务(如生成激励,功能检查,收集覆盖率数据等)都可以在事务级别上更好地完成,只要使它们独立于实际信号级别的细节即可 。 这有助于在项目内部和项目之间重用和更好地维护这些组件。
[261] 什么是TLM port和export?
在事务级建模中,不同的组件或模块使用事务对象进行通信。TLM port 定义了一组用于特定连接的方法(API),这些方法的实际实现称为TLM export。TLM port和export之间的连接建立了两个组件之间的通信机制。
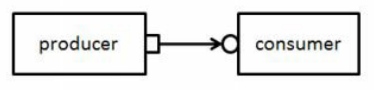
上面是一个简单的示例,演示了生产者如何使用一个简单的TLM port与消费者通信。生产者可以创建一个事务并将其“put”到TLM port,而“put”方法(也称为TLM export)的实现将在读取生产者创建的事务的使用者中进行,从而建立一个通信通道。
[262] 什么是TLM FIFO?
如果生产组件和消费组件都需要独立操作,则使用TLM FIFO进行事务性通信。在这种情况下(如下所示),生产组件生成事务并将其“放入”FIFO,而消费组件每次从FIFO获取一个事务并对其进行处理。

[263] TLM FIFO中的get方法和peek方法有什么区别?
get()操作将从TLM FIFO中返回一个事务(如果可用),并从FIFO中删除该事务。如果FIFO中没有可用的事务,它将阻塞并等待,直到FIFO至少有一个事务。peek()操作将从TLM FIFO中返回一个事务(如果可用),而不会实际从FIFO中删除该项目。它也是一个阻塞调用,如果FIFO没有可用的条目,它将等待。
[264] TLM FIFO中的get方法和try_get方法有什么区别?
get()是一个从TLM FIFO获取事务的阻塞调用。因为它是阻塞的,所以如果FIFO中没有事务,任务get()将等待。try_get()是一个非阻塞调用,即使FIFO中没有可用的事务,它也会立即返回。try_get()的返回值指示是否返回成功。下面是使用get()和try_get()的两个等效实现
阻塞方法,get
class consumer extends uvm_component;
uvm_get_port #(simple_trans) get_port;
task run;
for(int i=0; i<10; i++)
begin
t = get(); //blocks until a transaction is returned //Do something with it.
end
endtask
endclass
非阻塞方法,try_get
class consumer extends uvm_component;
uvm_get_port #(simple_trans) get_port;
task run;
for(int i=0; i<10; i++)
begin
//Try get is nonblocking. So keep attempting
//on every cycle until you get something
//when it returns true
while(!get_port.try_get(t))
begin
wait_cycle(1); //Task that waits one clock cycle
end //Do something with it
end
endtask
endclass
[265] analysis port和TLM port有什么区别?analysis FIFO和TLM FIFO的区别是什么?何时使用analysis FIFO 和 TLM FIFO?
TLM port/FIFOs用于具有使用put/get方法建立的通信通道的两个组件之间的事务级通信。
analysis port/FIFOs是另一种事务性通信通道,用于组件将事务广播给多个组件。
TLM port/FIFO用于driver和sequencer之间的连接,而analysis port/FIFOs用于monitor广播事务,这些事务可由scoreboard或覆盖率收集组件接收。
[266] sequence和sequence item有什么区别?
sequence item是对在两个组件之间传输的信息进行建模的对象(有时它也可以称为事务,transaction)。例如:考虑从CPU到主内存的内存访问,在主内存中CPU可以执行内存读或内存写,每个事务都有一些信息,比如地址、数据和读/写类型。sequence可以被认为是一个已定义的sequence item模式,它可以被发送到驱动程序以注入到设计中。sequence item的模式是由如何按顺序实现body()方法定义的。例如:扩展上面的例子,我们可以定义一个从10个事务中读取增量内存地址的sequence。在这种情况下,body()方法将被实现来生成10次sequence item,并将它们发送到驱动程序,同时在下一个项之前递增或随机地址。
[267] uvm_transaction和uvm_sequence_item的区别是什么?
uvm_transaction 派生自uvm_object。uvm_sequence_item不仅是一个事务,还组织了一些信息在一起,增加了一些其他信息,如:sequence id,和transaction id等等。建议使用uvm_sequence_item实现基于sequence的激励。
[268] component类中的copy,clone和create方法有什么区别?
- create()方法用于构造对象。
- copy()方法用于将一个对象复制到另一个对象。
- clone()方法是一个一步的命令来创建和复制一个现有的对象到一个新的对象句柄。它首先通过调用create()方法创建一个对象,然后调用copy()方法将现有对象复制到新句柄。
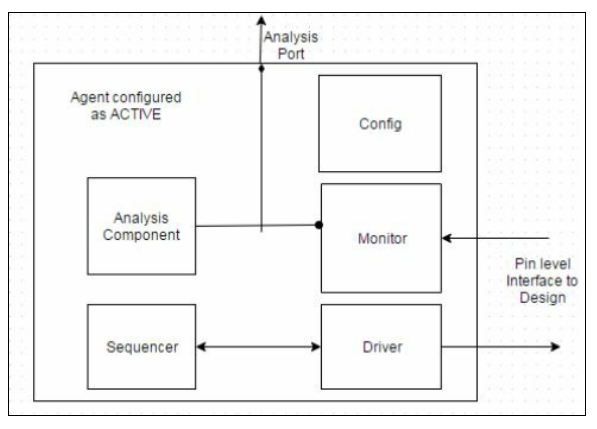
[269] 解释UVM方法学中的agent的概念
UVM agent是一个组件,它将一组其他uvm_components集中在DUT的特定pin级接口上。大多数dut具有多个逻辑接口,并且使用一个agent来对所有组件进行分组:driver, sequencer, monitor, 和其他组件,这些组件在特定的接口上进行操作。使用这种层次结构组织组件有助于跨具有相同接口的不同验证环境和项目重用“agent”。
下图是一个典型的agent组织方式。
[270] UVM agent中有多少种不同的组件?
如前所述,agent是基于DUT的逻辑接口进行分组的组件集合。一个agent通常有一个driver和一个sequencer来驱动它所操作的接口上的被DUT的激励。它还具有一个monitor和一个分析组件(如记分牌或覆盖率收集器)来分析该接口上的活动。此外,它还可以拥有配置agent及其组件的配置对象。
[271] 在uvm_object类中,get_name和get_full_name方法有什么区别?
get_name返回对象的名称,由new构造函数或set_name()方法中的名称参数提供。get_full_name返回对象的完整层次结构名称。对于uvm_components,在打印语句中使用时非常有用,因为它显示了组件的完整层次结构。对于没有层次结构的sequence或config对象,它将输出与get_name相同的值
[272] ACTIVE agent和PASSIVE agent有什么区别?
ACTIVE agent是能够在其操作的pin级接口上生成激励的代理。这意味着,像driver和sequencer这样的组件将被连接,并且会有一个sequence在其上运行以生成激励。
PASSIVE agent是不生成任何激励,但能监视接口上发生的活动的代理。这意味着,在被动代理中不会创建driver和sequencer。
在需要生成激励的模块级验证环境中,agent通常被配置为ACTIVE 。当我们从模块级转移到芯片级验证环境时,可以配置相同的agent,在这种环境中不需要生成激励,但是我们仍然可以在调试或覆盖率方面使用相同的agent来监视信号。
[273] 如何将agent配置为ACTIVE或者PASSIVE?
UVM agent有一个类型为UVM_ACTIVE_PASSIVE_e的变量,该变量定义了agent是ACTIVE的(UVM_ACTIVE),它构造了sequencer和driver,还是PASSIVE的(UVM_PASSIVE),它既不构造driver,也不构造sequencer。这个参数被称为active,默认情况下它被设置为UVM_ACTIVE。
当在environment类中创建agent时,可以使用set_config_int()更改这一点。然后,agent的build阶段应该具有如下代码,以有选择地构造driver和sequencer。
function void build_phase(uvm_phase phase);
if(m_cfg.active == UVM_ACTIVE)
begin //create driver, sequencer
end
endfunction
[274] 什么是sequencer和driver?为什么需要他们?
driver是将transaction或sequence item转换为一组基于信号接口协议的pin级别切换的组件。
sequencer是一个组件,它将sequence item从sequencer路由到driver,并将响应从driver路由回sequence。还负责多个sequence(如果存在)之间的仲裁。
在像UVM这样的TLM方法中,这些组件是必需的,激励产生是根据事务进行抽象的,而sequencer和driver是路由它们并将它们转换为实际的信号行为的组件。
[275] UVM中的monitor和scoreboard有什么区别?
monitor是观察pin级活动并将其观察结果转换为事务或sequence_items的组件。它还通过analysis port将这些事务发送到分析组件。
scoreboard是一个分析组件,用来检查DUT是否正常工作。UVM scoreboard使用来自agent内部实现的monitor来分析事务。
[276] 如何启动UVM?
run_test方法(一个静态方法)可以激活UVM测试平台。它通常在顶级测试模块的“initial begin…end”块中调用,它接受要运行的测试类的参数。然后它触发测试类的构造,build_phase()将在层次结构中执行并进一步构造Env/Agent/Driver/Sequencer 对象。
[277] 运行一个sequence需要哪些步骤?
运行一个sequence需要三个步骤:
- 创建一个sequence。使用factory create方法创建一个序列,如下所示:
my_sequence_c seq;
seq = my_sequence_c:: type_id::create(“my_seq”)
- 配置或随机化一个sequence。一个sequence可能有几个需要配置或随机化的数据成员。因此,要么配置值,要么调用seq.randomize()
- 开始一个sequence。sequence使用sequence.start()方法启动。start方法接受一个参数,该参数是指向sequencer的句柄。一旦sequence启动,sequence中的body()方法就会被执行,它定义了序列的操作方式。start()方法是阻塞的,只在sequence执行完成后返回。
[278] 解释sequencer和driver中的握手协议
UVM sequence-driver API主要在sequence和driver端使用阻塞方法,如下所述,用于将sequence item从sequencer传输到driver并从driver收集响应。
在sequence端,有两种方法:
- start_item(<item>):请求sequencer访问sequence item的driver,并在sequencer授予访问权时返回。
- finish_item(<item>):该方法使driver接收sequencer item,是一个阻塞方法,仅在driver调用item_done()方法后返回。
在driver侧
- get_next_item(req):这是一个在driver中的阻塞方法,它阻塞直到一个sequence item在连接到sequencer的端口上被接收。该方法返回sequence item,sequence item可由driver转换为pin级协议。
- item_done(req):driver使用这个非阻塞方法向sequencer发出信号,表明它可以解除对sequence中finish_item()方法的阻塞,无论是在driver接受sequence请求时,还是在它已经执行sequence请求时。
下图说明了sequencer和driver之间的协议握手,这是在sequencer和driver之间传输请求和响应时最常用的握手。
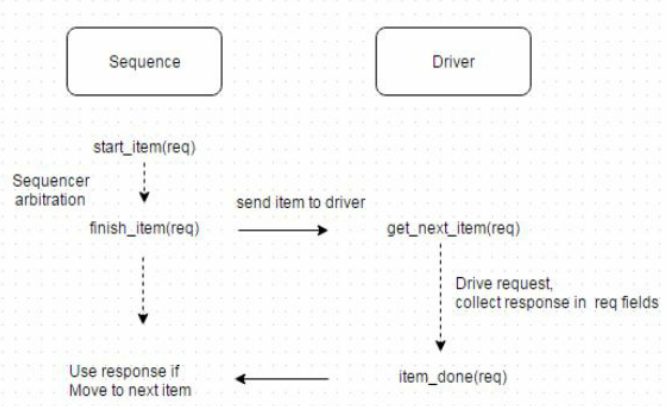
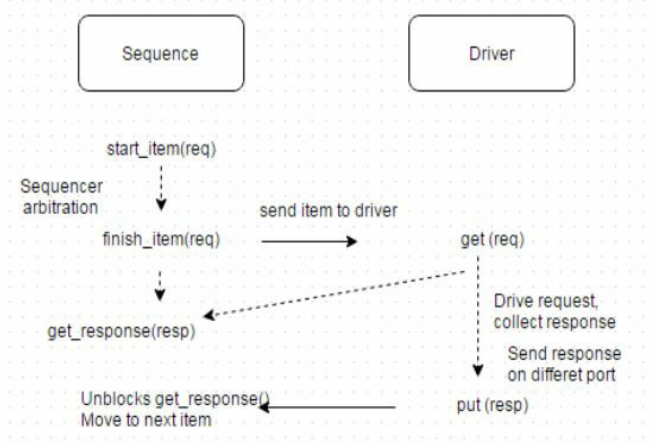
还存在一些其他替代方法:在driver中使用get()方法,它相当于调用get_next_item()和item_done()。
有时,如果从driver到sequence的响应包含比请求类中封装的信息更多的信息,那么还需要一个单独的响应端口。
在这种情况下,sequencer将使用get_response()阻塞方法,当driver使用put()方法在该端口上发送单独的响应时,该方法将被解除阻塞。如下图所示。
[279] 什么是sequence中的pre_body()和post_body()函数?他们通常会被调用吗?
