520疯狂之后我彻底蒙了,老板让我做技术选型,数据处理选kafka还是RocketMQ?
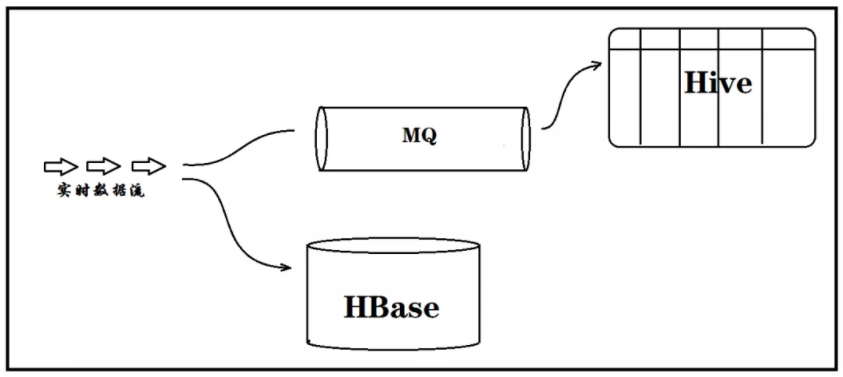
场景描述:北京有很多电动车,这些车都会定时地向一个服务器发送状态信息,这些信息可能包括:车的id、发送 时间、车的位置(经纬度)、车的速度、剩余电量等等。有了这些信息我们可以做很多事情,比如:计算车 的轨迹、出租车的运行规律、电量维持时间等等。

一、kafka到底在怎样的应用场景下使用?
在类似这样的场景下,项目开发中的数据量很大,一天上千万,最初,数据存在HBase,我们想替换掉HBase ,原因如下:
1、数据量大了后,HBase运维成本很高
2、数据统计一般在Hive中进行,导致数据有一天的延时
那么可实行的方案就是:用Kafka兜住热数据,然后定时以 microbatch 的方式将数据落地到HDFS
效果演示
回退环境

MQ 选型
问:RocketMQ 异常优秀。是不是直接选用 RocketMQ?
答:RocketMQ 是在 Kafka 的基础上重写的,保留了 Kafka durable 机制、集群优势,牺牲了一些 吞吐量,换取了更好的 数据可靠性。我们这个场景要求的就是吞吐量。
Kafka 更适合密集的数据,RocketMQ适合稀疏的数据:

结论:
业务场景:用RocketMQ
数据场景:1、一般用 Kafka,2个例外:
》若有大量小 Topic,用 RocketMQ
》若对数据可靠性要求极高,用 RocketMQ
二、Kafka 基础
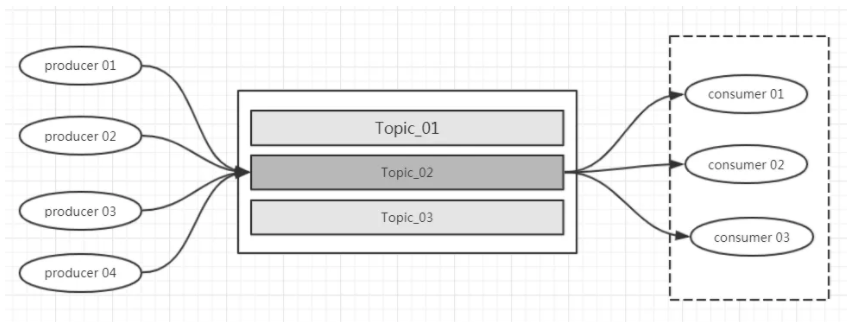
1 Topic
Kafka对数据进行划分唯一的逻辑单元
2 、架构速览
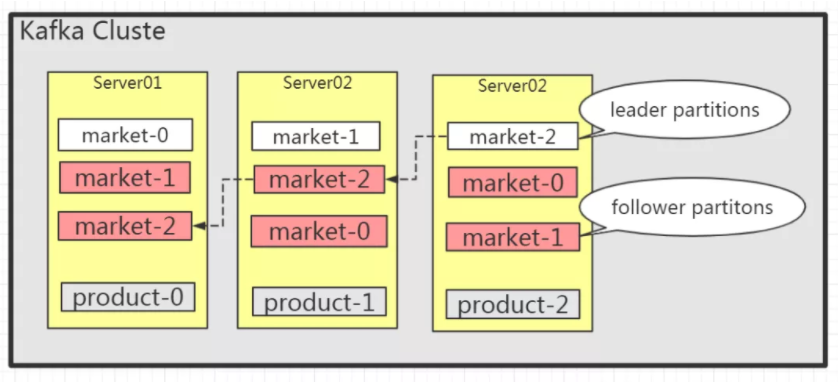
问:这样的架构,能否保证 Topic 中数据的顺序?

