jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库
——jieba库!
这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚至是根据猜测的词义形成字典!
这么好用的库不去了解实在是可惜啊!!!
那么第一步,我们当然是先安装它了!
步骤很简单!
就是我们以往的cmd命令行安装即可;
接下来让我们了解一下它的基本语法吧!
jieba库有三个基本的模式:精确模式、全模式、搜索引擎模式
精确模式:试图将语句最精确的切分,不存在冗余数据,适合做文本分析
全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据
搜索引擎模式:在精确模式的基础上,对长词再次进行切分
于是我们来尝试一下:
第一步:首先是精准模式:
上图

哇!!真的可以准确地分词诶!!不过……我知道我可以很伟大……但也没必要拆了我名字把……哈哈哈哈
第二步:全模式

哟~好吧,我用亲生经历告诉大家,其实这jieba库还是有它识别的局限的,我现在又“伟大”,又“大帅”了哈哈哈
不过我发现,该模式下,一个标点符号后就会多出“//”来区分断点,而且少掉了标点符号,显然它是对主体的词汇进行操作了!
第三步:搜索引擎模式
虽然不知道是什么模式,不过听上去就很高大上!
不多说,先试!

emmm……看这输出结果我并不能看出与第一步模式有什么不同,也许我还得深入研究!
接下来我看可以开始一些简单的应用了,
下面贴一段代码:
def get_text(): txt = open("NEWS.txt", "r", encoding='UTF-8').read() txt = txt.lower() for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格 return txt file_txt = get_text() words = file_txt.split() # 对字符串进行分割,获得单词列表 counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) for i in range(5): word, count = items[i] print("{0:<5}->{1:>5}".format(word, count))
很显然,我在桌面上放了一个名为“NEWS”的txt文件(其实是Python目录里的一个说明的一部分哈哈哈),然后用着代码去计算里面一些长度的词的个数(该代码适合英文)
结果是:

挺好用!
当然,在这里介绍的只是一些初步,jieba库还有好多值得一试的好玩功能,你甚至可以结合字典,搜索关键字等等……
接下来!!!是词云部分的制作!
虽然我们有很多词云自动生成的网站,但是自己编写出来的可运行程序会不会更加有成就感呢!
有一种形式:
(1)打开taglue官网,点击import words,把运行的结果copy过来。
(2)选择形状,在这里是网上下载的图片进行的导入。
(3)选择字体。
(4)点击Visualize生成图片。
当然啦~其实这也不是什么高深莫测的题目,我们可是拥有强大的第三方python库的啊!!wordcloud——你值得拥有!
一样滴先cmd安装,接着还有确保jieba库和matploylib的安装
下面是代码实现:
from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba def create_word_cloud(filename): text = open("百年孤独.txt".format(filename)).read() wordlist = jieba.cut(text, cut_all=True) wl = " ".join(wordlist) wc = WordCloud( background_color="black", max_words=2000, font_path='simsun.ttf', height=1200, width=1600, max_font_size=100, random_state=100, ) myword = wc.generate(wl) plt.imshow(myword) plt.axis("off") plt.show() wc.to_file('img_book.png') if __name__ == '__main__': create_word_cloud('mytext')
通过放在桌面的《百年孤独》文本搜索素材
效果如图:
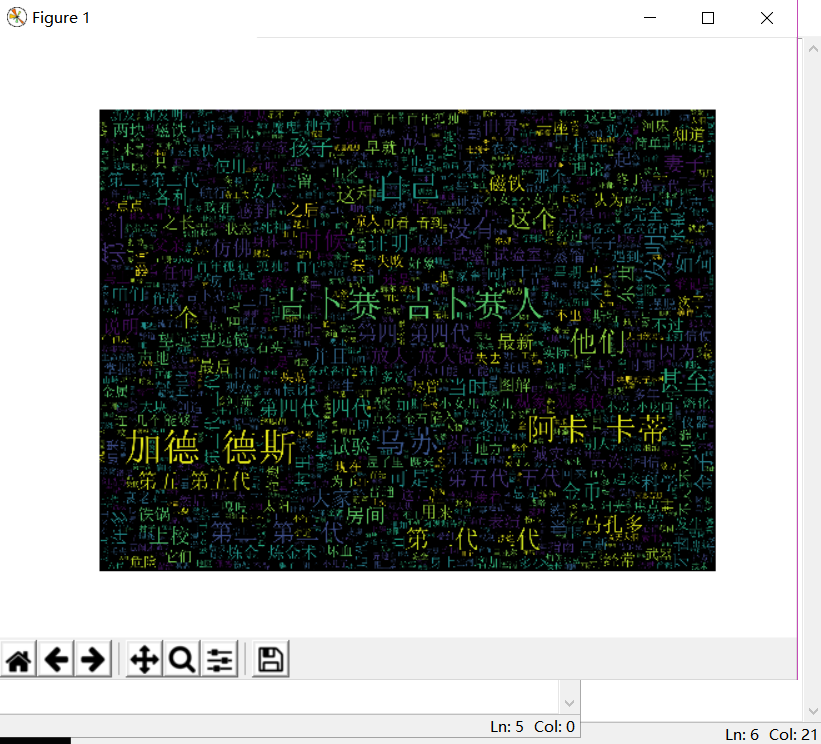
我还发现了下面的按钮还有一些比较好玩的功能比如调节大小

在这个数值下会覆盖全框哦!
是不是很赞呢~快去自己试试看怎么实现吧~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号