pre_body()是sequence类中的一个方法,它在调用sequence的body()方法之前被调用。在调用body()方法之后,依次调用post_body()方法。并不总是调用pre_body()和post_body()方法。uvm_sequence::start()有一个可选参数,如果将其设置为0,将导致这些方法不被调用。下面是一个sequence中的start()方法的形式参数。
virtual task start (
uvm_sequencer_base sequencer, // Pointer to sequencer
uvm_sequence_base parent_sequencer = null, // parent sequencer
integer this_priority = 100, // Priority on the sequencer
bit call_pre_post = 1); // pre_body and post_body called
[280] sequence中的start方法使阻塞还是非阻塞方法?
start方法是一个阻塞方法,阻塞进程直到sequence的body方法执行完毕。
[281] sequencer有哪些仲裁机制?
多个sequence可以与同一个接口的driver并发交互。sequencer支持多种仲裁机制,以确保在任何时间点只有一个sequence可以访问driver。哪个sequence可以发送sequence_item取决于用户选择的仲裁机制。在UVM中实现了五种内置的仲裁机制。还有一个附加的回调函数可以实现用户定义的算法。sequencer具有一种称为set_arbitration()的方法,可以调用该方法来选择sequencer应使用哪种算法进行仲裁。可以选择的六种算法如下:
- SEQ_ARB_FIFO(默认值)。如果指定了此仲裁模式,那么sequencer将使用一个FIFO选择sequence。例如:如果seq1,seq2和seq3在sequencer上运行,它将首先从seq1中选择一个item,然后从seq2中选择一个item,然后从seq3中选择一个item(如果可用),然后继续。
- SEQ_ARB_WEIGHTED:如果选择此仲裁模式,则始终首先选择优先级最高的sequence,直到没有可用为止,然后再选择下一个优先级sequence,依此类推。如果两个sequence具有相同的优先级,则以随机顺序从中选择它们。
- SEQ_ARB_RANDOM:如果选择此仲裁模式,忽略所有优先级以随机顺序选择sequence。
- SEQ_ARB_STRICT_FIFO:与SEQ_ARB_WEIGHTED相似,不同之处在于,如果两个sequence具有相同的优先级,则来自这些sequence的项顺序是按FIFO顺序而不是随机顺序选择的。
- SEQ_ARB_STRICT_RANDOM:与SEQ_ARB_RANDOM相似,只是不忽略优先级。首先从优先级最高的序列中随机选择sequence,然后依次选择下一个和最高顺序。
- SEQ_ARB_USER:此算法允许用户定义用于sequence之间仲裁的自定义算法。这是通过扩展uvm_sequencer类并覆盖user_priority_arbitration()方法来完成的。
[282] 在sequencer上启动sequence时,如何指定其优先级?
通过将参数传递给序列的start()方法来指定优先级。 根据为权重来确定优先级。 例如:第三个参数指定sequence的优先级。
seq_1.start(m_sequencer, this, 500); //Highest priority
seq_2.start(m_sequencer, this, 300); //Next Highest priority
seq_3.start(m_sequencer, this, 100); //Lowest priority among three sequences
[283] sequence如何才能独占sequencer的访问权限?
当在sequencer上运行多个sequence时,sequencer进行仲裁并授予sequence的访问权限。 有时,一个sequence可能希望独占sequencer的访问权限,直到将其所有sequence_item送到driver为止(例如:如果您希望在不中断的情况下激发确定性模式)。 有两种机制允许sequence获得对sequencer的独占访问权。
- 使用lock()和unlock():sequence可以调用在其上运行的sequencer的lock方法。当sequence通过sequencer仲裁机制获得下一个访问权限时,将授予该sequence对driver的独占访问权限。如果还有其他标记为更高优先级的sequence,则此序列需要等待,直到获得授权。权限锁定后,其他sequence将无法访问driver,直到该序列在sequencer上调用unlock()后,权限将被释放。 lock方法是一个阻塞方法,直到授予锁后才返回。
- 使用grab()和ungrab():grab方法类似于lock方法,可以在需要独占访问时由sequence调用。grab和lock之间的区别在于,调用grab()时,它将立即生效,并且该sequence将100%获得下一个sequencer的授权机会,从而高于所有当前的sequence优先级。阻止sequence通过grab独占sequencer的唯一方法是sequencer上已经存在的lock()或grab()。
[284] sequencer上的lock和grab有什么区别?
在sequencer上运行的sequence使用sequencer的grab()和lock()方法来获得对该序列器的独占访问权,直到调用了相应的unlock()或ungrab()。 grab和lock之间的区别在于,当调用sequencer上的某个grab()时,它将立即生效,并且该sequence将获得下一个sequencer的授权,从而高于所有当前的sequence优先级。 但是,对lock()的调用将需要等待,直到sequence根据设置的优先级和仲裁机制获得其下一个授权为止。 在用法方面,可以使用lock来对优先级中断进行建模,并使用grab来对不可屏蔽的中断进行建模,在别的建模场景中也很有用。
[285] 流水线和非流水线sequencer-driver模型有什么区别?
根据需要如何通过interface发送激励,在UVM driver类中可以实现两种模式。
- 非流水线模型:如果driver一次仅对一个事务进行建模,则称为非流水线模型。 在这种情况下,sequence可以将一个事务发送给driver,并且driver可能需要几个周期(基于接口协议)才能完成驱动该事务。 只有在那之后,驱动程序才会接受sequencer的新事务.
class nonpipe_driver extends uvm_driver #(req_c);
task run_phase(uvm_phase phase);
req_c req;
forever begin
get_next_item(req); // Item from sequence via sequencer
// drive request to DUT which can take more clocks
// Sequence is blocked to send new items til then
item_done(); // ** Unblocks finish_item() in sequence
end
endtask: run_phase
endclass: nonpipe_driver
- 流水线模型:如果driver一次建模多个活动事务,则称为流水线模型。 在这种情况下,sequence可以继续向driver发送新事务,而无需等待driver完成之前的事务。 在这种情况下,对于从该sequence发送的每个事务,driver都会派生一个单独的进程来基于该事务驱动接口信号,不会等到它完成后再接受新事务。 如果我们要在接口上回送请求而不等待设计的响应,应该采用这种建模。
class pipeline_driver extends uvm_driver #(req_c);
task run_phase(uvm_phase phase);
req_c req;
forever begin
get_next_item(req); // Item from sequence via sequencer
fork begin //drive request to DUT which can take more clocks
//separate thread that doesn't block sequence
//driver can accept more items without waiting
end
join_none
item_done(); // ** Unblocks finish_item() in sequence
end
endtask: run_phase
endclass: pipeline_driver
[286] 如何确保在sequencer-driver上运行多个sequnce时,响应会从driver发送回正确的sequence?
如果从driver返回了几个序列之一的响应,则sequencer将sequence中的sequenceID字段用于将响应路由回正确的sequence。 driver中的响应处理代码应调用set_id_info(),以确保任何响应项都具有与其原始请求相同的sequenceID。 下面是driver中的一个示例代码,该代码获取sequencer_item的id并发送回响应(请注意,这是用于说明的参考伪代码,并且假定某些功能在其他地方进行了编码)
class my_driver extends uvm_driver;
//function that gets item from sequence port and
//drives response back
function drive_and_send_response();
forever begin
seq_item_port.get(req_item);
//function that takes req_item and drives pins
drive_req(req_item);
//create a new response
itemrsp_item = new();
//some function that monitors response signals from dut
rsp_item.data = m_vif.get_data();
//copy id from req back to response
rsp.set_id_info(req_item);
//write response on rsp port
rsp_port.write(rsp_item);
end
endfunction
endclass
[287] 什么是m_sequencer句柄?
启动sequence时,它始终与启动sequencer相关联。 m_sequencer句柄指向了当前sequence挂载的sequencer。 使用此句柄,序列可以访问UVM组件层次结构中的任何信息和其他资源句柄。
[288] m_sequencer和p_sequencer有什么区别?
UVM sequence是寿命有限的对象,与sequencer,driver或monitor不同,后者是UVM的组件,并且在整个仿真时间内都存在。 因此,如果需要从测试平台层次结构(组件层次结构)访问任何成员或句柄,sequence需要sequencer的句柄。 m_sequencer是uvm_sequencer_base类型的句柄,默认情况下在uvm_sequence中可用。 但是,要访问在其上运行sequence的真实sequencer,我们需要将m_sequencer转换为真实sequencer,通常称为p_sequencer(可以自定义为任何名字,不仅仅是p_sequencer)。 下面是一个简单的示例,其中sequence要访问clock monitor组件的句柄,该组件可在sequencer中用作句柄。
//clock monitor component which is available as a handle in the sequencer.
class test_sequence_c extends uvm_sequence;
test_sequencer_c p_sequencer;
clock_monitor_c my_clock_monitor;
task pre_body();
if(!$cast(p_sequencer, m_sequencer))begin
`uvm_fatal("Sequencer Type Mismatch:", " Wrong Sequencer");
end
my_clock_monitor = p_sequencer.clk_monitor;
endtask
endclass
class test_Sequencer_c extends uvm_sequencer;
clock_monitor_c clk_monitor;
endclass
[289] 生成sequence时,早期随机化和后期随机化有什么区别?