三、Kafka集群搭建
要进行这样一个方案,我们首先需要一个Kafka集群,毕竟巧妇难为无米之炊
现在就带着搭建一个生产级别的Kafka
今天带着大家全手动搭建集群,这样可以对集群原理有更好的认识
1、 安装JDK8
JDK自行解决
2、 ZK 安装
Kafka的元数据全部放在ZK上,Kafka强依赖ZK,所以PROD上转kafka,要先装ZK
#统一各机器的时钟 date -s 'Fri Nov 1 11:17:46 CST 2019' #上传安装包 #解压缩 tar -zxvf kafka_2.11-2.2.1.tgz tar -zxvf zookeeper-3.4.13.tar.gz #创建数据目录 mkdir -p data/zookeeper/ mkdir -p data/kafka
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 syncLimit=5 # example sakes. dataDir=/home/zk/data/zookeeper #change # the port at which the clients will connect clientPort=2181 server.1=192.168.90.131:8880:7770 #add server.2=192.168.90.132:8880:7770 #add server.3=192.168.90.133:8880:7770 #add
#创建日志目录 mkdir -p /home/zk/zookeeper-3.4.13/logs #指定日志目 vi zkEnv.sh 添加如下行: ZOO_LOG_DIR=/home/zk/zookeeper-3.4.13/logs
#分发 安装包 cd /home/zk/ scp -r zookeeper-3.4.13 192.168.90.132:`pwd` scp -r zookeeper-3.4.13 192.168.90.133:`pwd` #每台机器配置 myid cd /home/zk/data/zookeeper/ echo "1" > myid #在第1台机器执行 echo "2" > myid #在第2台机器执行 echo "3" > myid #在第3台机器执行 #启动ZK,每台机器执行: cd /home/zk/zookeeper-3.4.13 bin/zkServer.sh start #检查集群状态 bin/zkServer.sh status 集群状态为 leader 或 follower,则集群正常
3、Kafka 安装
#分发kafka安装包 scp -r kafka_2.11-2.2.1 192.168.90.132:`pwd` scp -r kafka_2.11-2.2.1 192.168.90.133:`pwd
修改 每台机器,confifig/server.properties
broker.id=0 其他机器改为为1、2 log.dir=/home/zk/data/kafka listeners=PLAINTEXT://zkserver1:9092 zkserver1改为其他机器相应的 hostname
启动kafka,每台机器执行: bin/kafka-server-start.sh config/server.properties &
5、测试Kafka
#创建topic bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test --partitions 3 --replication-factor 2 #生产 bin/kafka-console-producer.sh --broker-list 192.168.90.131:9092 --topic test #消费 bin/kafka-console-consumer.sh --bootstrap-server 192.168.90.131:9092 --topic test
四、producer端
1、 创建项目
创建项目,指定 compiler
<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties>
2、确定数据结构
import java.sql.Date; public class Electrocar { private String id; //数据发送时间 private Date time; //经度 private double longitude; private double latitude; //速度 private double speed; //剩余电量 private double dump_energy; //构造函数,用于快速构造数据 public Electrocar(String id, Date time, double longitude, double latitude, double speed, double dump_energy){ this.id = id; this.time = time; this.longitude = longitude; this.speed = speed; this.dump_energy = dump_energy; } //生成getter方法,不生成setter方法 public String getId() { return id; } public Date getTime() { return time; } public double getLongitude() { return longitude; } public double getLatitude() { return latitude; } public double getSpeed() { return speed; } public double getDump_energy() { return dump_energy; } }
2、生成数据
public class CarDataSource {
public static void main(String args[]) throws InterruptedException {
while (true){
ElectroCar car = nextRecord(); //生成数据
System.out.println(String.format("%s|%f|%f", car.getId(), car.getLatitude(), car.getLongitude()));
Thread.sleep(200);
}
}
public static ElectroCar nextRecord(){
//定义random,用于生成随机值
Random random = new Random();
//构建 ElectroCar对象
ElectroCar car = new ElectroCar(
random.nextInt(10) + "",
new Date(System.currentTimeMillis()),
random.nextFloat(),
random.nextFloat(),
random.nextFloat(),
random.nextFloat()
);
return car;
}
}
3、producer 官网示例
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
4 创建topic
bin/kafka-topics.sh --create \ --bootstrap-server 192.168.90.131:9092 \ --replication-factor 3 \ --partitions 3 \ --topic electrocar
5 数据格式
思考:应该以什么格式将数据 publish 到 Kafka? json不好, 要用二进制