在早期随机化中,首先使用randomize()对sequence进行随机化,然后使用start_item()来请求对sequencer的访问,这是一个阻塞调用,根据sequencer的繁忙程度可能会花费一些时间。 下面的示例显示一个对象(req)首先被随机化,然后sequence等待仲裁。
task body()
assert(req.randomize());
start_item(req); //Can consume time based on sequencer arbitration
finish_item(req);
endtask
在后期随机化中,sequence首先调用start_item(),等待直到sequencer批准仲裁,然后在将事务发送给sequencer/driver之前,调用randomize。 这样做的好处是,可以将item及时地随机化,并且可以在将item发送给driver之前使用来自设计或其他组件的任何反馈。 以下代码中使用的就是后期随机化(req)
task body()
start_item(req); //Can consume time based on sequencer arbitration
assert(req.randomize());
finish_item(req);
endtask
[290] 什么是subsequence?
subsequence是从另一个sequence开始的sequence。 从sequence的body()中,如果调用了另一个sequence的start(),则通常将其称为subsequence。
[291] UVM driver中的get_next_item()和try_next_item()有什么不同?
get_next_item是一个阻塞方法(driver-sequencer API的一部分),阻塞直到sequence_item可供driver处理为止,并返回指向sequence_item的指针。 try_next_item是非阻塞版本,如果没有sequence_item可用于driver处理,则它将返回空指针。
[292] UVM driver中的get_next_item()和get()有什么不同?
get_next_item是一个阻塞调用,用于从sequencer FIFO获取sequence_item以供driver处理。 driver处理完sequence_item后,需要先使用item_done完成握手,然后再使用get_next_item()请求新的sequence_item。
get()也是一个阻塞调用,它从sequencer FIFO获取sequence_item以供driver处理。 但是,在使用get()时,由于get()方法隐式完成了握手,因此无需显式调用item_done()。
[294] UVM driver中的peek()和get()有什么不同?
driver的get()方法是一个阻塞调用,从sequencer FIFO获取sequence_item以供driver处理。 一旦有sequence_item可用,它就会解锁,并与sequencer完成握手。 peek()方法类似于get(),并阻塞直到sequence_item可用为止。 但是,它不会从sequencer FIFO中删除sequence。 因此,多次调用peek()将在driver中返回相同的sequence_item。
[295] 带有和不带有参数调用时,driver-sequencer API的item_done()方法有什么区别?
item_done()方法是driver中的一种非阻塞方法,用于在get_next_item()或try_next_item()成功之后与sequencer完成握手。 如果不需要发回响应,则不带参数调用item_done(),它将完成握手,而无需在sequencer响应FIFO中放置任何内容。 如果希望将响应发送回去,则将item_done()与指向响应sequence_item的句柄作为参数一起传递。 该响应句柄将放置在sequencer响应FIFO中,sequence通过这种方式进行响应。
[296] 下面哪些方法是阻塞的,哪些是非阻塞的?
- get()
- get_next_item()
- item_done()
- put()
- try_next_item()
- peek()
get(), get_next_item(), peek() 是阻塞的
try_next_item(), item_done(), and put() 是非阻塞的
[297] UVM driver中,下面哪些代码是错误的?
1)
function get_drive_req();
forever begin
req = get();
req = get();
end
endfunction
2)
function get_drive_req();
forever begin
req = get_next_item();
req = get_next_item();
item_done();
end
endfunction
3)
function get_drive_req();
forever begin
req = peek();
req = peek();
item_done();
req = get();
end
endfunction
2是错的,因为不能在调用item_done之前两次调用get_next_item,它无法完成与sequencer的握手。
[298] 如何停止sequencer上的所有sequence?
sequencer具有stop_sequences()方法,可用于停止所有sequence。 但是,此方法不检查driver当前是否正在处理任何sequence_items。 因此,如果driver调用item_done()或put(),则可能会出现致命错误,因为sequence指针可能无效。 因此,用户需要注意,一旦调用stop_sequence(),就禁用了sequencer线程(如果在fork中启动)。
[299] 用户调用sequence.print()方法时,将调用sequence中的哪个方法?
convert2string():建议实现此函数,该函数返回对象的字符串表示形式(其数据成员的值)。 这对于将调试信息打印到模拟器脚本或日志文件很有用。
[300] 找出UVM sequence的以下代码部分中的所有潜在问题
task body();
seq_item_c req;
start_item(req);
#10 ns;
assert(req.randomize());
finish_item(req);
endtask
应该避免在start_item和finish_item之间添加延迟。 start_item返回后,该sequence将赢得仲裁并可以访问driver-sequencer。 从那时起直到finish_item的任何延迟都将阻塞driver-sequencer,并且使得任何其他sequence都不能访问driver-sequencer。 如果在一个接口上运行多个sequence,并且延迟很大,设计接口上有很多空闲时,这会造成很大的麻烦。
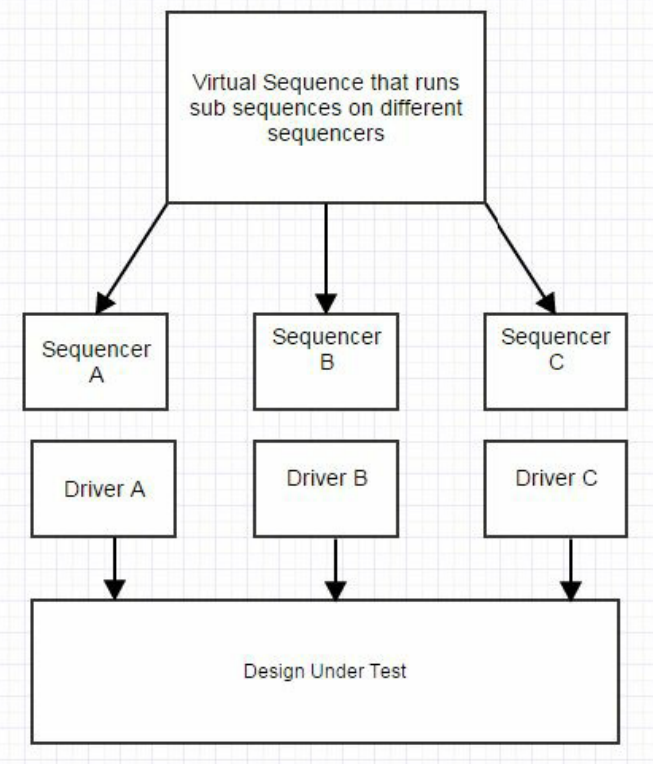
[301] 什么是virtual sequence?如何使用virtual sequence?为什么要使用virtual sequence?
virtual sequence是控制多个sequencer中激励生成的序列。 由于sequence,sequencer和driver集中在单个接口上,因此几乎所有测试平台都需要virtual sequence来协调不同接口之间的激励和交互。 virtual sequence在子系统或系统级别的测试台上也很有用,可以使单元级别的sequence以协调的方式运行。 下图从概念上展示了这一点,其中virtual sequence具有三个sequencer的句柄,这些sequencer连接到driver,以连接到DUT的三个独立接口。 然后,virtual sequence可以在每个接口上生成subsequence,并在相应的subsequencer上运行它们。
[302] 如下所示,给定一个简单的单端口RAM,它可以读取或写入,请shiyong1UVM编写一个sequence和driver以测试他的读取和写入。 假设read_enable = 1表示读取,而write_enable = 1表示写入。 读或写操作只能在一个周期内发生。
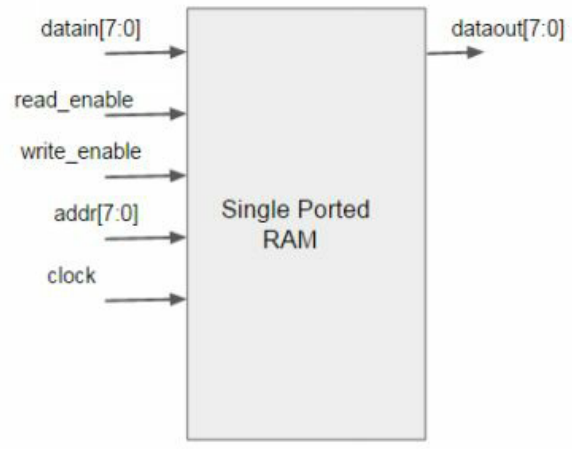
要实现UVM driver和sequence,我们需要先定义sequence item类,然后sequence和driver类才能将其用作事务进行通信。 以下是sequence item,sequence和driver类的示例代码。 可以使用类似的方法使用UVM处理任何编程代码。
- sequence item是用于sequence和driver之间通信的事务。 应该抽象出最终需要在DUT上进行信号驱动的所有信息。
class rw_txn extends uvm_sequence_item;
rand bit[7:0] addr; //address of transaction
typedef enum {READ, WRITE} kind_e; //read or write type
rand kind_e sram_cmd;
rand bit[7:0] datain; //data
//Register with factory for dynamic creation
`uvm_object_utils(rw_txn)
//constructor
function new (string name = "rw_txn");
super.new(name);
endfunction
//Print utility
function string convert2string();
return $psprintf("sram_cmd=%s addr=%0h datain=%0h,sram_cmd.name(),addr,datain);
endfunction
endclass
- 生成上述类型的10个事务并发送给driver的sequence:
class sram_sequence extends uvm_sequence#(rw_txn) ; //Register with factory
`uvm_object_utils(sram_sequence)
function new(string name ="sram_sequence");
super.new(name);
endfunction
//Main Body method that gets executed once sequence is started
task body();
rw_txn rw_trans; //Create 10 random SRAM read/write transaction and send to driver
repeat(10) begin
rw_trans = rw_txn::type_id::create(.name("rw_trans"),.contxt(get_full_name()));
start_item(rw_trans); //start arbitration to sequence
assert (rw_trans.randomize());//randomize item
finish_item(rw_trans); //send to driver
end
endtask
endclass
- driver代码,从sequence中接收上述事务并根据SRAM协议进行驱动。
class sram_driver extends uvm_driver#(rw_txn);
`uvm_component_utils(sram_driver)
virtual sram_if vif; //Interface that groups dut signals
function new(string name,uvm_component parent = null);
super.new(name,parent);
endfunction
//Build Phase
//Get the virtual interface handle from config_db
function void build_phase(uvm_phase phase);
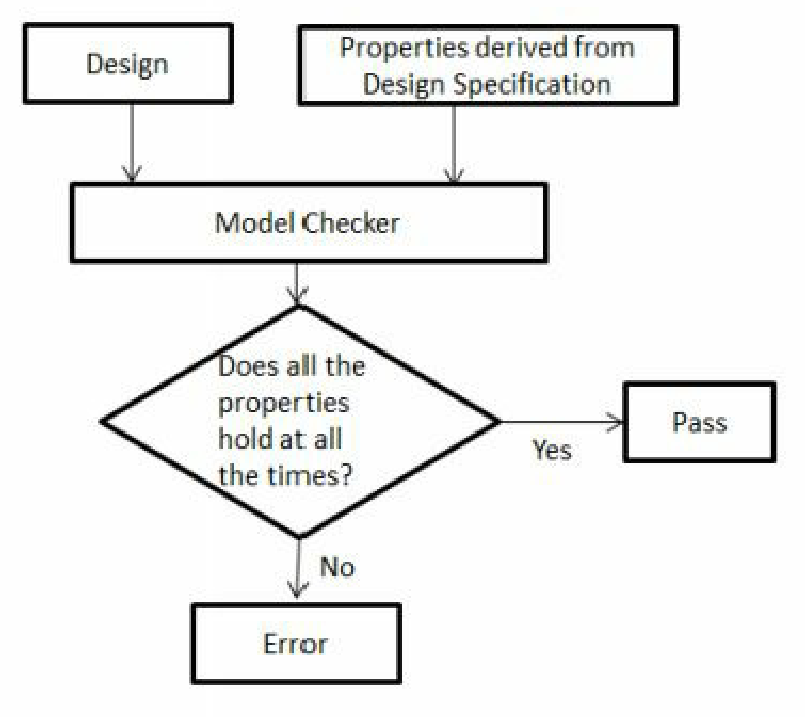
super.build_phase(phase);
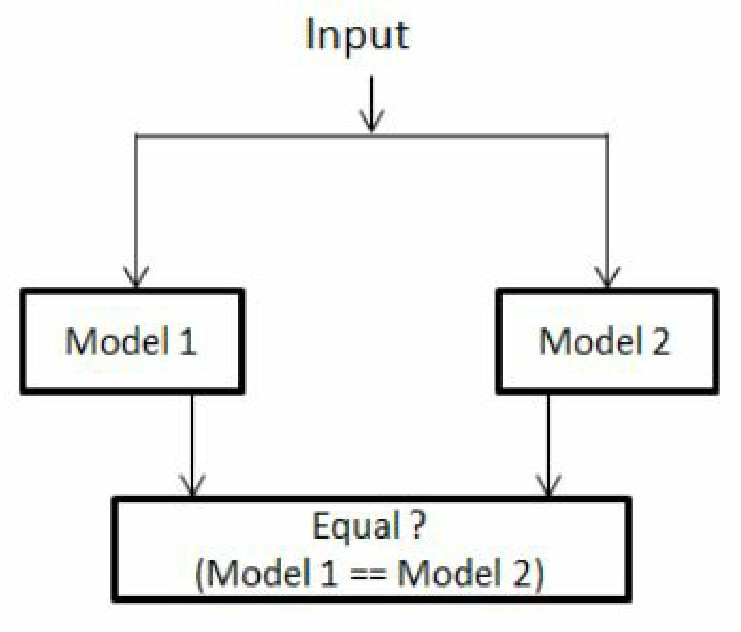
if (!uvm_config_db#(virtual sram_if)::get(this, "", "sram_if", vif))
begin
`uvm_fatal("SRAM/DRV", "No virtual interface specified")
end
endfunction
//Run Phase
//Implement the Driver-Sequencer API to get an item
//Based on if it is Read/Write - drive on SRAM interface the corresponding pins virtual
task run_phase(uvm_phase phase);
super.run_phase(phase);
this.vif.read_enable <= '0;
this.vif.write_enable <= '0;
forever begin
rw_txn tr;
@ (this.vif.master_cb);
//First get an item from sequencer
seq_item_port.get_next_item(tr);
@ (this.vif.master_cb); //wait for a clock edge
uvm_report_info("SRAM_DRIVER ", $psprintf("Got Transaction%s",tr.convert2string()));
//Decode the SRAM Command and call either the read/write function
case (tr.sram_cmd)
rw_txn::READ: drive_read(tr.addr, tr.dataout);
rw_txn::WRITE: drive_write(tr.addr, tr.datain);
endcase
//Handshake DONE back to sequencer
seq_item_port.item_done();
end
endtask: run_phase
//Drive the SRAM signals needed for a Read
virtual protected task drive_read(input bit [31:0] addr, output logic [31:0] data);
this.vif.master_cb.addr <= addr;
this.vif.master_cb.write_enable <= '0;
this.vif.master_cb.read_enable <= '1;
@ (this.vif.master_cb);
this.vif.master_cb.read_enable <= '0;
data = this.vif.master_cb.dataout;
endtask: drive_read
//Drive the SRAM signals needed for a Write
virtual protected task drive_write(input bit [31:0] addr, input bit [31:0] data);
this.vif.master_cb.addr <= addr;
this.vif.master_cb.write_enable <= '1;
this.vif.master_cb.read_enable <= '0;
@ (this.vif.master_cb);
this.vif.master_cb.write_enable <= '0;
endtask: drive_write
endclass
[303] 什么是工厂?
UVM中的“工厂”是一个特殊的查找表,其中记录了所有UVM组件和事务。 在UVM中创建组件和事务对象的推荐方法是使用工厂方法create()。 使用工厂创建对象可以很方便地实现类型覆盖,而不必更改验证环境的结构或修改验证环境的代码。
[304] 使用new()和create()创建对象有什么区别?
UVM中用于创建组件或事务对象的推荐方法是使用内置方法::type_id::create(),而不是直接调用构造函数new()。
create方法在内部调用工厂,查找所请求的类型,然后调用构造函数new()来创建对象。 这样可以轻松地重写类型,可以指定类的类型(基类,一个或派生类),并且所有其他测试平台组件将能够创建该类类型的对象而无需任何代码更改。
new()构造函数将仅创建给定类型的对象,因此使用new()将不允许在运行时更改类类型。 因此,使用new()意味着测试平台代码将需要根据要使用的不同类型进行更改。
[305] 如何在工厂中注册uvm_component类和uvm_sequence类?
使用uvm_object_utils()宏注册uvm_sequence类,uvm_component_utils()宏注册uvm_component类,下面是示例代码
class test_seq_c extends uvm_sequence;
`uvm_object_utils(test_seq_c)
class test_driver_c extends uvm_component;
`uvm_component_utils(test_driver_c)
[306] 为什么要将类注册到工厂?
工厂是UVM中使用的一种特殊查找表,用于创建组件或事务类型的对象。 使用工厂创建对象的好处是,测试平台构建可以在运行时决定创建哪种类型的对象。 因此,一个类可以用另一个派生类替换,而无需任何实际代码更改。 为确保此功能,建议所有类都在工厂注册。 如果不注册到工厂,则将无法使用工厂方法::type_id::create()构造对象。
[307] 工厂覆盖(override)的意思是?
UVM工厂允许在构造时将一个类替换为另一个派生类。 通过将一个类替换为另一个类而不需要编辑或重新编译测试平台代码,这对于控制测试平台的行为很有用。
[308] 工厂的实例覆盖(instance override)和类型覆盖(type override)有什么区别?
类型覆盖意味着每次在测试平台层次结构中创建组件类类型时,都会在其位置创建替代类型。 这适用于该组件类型的所有实例。
另一方面,实例覆盖意味着仅覆盖组件类的特定实例。 组件的特定实例由该组件在UVM组件层次结构中的位置进行索引。
由于只有UVM组件类可以在UVM测试平台中具有层次结构,因此实例覆盖只能作用于组件类,而sequence(或者说object)只能覆盖类型。
[309] 实例覆盖和类型覆盖都可以作用于UVM_component和transaction吗?
不,只有UVM_component类是UVM测试平台层次结构的一部分,从而可以使用实例覆盖。 sequence_item或sequence不是UVM测试平台层次结构的一部分,因此只能使用类型覆盖来覆盖,类型覆盖将覆盖该类型的所有对象。
[310] uvm_obejction是什么?在哪里使用它们?
uvm_objection类提供了一种在多个组件和sequence之间共享计数器的方法。 每个组件/sequence可以异步地"raise"和"drop" objections,这会增加或减少计数器值。 当计数器达到零(从非零值开始)时,将发生"all dropped"情况。
objection机制最常用于UVM phase机制中,以协调每个run_time phase的结束。 在phase中启动的用户进程会首先raise objections,并在进程完成后drop objections。 当一个phase中的所有进程都放下objections时,该phase的objections计数器清零。 这种“all dropped”的情况说明每个进程都同意结束该phase。
下面是一个示例,说明如何在sequencer(my_sequencer)上启动sequence(my_test_sequence)并在sequence执行后drop objections
task run_phase( uvm_phase phase);
phase.raise_objection( this );
my_test_sequence.start(my_sequencer);
phase.drop_objection( this );
endtask
[311] 如何在UVM中实现仿真超时机制?
如果由于超出最大时间的某些错误而导致测试无法进行,那么仿真超时机制有助于停止仿真。 在UVM中,set_global_timeout(timeout)是一个便捷函数,用于将uvm_top.phase_timeout变量设置为超时值。 如果run()阶段在该这个时间内之前没有结束,则仿真将停止并报告错误。
在顶层模块中调用此函数,该模块会按以下方式启动测试
module test;
initial begin
set_global_timeout(1000ns);
end
initial begin
run_test();
end
endmodule
[312] uvm中的phase机制是什么意思?
与基于module的测试平台(所有module静态地存在于层次结构中)不同,基于类的测试平台需要管理不同对象的创建以及这些对象中各种task和function的执行。 phase是基于类的测试平台中重要的概念,它具有一致的测试平台执行流程。 从概念上讲,测试执行可以分为以下阶段-配置,创建测试平台组件,运行时激励和测试结束。 UVM为每一个阶段中定义了标准phase。
[313] uvm_component有哪些phase?UVM的run_phase有哪些子phase?
UVM使用标准phase来排序仿真过程中发生的主要步骤。 有三组阶段,按以下顺序执行。
-
Build phases-在Build phases; 测试平台将会被配置和构建。 它具有以下子phase,这些子phase都在uvm_component基类中作为虚方法实现。
- build_phase()
- connect_phase()
- end_of_elaboration()
-
Run time phases-这些phase会消耗时间,这是大多数测试执行的地方。
- start_of_simulation()
- run_phase(),run_phase()进一步分为以下12个子phase:
- pre_reset
- reset
- post_reset
- pre_configure
- configure
- post_configure
- pre_main
- main
- post_main
- pre_shutdown
- shutdown
- post_shutdown
-
Clean up phase -此phase 在测试结束后执行,用于收集并报告测试的结果和统计信息。 包括以下子phase :
- extract()
- check()
- report()
- final()
[314] 为什么build_phase是自顶向下执行的?
在UVM中,所有组件(例如test,Env,Agent,Driver,Sequencer)都基于uvm_component类,并且组件始终具有层次结构。 build_phase()方法是uvm_component类的一部分,用于从父组件构造所有子组件。 因此,要构建测试平台层次结构,始终需要先拥有一个父对象,然后才能构造其子对象,并可以使用build_phase进一步构造其子对象。 因此,build_phase()总是自顶向下执行。
例如:uvm_test类调用build_phase,构造该test的所有uvm_env组件,而每个uvm_env类的build_phase()应该构造属于该uvm_env的所有uvm_agent组件,然后继续。 对于所有其他phase,调用顺序实际上并不重要。 所有组件的run_phase()是并行运行的。
[315] uvm_component中的phase_ready_to_end()的作用是?
phase_ready_to_end(uvm_phase phase)是组件类的回调方法,当相应phase的所有objection均被放下并且该phase将要结束时,会调用该方法。 组件类可以使用此回调方法来定义phase即将结束时需要执行的任何功能。
例如,如果某个组件希望将phase结束延迟到某个条件,甚至在所有objections均被放下之后,也可以使用此回调方法来完成。
再比如,如果一个激励或应答sequence正在运行,在主sequence结束之前,则可以使用main_phase()中的phase_ready_to_end()回调方法来停止那些激励或应答sequence。
[316] 什么是uvm_config_db?它的作用是?
uvm_config_db机制支持在不同的测试平台组件之间共享配置和参数。 用名为uvm_config_db的配置数据库启用该功能。 任何测试台组件都可以使用变量,参数,对象句柄等填充配置数据库。
其他测试平台组件可以从配置数据库访问这些变量,参数,对象句柄,而无需真正知道其在层次结构中的位置。
例如,顶层测试平台模块可以通过uvm_config_db储存虚接口句柄。 然后,任何uvm_driver或uvm_monitor组件都可以查询uvm_config_db获取此虚接口的句柄,并将其用于通过接口实际访问信号。
[317] 如何使用uvm_config_db的get()和set()方法?
get()和set()是用于从uvm_config_db存储或检索信息的主要方法。任何验证组件都可以使用set()方法为config_db存储一些配置信息,还可以控制哪些其他组件对相同信息具有可见性。可以将其设置为具有全局可见性,或者仅对一个或多个特定测试平台组件可见。 get()函数从数据库中检查与参数匹配的共享配置。
get()和set()方法的语法如下:
uvm_config_db#(<type>)::set(uvm_component context, string inst_name, string field_name,<type> value)
uvm_config_db#(<type>)::get(uvm_component context, string inst_name, string field_name, ref value)
context指定从中调用get / set的当前类或组件。 inst_name是从中调用get / set的组件实例的名称。 field_name是在config_db中设置/获取的对象或参数或变量的名称。 <type>标识config_db中设置/获取的配置信息的类型。对于对象句柄,type是类名,而对于其他变量,type是数据类型名,代表了该变量的类型。
[318] 在验证平台层次结构中较低的组件是否可以使用get / set config方法将句柄传递给较高层次结构中的组件?