ObjectBinary测试
public class ObjectBinaryUtil {
public static void main(String args[]){
Electrocar car = CarDataSource.nextRecord();
byte[] arr = null;
//将Car obj output 为byte[]
//ByteArray输出
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try {
//将oos输出到bos
ObjectOutputStream oos = new ObjectOutputStream(bos);
//对象输出到oos
oos.writeObject(car);
//获取byte[]
arr = bos.toByteArray();
System.out.println("arr.length :" + arr.length);
} catch (IOException e) {
e.printStackTrace();
}
//将byte[] 转成 obj
//接受arr输入
ByteArrayInputStream bis = new ByteArrayInputStream(arr);
try {
//bis 转为ObjectInput
ObjectInputStream ois = new ObjectInputStream(bis);
//从ObjectInput 读取Obj
Electrocar car1 = (Electrocar) ois.readObject();
System.out.println("++++" + car.getLatitude());
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
ObjectBinearyUtil 封装
//Object to byte[]
public static byte[] toBinary(Object obj){
//将Car obj output 为byte[]
//ByteArray输出
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = null;
try {
//将oos输出到bos
oos = new ObjectOutputStream(bos);
//对象输出到oos
oos.writeObject(obj);
//获取byte[]
return bos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (bos !=null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (oos !=null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
//byte[] to Object
public static Object toObject(byte[] arr){
//将byte[] 转成 obj
//接受arr输入
ByteArrayInputStream bis = new ByteArrayInputStream(arr);
ObjectInputStream ois = null;
try {
//bis 转为ObjectInput
ois = new ObjectInputStream(bis);
//从ObjectInput 读取Obj
return ois.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}finally {
if (bis!=null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (ois !=null){
if (ois !=null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
return null;
}
6、消息顺序
思考:消息的顺序丢失了,怎么办? 将相同id的数据放到同一个partition
while (true){
Electrocar car = nextRecord();
byte[] carBinary = ObjectBinaryUtil.toBinary(car);
ProducerRecord<String, byte[]> record = new ProducerRecord<String, byte[]>(
"electrocar",
car.getId(), //通过传入carId,来保证消息的顺序
carBinary);
producer.send(record);
Thread.sleep(200);
System.out.println("published...");
}
五、consumer 传统方式
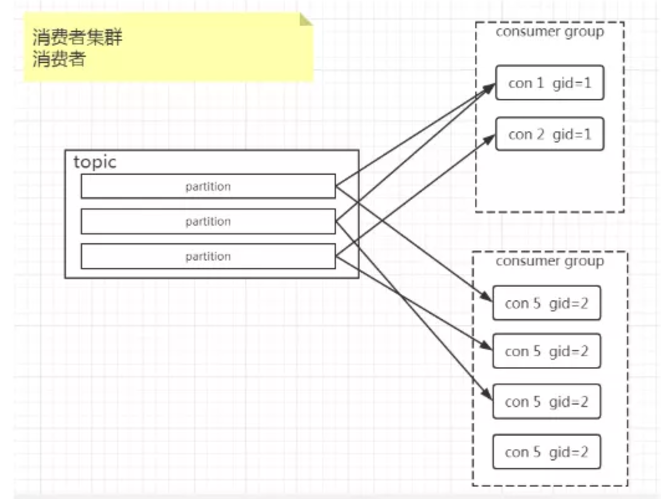
group.id
Kafka 中有一个消费者集群的概念,我们将其称之为consumer group。
auto.commit
1、问:consumer 重启时,应该从何处开始继续消费?
答:从关闭时的 offset开始消费,这就要 实时记录消费进度
2、enable.auto.commit=true时,由 consumer 自动提交,false时手动提交
consumer.commitAsync(); //手动提交API
3、问: offset 提交到哪里了呢?
答:在 offset早期,提交到ZK,提交到系统级别的topic
4、存在数据数据一致性问题
能够理解的同学扣个1,不理解的扣个2