建议不要在UVM中这么做。 通常,较高级别的组件使用句柄设置配置数据库,而较低级别的组件则使用get / set方法获取它们。
[319] 在UVM中,将虚接口分配给不同组件的最佳方法是什么?
实例化DUT和接口的顶级testbench模块在uvm_config_db中例化虚接口。 然后,测试类或UVM组件层次结构中的任何其他组件可以使用get()方法查询uvm_config_db,获得此虚接口的句柄并将其用于访问信号。
下面栈是了如何进行此操作。 为APB总线master实例化了DUT和物理接口,然后,将虚接口句柄设置到uvm_config_db。
module test;
logic pclk;
logic [31:0] paddr;
//Instantiate an APB bus master DUT
apb_master apb_master(.pclk(pclk),*);
//Instantiate a physical interface for APB interface
apb_if apb_if(.pclk(pclk), *);
initial begin //Pass this physical interface to test class top //which will further pass it down to env->agent->drv/sqr/mon
uvm_config_db#(virtual apb_if)::set(null, "uvm_test_top", "vif",apb_if);
end
endmodule
下面是APB Env类,该类使用uvm_config_db中的get()方法检索在顶层测试模块中设置的虚接口。
class apb_env extends uvm_env;
`uvm_component_utils(apb_env);
//ENV class will have agent as its sub component
apb_agent agt;
//virtual interface for APB interface
virtual apb_if vif; //Build phase - Construct agent and get virtual interface handle fromtest and pass it down to agent
function void build_phase(uvm_phase phase);
agt = apb_agent::type_id::create("agt", this);
if (!uvm_config_db#(virtual apb_if)::get(this, "", "vif", vif))begin
`uvm_fatal("config_db_err", "No virtual interface specified forthis env instance")
end
uvm_config_db#(virtual apb_if)::set( this, "agt", "vif", vif);
endfunction: build_phase
endclass : apb_env
[320] 在UVM中,如何结束仿真?
UVM具有phase机制,由一组构建阶段,运行阶段和检查阶段组成。 在run()阶段进行实际的测试仿真,并且在此phase中,每个组件都可以在开始时提出raise_objection和drop_objection。 一旦所有组件都drop_objection,则run_phase完成,然后所有组件的check_phase执行,然后测试结束。
这是正常仿真结束的方式,但是如果某些组件由于设计或测试平台中的错误而挂起,则仿真超时也可以终止run_phase。 当run_phase启动时,并行超时计时器也会启动。 如果在run_phase完成之前超时计时器达到指定的超时限制,则将发出一条错误消息,然后将执行run_phase之后的所有phase,最后测试结束。
[321] 什么是UVM RAL(UVM Register Abstraction Layer)?
UVM RAL(UVM Register Abstraction Layer)是UVM所支持的功能,有助于使用抽象寄存器模型来验证设计中的寄存器以及DUT的配置。 UVM寄存器模型提供了一种跟踪DUT寄存器内容的方法,以及一个用于访问DUT中寄存器和存储器的层次结构。 寄存器模型反映了寄存器spec的结构,能够作为硬件和软件工程师的共同参考。 RAL还具备其他功能,包括寄存器的前门和后门初始化以及内置的功能覆盖率支持。
[322] 什么是UVM Callback?
uvm_callback类是用于实现回调的基类,这些回调通常用于在不更改组件类的情况下修改或增强组件的行为。 通常,组件开发人员会定义一个专用于应用程序的回调类,该类扩展并定义一个或多个虚方法,称为回调接口。 这些方法用于实现组件类行为的重写。
一种常见用法是在driver将错误发送到DUT之前将错误注入到生成的数据包中。 以下伪代码展示了如何实现。
- 定义一个具有错误位的数据包类
- 定义一个从sequence中提取数据包,输入到DUT的driver类
- 定义从基类uvm_callback派生的driver回调类,并添加一个虚方法,该方法可用于注入错误或翻转数据包中的某个位。
- 用`uvm_register_cb()宏注册回调类
- 在接收和发送数据包到DUT的driver的run_phase()方法中,基于概率执行回调以导致数据包损坏
class Packet_c;
byte[4] src_addr, dst_addr;
byte[] data;
byte[4] crc;
endclass
//User defined callback class extended from base class
class PktDriver_Cb extends uvm_callback;
function new (string name = "PktDriver_Cb");
super.new(name);
endfunction
virtual task corrupt_packet (Packet_c pkt);
//Implement how to corrupt packet
//example - flip one bit of byte 0 in CRC
pkt.crc[0][0] = ~pkt.crc[0][0]
endtask
endclass : PktDriver_Cb
//Main Driver Class
class PktDriver extends uvm_component;
`uvm_component_utils(PktDriver)
//Register callback class with driver
`uvm_register_cb(PktDriver,PktDriver_Cb)
function new (string name, uvm_component parent=null);
super.new(name,parent);
endfunction
virtual task run();
forever begin
seq_item_port.get_next_item(pkt);
`uvm_do_callbacks(PktDriver,PktDriver_Cb, corrupt_packet(pkt))
//other code to derive to DUT etc
end
endtask
endclass
[323] 什么是uvm_root类?
uvm_root类充当所有UVM组件的隐式顶级和phase控制器。 用户不直接实例化uvm_root。 UVM会自动创建一个uvm_root实例,用户可以通过全局(uvm_pkg-scope)变量uvm_top访问该实例。
[324] uvm_test的父级类是什么?
uvm_test类是用户可以实现的顶级类,并且没有显式父类。 但是,UVM有一个称为uvm_top的特殊组件,它被指定为测试类的父级。
形式验证
[325] 什么是形式验证?
形式验证是使用数学建模来验证设计实现是否符合spec的方法。 形式验证使用数学推理和算法来证明设计符合spec。 在形式验证中,该工具隐式地涵盖了所有情况(输入和状态),而无需开发任何激励生成器或预期输出。 该工具需要以property或更高级别的模型形式对spec进行形式描述,以详尽地涵盖所有输入组合,证明功能的正确性。 SystemVerilog的property也可用于形式化描述spec。
[326] 形式验证是静态仿真还是动态仿真?
是静态仿真
[327] 形式验证有哪些方法?
- 模型检查
- 形式等效
[328] 解释模型检查
在“模型检查”方法中,将要验证的模型描述为从设计规范中提取的一组property。 因此要详尽搜索设计的状态空间,检查所有property是否在所有状态下均成立。 如果在任何状态下违反了property,则会引发错误。 下图是一个示意图:
[329] 什么是形式等效
形式等效用于验证两个具有相同或不同抽象的模型在功能上是否一致的方法。 此方法无法确定模型在功能上是否正确,但是可以确定两个模型在功能上是否相同。 常用于比较RTL设计和综合网表的功能。 它也可以用来检查两个RTL模型或两个门级模型的一致性。 下图是一个示意图:
[330] 列出一些可以使用形式等效的场景
- RTL设计与综合网表
- RTL设计与参考模型
- 两个RTL设计
- 两个门级模型
- 两个参考模型
[331] 与动态仿真相比,形式验证有什么优势?
- 动态仿真不可能进完全的验证,因为输入激励是使用生成器或testcase来实现的。 但是,形式验证会覆盖所有的状态空间,因为该工具会自动生成激励来验证所有的spec。
- 由于工具会自动生成完备的激励,因此无需自行生成激励。 用户可以专注于使用属性来映射形式spec。
- 无需生成预期的输出序列,并且在数学上保证了设计的正确性。
[332] 形式验证有什么局限性?
- 可拓展性是形式验证的最大限制之一。 形式验证仅限于较小的设计,因为即使添加一个触发器也会将设计状态空间增加2倍(这意味着每个触发器的输入场景都会加倍)。
- 它可以确保设计相对于spec的正确性。 它不能保证设计是否正常工作(例如spec本身是否有错误)。
- 对于模型检查,spec需要使用property来描述、编码
[333] 如果设计中的某个模块经过形式验证可以正常工作,我们是否还需要收集该模块的覆盖率?
不,我们不需要通过了形式验证的模块的覆盖率。 因为形式验证在数学上保证了可以在所有可能的输入条件下都符合spec。
功耗和时钟
[334] CMOS电路功耗由哪些部分组成?
- 动态功耗:这部分是由晶体管电容充放电产生的
- 静态功耗:这部分是由开关的漏电流产生的
[335] 什么是动态功耗?它与哪些参数有关?
动态功耗(\(P_D\))是容性负载功耗(\(P_{cap}\))与瞬态功耗(\(P_{Transient}\))的总和。 动态功耗(\(P_D\))与\(CV^2f\)成正比。
其中,
[336] 什么是静态功耗?它与哪些参数有关?
静态功耗是电路中没有开关活动时消耗的功耗。 它是漏电功耗。 例如:打开电路时,由于电流流动,电池开始漏电。
其中,\(V_{dd}\)是电源电压,\(I_{static}\)是流过器件的总电流。
[337] 什么是多电压域?为什么要使用它?
多电压域是一种低功耗技术,它在设计中使用多个电压域。 在此,它的目标是针对所需性能优化功耗。 电压越高,电路速度越快(性能越高),但功耗也越高(因为动态功耗(\(P_D\))与\(CV^2f\)成正比)。 在某些设计中,设计的只有几个部分可能需要以较高的频率运行,而其他部分可以较低的频率运行。 在这种情况下,给低频率部分提供低电压,从而减小功耗。
[338] 什么是“动态电压频率调节”(DVFS)?何时使用?
动态电压频率调节是一种低功耗设计技术,通过动态调整频率降低功耗。 在DVFS中,工作频率或电压以某种方式进行调节,使得设计在正常运行的同时使用最小的频率或电压。 这个过程发生在设计的运行过程中,因此称为“动态”。 传统的低功耗方法中,设计以工作频率运行,然后在空闲时关闭电源来进行定期调度。DVFS技术利用了CMOS芯片的特性:CMOS芯片的能量消耗正比于电压的平方和时钟频率。DVFS技术是以延长任务执行时间为代价来达到减少系统能量消耗的目的,体现了功耗与性能之间的权衡。可以通过减少时钟频率来降低通用处理器功耗的。然而,仅仅降低时钟频率并不节约能量,因为性能的降低会带来任务执行时间的增加。调节电压需要以相同的比例调节频率以满足信号传播延迟要求。然而不管是电压调节还是频率调节,都会造成系统性能的损失,并增加系统的响应延迟。
为了尽量减少可感知的系统性能负面影响同时又能最大程度地降低系统能耗,策略必须估计未来的工作负载并选择最合适的频率。准确地预测未来的工作负载对广泛使用的策略是至关重要的。预测错误可能会导致设置的频率太高降低节省能耗,或设置频率过低造成系统响应延迟过高。所以,要想降低功耗,需要选择合适的供电电压和时钟频率。
所以安全的调节机制是:
- 当需要提升功率时,应先提升供电电压,然后提升时钟频率。
- 当需要降低功率时,应先降低时钟频率,再降低供电电压。
制定调整策略前,需要先找出系统中的耗电大的部件,如CPU、GPU、DSP等硬件算法加速模块(结合逻辑规模);然后统计出这些模块的负载情况,基本的策略当然是工作负载增加则升频升压,工作负载降低则降频降压。工作负载的粗略模型是在一个时间窗口内,统计模块工作的时间长度,设定不同阈值,高阈值对应高电压高频率,低阈值对应低电压低频率。每次统计值穿过阈值边界,触发DVFS转换。
[339] 什么是UPF?
其主要是由Synopsys推出的专门用于描述电路电源功耗意图的一种语言标准,它是Tcl语言的扩展,并且现在已经成为IEEE-1801标准且被三大EDA厂商(Synopsys、Cadence、Mentor)支持。 传统的数字芯片设计均是采用Verilog或者VHDL语言对电路进行描述,但是这种方式描述出的电路并没有包含任何的芯片的供电网络信息,这会导致后续的流程如功耗验证和后端实现很难处理或者极易出错。UPF标准正好可以很好的解决这个问题,因为UPF标准本身包含了大量的用于描述电源网络的Tcl命令,直接使用这些命令可以很方便的创建电源域和功耗控制的特殊单元等,用UPF编写的统一功耗格式文件不仅可以在RTL级,同时还可以被后端工具使用,这在一定意义上保证了整个芯片设计过程中功耗流程的一致性,在后端工具进行处理之后也会生成相应的UPF文件,此时前端工具可以使用该UPF文件对网表进行Power仿真分析
[340] 什么是Power Aware Simulation,它的重要性体现在什么地方?
Power Aware Simulation意味着在RTL或GLS级别上对Power Down和Power Up行为进行建模。Power Aware Simulation的重要性体现在:
- 在设计周期的早期就必须找到与电源相关的RTL / Spec的错误。 与电源有关的严重错误可能导致芯片无法正常工作。
- 电源管理至关重要,现代的ASIC / SoC设计都具有为电源管理而专门的重要逻辑。##
[341] 电源域的意思是?
电源域是共享一个主要电源的设计元素的集合,根据通用电源策略(例如工作电压,电源网络,上电/断电条件等)进行分组。
[342] 什么是亚稳态?亚稳态是如何产生的?它有什么影响?
亚稳态是一种电路状态,在电路正常工作所需的时间内,电路无法稳定在的“ 0”或“ 1”逻辑电平的状态。 通常在建立时间和保持时间违例时发生。
亚稳态可能会导致:
- 不可预测的系统行为。
- 不同的扇出可能得到不同的信号值,从而导致设计进入未知状态。
- 如果不稳定的数据(“ 0”或“ 1”)传播到设计中的不同部分,则可能导致高电流并最终芯片烧坏。
[343] 如何避免亚稳态?
通过在设计中使用同步器,可以避免跨时钟域时的亚稳态。同步器让信号有足够的时间从不稳定的振荡(“ 0”和“ 1”)稳定下来,从而获得稳定的输出。对于跨时钟域时可能出现的亚稳态,还可以使用包括握手机制、异步FIFO等方法。对于同步电路中,要进行合理的设计与设计约束,避免建立时间和保持时间违例。
[344] 同步器的构成是怎样的?
以下是一个同步器电路的例子。 这是一个两个触发器同步器,第一个触发器等待一个时钟周期,使输入端的亚稳态稳定下来/逐渐消失,然后第二个触发器在输出端提供稳定的信号。
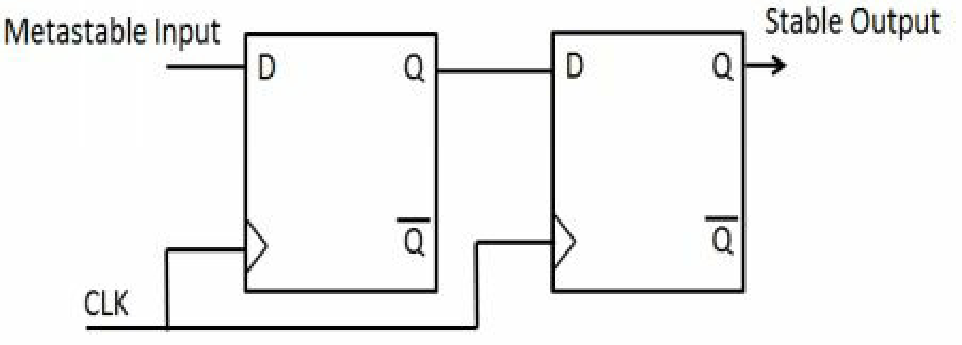
值得注意的是,在信号输入第二级时,第一触发器的输出仍然可能不稳定(并导致第二级输出信号变为亚稳态)。 在这种情况下,我们可以使用三个触发器同步器电路。 但是,通常两个触发器同步器电路足以消除亚稳态,使用三个触发器的情况比较少。
[345] 什么是时钟门控?
时钟门控是一种低功耗技术,通过关闭了设计中某些部分的时钟达到降低功耗的目的。 它是一种被用于控制时钟网络耗散功率的技术,通过避免不必要的开关活动,减少设计消耗的动态功耗。
[346] 什么是电源门控,为什么要使用它?
电源门控是一种低功耗,可以关闭设计中不工作的部分。 当不工作时,电源门控可关闭电源,减少漏电功耗,从而降低了功耗。 时钟门控有助于降低动态功耗,而时钟门控有助于降低静态功耗。
[347] 多时钟域设计会遇到哪些问题?
- 亚稳性导致的同步失败:时钟在不同的时钟域中以不同的频率运行,并且在一个时钟域中生成的信号在非常接近第二个时钟域中时钟有效沿的位置采样时,输出可能进入亚稳态状态,在设计中出现同步失败。
- 数据不一致:如果设计不合理,目标时钟域可能会接收错误的数据。 例如:如果多个信号从一个时钟域传输到另一个时钟域,所有这些信号同时变化,并且源和目标时钟沿彼此接近,那么这些信号中的某些可能会在一个时钟中捕获,而有一些信号可能在另一个时钟周期中被捕获,从而导致数据不一致。 注意:这只是数据不一致的一个例子, 数据不一致的产生还有很多原因。
- 数据丢失:如果设计不合理,则数据可能会在CDC边界丢失。 例如:如果信号从较快的时钟域送到较慢的时钟域,并且该信号的宽度仅等于一个时钟周期(较快的时钟),则可能会丢失以下信息: 信号在较慢的时钟域中的采样沿前就变化了。 注意:这只是数据丢失的一个例子, 数据丢失的产生还有很多原因。
[348] 如何处理跨时钟域信号?
跨时钟域处理有很多方法,具体取决于我们需要在不同的时钟域之间传递1位还是多位。 假设以下情况:多个信号从一个时钟域传输到另一时钟域,所有信号同时变化,并且源和目标活动时钟沿彼此接近。 在这种情况下,这些信号中的某些信号可能在目标时钟域的一个时钟周期中被捕获,而另一些信号在目标时钟域中的另一个时钟周期中被捕获,从而导致数据不一致性。 可以使用下面方法在两个时钟域之间同步信号。
对于单bit跨时钟域:
- 两级或者三级同步器
- 使用握手信号进行同步
对于多bit跨时钟域:
- 使用多周期路径的方法进行同步,将未经同步的信号和同步控制信号一起发射到目标时钟域
- 对信号进行格雷码编码,由于相邻的格雷码计数只会变化1bit,亚稳态的发生会大大减小
- 使用异步FIFO
- 将多比特信号合并成1bit,然后再通过多级同步器进行传输
[349] 举例信号从快时钟域到慢时钟域可能发生的问题
信号只持续一个时钟周期(快时钟域),可能导致慢时钟域漏采样。
[350] 异步复位的优缺点有哪些?
优点:
- 异步复位具有最高优先级。
- 保证数据路径干净。
- 在有或没有时钟信号的情况下都能生效。
缺点:
- 如果在时钟的有效沿(或附近)撤销异步复位,则触发器的输出可能进入亚稳态。
- 它对毛刺很敏感,可能导致虚假的复位。
[351] 同步复位的优缺点有哪些?
优点:
- 整个电路都是同步的
- 更加容易仿真
- 综合以后可能会更加节省面积
缺点
- 需要脉冲扩展,让复位脉冲足够长,保证能够正确地被采样
- 会添加额外的组合逻辑
- 同步复位需要时钟才能复位。 如果电路具有内部三态总线,则需要单独的异步复位,以防止内部三态总线上的总线冲突。
[352] 什么是Reset Recovery Time? 它和复位有什么关系?
复位恢复时间(Reset Recovery Time)是复位解除和时钟信号有效沿之间的时间。 如果发生复位解除,并且在非常小的时间窗口内,如果时钟信号边沿来临,则可能导致亚稳态。 这是因为复位解除置位后所有信号将不满足下一个触发器输入的时序条件。
[353] 什么是频率合成器? 举一个频率合成器的例子?
频率合成器是一种可以从单个稳定参考频率生成新频率的电路。 例如:为了从参考100 MHz时钟信号生成200MHz时钟信号,PLL通常用作频率合成器。
[354] 什么是PLL?
PLL全称是“Phase Locked Loop,锁相环”。 简而言之,它是一种反馈电路(准确地说是控制系统),用于生成输出信号,该输出信号的相位与输入信号的相位有关。 它用于相位/频率调制和解调,还可以用作频率合成器。 PLL由三个功能块组成:
- 鉴相器
- 环路滤波器
- 压控振荡器
[355] 画出PLL的框图
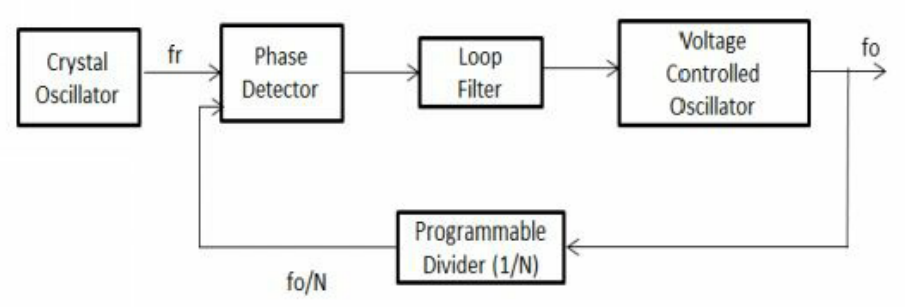
这里\(fr\)是参考频率,\(fo\)是输出频率,这样\(fr = fo / N\),这意味着\(fo = N * fr\)
覆盖率
[356] 代码覆盖率与功能覆盖率的区别是什么?
-
代码覆盖率:代码覆盖率是一种度量,用于度量给定测试case对设计代码(HDL模型)进行测试的程度。 启用后,模仿真器会自动提取代码覆盖率。
-
功能覆盖率:功能覆盖率是用户定义的度量标准,用于度量已执行了多少spec(如测试计划中的功能所列举的)。 它可以用来衡量对于spec的测试充分性。 它是用户定义的,不会自动生成。 它也不依赖于设计代码,因为它是根据spec实现的
[357] 代码覆盖率有哪几种?