exactly-once 方案
方案总述

消费kafka
//创建 demo2 //实例化consumer从demo1处拷贝 //修改数据类型 KafkaConsumer<String, byte[]> consumer ByteArrayDeserializer //没有 commit offset,不能用subscribe 方法 List<TopicPartition> partitions = new ArrayList<>(); for (int i=0; i<3; i++){ //构建partition 对象 TopicPartition p = new TopicPartition(topic, i); partitions.add(p); } //指定,当前consuer具体消费哪几个paritions consumer.assign(partitions);
seek到具体Offset
重启consumer时,要从MySQL中获取offset,
根据该offset开始消费 toipic,
就要知道如何跳转到 具体的 offset
for (TopicPartition p : partitions){ consumer.seek(p, 20); //将partition seek到具体的offset开始消费 }
建MySQL表
CREATE TABLE `electrocar` ( `topic` varchar(20) DEFAULT NULL, `pid` int(11) DEFAULT NULL, `offset` mediumtext, `id` int(11) DEFAULT NULL, `timestamp` date DEFAULT NULL, `longitude` float DEFAULT NULL, `latitude` float DEFAULT NULL, `speed` float DEFAULT NULL, `dump_energy` float DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8
落地数据
//引入JdbcHelper
#创建连接
JdbcHelper jdbcHelper = new JdbcHelper("jdbc:mysql://192.168.90.131:3306/kafka", "kafka", "kafka");
Connection conn = jdbcHelper.getConnection();
System.out.println("MySQL conn inited...");
Statement stat = null; //创建会话
try {
stat = conn.createStatement();
while (true) { //循环执行poll方法
//到服务端拉取消息,得到一个集合
ConsumerRecords<String, byte[]> records = consumer.poll(Duration.ofMillis(100));
if (records.count() >0){ //有消息,才insert
//将records 转成 批量插入的SQL语句
String sql = records2SQL(records);
stat.execute(sql);
System.out.println("inserted...");
}else {
System.out.println("no record...");
}
}
} catch (SQLException e) {
e.printStackTrace();
}
records转SQL
public static String records2SQL(ConsumerRecords<String, String> records){ StringBuilder sb = new StringBuilder(); sb.append("INSERT INTO kafka.electrocar VALUES "); Iterator itr = records.iterator(); while (itr.hasNext()){ ConsumerRecord<String, byte[]> record = (ConsumerRecord<String, byte[]>)itr.next(); Electrocar car = (Electrocar) ObjectBinaryUtil.toObject(record.value()); String strDateFormat = "yyyy-MM-dd HH:mm:ss"; SimpleDateFormat sdf = new SimpleDateFormat(strDateFormat); String time = sdf.format(car.getTime()); String sqlPiece = String.format("('%s',%d,%d,%s,'%s',%f,%f,%f,%f)", record.topic(), record.partition(), record.offset(), car.getId(), time, car.getLongitude(), car.getLatitude(), car.getSpeed(), car.getDump_energy()); sb.append(sqlPiece); if (itr.hasNext()){ sb.append(","); } } //System.out.println(sb.toString()); return sb.toString(); }
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.25</version>
</dependency>
import com.mysql.jdbc.Driver;
封装成通用工具
1、创建 ExactOnceConsumer
现在还只是一个demo,只能用于electrocar topic的消费,现在我们将其封装成一个小框架,让他能够经过极少量的开发,就能消费其他的topic
2、重构
关注公众号:艾编程,看完整本课程视频+资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号