- Statement/Line coverage:用于衡量在仿真测试期间测试了多少条语句(行)。 一般行覆盖率的目标是100%。 在下面的代码中,有4行或语句将在Statement/Line coverage中进行收集。
always @ (posedge clk) begin
if( A > B) begin //Line 1
Result = A - B; //Line 2
end else begin //Line 3
Result = A + B; //Line 4
end
end
- Block coverage:在begin-end或if else或case语句之间或while循环或for循环之间的一组语句称为块。 块覆盖率衡量的是在仿真过程中是否覆盖了这些类型的块码。 块覆盖范围看起来类似于语句覆盖范围,不同之处在于块覆盖率包含了一组语句。 在下面的的示例代码中,有三个代码块
always @ (posedge clk) begin //always block
if( A > B) begin // if block
Result = A - B;
end else begin // else block
Result = A + B;
end
end
-
Branch/Decision coverage:分支覆盖率评估HDL代码中的条件,例如if-else,case语句和三元运算符(?:)语句,并检测是否同时包含真假情况。 在上面的示例中,只有一个分支(if A> B),分支覆盖率会检查是否真假两个分支都被触发了。
-
Conditional Coverage and Expression coverage:条件覆盖率会检查HDL中的所有布尔表达式,并计算该表达式为真或假的次数。 表达式覆盖率检查语句的右侧,统计所有可能组成的真值表的覆盖程度。 以下是包含3个布尔变量的表达式,它们决定了Result变量为true或false
Result = (A && B) || (C)针对A,B和C的所有可能情况,如下创建真值表。 条件覆盖率可以衡量此真值表的所有行是否都被覆盖。
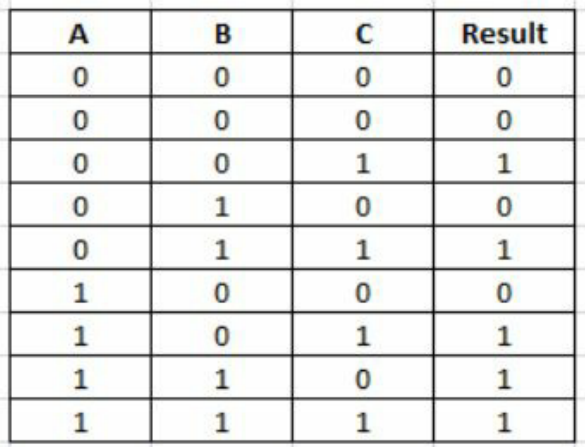
- Toggle coverage:翻转覆盖率可衡量仿真运行期间设计中信号和端口的翻转率。 这有助于识别哪些信号一直没有翻转。
- FSM coverage:状态机覆盖衡量仿真期间是否所有状态机的状态都被覆盖到。
[358] 如果功能覆盖率接近100%而代码覆盖率不足60%,说明了什么?
仿真器会基于testcase提取代码覆盖率,而功能覆盖率则是用户定义的指标。低代码覆盖率表明并非设计代码的所有部分都经过了测试。高功能覆盖率表明,用户从测试计划中捕获的所有功能都得到了测试。如果覆盖率指标显示低代码覆盖率和高功能覆盖率,原因可能是:
- 可能有许多设计代码未按照spec用于实现的功能。 (无效的代码)
- 用户定义的功能覆盖率量中存在一些错误。测试计划未捕获所有设计功能/场景/边界,或者缺少功能覆盖率监视器。代码覆盖率中未覆盖的设计代码可能会映射到这些功能上。
- 在实现功能覆盖率监视器时可能存在潜在的错误,导致它们收集了错误的覆盖率。因此,在验证项目中,对用户定义的功能覆盖率指标及其实现进行适当的检查很重要。
[359] 如果代码覆盖率接近100%而功能覆盖率不足60%,说明了什么?
- 没有按照spec在设计中实现了所有功能。 因此,设计代码无法实现所有功能
- 在功能覆盖率监视器中可能存在潜在的错误,即使设计代码实现了功能,也无法覆盖它们。
- 功能正确,但是由于发送的激励不正确,对应的功能覆盖率无法收集。
[360] 覆盖组可以在类内部定义和使用吗??
是的,可以在类内部定义覆盖组。 这对于基于测试平台结构(例如事务,序列,检查器,监视器等)实现功能覆盖率非常有用。
[361] 什么是covergroups和bins?
覆盖点(coverpoint)是用于指定需要收集覆盖率的目标。 Covergroup可以具有多个覆盖点以覆盖不同的表达式或变量。 每个覆盖点还包括一组bin,这些bin是该覆盖点不同采样值。 bin可以由用户定义,也可以缺省自动创建。 在下面的示例中,有两个变量a和b,covergroup有两个coverpoint,他们会检查a和b的值。 Coverpoint cp_a是用户定义的,bins values_a检测a是否覆盖到特定的值。 Coverpoint cp_b是自动的,bin是自动生成的,会检测b是否覆盖到所有的可能性
bit [2:0] a;
bit [3:0] b;
covergroup cg @(posedge clk);
cp_a coverpoint a {
bins values_a = { [0,1,3,5,7 };
}
cp_b coverpoint b;
endgroup
[362] 下面的例子中coverpiont cp_a创建了多少个bin?
bit[3:0] var_a;
covergroup test_cg @(posedge clk);
cp_a : coverpoint var_a {
bins low_bins[] = {[0:3]};
bins med_bins = {[4:12]};
}
endgroup
lowbins[]创建了四个bin,对应检查是否覆盖到0,1,2,3,med_bins创建里一个仓,检查是否覆盖到4-12之间的值。因此,一共创建了5个仓
[363] ignore bins 和 illegal bins的区别是什么?
ignore_bins用于指定与覆盖点关联的一组值或者翻转行为,这些值或者翻转行为可以明确从覆盖范围中排除。 例如,以下将忽略变量a的所有采样值7和8。
coverpoint a {
ignore_bins ignore_vals = {7,8};
}
illegal_bins用于指定与覆盖点关联的一组值或者翻转行为,这些值或者翻转行为被标记为非法。 例如,以下会将所有1、2、3采样值标记为非法。
covergroup cg3;
coverpoint b {
illegal_bins bad_vals = {1,2,3};
}
endgroup
当采样到illegal_bins时,仿真会报错,并且illegal_bins的优先级高于其他bin,即使其他bin和illegal_bins的范围有重叠,也会导致报错。
[364] 如何编译一个coverpoint来覆盖一个翻转行为?
翻转覆盖率指定为“ value1 => value2”,其中value1和value2是在两个连续采样点上的表达式的采样值。 例如,在coverpoint之下,在clk的三个连续正边缘中寻找变量v_a的值4、5和6的翻转行为。
covergroup cg @(posedge clk);
coverpoint v_a {
bins sa = (4 => 5 => 6),
}
endgroup
[365] 下面的语句覆盖了什么样的翻转行为?
coverpoint my_variable {
bins trans_bin[] = ( a,b,c => x, y);
}
a=>x, a=>y, b=>x, b=>y, c=>x, c=>y
[366] 下面的bin覆盖了哪些范围?
covergroup test_cg @(posedge clk);
coverpoint var_a {
bin hit_bin = { 3[*4]};
}
endgroup
[* N]指的是连续的重复操作。 因此,上面的bin覆盖的是连续4次采样都是3的翻转覆盖率
[367] 什么是wildcard bins?
wildcard bins可以让bin在定义时使用x、z和?作为0或者1的通配符。下面的例子中,并不关心低两位是多少,只要高两位为11就在覆盖范围内。
coverpoint a[3:0] {
wildcard bins bin_12_to_15 = { 4'b11?? };
}
[368] 什么是cross coverage?何时使用它?
coverage可以指定两个或多个coverpoint或变量之间的cross coverage。 cross coverage使用cross进行指定的。交叉覆盖率的仓数,等于交叉目标仓数的乘积,因为要覆盖到两者的所有可能组合。
bit [31:0] a_var;
bit [3:0] b_var;
covergroup cov3 @(posedge clk);
cp_a: coverpoint a_var {
bins yy[] = { [0:9] };
}
cp_b: coverpoint b_var;
cc_a_b : cross cp_b, cp_a;
endgroup
cp_a有10个bin,cp_b有16个bin,因此cc_a_b有160个bin。
交叉覆盖率通常用于不同功能或者事件同时发生的情况,去验证这些事件是否同时发生了。
[369] 下面的交叉覆盖率有多少个bin?
bit[1:0] cmd;
bit[3:0] sub_cmd;
covergroup abc_cg @(posedge clk);
a_cp: coverpoint cmd;
cmd_x_sub: cross cmd, sub_cmd;
endgroup
cmd和sub_cmd都是二值变量,a_cp有4个bin,sub_cmd默认有16个bin,因此,交叉覆盖率具有64个bin。
[370] 下面的覆盖率代码有什么错误?
int var_a;
covergroup test_cg @(posedge clk);
cp_a: coverpoint var_a {
bins low = {0,1};
bins other[] = default;
}
endgroup
代码对int类型进行覆盖率收集,low的bin数为2,而通过default所创建的数量为\(2^{32}-2\)个,数量十分巨大,这会导致仿真器崩溃或者仿真速度下降。应该尽量避免使用default或者不要使用default。
[371] covergroup有几种采样方式?
有两种采样方式
- 定义covergroup时指定时钟事件,下面是一个例子
covergroup transaction_cg @(posedge clk)
coverpoint req_type;
endgroup
- 显式地调用sample()方法
class packet;
byte[4] dest_addr;
byte[4] src_addr;
covergroup pkt_cg;
coverpoint dest_addr;
endgroup
function new();
pkt_cg =new();
endfunction;
endclass
module test;
initial begin
packet pkt =new();
pkt.pkt_cg.sample();
end
endmodule
[372] 如何给covergroup传递参数,何时用它?
像定义方法一样,covergroup也可以通过类似的语法进行参数传递,主要使用ref,以便随时检测信号的变化。当我们要对多个信号进行相同类型的覆盖率组定义时,我们可以通过定义参数传递的方法改变采样的信号,而覆盖率的定义只需要进行一次即可。下面是一个例子。
module test;
covergroup xy_cg ( ref int x , ref int y, input string name);
cp_x: coverpoint x;
cp_y: coverpoint y;
cc_x_y: cross cp_x, cp_y;
endgroup
initial begin
xy_cg xy_cg_mod1 = new( top.mod1.x, top.mod1.y, "mod1_cvg");
xy_cg xy_cg_mod2 = new( top.mod2.x, top.mod2.y, "mod2_cvg");
end
endmodule
[373] covergroup可以引用DUT中的层次信号吗?
可以
[374] 能够对不同covergroup的coverpoint进行交叉覆盖率定义吗?
不可以,只能对当前covergroup的coverpoint定义交叉覆盖率
[375] per_instance和per_type的区别是什么?如何使用覆盖率选项控制它们?
Covergroup可以定义和实例化多次。 如果一个covergroup有多个实例,则默认情况下,SystemVerilog的coverage报告是所有实例的累计coverage。 这就是默认的per_type。 但是,可以在covergroup中设置一个per_instance选项,那么SystemVerilog将分别报告该Covergroup的每个实例的coverage。
covergroup test_cg @(posedge clk)
option.per_instance =1;
coverpoint var_a;
//and other coverpoints
endgroup
断言
[376] 什么是断言?在验证中使用断言的好处是什么?
断言是根据规范对设计属性的property,用于验证设计的行为。 如果在仿真中检查的property未按照规范运行,则断言失败。 类似地,如果禁止在设计中发生的行为,而在仿真期间发生了,则断言也会失败。
使用断言的好处有:
- 断言在错误发生是会立刻捕获,改善了检测错误的能力
- 断言在设计中能够提供更好的可观察性,因此有助于更轻松地调试
- 断言既可以用于动态仿真,也可以用于设计的形式验证
- 断言还可以用于提供对输入激励的功能覆盖,并确保设计属性确实进行了验证。
[377] 有多少种断言?
systemvrilog中有两种断言,立即断言和并发断言
[378] 立即断言和并发断言的区别是什么?
立即断言使用表达式进行评估,并且像在过程块中的语句一样执行。,执行后会立即进行评估。 立即断言仅用于动态仿真中。 以下是一个简单的立即断言的示例,该断言检查“a和b是否始终相等”:
always_comb begin a_eq_b:
assert (a==b) else $error ("A not equal b");
end
并发断言根据所涉及变量的采样值在时钟沿评估测试表达式。 它们与其他设计模块同时执行。 它们可以放置在模块或接口中。 并发断言可以与动态仿真以及静态(形式)验证一起使用。 以下是一个并发断言的简单示例,该断言检查“如果c在一个时钟周期内为高,则在下一个周期,a和b的值相等”:
ap_a_eq_b : assert property((@posedge clk) c |=> (a == b));
[379] 简单立即断言和延迟立即断言之间有什么区别?
延迟断言是立即断言的一种特殊类型。 简单立即断言立即求值,而无需等待其组合表达式中的变量稳定下来。 因此,当组合表达式逐渐趋于稳定时,简单立即断言很容易出现小故障。 这可能导致断言多次触发,其中一些断言可能是错误的。 为了避免这种情况,定义了延迟断言,仅在时间戳结束时,组合表达式中的变量稳定下来后,才评估这些断言。 这意味着将在时间戳的reactive区域中对它们进行评估。
[380] 与使用过程式SystemVerilog代码编写检查程序相比,使用SVA(SystemVerilog断言)编写checker有什么优势?
最好使用SVA而非程序代码编写某些类型的checker。 SVA具备sequence和property规范的丰富构造,这比使用过程代码或编写基于类的检查器更容易。 另一个额外的好处是,相同的断言也可以在静态检查工具(如形式验证工具)中使用,也可以用于提供功能覆盖率。
下面是一些推荐使用SVA的例子:
- 检查内部设计结构,例如FIFO的上溢或下溢。
- 使用设计中的嵌入式断言可以更轻松地检查模块之间的内部信号和接口
- 使用时间表达式也可以轻松开发标准接口协议(如PCIE,AMBA,以太网等)的checker。
- 仲裁,资源匮乏,协议死锁等检查是很多设计中形式验证的检查内容,因此编写断言将有助于它们在静态和动态仿真中同时使用。
[381] 有几种方式为一个设计编写断言?
- 可以直接在module内部编写断言。 如果断言是由设计工程师为设计中的某些内部信号或接口编写的,则通常会采用这种方式
- 断言也可以编写在单独的interface或module或program中,然后可以绑定到特定的module或实例,在断言中引用来自该特定module或实例的信号。 这是使用SystemVerilog中的bind构造完成的。 如果断言是由验证工程师编写的,会采用这种方式。
[382] SVA中的sequence的作用是什么?
sequence是编写property或断言的基本构建块。 sequence可以认为是在单个时钟边沿求值的简单布尔表达式,也可以是在多个周期内求值的事件sequence。 property可能涉及检查在不同时间开始的一个或多个sequence行为。 因此,可以使用逻辑或sequence组合的多个sequence来构造property。
sequence的基本语法是:
sequence name_of_sequence;
<boolean expression >
endsequence
例如,下面的sequence在检查每个周期的上升沿是否a和b始终相等
sequence s_a_eq_b;
@posedge(clk) (a ==b);
endsequence
[383] $rose(tst_signal)和@posedge(tst_signal)有什么区别?
@posedge(tst_signal)会在每个上升沿进行采样,检查tst_signal是否为1。 但是,$rose()是一个系统任务,它检查信号的采样值在先前采样和当前采样之间(先前采样可能是0 / x / z)是否变为1。 因此,$rose()需要两个采样值进行判断,从原来的非1变成1。 例如:在下面的sequence中,仅当信号“a”在时钟的两个正沿之间从0/x/ z的值变为1时,$rose(a)的计算结果为true
sequence S1;
@(posedge clk) $rose(a)
endsequence
[384] 下面的sequence在以下那种情况下会捕获成功?
sequence S1;
@(posedge clk) $rose(a);
endsequence
- 当信号a”从0变为1时。
- 当信号“a”在clk的一个上升沿采样的值为“0”,而在下一个上升沿采样的值变为“1”。
- 当信号“a”在clk的一个上升沿采样的值为“1”,而在下一个上升沿采样的值变为“0”。
第二种情况下会捕获成功,$rose()检查的是两次采样,第一次非1,第二次为1,@(posedge clk)表示在上升沿时采样。
[385] sequence可以在下面那些地方定义?
- Module
- Interface
- Program
- Clocking Block
- Package
以上所有地方都可以
[386] 在类中是否可以实现并发断言?
不能,并发断言不能再类中实现
[387] 下面的sequence会匹配事件?
req ##2 gnt ##1 !req
当gnt信号在req信号为高电平后的两个周期变为高电平,然后一个周期后req信号被置为零时,该sequence的值为真。
[388] 什么是序列重复运算符? 有哪三种?
如果需要对一个sequence表达式进行一次以上的迭代求值,则可以使用重复运算符来构造一个更长的sequence,而不是编写一个长sequence。 SVA支持三种类型的重复运算符:
- 连续重复([*const_or_range_expression]):如果sequence从一个迭代结束起以一个时钟单位进行有限次数的迭代,可以使用连续重复运算符。在下面的例子中,描述的是如果a为高,一个周期后,b连续五个周期为高的事件。
a ##1 b [*5]
- 跟随重复([->const_or_range_expression]):和连续重复类似,不一样的是,并不要求重复是连续的,间断的也可以,并且要求在最后一次匹配时,立刻匹配后续表达式。下面的例子中,描述的是如果a为高,一个周期后b连续至少2个至多10个周期为高,然后一个周期后c为高的事件
a ##1 b [->2:10] ##1 c
- 非连续重复([=const_or_range_expression] ):和跟随重复类似,但是重复匹配后,并不要求后续立刻跟上,只要在之后能够匹配到即可。例如下面的例子中,可以在c有效匹配前一个时钟,并不需要b进行有效匹配。
a ##1 b [=2:10] ##1 c
[389] 下面的断言有什么错误?
module test (input clk, input a, input b);
assert_1: assert ( a && b);
endmodule;
立即断言只能在程序块中使用
[390] 写一个断言,检查信号最少2个最多6个周期内为高电平
property a_min_2_max_6:
@(posedge clk) $rose(a) |-> a[*2:6] ##1 (a==0)
endproperty
assert property (a_min_2_max_6);
[391] 什么是蕴含操作符?
蕴含操作符用于指定检查的先决条件,描述当先决条件发生后,再继续匹配。蕴含操作符只能再property这一级别使用。蕴含操作符有两种
- 交叠蕴含操作符
assert property prop_name ( sequence_expr |-> property_expr )
- 非交叠蕴含操作符
assert property prop_name ( sequence_expr |=> property_expr )
当蕴含操作符左侧发生后,才会匹配右侧
[392]交叠蕴含操作符和非交叠蕴含操作符有什么不同?
- 交叠蕴含操作符,先决条件的起点和后继事件的起点是同一个时刻。例如下面的例子中,再时钟上升沿是,a要为1,同时开始检查b是否为1,如果不是那么匹配不成功,不会进行后续的评估
assert property abc_overlap (@posedge clk (a==1) |-> b ##1 c )
- 非交叠运算符,先决条件的终点是后继事件的起点,在下一个周期才会匹配后续。例如下面的例子中,时钟上升沿a为1,下个周期要匹配b为1,而不是同一时刻进行匹配。
assert property abc_overlap (@posedge clk (a==1) |=> b ##1 c )
[393] 蕴含操作符可以在sequence中使用吗?
不能,只能在property中使用
[394] 下面的两个断言是等效的吗?
1) @(posedge clk) req |=> ##2 $rose(ack);
2) @(posedge clk) req |-> ##3 $rose(ack);
是的,参考[392]
[395] SVA中允许嵌套蕴含吗?
允许,下面就是一个例子
a |=> b |=> c
匹配的就是a为高,下个周期b为高,再下个周期c为高
[396] 系统函数$past()的作用是什么?
这个系统函数能够从之前的时钟周期中获得信号
[397] 写一个断言,检查一个信号永远不会变成X
使用系统函数$isunknown(signal)可以进行此项检查。
assert property (@(posedge clk) ! $isunknown(mysignal));
[398] 写一个断言,检查一个变量保持独热码状态
使用系统函数$isonehot()或者$countones()可以进行此项检查
assert property (@(posedge clk) $isonehot(state));
assert property (@(posedge clk) $countones(state)==1);
[399] 写一个断言,检查主设备是否在发出有效请求后就在2到5个时钟周期内提供授权
property p_req_grant; @(posedge clk) $rose (req) |-> ##[2:5] $rose (gnt); endproperty
[400] 如何再复位期间禁止进行断言检查?
使用“disable iff”可以实现
assert property (@(posedge clk) disable iff (reset) a |=> b);
[401] systemverilog中的bind构造是什么意思?
SystemVerilog中的bind构造用于将checker于模块、模块的示例或者一个模块的多个示例进行绑定。通过绑定可以分离断言和设计diamagnetic。下面是示例语法
bind <target module/instance> <module/interface to be instantiated> <instance name with port map>
当我们有下面的一个接口,并且内嵌断言
interface range (input clk, enable, int minval, expr);
property crange_en;
@(posedge clk) enable |-> (minval <= expr);
endproperty
range_chk: assert property (crange_en);
endinterface
- 绑定到模块
bind cr_unit range r1(c_clk,c_en,v_low,(in1&&in2));
- 绑定到模块的某个实例
bind cr_unit:cr_unit_1 range r1(c_clk,c_en,v_low,(in1&&in2));
[402] 如何关掉所有的断言?
使用$assertoff()系统函数可以实现,缺省情况下会关掉所有断言。也可以指定关闭哪些断言。
$assertoff[(levels[, list])]
第一个参数指定关闭哪个层次的断言,第二个参数指定关闭具体哪些property
[403] 有哪些方式为property指定时钟?
- sequence中显式使用时钟,继承到property中
sequence seq1;
@(posedge clk) a ##1 b;
endsequence
property prop1;
not seq1;
endproperty
assert property (prop1);
- property中显示使用时钟
property prop1;
@(posedge clk) not (a ##1 b);
endproperty
assert property (prop1);
- 从过程块中推断当前使用的时钟
always @(posedge clk) assert property (not (a ##1 b));
- 使用当前时钟块的时钟
clocking master_clk @(posedge clk);
property prop1;
not (a ##1 b);
endproperty
endclocking
assert property (master_clk.prop1);
- 直接定义默认时钟,在没有上述方法指定时钟的条件下会使用默认时钟。
default clocking master_clk ; // master clock as defined above
property p4;
not (a ##1 b);
endproperty
assert property (p4);
[404] 对于深度= 32的同步FIFO,为以下情况编写断言。 假设具有时钟信号(clk),写入和读取使能信号,满标志和计数器信号。 1)如果计数器> 31,则设置FIFO已满标志。 2)如果计数器为31,并且在没有同时读取的情况下发生了新的写操作,则FIFO满标志将置1。
assert property (@(posedge clk) disable iff (!rst_n) (wordcnt>31 |-> fifo_full));
assert property (@(posedge clk) disable iff (!rst_n) (wordcnt==31 && write_en && !read_en |=> fifo_full));
注意第二条,使用的是非交叠蕴含操作符,满标志位要在下个周期拉高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号